
介绍一种通过数据驱动的方法,在自定义数据集上选择最快,最准确的ANN算法

人工神经网络背景
KNN是我们最常见的聚类算法,但是因为神经网络技术的发展出现了很多神经网络架构的聚类算法,例如 一种称为HNSW的ANN算法与sklearn的KNN相比,具有380倍的速度,同时提供了99.3%的相同结果。
为了测试更多的算法,我们整理了几种ANN算法,例如
- Spotify’s ANNOY
- Google’s ScaNN
- Facebook’s Faiss
- HNSW(Hierarchical Navigable Small World graphs)
- 一些其他算法
作为数据科学家,我我们这里将制定一个数据驱动型决策来决定那种算法适合我们的数据。在本文中,我将演示一种数据驱动的方法,通过使用出色的an-benchmarks GitHub存储库,确定哪种ANN算法是自定义数据集的最佳选择。

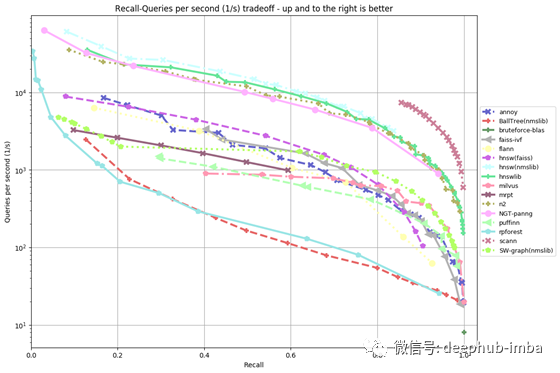
下图是通过使用距离度量在glove-100 数据集上运行ANN基准而得到的图形。在此数据集上,scann算法在任何给定的Recall中具有最高的每秒查询数,因此在该数据集上具有最佳的算法。
总流程
这些是在自定义数据集上运行ann-benchmarks代码的步骤。
- 在python 3.6环境中安装ann-benchmarks。
- 将自定义嵌入数据框架上传到anbenchmarks / data目录。
- 更新ann-benchmarks / ann-benchmarks / dataset.py,以读取并拆分新的自定义DataFrame。
- 运行基准测试代码。
- 绘制结果
1.在python 3.6环境中安装ann-benchmarks
此步骤的代码需要在终端中执行。我在使用anaconda进行环境设置。这将需要几分钟才能完成。您可以使用proc参数增加并发进程的数量,从而加快速度。我仅在安装完成后才升级pandas和scipy。
在撰写本文时,Ann基准仅支持Python 3.6。
conda create -n ann python=3.6 jupyterlab -y
conda activate ann
git clone https://github.com/erikbern/ann-benchmarks.git
cd ann-benchmarks/
pip install -r requirements.txt
python install.py --proc=8
pip install --upgrade pandas scipy
mkdir data
可能出现的问题:
- 未安装gcc:使用sudo apt-get install gcc安装GCC。
- 权限问题:如果在运行python install.py时遇到任何权限问题,只需使用sudo / opt / conda / envs / ann / bin / python install.py即可运行它。使用sudo时,请记住在您的环境中提供anaconda python的完整路径。
2.上传自定义DataFrame
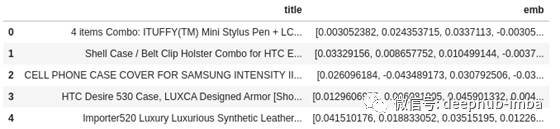
在此步骤中,将自定义数据框架文件复制到ann-benchmarks / data目录中。对于这篇文章,我的DataFrame与使用的带有FastText句子嵌入的[Amazon产品数据集]。但是,我只是随机抽样5万行,以确保基准测试能够在合理的时间内运行。以下是将嵌入数据框保存为正确目录中名为custom-euclidean.pkl的文件的代码,也是该数据框前5行的摘录。
df.to_pickle('ann-benchmarks/data/custom-euclidean.pkl')
df.head()
3.更新datasets.py以处理您的自定义DataFrame
我们需要更新ANN基准代码,编写我们的新的DataFrame处理代码。我们在ann-benchmarks / ann-benchmarks / datasets.py文件的末尾添加了一个新的function和dictionary元素。距离参数的允许选项是“euclidean”,“angular”,“hamming”或“jaccard”。距离度量的选择特定于您的问题。就我而言,我发现“欧式距离”提供了最好的结果
def custom_dataset(out_fn, test_ratio, distance):
# Function to handle our custom dataset
import pandas as pd
# Read the Data Frame
# out_fn is of the form 'data/<dataset-name>.hdf5'
df = pd.read_pickle(out_fn.split('.')[0]+'.pkl')
# Convert single embedding column to numpy list of lists
X = pd.DataFrame(df['emb'].tolist()).to_numpy()
# Split Train and Test
X_train, X_test = train_test_split(X, test_size=test_ratio)
# Write HDF5 Output
write_output(X_train, X_test, out_fn, distance)
# Create a new dictionary element to call our new function
# 20% of rows used as Test Set
# Euclidean distance used as measure for finding neighbors
DATASETS['custom-euclidean'] = lambda out_fn: custom_dataset(out_fn, test_ratio=0.2, distance='euclidean')
4.运行基准测试代码
如果到目前为止一切顺利,我们现在可以通过从终端调用以下代码来运行基准测试。将并行性的值更改为要使用的尽可能多的CPU内核。我使用的是16核CPU,因此我选择parallelism = 14来为其他任务保留2核。这将需要一些时间才能完成。我的具有20%测试集的5万数据行了大约7个小时。
python run.py --dataset='custom-euclidean' --parallelism=14
5.绘制结果
运行完成后,我们可以通过运行plot.py绘制结果。我们还可以使y轴以对数比例绘制。请注意,我在使用sudo时使用了Anaconda Python的完整路径,因为在尝试正常运行plot.py时遇到权限问题:python plot.py --dataset = custom-euclidean --y-log。您可以使用任何适合您的方法。
sudo /opt/conda/envs/ann/bin/python plot.py --dataset=custom-euclidean --y-log
结果图将作为png文件保存在结果目录中。对于我在本文中使用的5万行Amazon数据集,结果如下。
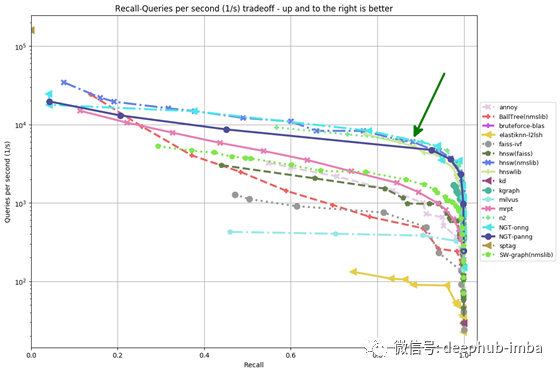
从该图中可以看出,通过在任意给定的Recall上每秒提供更高的查询,诸如NGT-onng,hnsw(nmslib),n2,hnswlib,SW-graph(nmslib)之类的算法明显优于其余算法。因此,我们可以在亚马逊产品数据集上为我们的项目进一步探索这些算法。
总结
总之,通过使用ann-benchmarks,并编写一些自定义的代码,我们可以 在自己的自定义数据集上测试大量的ANN算法,以缩小筛选范围,以进一步探索。这篇文章的所有代码都可以在我的Github存储库中找到。感谢您的阅读!
代码地址:https://github.com/stephenleo/adventures-with-ann/blob/main/ann_benchmarking.ipynb
作者:Marie Stephen Leo
deephub翻译组