
1、实战内容
爬取京东笔记本电脑商品的信息(如:价格、商品名、评论数量),存入 MySQL 中
2、思路
京东需要登录才能搜索进入,所以首先从登录页面出发,自己登录,然后等待,得到 Cookies,之后带着 Cookies 模拟访问页面,得到页面的 response,再对 response 进行分析,将分析内容存入 MySQL 中。
3、分析 url
来到 京东搜索 笔记本电脑,之后观察首页之后的几页的链接,如下:
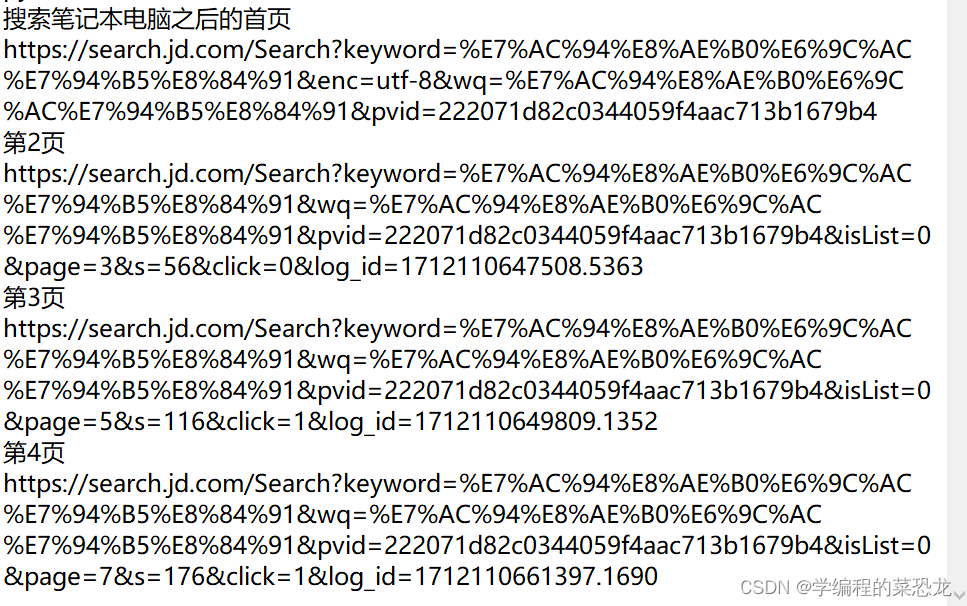
不难发现,除了首页之外,其他链接的区别是从第四行的 page 开始,大胆猜测链接就到此即可,且规律也显而易见,就可以直接构造链接。
4、开始操作
1、得到 Cookies
from selenium import webdriver
import json, time
def get_cookie(url):
browser = webdriver.Chrome()
browser.get(url) # 进入登录页面
time.sleep(10) # 停一段时间,自己手动登录
cookies_dict_list = browser.get_cookies() # 获取list的cookies
cookies_json = json.dumps(cookies_dict_list) # 列表转换成字符串保存
with open('cookies.txt', 'w') as f:
f.write(cookies_json)
print('cookies保存成功!')
browser.close()
if __name__ == '__main__':
url_login = 'https://passport.jd.com/uc/login?' # 登录页面url
get_cookie(url_login)
之后就可看到 txt 文件中的 cookies(多个),之后模拟登录构造 cookie 时,对照其中的即可.
2、访问页面,得到 response
当 selenium 访问时,若页面是笔记本电脑页,直接进行爬取;若不是,即在登录页,构造 cookie,添加,登录;
js 语句是使页面滑倒最低端,等待数据包刷新出来,才能得到完整的页面 response(这里的 resposne 相当于使用 request 时候的 response.text );
def get_html(url): # 此 url 为分析的笔记本电脑页面的 url
browser = webdriver.Chrome()
browser.get(url)
if browser.current_url == url:
js = "var q=document.documentElement.scrollTop=100000"
browser.execute_script(js)
time.sleep(2)
responses = browser.page_source
browser.close()
return responses
else:
with open('cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
cookie_dict = {
'domain': '.jd.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '1746673777', # 表示 cookies到期时间
'path': '/', # expiry必须为整数,所以使用 expires
'httpOnly': False,
"sameSite": "Lax",
'Secure': False
}
browser.add_cookie(cookie_dict) # 将获得的所有 cookies 都加入
time.sleep(1)
browser.get(url)
js = "var q=document.documentElement.scrollTop=100000"
browser.execute_script(js)
time.sleep(2)
response = browser.page_source
browser.close()
return response
cookies 到期时间是用时间戳来记录的,可用工具查看时间戳(Unix timestamp)转换工具 - 在线工具
3、解析页面
这里我使用了 Xpath 的解析方法,并将结果构造成字典列表,输出。
def parse(response):
html = etree.HTML(response)
products_lis = html.xpath('//li[contains(@class, "gl-item")]')
products_list = []
for product_li in products_lis:
product = {}
price = product_li.xpath('./div/div[@class="p-price"]/strong/i/text()')
name = product_li.xpath('./div/div[contains(@class, "p-name")]/a/em/text()')
comment = product_li.xpath('./div/div[@class="p-commit"]/strong/a/text()')
product['price'] = price[0]
product['name'] = name[0].strip()
product['comment'] = comment[0]
products_list.append(product)
print(products_list)
print(len(products_list))
4、存入 MySQL
上述已经得到每一个商品数据的字典,所以直接对字典或字典列表进行存储即可。
参考链接:4.4 MySQL存储-CSDN博客 5.2 Ajax 数据爬取实战-CSDN博客
5、1-3步总代码
from selenium import webdriver
import json, time
from lxml import etree
def get_cookie(url):
browser = webdriver.Chrome()
browser.get(url) # 进入登录页面
time.sleep(10) # 停一段时间,自己手动登录
cookies_dict_list = browser.get_cookies() # 获取list的cookies
cookies_json = json.dumps(cookies_dict_list) # 转换成字符串保存
with open('cookies.txt', 'w') as f:
f.write(cookies_json)
print('cookies保存成功!')
browser.close()
def get_html(url):
browser = webdriver.Chrome()
browser.get(url)
if browser.current_url == url:
js = "var q=document.documentElement.scrollTop=100000"
browser.execute_script(js)
time.sleep(2)
responses = browser.page_source
browser.close()
return responses
else:
with open('cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
cookie_dict = {
'domain': '.jd.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '1746673777',
'path': '/',
'httpOnly': False,
"sameSite": "Lax",
'Secure': False
}
browser.add_cookie(cookie_dict) # 将获得的所有 cookies 都加入
time.sleep(1)
browser.get(url)
js = "var q=document.documentElement.scrollTop=100000"
browser.execute_script(js)
time.sleep(2)
response = browser.page_source
browser.close()
return response
def parse(response):
html = etree.HTML(response)
products_lis = html.xpath('//li[contains(@class, "gl-item")]')
products_list = []
for product_li in products_lis:
product = {}
price = product_li.xpath('./div/div[@class="p-price"]/strong/i/text()')
name = product_li.xpath('./div/div[contains(@class, "p-name")]/a/em/text()')
comment = product_li.xpath('./div/div[@class="p-commit"]/strong/a/text()')
product['price'] = price[0]
product['name'] = name[0].strip()
product['comment'] = comment[0]
products_list.append(product)
print(products_list)
print(len(products_list))
if __name__ == '__main__':
keyword = '笔记本电脑'
url_login = 'https://passport.jd.com/uc/login?' # 登录页面url
get_cookie(url_login)
for page in range(1, 20, 2):
base_url = f'https://search.jd.com/Search?keyword={keyword}&wq=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&pvid=222071d82c0344059f4aac713b1679b4&isList=0&page={page}'
response = get_html(base_url)
parse(response)
文章参考:python爬虫之使用selenium爬取京东商品信息并把数据保存至mongodb数据库_seleniu获取京东cookie-CSDN博客
文章到此结束,本人新手,若有错误,欢迎指正;若有疑问,欢迎讨论。若文章对你有用,点个小赞鼓励一下,谢谢大家,一起加油吧!
版权归原作者 学编程的菜恐龙 所有, 如有侵权,请联系我们删除。