
Python使用urllib.open再配合BeautifulSoup解析是最快的网页抓取方式,但部分网站做了反爬,用这种抓取方法会出错,就是浏览器里看网页内容是有的,但Python里抓出来的是空架子无数据。这种时候可以F12观察网站是否有直接的数据接口返回了数据,找到这个接口直接调用更方便,但如果也没有,那就只有用selenium来启动浏览器去模拟抓取了。
因为浏览器可以解析加载js等数据,而Python模拟则不行,所以必须多一个步骤用Python去调起浏览器再抓。
例如抓取天眼查具体公司页面的工商信息。
https://www.tianyancha.com/company/270844017
urllib.open去抓取不稳定,数据时有时无,现在用selenium。
1、使用selenium首先在cmd里导入包 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
2、在浏览器驱动镜像网站下载对应的驱动 http://chromedriver.storage.googleapis.com/index.html ,这里用的谷歌浏览器102.0.5005版本就下载对应驱动,下载后解压是chromedriver.exe驱动文件,把该文件丢到Python安装目录下的Scripts目录下
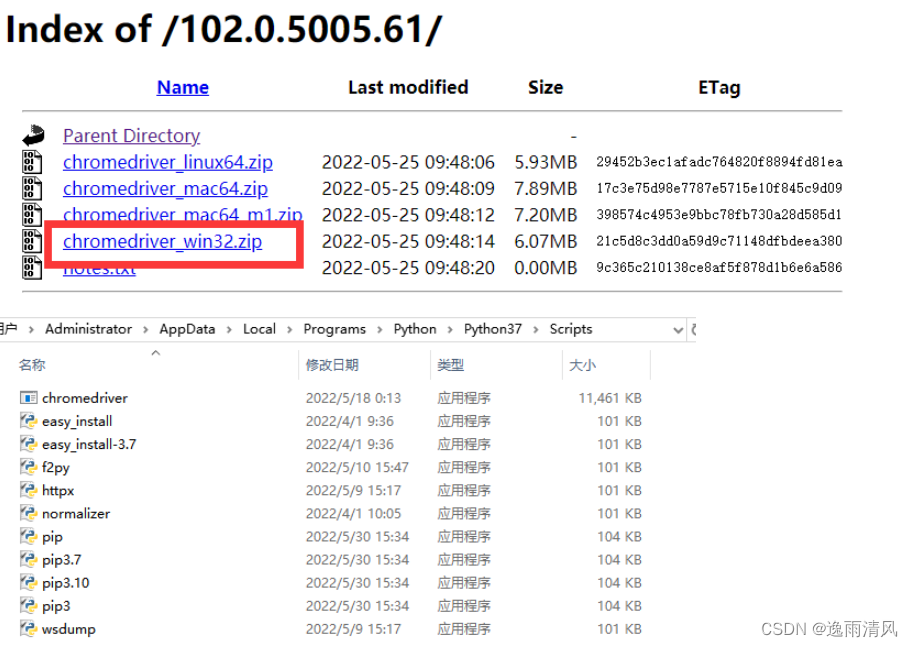
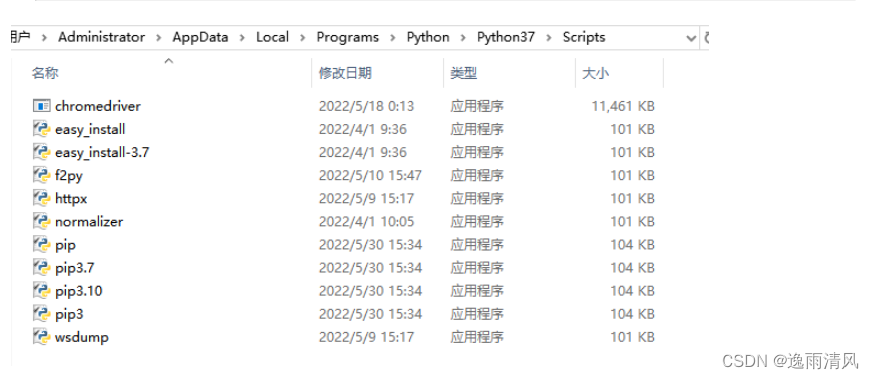
3、主程序里代码
driver = webdriver.Chrome() 启动模拟浏览器
4、抓取方法里就和传统BeautifulSoup一致了,相当于就是用实际调用起来的模拟浏览器selenium代替了后台静默的requests。
这里需要注意的一点是因为页面动态加载,个人网速不一样所以有的元素没有及时加载出来,就用一个死循环和异常判定,因为我笃定正常情况可以获取到这个元素,所以获取不到时候就是没加载出来,就等待1秒后再次获取,获取到后就跳出死循环继续后面的数据处理。
driver.get(url)
#等待页面加载
while 1:
try:
print("开始获取")
data = bs.select_one("table.index_tableBox__GoBpe ").text
break
except:
print("刷新等待")
time.sleep(1)
bs = BeautifulSoup(driver.page_source,from_encoding="gb18030")
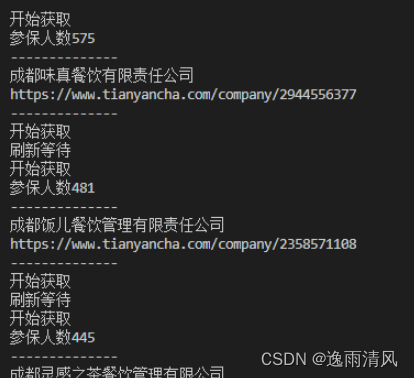
以上就是用selenium代替requests抓取网页数据的全流程
版权归原作者 逸雨清风 所有, 如有侵权,请联系我们删除。