
文章目录
一、jieba介绍
jieba是一个分词器,可以实现智能拆词,最早是提供了python包,后来由花瓣(huaban)开发出了java版本。
源码:https://github.com/huaban/jieba-analysis
分词的模式
- search 精准的切开,用于对用户查询词分词
- index 对长词再切分,提高召回率
二、集成
1.引入相关依赖
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
2.核心代码
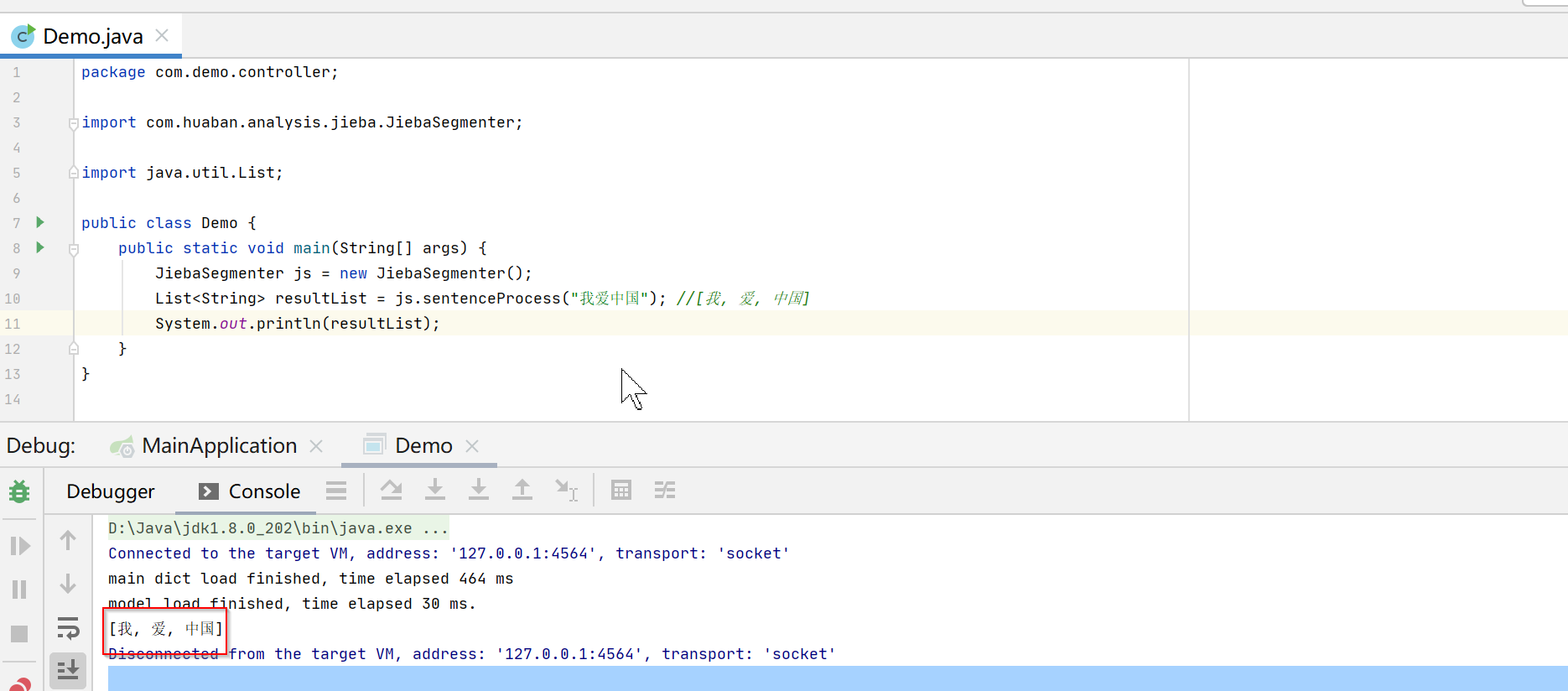
public class Demo {
public static void main(String[] args) {
JiebaSegmenter js = new JiebaSegmenter();
List<String> resultList = js.sentenceProcess("我爱中国"); //[我, 爱, 中国]
System.out.println(resultList);
}
}
三、原理
为什么jieba可以实现智能拆词?是否可以自己增加拆词呢?
jieba项目resource目录下有个dict.txt文件,里面维护了非常多的拆词,jieba就是根据这个文件进行拆词的。自己也可以在这个文件中添加自定义拆词,或者新建一个文件。
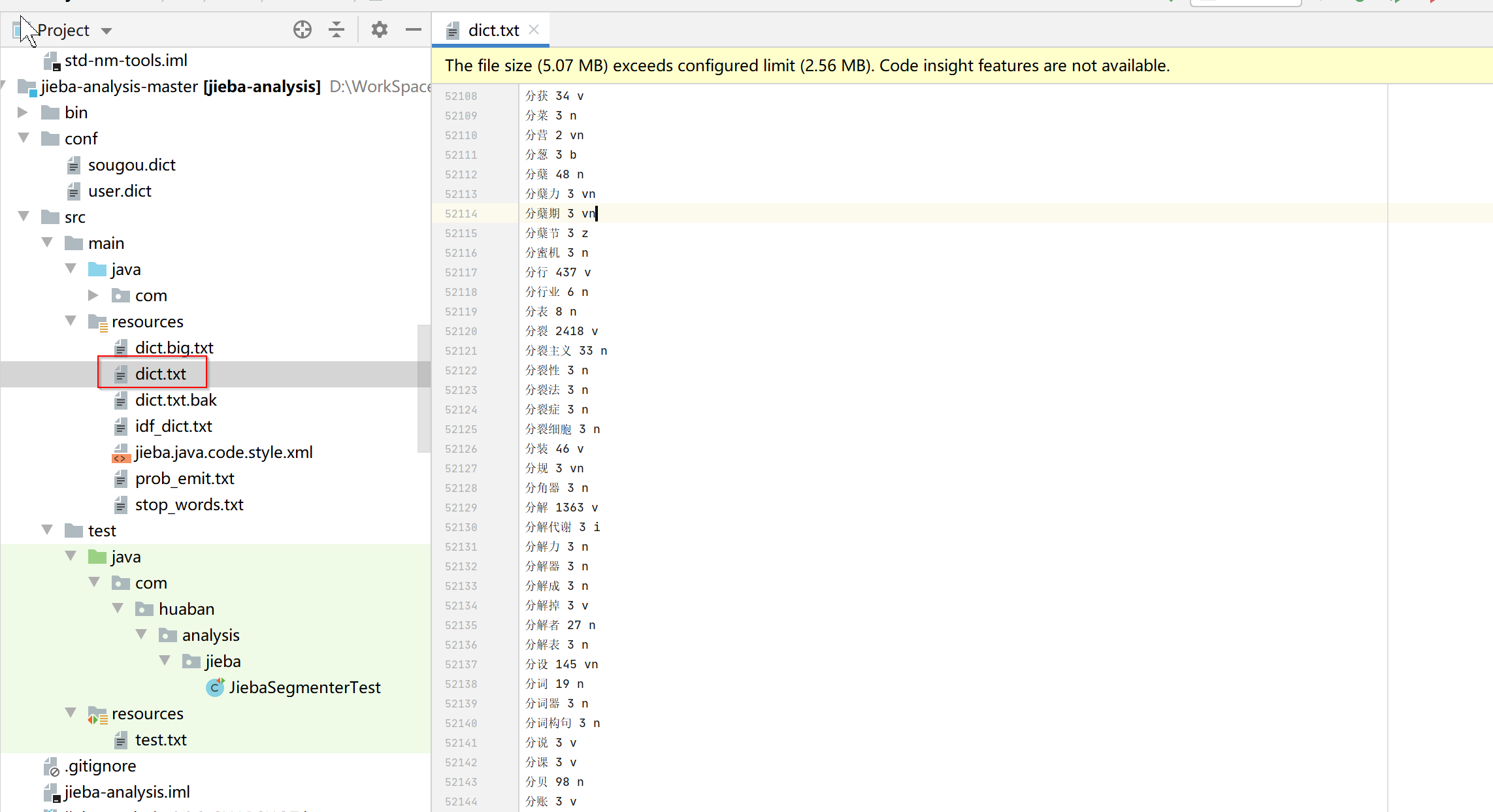
四、自定义拆词
4.1、方式一:在源码的dict.txt中修改然后重新打包(推荐)
我们可以把源码下载下来,然后修改dict.txt文件后重新打包,这种方式是比较推荐的。还有一种方式就是新建一个txt文件然后引用,但是新增文件会导致在两个地方维护了拆词,而且新增文件中的拆词有时候会跟jieba里的dict.txt冲突,导致影响其他拆词。
1.下载源码
https://github.com/huaban/jieba-analysis
2.修改dict.txt文件
dict.txt文件中是按照字母顺序排序的,每一行包括分词、词频、词性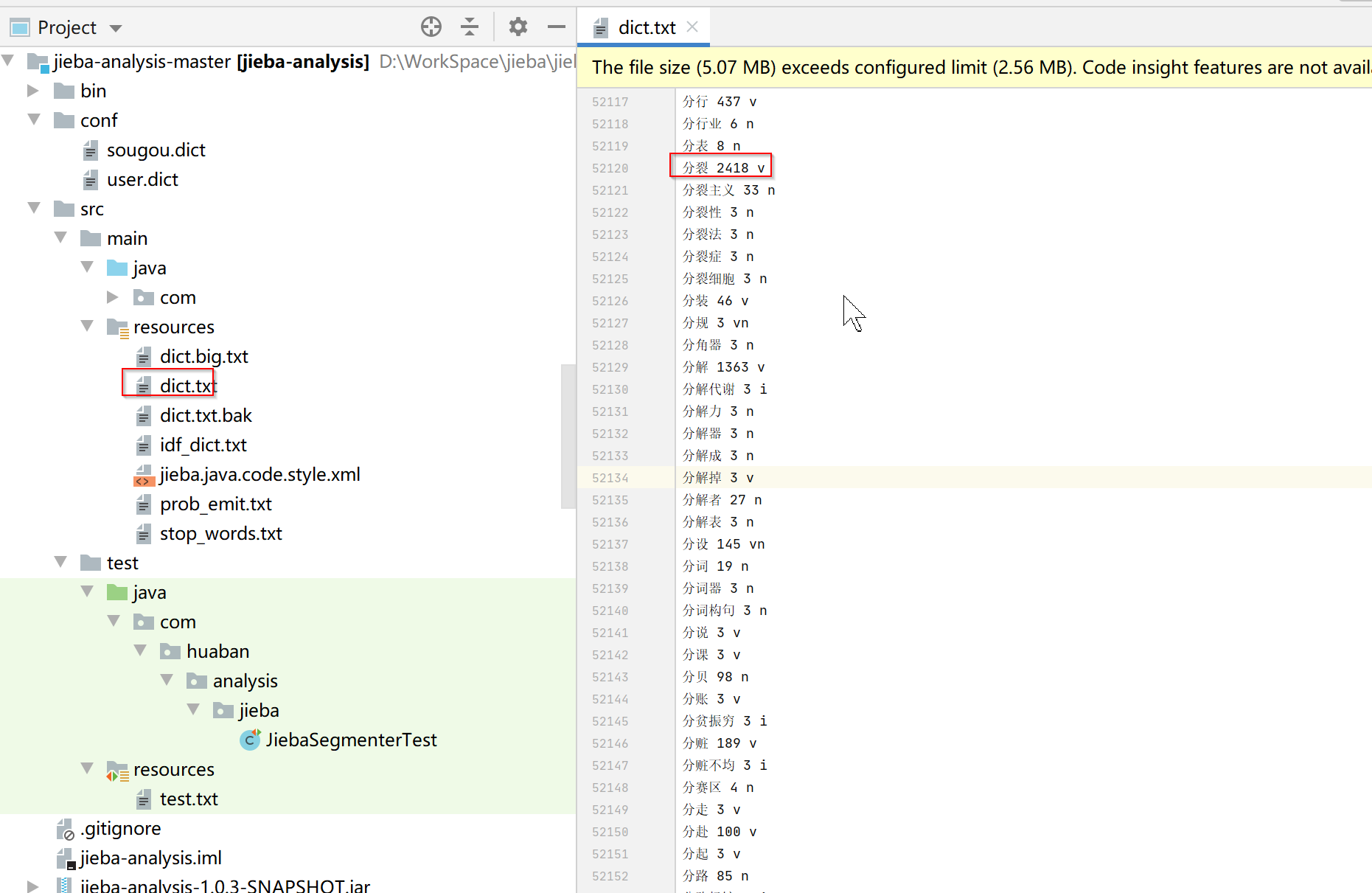
3.测试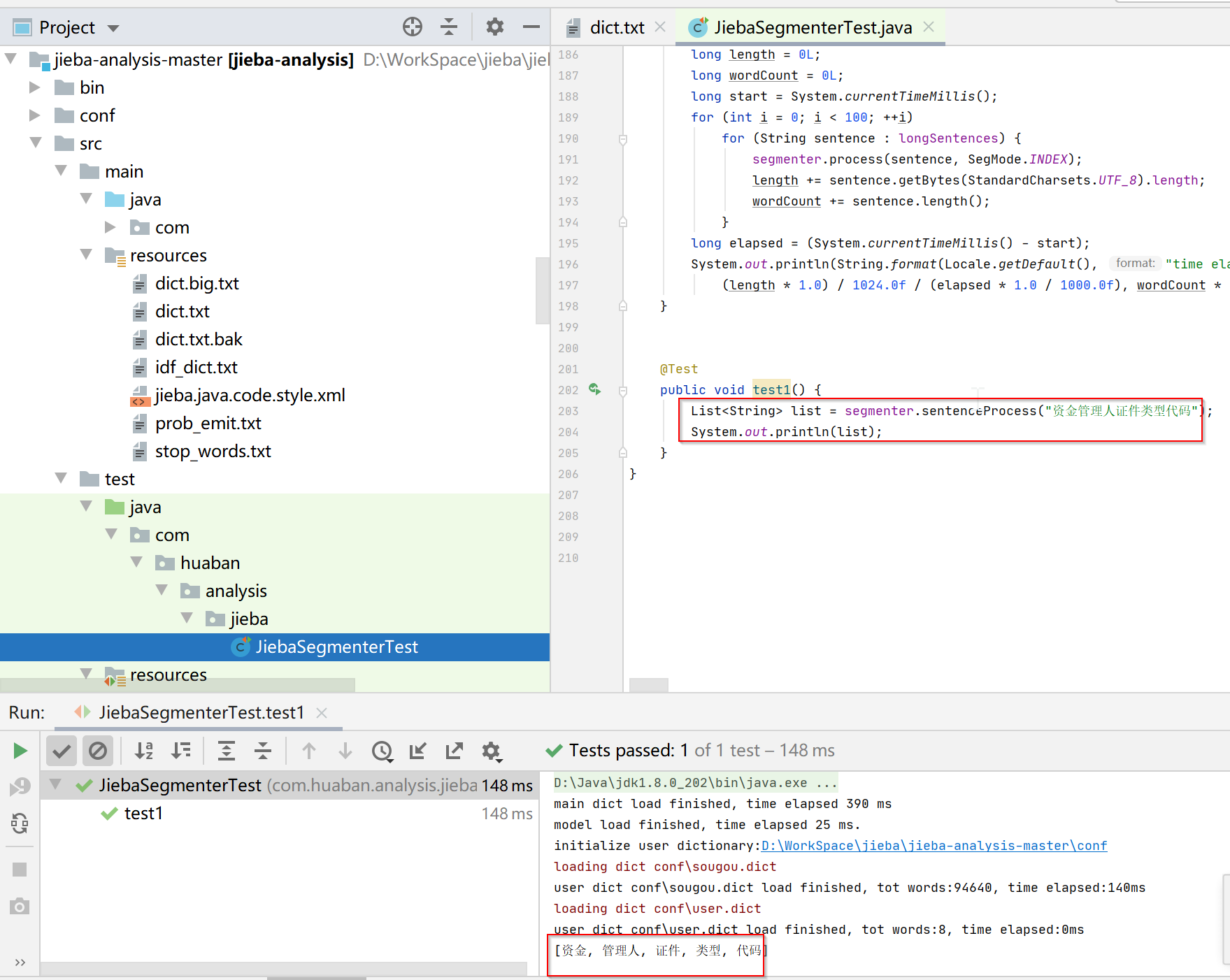
4.重新打包并引用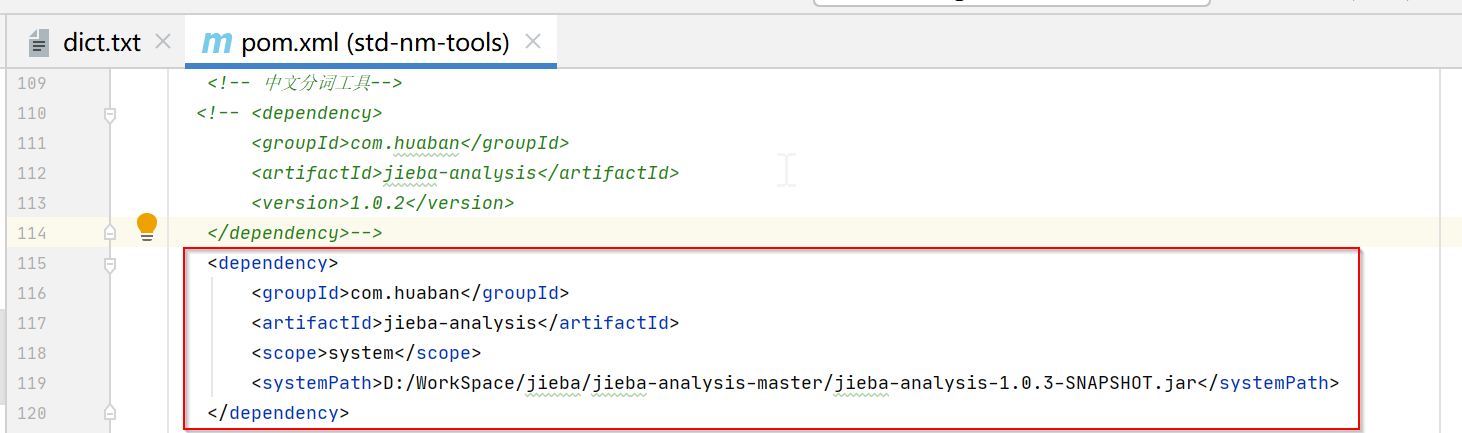
4.2、新建文件自定义拆词
resource目录下新增txt文件,通过initUserDict方法进行初始化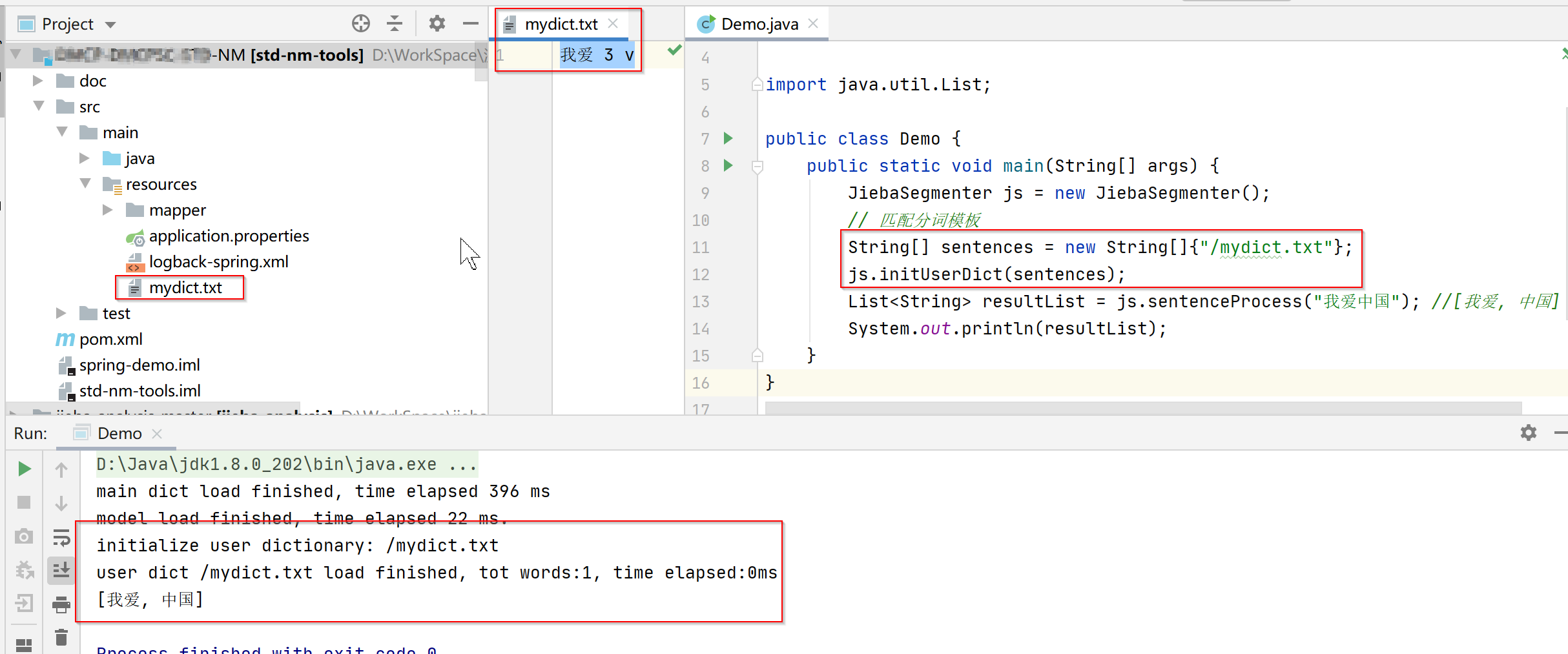
五、其他问题
- 新增或修改拆词后可能会导致其他拆词出现问题,所以有条件的最好都测试一下
本文转载自: https://blog.csdn.net/weixin_49114503/article/details/138196846
版权归原作者 五月天的尾巴 所有, 如有侵权,请联系我们删除。
版权归原作者 五月天的尾巴 所有, 如有侵权,请联系我们删除。