
走进JPA
文章目录
前言
在SpringBoot环境下使用JPA。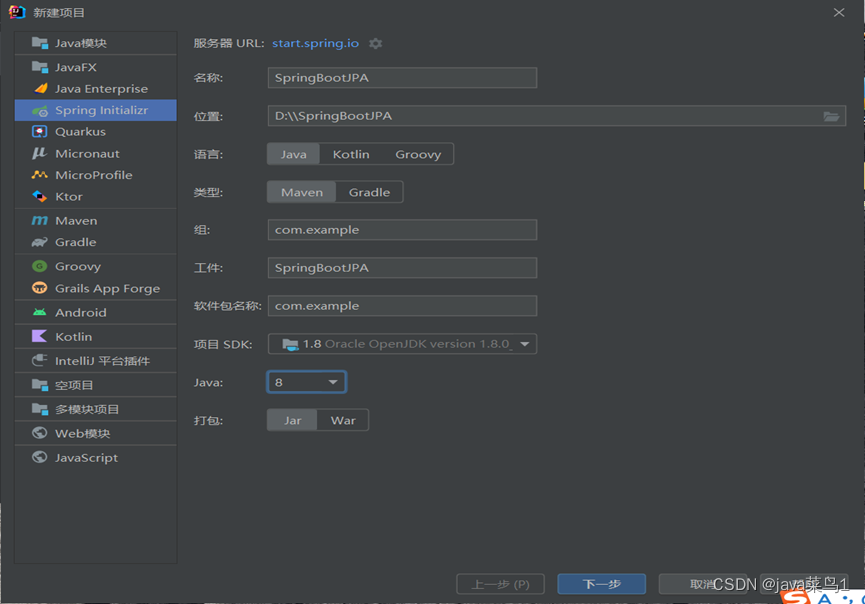
一、JPA是什么?
JPA(Java Persistence API)和JDBC类似,也是官方定义的一组接口,但是它相比传统的JDBC,它是为了实现ORM而生的,即Object-Relationl Mapping,它的作用是在关系型数据库和对象之间形成一个映射,这样,我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了。
在之前,我们使用JDBC或是Mybatis来操作数据,通过直接编写对应的SQL语句来实现数据访问,但是我们发现实际上我们在Java中大部分操作数据库的情况都是读取数据并封装为一个实体类,因此,为什么不直接将实体类直接对应到一个数据库表呢?也就是说,一张表里面有什么属性,那么我们的对象就有什么属性,所有属性跟数据库里面的字段一一对应,而读取数据时,只需要读取一行的数据并封装为我们定义好的实体类既可以,而具体的SQL语句执行,完全可以交给框架根据我们定义的映射关系去生成,不再由我们去编写,因为这些SQL实际上都是千篇一律的。
而实现JPA规范的框架一般最常用的就是
Hibernate
,它是一个重量级框架,学习难度相比Mybatis也更高一些,而SpringDataJPA也是采用Hibernate框架作为底层实现,并对其加以封装。
二、使用步骤
1.配置数据源
这里用的yml方式,里面的jpa就是数据库的名称,大家也可以写其他的,前提是这个数据库存在,用户名和密码写自己的就好。
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driver
password: wc
url: jdbc:mysql://localhost:3306/jpa
username: root
2.导入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>
3.创建实体类并通过注解方式让数据库知道我们的表长什么样
这里就可以知道表的名称是users(当然你可以任意取名),表的创建一般都有主键和自增操作,这里全部通过注解来完成。这里第一次创建表的时候表名会爆红,我们需要给他手动指定数据库,也就是数据源配置时的数据库
@Data@Entity//表示这个类是一个实体类@Table(name ="users")//对应的数据库中表名称publicclassAccount{@GeneratedValue(strategy =GenerationType.IDENTITY)//生成策略,这里配置为自增@Column(name ="id")//对应表中id这一列@Id//此属性为主键int id;@Column(name ="username")//对应表中username这一列String username;@Column(name ="password")//对应表中password这一列String password;}
这里我们还需要设置自动表定义ddl-auto
spring:jpa:#开启SQL语句执行日志信息show-sql:truehibernate:#配置为自动创建ddl-auto: create
ddl-auto
属性用于设置自动表定义,可以实现自动在数据库中为我们创建一个表,表的结构会根据我们定义的实体类决定,它有4种
- create 启动时删数据库中的表,然后创建,退出时不删除数据表
- create-drop 启动时删数据库中的表,然后创建,退出时删除数据表 如果表不存在报错
- update 如果启动时表格式不一致则更新表,原有数据保留
- validate 项目启动表结构进行校验 如果不一致则报错
4.启动测试类完成表创建(随便一个空的测试类就行)
这时候可以看到控制台打印这两句话,就会发现表已经创建成功了(和我们自己去敲命令行十分类似,hibernate帮我们完成这些操作,是不是很方便)
删表是因为选择了create策略创建表,后面还会讲其他的策略。
Hibernate: drop table if exits account
Hibernate: create table users (id integer not null auto_increment, password varchar(255), username varchar(255), primary key (id)) engine=InnoDB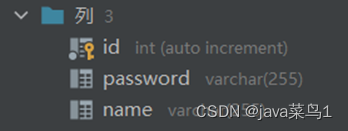
我们可以添加一条记录测试一下表
发现没有问题
5.如何访问我们的表,也就是如何对表进行操作(这里用接口自带的方法,后面会讲自定义方法)
这里我们需要自定义借口继承接口JpaRepository
@RepositorypublicinterfaceAccountRepositoryextendsJpaRepository<Account,Integer>{}
注意JpaRepository有两个泛型,前者是具体操作的对象实体,也就是对应的表,后者是ID的类型,接口中已经定义了比较常用的数据库操作。编写接口继承即可,我们可以直接注入此接口获得实现类:
这是查操作
@SpringBootTestclassJpaTestApplicationTests{@ResourceAccountRepository repository;@TestvoidcontextLoads(){//直接根据ID查找
repository.findById(1).ifPresent(System.out::println);}}
这里需要注意把create策略改成update,因为create策略会删表中数据
这是增操作
@TestvoidaddAccount(){Account account =newAccount();
account.setUsername("Admin");
account.setPassword("123456");
account = repository.save(account);//返回的结果会包含自动生成的主键值System.out.println("插入时,自动生成的主键ID为:"+account.getId());}
这是删操作
@TestvoiddeleteAccount(){
repository.deleteById(2);//根据ID删除对应记录}
这是分页操作 每页只显示一个数据 ,大家可以先多添加几条记录后再来测试
@TestvoidpageAccount(){
repository.findAll(PageRequest.of(0,1)).forEach(System.out::println);//直接分页}
自带的方法肯定不止这几个,这里就是一一举例。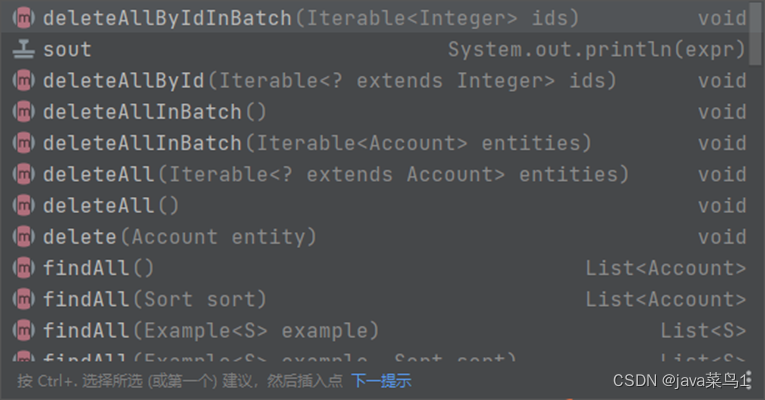
6.方法名称拼接自定义SQL语句(重点),写在接口中
6.1.模糊查询
@RepositorypublicinterfaceAccountRepositoryextendsJpaRepository<Account,Integer>{//按照表中的规则进行名称拼接,不用刻意去记,IDEA会有提示List<Account>findAllByUsernameLike(String str);}
再去测试类里测试(这里就是查名字中带有T的记录)
@Testvoidtest(){
repository.findAllByUsernameLike("%T%").forEach(System.out::println);}
6.2.同时根据用户名和ID一起查询:
optional封装就可以使用ifPresent(System.out::println),大家自由选择
@RepositorypublicinterfaceAccountRepositoryextendsJpaRepository<Account,Integer>{AccountfindByIdAndUsername(int id,String username);//可以使用Optional类进行包装,Optional<Account> findByIdAndUsername(int id, String username);}
@Testvoidtest(){System.out.println(repository.findByIdAndUsername(1,"Test"));}
6.3. 判断数据库中是否存在某个ID的用户:
这里只需要用返回布尔值就可以了
@RepositorypublicinterfaceAccountRepositoryextendsJpaRepository<Account,Integer>{booleanexistsAccountById(int id);}
@Testvoidtest(){System.out.println(repository.existsAccountByUsername("Test"));}
7.不使用方法名称拼接(自由度更高)
这里用到的?可以起到防止SQL注入的问题
7.1.改操作
//自定义SQL语句必须在事务环境下运行 必须有DML支持(Modifying) ?2表示下面的形参的第二个位置 这里不对表进行操作 直接对实体类进行操作 然后实体类映射到表中@Transactional//这个注解也可以加到测试类上面 但需要跟进一个@commit提交事务的注解 因为测试类会自动回滚事务@Modifying@Query("update Account set password=?2 where id=?1")intupdatePasswordById(int id,String newPassword);
repository.updatePasswordById(1,"123");
7.2.当然要是自定义sql语句看着不习惯,也可以使用原生sql语句,也就是对表进行操作
@Modifying@Query(value ="update account set password=?2 where name=?1",nativeQuery =true)//开启原生SQL@TransactionalintupdatePasswordByUsername(String username,String password);
repository.updatePasswordByUsername("test","123456");
8.关联查询一对一
在实际开发中,比较常见的场景还有关联查询,也就是我们会在表中添加一个外键字段,而此外键字段又指向了另一个表中的数据,当我们查询数据时,可能会需要将关联数据也一并获取,比如我们想要查询某个用户的详细信息,一般用户简略信息会单独存放一个表,而用户详细信息会单独存放在另一个表中。当然,除了用户详细信息之外,可能在某些电商平台还会有用户的购买记录、用户的购物车,交流社区中的用户帖子、用户评论等,这些都是需要根据用户信息进行关联查询的内容。
这里我们在写一个账户详细信息表并启动测试类完成表创建
@Data@Entity@Table(name ="account_details")publicclassAccountDetail{@Column(name ="id")@GeneratedValue(strategy =GenerationType.IDENTITY)//还是设置一个自增主键@Idint id;@Column(name ="address")String address;@Column(name ="email")String email;@Column(name ="phone")String phone;@Column(name ="real_name")String realName;}
再去Account实体类中添加外键
这时候再启动测试类后就会发现account表的结构已经发生改变
对象数据类型也是为了更好的插入数据,设定数据时直接当做一个对象来插入
//一对一@JoinColumn(name ="detail_id")@OneToOne//声明为一对一关系AccountDetail detail;//对象类型,也可以理解这里写哪个实体类,外键就指向哪个实体类的主键
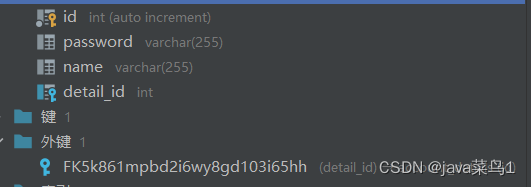
这里从日志中可以看出hibernate帮我们完成外键的创建
Hibernate: alter table users add column detail_id integer
Hibernate: create table users_detail (id integer not null auto_increment, address varchar(255), email varchar(255), phone varchar(255), real_name varchar(255), primary key (id)) engine=InnoDBHibernate: alter table users add constraint FK7gb021edkxf3mdv5bs75ni6jd foreign key (detail_id) references users_detail (id)
但这还不能完成同时对两张表进行操作
设置懒加载完成想查什么就查什么功能,设置关联级别完成同时操作两张表
@JoinColumn(name ="detail_id")@OneToOne(fetch =FetchType.LAZY, cascade =CascadeType.ALL)//设置关联操作为ALLAccountDetail detail;
这里的关联级别也是有多个,一般设置为all就行
- ALL:所有操作都进行关联操作
- PERSIST:插入操作时才进行关联操作
- REMOVE:删除操作时才进行关联操作
- MERGE:修改操作时才进行关联操作
@Transactional//懒加载属性需要在事务环境下获取,因为repository方法调用完后Session会立即关闭@TestvoidpageAccount(){
repository.findById(1).ifPresent(account ->{System.out.println(account.getUsername());//获取用户名System.out.println(account.getDetail());//获取详细信息(懒加载)});}
现在我们就可以同时添加数据和删除了
@Test//一次性添加数据到两张表中voidadd(){Account account =newAccount();
account.setUsername("Nike");
account.setPassword("123456");AccountDetail detail =newAccountDetail();
detail.setAddress("重庆市渝中区解放碑");
detail.setPhone("1234567890");
detail.setEmail("[email protected]");
detail.setRealName("张三");
account.setDetail(detail);//这里就是传入一个对象
account = repository.save(account);System.out.println("插入时,自动生成的主键ID为:"+account.getId()+",外键ID为:"+account.getDetail().getId());}
@Test//同时删除(建立在cascade = CascadeType.ALL的基础上)voiddelete(){
repository.deleteById(3);}
9.关联查询一对多(一个学生对应多个成绩),这里可以结合一对一进行操作
先创建成绩表,成绩表里设置两个外键
@Data@Entity@Table(name ="account_score")publicclass score {@GeneratedValue(strategy =GenerationType.IDENTITY)//成绩表,注意只存成绩,不存学科信息,学科信息id做外键@Column(name ="id")@Idint id;@OneToOne//一对一对应到学科表Subject上@JoinColumn(name ="cid")Subject subject;@Column(name ="score")double score;@Column(name ="uid")//哪个学生int uid;}

现在去表中插入数据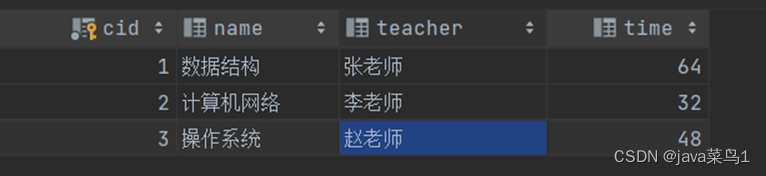
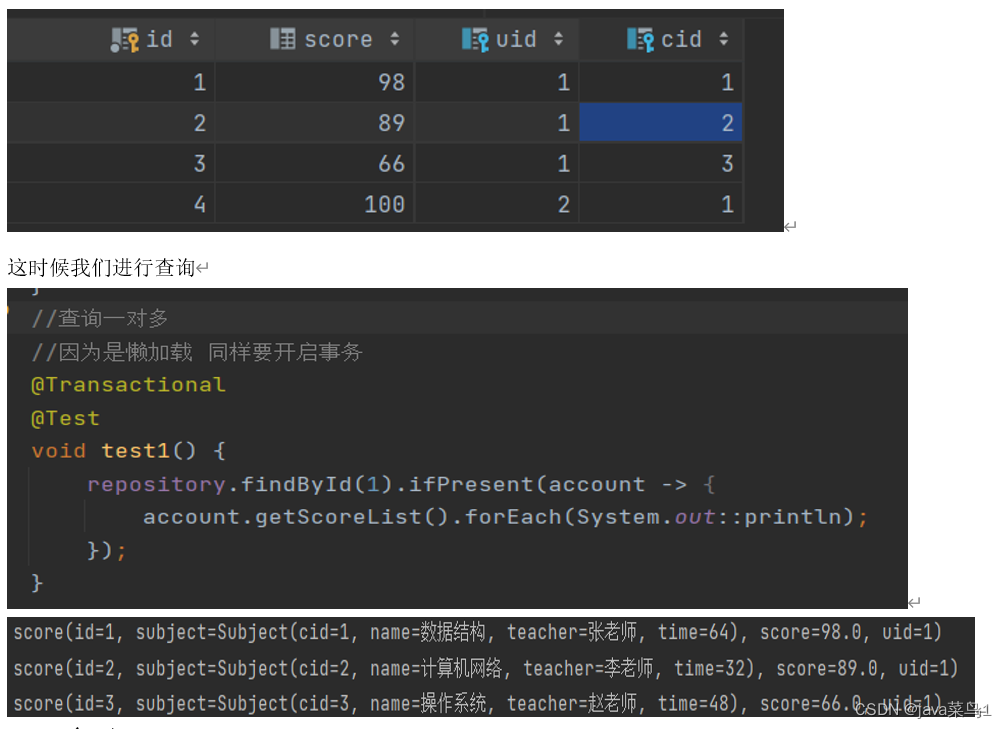
可以看到数据已经被查询出来
三、总结
以上就是今天要讲的内容,本文仅仅简单介绍了jpa的常用方法,而jpa还提供了大量能使我们快速便捷地处理数据的方法,就留给大家自己去探索吧。
官网:https://spring.io/projects/spring-data-jpa
版权归原作者 java菜鸟1 所有, 如有侵权,请联系我们删除。