
这是2020年VCIP的一篇论文:灵感来自EDSR,以帧内预测信号作为附加输入,Y,U和V分量的平均BD速率增益分别为6.7%,12.6%和14.5%。
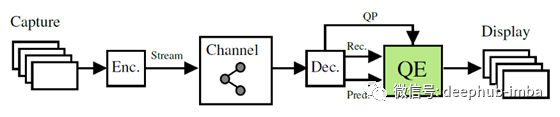
在篇文章中,我们将简单的介绍Nasiri VCIP ' 20的一篇论文使用CNN (VVC滤波)提高VVC的预测感知质量,它主要包括以下两个方面
- 卷积神经网络(CNN)提高VVC编码帧解码后的质量,以减少低比特率伪影。
- 同时利用帧内的预测信息进行训练。
帧内编码和压缩伪像之间的关系和动机

VVC中有67种帧内预测模式(IPM),代表65个角度IPM,以及DC和平面。
- 严格的比特率约束可能会导致一种情况,即最佳IPM(最小化块的R-D成本)不一定是最准确地对块纹理进行建模的IPM。
- 从上面的示例可以看出,尽管这两个IPM具有相似的R-D成本,但它们会产生非常不同的重构信号,并具有不同类型的压缩损耗模式。
这种行为是由于所选模式的两种不同的R-D权衡造成的。
一个块、帧或整个序列的质量增强(QE)任务可能会受到编码器决定的不同编码模式(如IPM)选择的显著影响。
这一假设是本论文的主要动机,以使用内部预测信息的训练质量增强网络。
提出网络体系结构
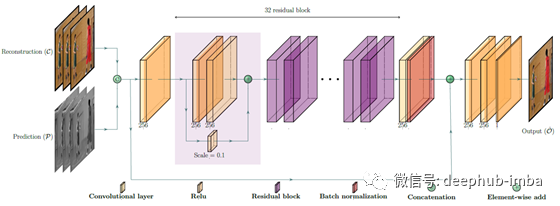
该网络的灵感来自EDSR。
第一卷积层接收重构C和预测帧P作为拼接输入。

- 在一个卷积层之后,使用32个相同的残差块(ResNet),每个残差块由两个卷积层组成,中间有一个ReLU层。
- 批处理规范化应用于残差块之后。
- 在第一个和最后一个残差块的输入之间使用长跳过连接。
- 在使用残差块之后,再增加两个卷积层。
- 最后一个卷积层有一个特征映射,它构造了输出帧^O。
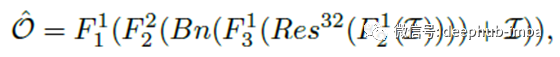
其中F1()和F2()是3×3×256卷积层,分别带有和不带有ReLU激活层。
F3()是一个带有ReLU的3×3×1卷积层。
相对于原始帧O的L2范数用作训练阶段的成本函数:
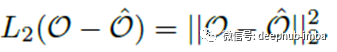
使用上述网络体系结构,可以训练不同QP中每个组件的一个网络。
使用DIV2K和Flickr2K的两个图像数据集进行训练。
VTM-5.0用于全内部配置,使用6个QP(介于22和47之间)。
使用64×64补丁,最小训练批次为32个。
训练结束时,针对6个QP中的3个组件,共获得了36个受过训练的模型。
实验结果

- 在CTC QP范围内,该方法在Y、U和V分量上的平均bd速率增益分别为6.7%、12.6%和14.5%。
- 在Y、U和V分量上,有预测信号的方法比没有预测信号的方法分别高出0.9%、8.1%和4.8%。
- 与其他两种JVET解决方案相比,所提出的方法有显著的提高。
- 在伪影明显较强的高QP范围内,该方法在Y、U和V分量上的平均bd速率增益分别为8.3%、15.8%和16.2%。
- 对于U和v来说,使用预测信号所获得的BD-rate增益相对较高,这是因为VVC中有高级的色度编码工具来利用冗余。这些工具的例子有色度缩放的色度映射(LMCS)、联合Cb-Cr残差编码(JCCR)、交叉组件线性建模(CCLM)和一种称为色度派生模式(DM)的特定色度IPM。
最后论文地址:
[VCIP 20] Prediction-Aware Quality Enhancement of VVC Using CNN (使用CNN对VVC进行预测感知的质量增强)
作者:Sik-Ho Tsang