
前言
前段时间需要在树莓派上部署一个深度学习环境,先试了YoloV5,fs基本才0.3,远远达不到要求,于是就尝试了一下轻量化网络,试过mobileNet系列+YoloV4,fps有所提升,大概能达到0.9左右,但还是比较慢,于是就发现了YoloV5-Lite这个轻量化网络,极大地加速了fps,基本能达到3左右,因此详细了解了一下YoloV5-Lite网络,在这写一篇博客记录一下学习成果,有讲的不对的地方还望大家批评指正!!!
一、YoloV5概述
yolov5的网络结构图如下图所示: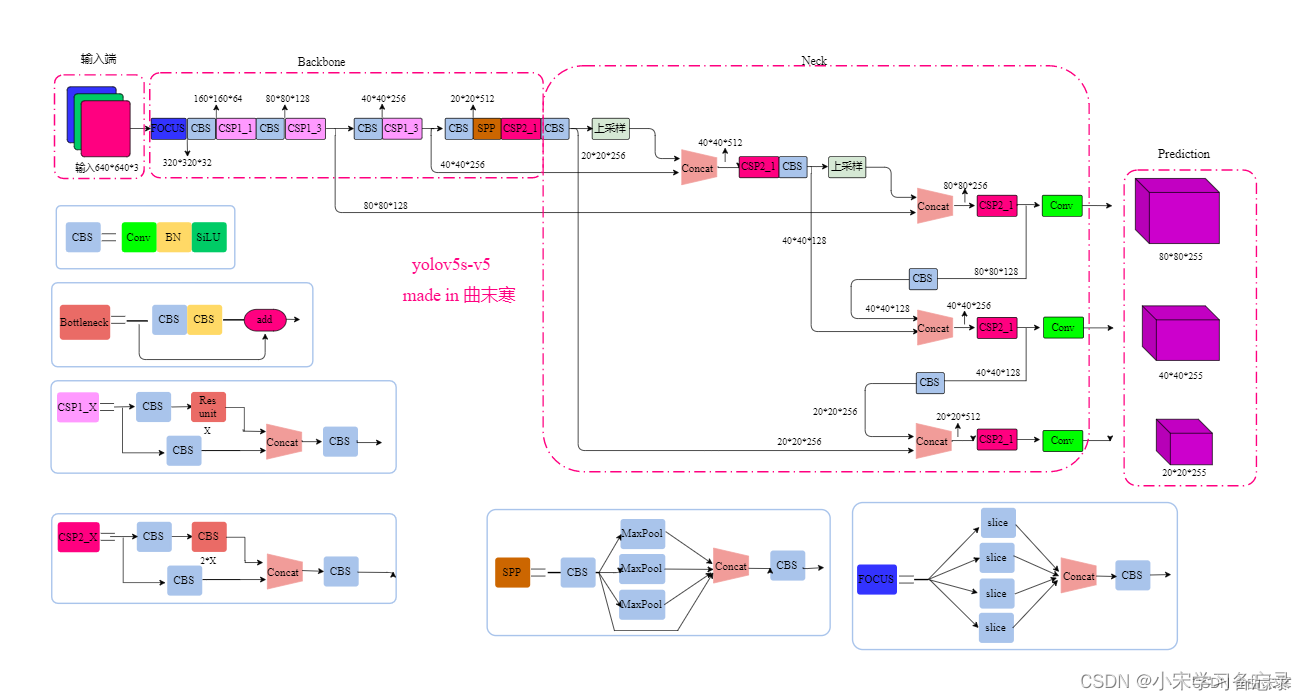
图1 yoloV5-5.0网络结构图
yolov5整体结构分为Input,Backbone、Neck、Prediction network(Head)四个部分,其亮点有如下:
(1)输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction network:GIOU Loss
** **再者,作者也加入了新的模块:
1. Focus模块
focus模块是一种用来加速特征提取的模块,其主要作用是将输入的特征图进行分组处理,以减少计算量和提高模型效率。focus模块通常用于替代传统的下采样操作(如池化或步长卷积),以更有效地捕获多尺度的信息。focus模块可以帮助模型更好地处理不同尺度的特征信息,提高目标检测的准确性和效率。
首先focus模块通常由两部分组成,即切片(Slice)和连接(Concatenate)操作,如图2所示。在切片操作中,输入的特征图被水平或垂直分割成多个子特征图,然后这些子特征图经过一系列的卷积操作后再通过连接操作合并为一个输出特征图。
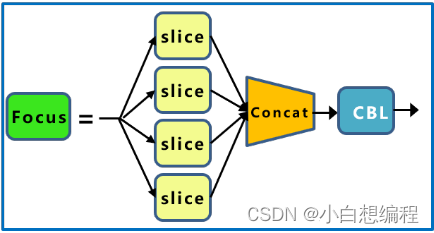
图2 Focus层
通过在输入特征图上进行分组处理,focus模块可以显著减少计算量,因为每个子特征图的尺寸较小,从而降低了计算复杂度。并且有助于捕获不同尺度的信息,使模型更具鲁棒性,能够更好地适应不同大小和形状的目标。
以yolov5为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下:
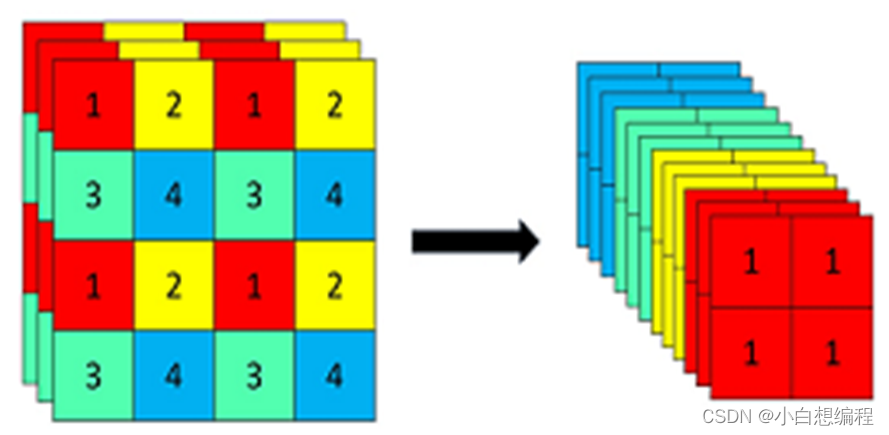
图3 Focus原理
具体的代码实现如下:
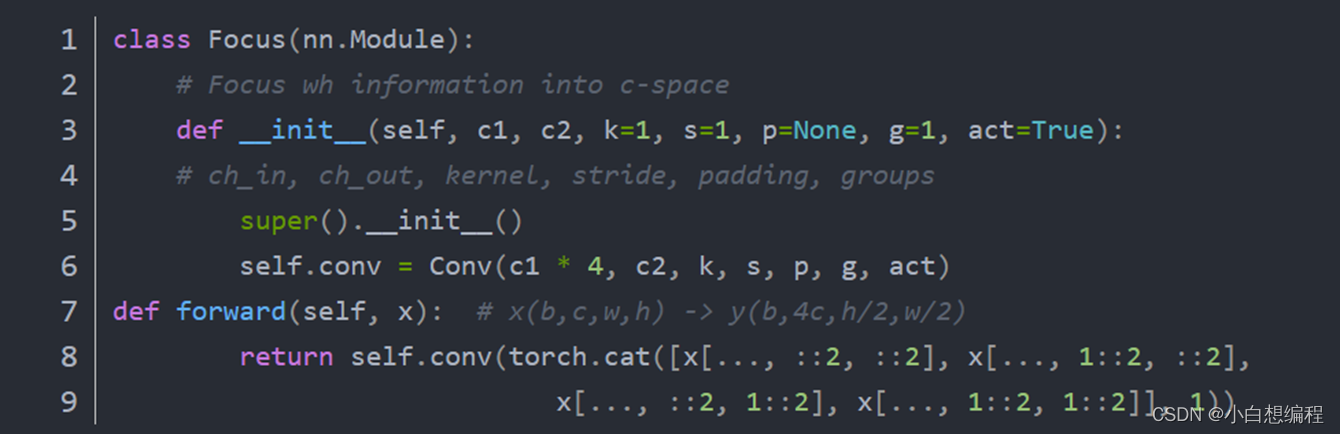
图4 Focus层代码实现
从代码中可以看出,在切片完成后,进行了concat操作,使每个slice切片的合并成一个,然后经过卷积操作最终得到需要的输出。
-------补充:concat是通道数的增加,也就是说描述图像本身的特征数(通道数)增加了,而每一特征下的信息是没有增加;横向或纵向空间上的叠加。相当于把每个块堆叠起来,只增加特征的通道数,而不会对图像特征本身做改变。
2. CSP1_X and CSP2_X
CSP1_X和CSP2_X的网络结构图如下所示:


图5 C3层
CSP1_X 由 CSPNet演变而来,该模块由 CBL 模块、Res unit、Conv、还有 Concate组成,其中X代表有X个这个模块。CSP2_X 也是由 CSPNet网络组成,该模块由 Conv 和 X个 CBL模块而成。这个也被称为C3模块,3的含义是它有三个卷积层。
如下图,C3模块输入为BCHW,左右两路分别通过卷积后,通道数变为原来的一半,因为c=C/2,然后右路又经过BottleNeck层,在BottleNet层中,有两种形式,BottleNet1就是类似于Resnet先做两次卷积操作后,然后做了add操作。BottleNet2直接进行两次卷积。不管是哪种形式,因为是卷积核的大小是1x1,而且c=c,所以输入和输出是一样的。
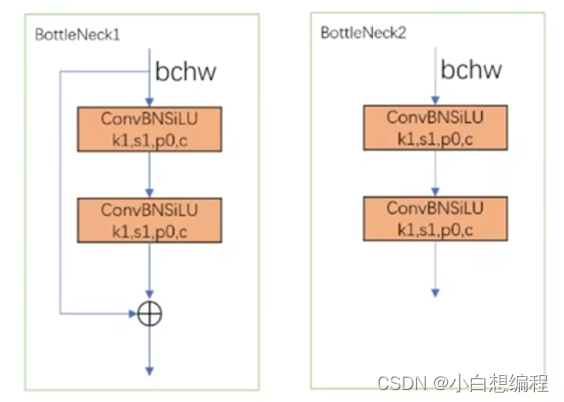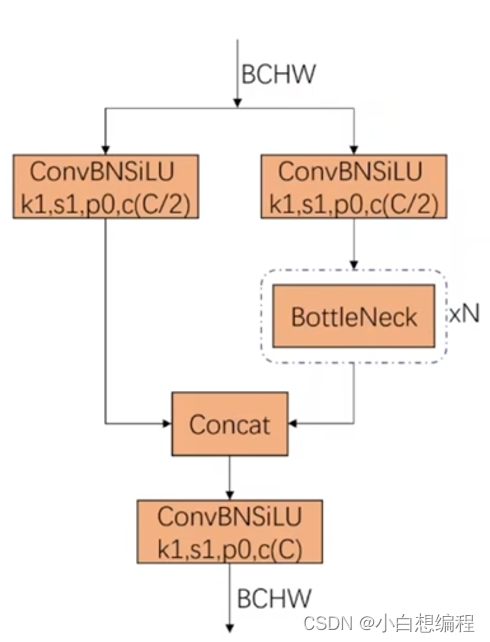
图6 C3模块
在BottleNet层结束后,进行一次concat操作,使得通道数翻倍,最终实现了输入的BCHW等于输出的BCHW。这里补充一下,add操作和concat操作的区别:
(1)concat是通道数的增加,也就是说描述图像本身的特征数(通道数)增加了,而每一特征下的信息是没有增加;横向或纵向空间上的叠加
(2)add为简单的像素叠加,是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加
如下图:

图7 concat和add
add只是对两张图上的特征点进行了 操作,改变了图像的像素点对应的特征;而concat单纯的是一种堆叠行为,把两个输入堆叠成一个,因此输出图像的通道数会翻倍。
3. SPP层
在 YOLOv5 中,SPP(Spatial Pyramid Pooling)层是一种用于增强目标检测网络性能的关键技术。SPP 层的主要作用是在不同尺度上对输入特征图进行空间金字塔池化操作,从而使网络能够更好地捕获多尺度的信息,提高检测精度。
SPP 层的作用是通过空间金字塔池化操作,从不同尺度下提取特征,使得网络可以在不同尺度上对目标进行检测,提高检测性能。SPP 层的结构包括一个金字塔池化层和一个全连接层,如下图所示。金字塔池化层将输入特征图分别进行不同尺度的池化操作,例如最大池化,然后将这些不同尺度的特征图连接在一起。全连接层通常用于减少维度并提取更高级的特征。
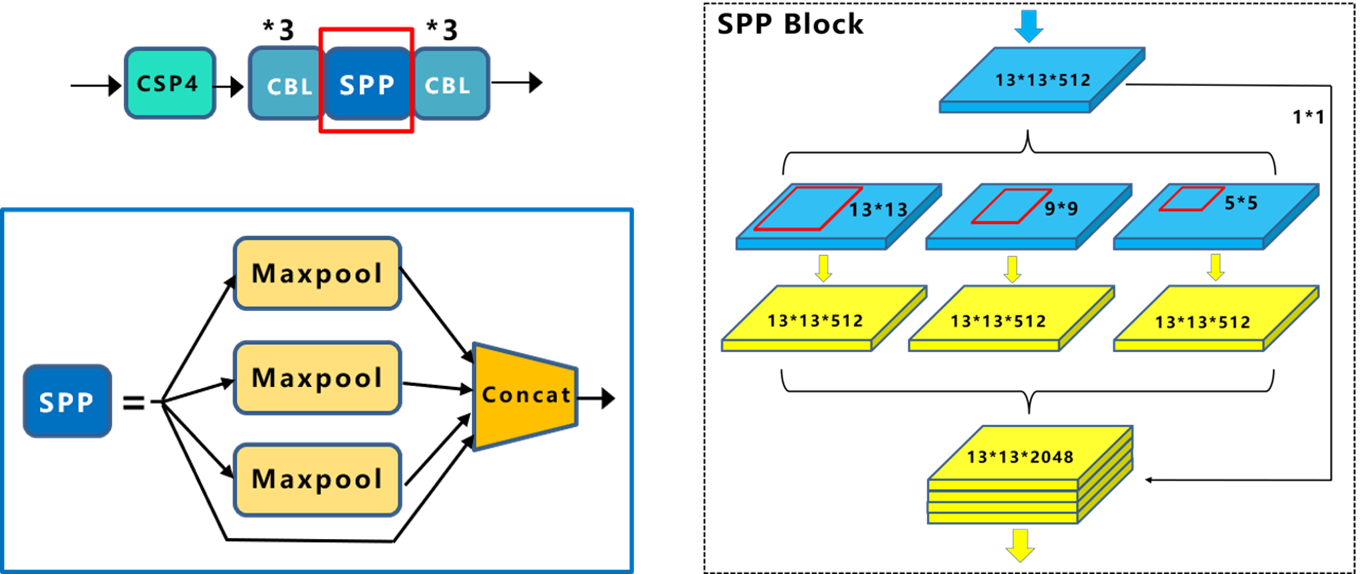
图8 SPP层
- 多尺度特征:通过 SPP 层,网络可以在不同的感受野下提取特征,从而克服固定感受野大小的限制,提高模型对各种尺度目标的检测能力。
- 减少参数量:SPP 层可以减少网络参数数量,因为它可以在不同尺度上共享权重,从而减少模型的复杂度。
- 适用性:SPP 层通常应用在深度卷积神经网络中,特别是在目标检测任务中,以提高检测准确性和多尺度检测性能。
总的来说,SPP 层在 YOLOv5 中被广泛应用,通过空间金字塔池化操作,有助于增强网络对多尺度信息的敏感性,提高目标检测的精度和鲁棒性。
YoloV5的部分细节就讲完啦,更多细节不再做过多赘述,因为我们的主题是yolov5-Lite
二、YoloV5-Lite概述
yoloV5-Lite是国内大佬ppogg在2021年做毕设消融实验创造出来的,源码地址:https://github.com/ppogg/YOLOv5-Lite,前言中也讲过,我也对比过其他轻量化网络,速度兼容精度yolov5-Lite是最好的,当然也只针对于我的项目,项目目标检测任务比较简单,类别数只有两个,且数据集不够庞大,因此yolov5-Lite是很适合数据集不足、类别数不多的情况的,而且ppogg的初衷就是能够部署在树莓派这种算力很低的设备上。下面先上图(本来想白嫖,找了一圈,只有一篇博文有图,但是有很多错误,因此自己画了一个):
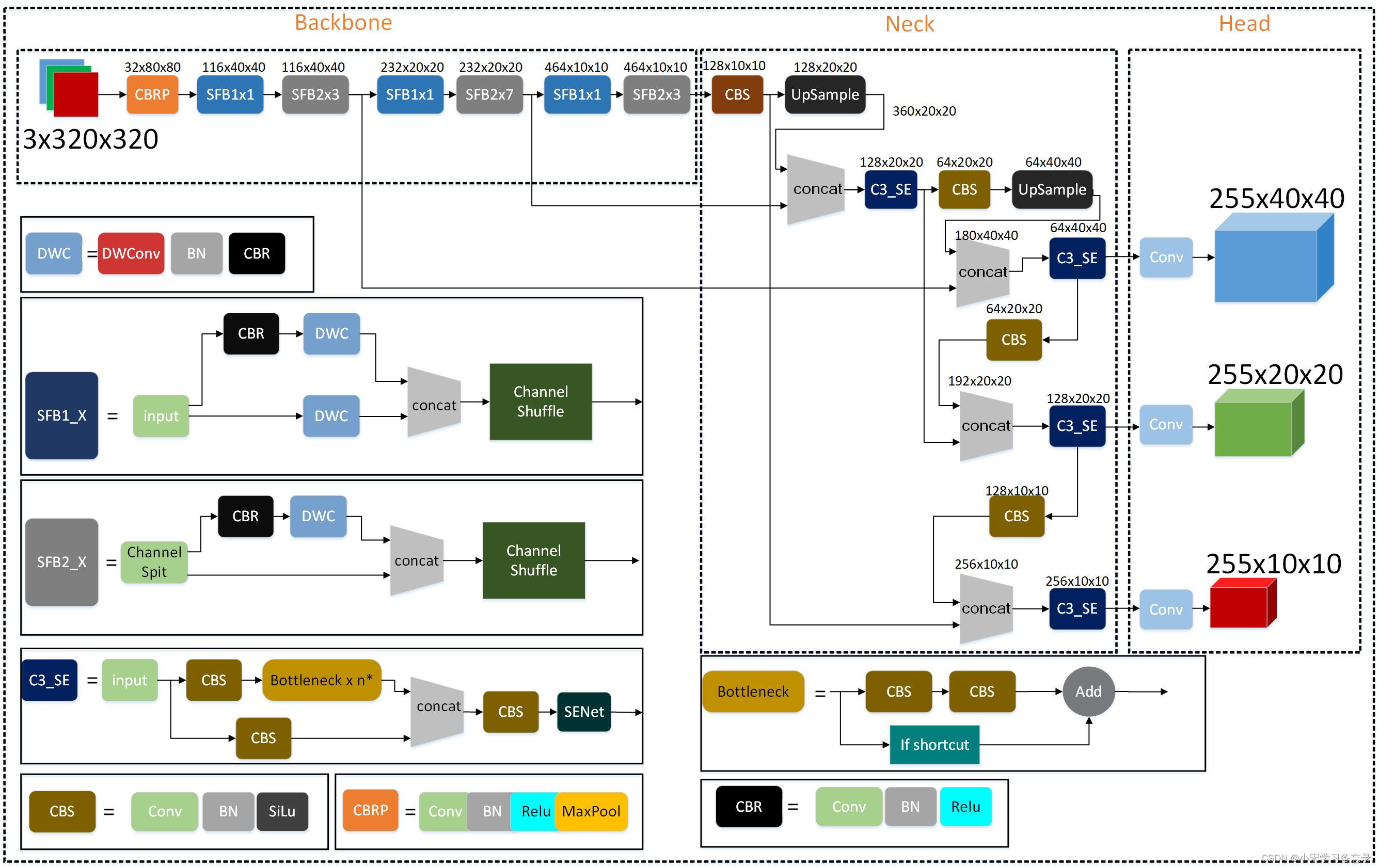
图9 Yolov5-Lite网络结构图
从图中可看到,整体结构和yolov5是差不多的,最主要的是引入了ShuffleNetV2网络,极大地减少了计算量和参数。还有摘除了很多的C3层,减少了C3层的使用,因此整体速度有很大的提升。在讲解YoloV5-Lite整体结构前,先需要了解什么是ShuffleNetV2,因此从这里先讲起。
2.1 ShuffleNetV1

图10 ShuffleNetV1论文
ShuffleNetV1 是由国产旷视科技团队在 2017年提出的,其原始论文为 ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices。ShuffleNetV1 主要在于**提出了 ****Channel Shuffle ****的思想**,shuffleNet Unit 中全是 Group Conv以及 DW Conv。 其核心网络结构图如下:
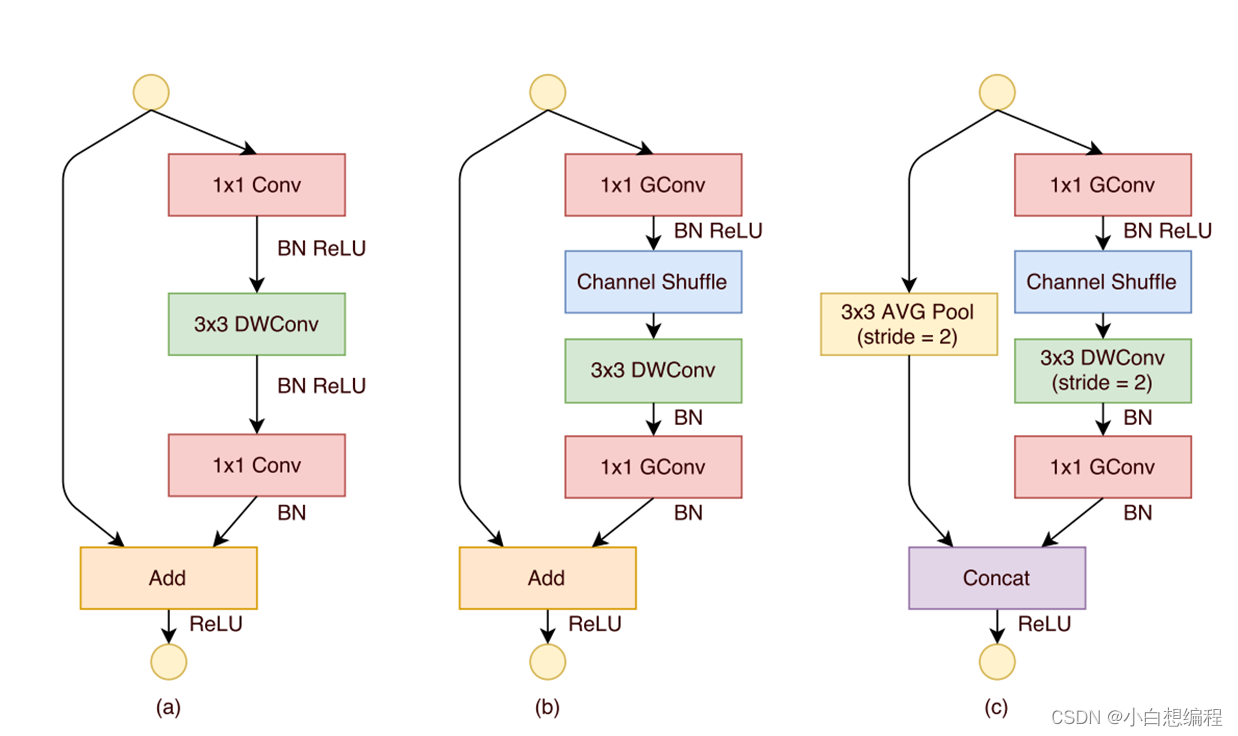
图11 ShuffleNetV1网络模块
图中(a)图为ResNet的网络结构图,(b)和(c)为ShuffleNetV1的两个模块,可以看出,作者是基于ResNet做了相关改进,下面就一一介绍:
2.1.1 channnel Shuffle思想
在介绍Channel Shuffle思想前,先讲一下什么是组卷积?什么是深度卷积? 组卷积是将输入通道分成若干组,在每一组内进行卷积操作,并将每组的输出连接起来。用图解更容易理解,如下图:
图12 组卷积&深度卷积示意图
对于常规卷积,假设输入的卷积核大小为kxk,Channel为n,经过卷积后,输出的参数量为**k*k*Cin*n** ;而分组卷积是将输入分为g组,那么卷积核的Channel也会被分为g组,那每组对应输出的卷积参数为多少呢?就是**k*k*Cin/g*n/g**,对g组进行concat拼接,通道数就变为原来的g倍,那对应的输出需要的参数就是**(k*k*Cin/g*n/g)*g**,化简之后就是**k*k*Cin*n*1/g**,可以看到,对比常规卷积,参数量变为了原来的1/g。 当Cin=g,n=Cin时,就是**DW卷积**。
在普及完了什么是组卷积后,我们就可以看看论文中的亮点,Channnel Shuffle思想, 如下图如: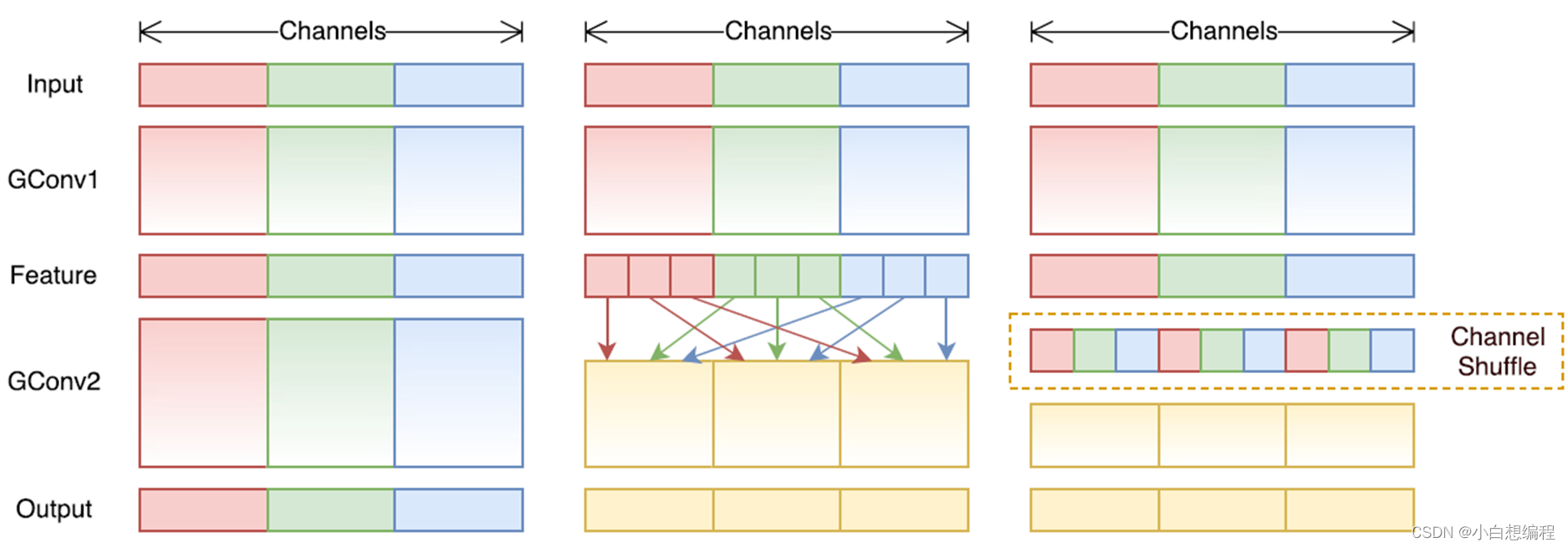
图13 channel shuffle示意图
Channel Shuffle的提出是因为作者在论文中说到:

图14 ShuffleNetV1论文节选
大致意思就是通过GConv之后,每个组之间是没有信息交互的,因此如果经过多次卷积后, 组与组之间的连接会越来越弱,这显然是我们不想看到的,因此,作者就创造了Channel Shuffle思想,Channel Shuffle是指在深度神经网络中对通道(channel)进行重新排列的一种思想。大致实现就是:假设卷积层有g组,输出有g×n个通道,先将输出通道维数reshape为(g,n),转置,展平,作为下一层的输入(即使两个卷积的组数不同,操作依然有效),下图摘自大佬同济子豪兄,我觉得画的很清晰明了,表达了Channel Shuffle的核心思想。
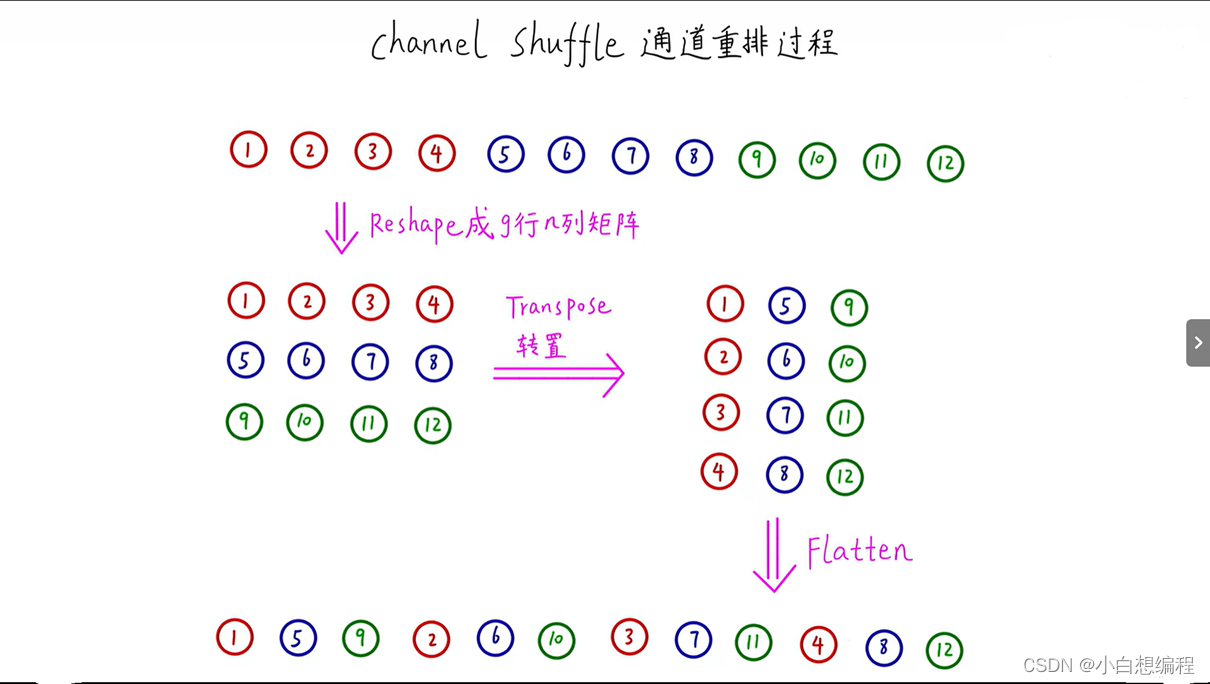
图15 Channel Shuffle流程图
2.1.2 ShuffleNetV1网络构架
作者在论文中提到:如下图
 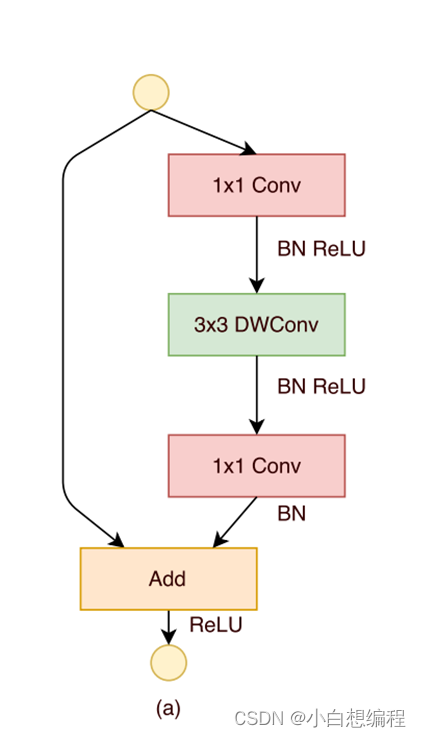
图16 Resnet网络结构图
标蓝的部分写到,通过结果,我们发现常规的1x1卷积占据了93.4%的内存量,而我们网络中的分组卷积(DWConv)只占了很小的一部分,所以作者就改进了Resnet后,网络结构为:
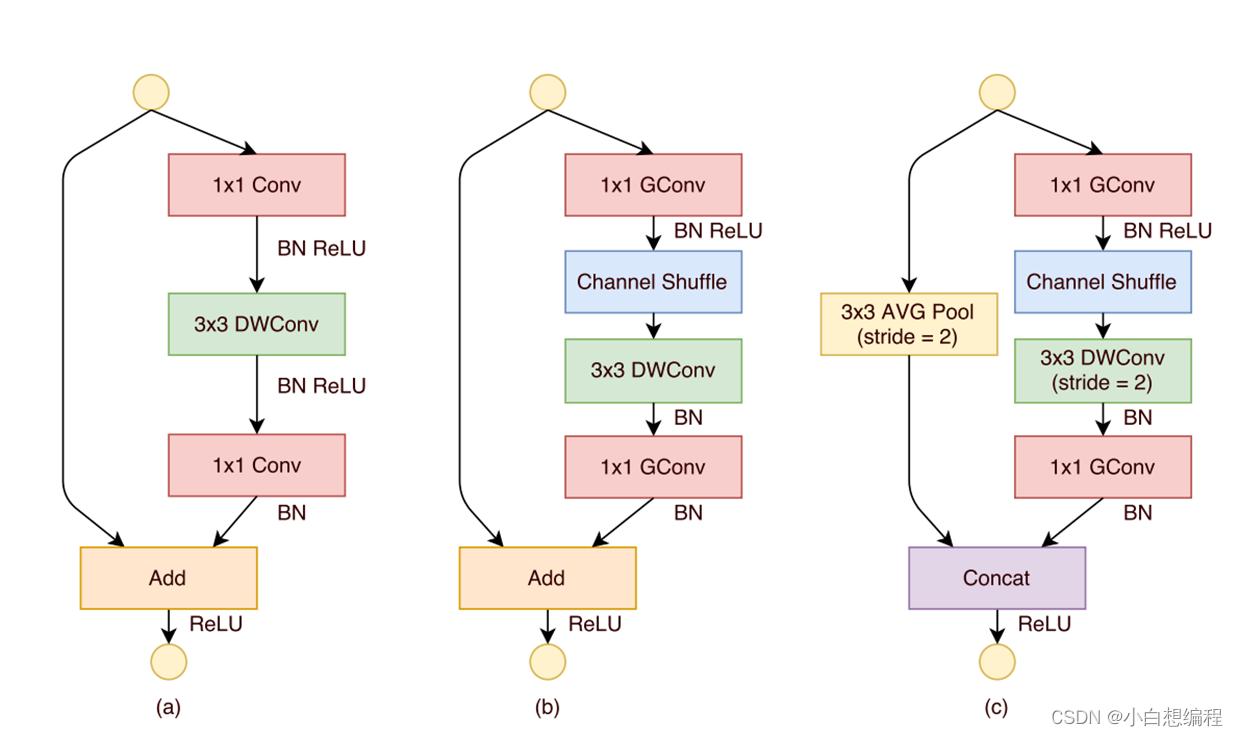
图17 ShuffleNetV1结构图
图中,(a)图为Resnet网络结构图,(b)和(c)为改进后的ShuffleNetV1网络结构图,可以看出作者将1x1的常规卷积换成了 GConv,而且在第一个GConv后又加入了Channel Shuffle操作,(b)和(c)的区别就是(c)中先做了下采样,再concat拼接后保持输入和输出是相同的。
下图就是ShuffleNetV1的结构设计:
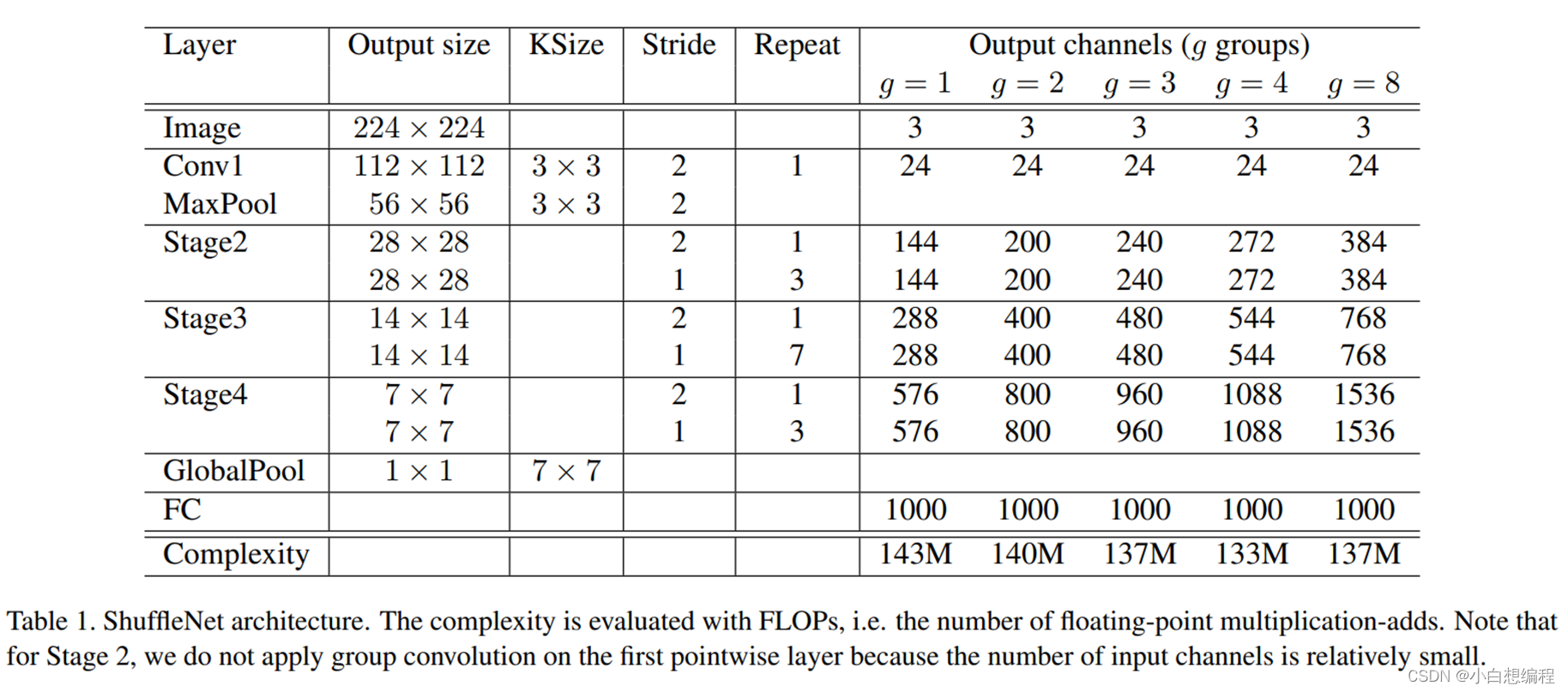
图18 ShuffleNetV1结构设计图
从图中可以看出,作者首先对输入进行了卷积和最大池化,进行下采样,输入尺寸变为原来的1/4,在进行一次步长为2的block,然后3次步长为1的block,重复操作,最后通过一个全局池化和全连接层输出特征。论文中还提到了一些注意点,首先就是图18说明最后面一段话:
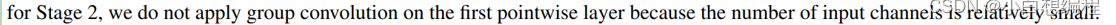
图19 ShuffleNetV1论文相关
这句话的意思就是对于第一个stage2的第一个卷积,我们不进行组卷积操作,而是使用常规卷积Conv,因为第一个stage2的输入Channel只有24,没必要进行组卷积,组卷积的作用之前也讲过就是对不同通道进行融合从而打乱数据,但是如果通道数相对过少,就不用使用。
其二就是作者在这段话中提到:
图20 ShuffleNetV1论文相关
第一个block也就是图17的(b)中,作者引用了resnet的思想,在第一个组卷积和第二个组卷积中使用了input/4的Channel大小,最后一个组卷积恢复为input大小的Channel,最终输出不变。对应网络设计图中,如果需要搭建网络的话,就要注意stage2中stride=1的block中第一个和第二个卷积是240/4,也就是Channel数为60。
最后,我们看一下作者对比resnet、resnext和ShuffleNetV1的FLOPs比较:

图21 ShuffleNetV1论文相关
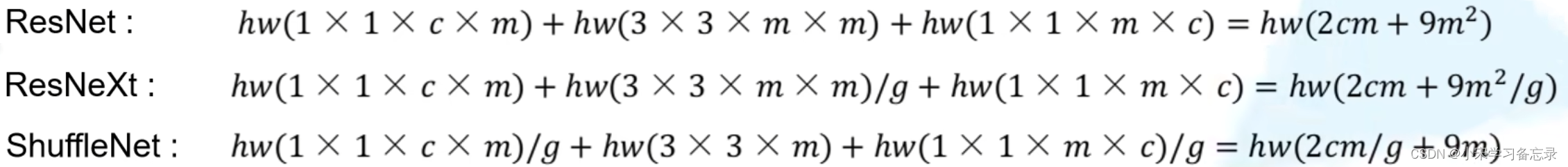
图22 三者FLOPs对比
显而易见,ShuffleNetV1的FLOPs是小了很多的。
**----------------小提示:关于FLOPs **


图23 FLOPs
2.2 ShuffleNetV2

图24 ShuffleNetV2论文
ShuffleNetV2,它是由旷视科技团队在 2018 年提出的,原论文发表在ECCV上。在同等复杂度下,ShuffleNetV2比ShuffleNetV1和MobileNetv2更准确。这篇论文除了提出这个**全新的轻量化网络结构**以外,还创新性地提出**四个重要的实用性原则**,并通过实验证明其准确性。
2.2.1 ShuffleNetV2网络结构图
ShuffleNetV2的网络结构图如下所示
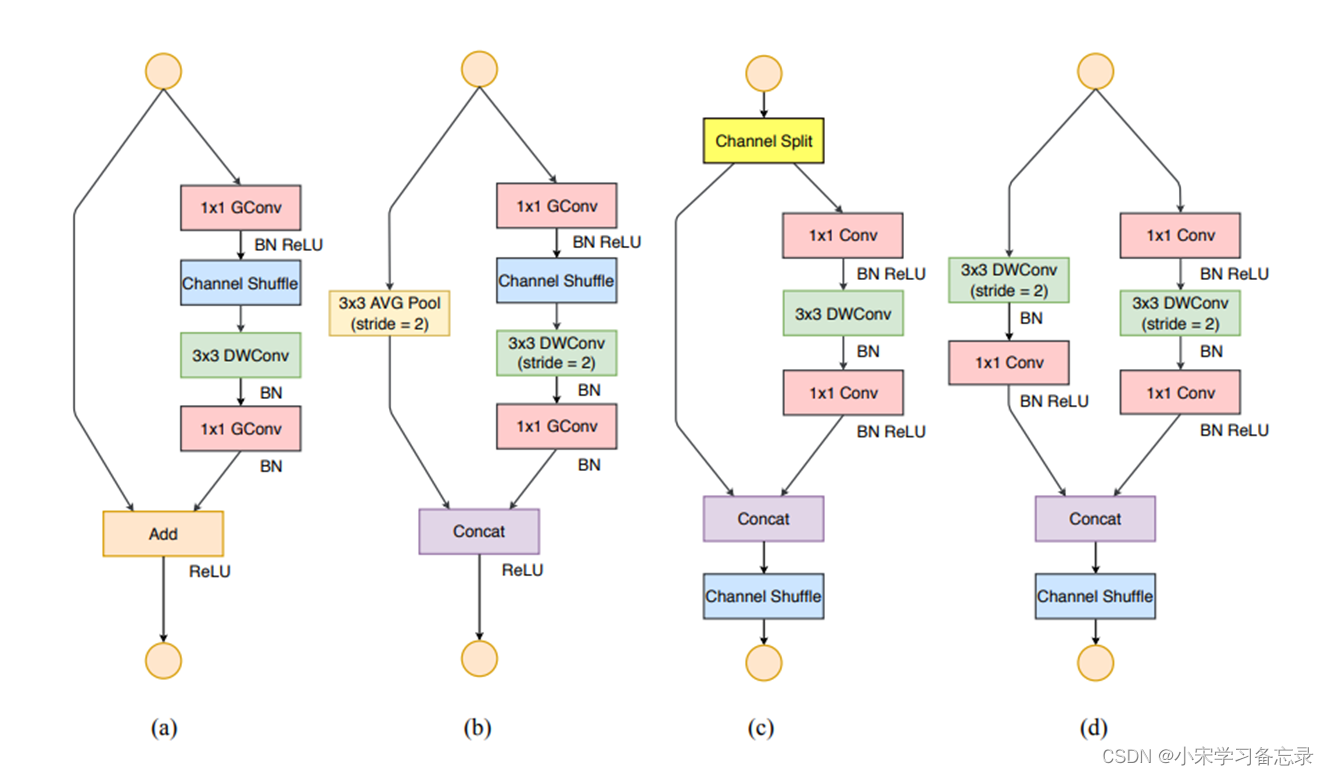
图25 ShuffleNetV2网络结构图
图中(a)和(b)为ShuffleNetV1的block,(c)和(d)为ShuffleNetV2的block,可以看出作者还是做了很多改进的,其中分支结构没有变化,(a)和(c)的区别是:①引入了Channel spit(后面会讲);②将1x1GConv的组卷积换作1x1Conv的常规卷积;③将Channel Shuffle移到了最后一步;④concat操作取代and操作 。(b)和(d)的区别是:①将3x3平均池化换作3x3的深度卷积再接一个1x1的常规卷积;②将1x1GConv的组卷积换作1x1Conv的常规卷积;③将Channel Shuffle移到了最后一步;④将Relu操作移到了最后一个Conv层后面,而并非输出的最后面。那作者为什么要这么操作呢,这就和作者提出的四条高效设计网络准则有关了。。。
2.2.2 四条高效设计网络准则
作者在文章中提到:

图26 ShuffleNetV2论文
这两段话总结下来的意思就是:
第一:应该用直接指标(例如速度)替换间接指标
第二:这些指标应该在目标平台上进行
基于以上,作者提出了矿石横空的四条硬核高效设计网络准则:
 图27 四条高效设计网络准则
图27 四条高效设计网络准则
G1) Equal channel width minimizes memory access cost (MAC)
** 相同通道宽度能够最小化MAC(内存访问成本)**
** ** 作者在前面也说了,衡量网络的指标不能只看FLOPs,而是应该把MAC考虑进去,因此作者给出了如下的不等式:
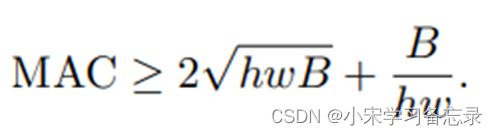
图28 MAC不等式
其中,MAC=hw(c1+c2)+c1c2 ,我们可以把它看成三项,其中第一项为hwc1,因为输入的长宽为hw,通道数为c1,所以mac就为这个,输出同理,那后面的c1c2如何理解呢,这对应的是卷积核的参数消耗,因为对于1x1的卷积核,hw就是1,所以mac为c1c2。公式中B=hwc1*c2,也就是我们的FLOPs;
那为啥会有这个不等式呢,是根据均值不等式演变而来的,即(c1+c2)/2 ≥ c1c2,带入得
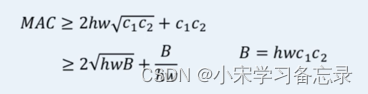
图29 MAC不等式
那不等式相等条件是什么呢,即c1等于c2的时候,所以这也就直接的印证了G1准则。那么,实践是检验真理的唯一标准,作者通过做对比实验,如下图:
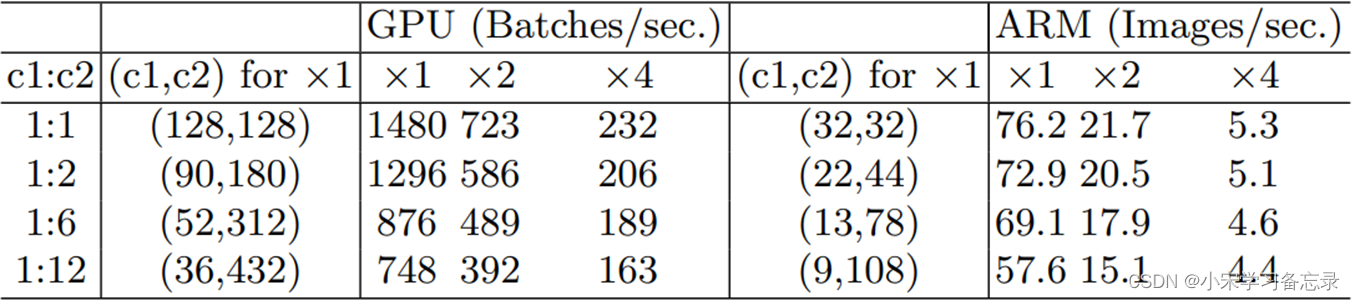
图30 C1:C2对比实验图
通过对比实验我们发现,当c1与c2的比值越来越大,不论是在GPU还是在CPU,推理速度都是越来越慢的。
G2) Excessive group convolution increases MAC
** 过度的组卷积会增加 MAC**
万变不离MAC,如果将1x1常规卷积变为组卷积GConv,那MAC为多少呢,如下图:
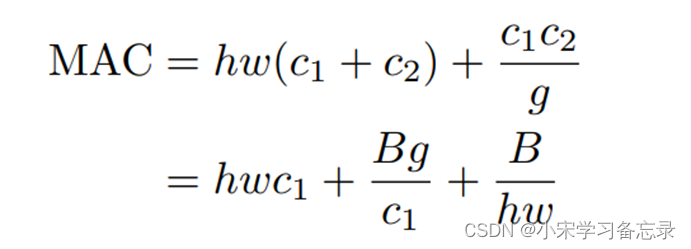

图31 GConv的MAC
显而易见,需要对输入和输出的Channel数除以g,因为我们分为了g组。当然作者提到了这个假设的前提是FLOPs不变,而是一旦输入确定,我们的hwc1也是不会变化的;将公式化简后,因为hwc1不变,B也不变,因此只有g是随着mac变化而变化的,这也就印证了G2理论。作者也做了对比实验,如下图:

图32 G2对比实验
从图中可看出,作者对g做了1248四种,其中g=1也就是我们的常规卷积,实验发现,常规卷积是最快的,这也就是为什么最开始网络中看到的将GConv又换作了Conv。
G3) Network fragmentation reduces degree of parallelism
** 网络碎片化会降低并行程度**
** ** 作者在论文中写道:

图33 ShuffleNetV2论文
作者的大致意思是网络碎片化程度,这里可以理解为网络的串行结构或者并行结构越多,对算力比较高的设备是不有好的。作者也做了对比实验:如下图
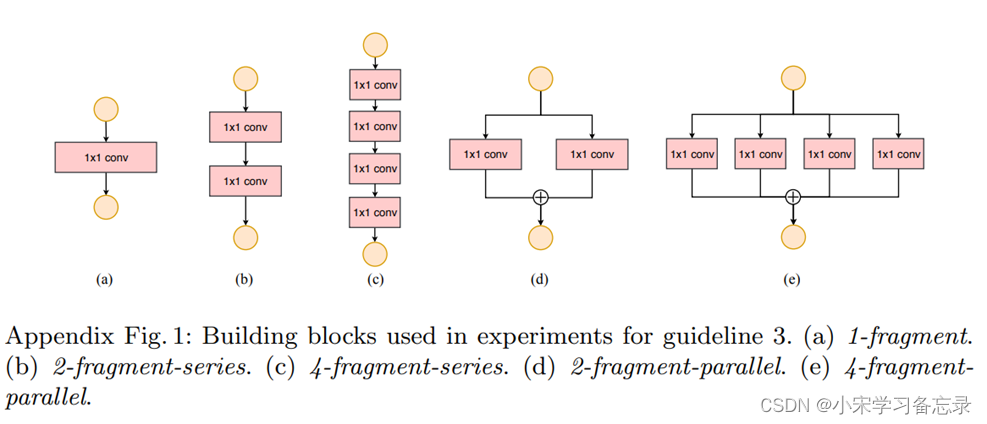
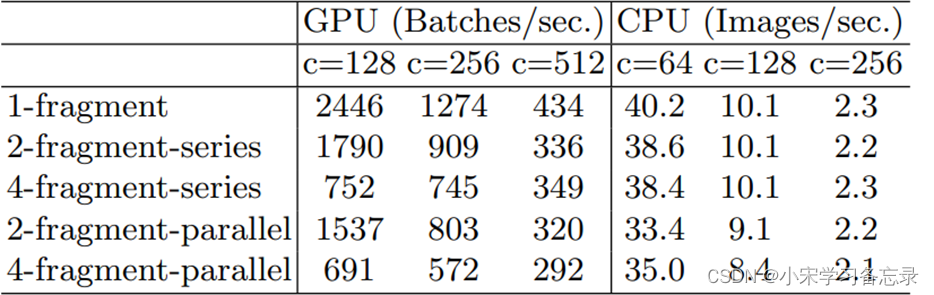
图34 G3准则实验对比图
对于(a)--(e)的网络,其推理速度在GPU上变化很大,但在CPU上变化幅度就比较小,这个就更加证明了使用更少的组卷积是有利于网络的,因为越多的组卷积,会造成网络的碎片化程度越高。
G4) Element-wise operations are non-negligible
** Element-wise(元素,神经网络中对应的就是张量)操作的影响不可忽略**
论文中提到:

图35 ShuffleNetV2论文相关
论文中写道,一些有关张量计算的操作也是不可忽视的,比如Relu和分支中的add计算,还有一些
偏置项等。作者也做了对比实验,如下图:
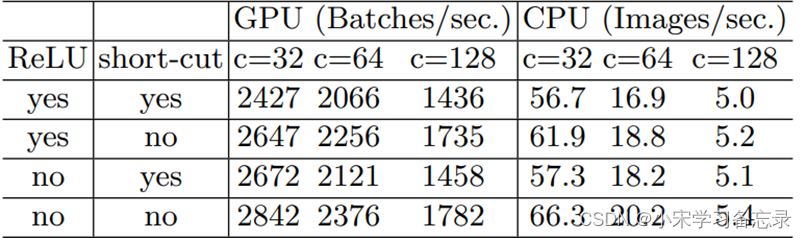
图36 G4准则对比实验
通过对比实验,可以看出当Relu和short-Cut为no的时候,速度是最快的。这也就是为什么网络中用concat取代add。
2.2.3 ShuffleNetV2总结
最后,作者基于四条准则总结出了如下四点:
**①use ****”balanced“ convolutions (equal channel width); **
**②be aware of the cost of using group convolution; **
③reduce the degree of fragmentation;
**④reduce element-wise operations. **
第一点就是使用平衡卷积,通道数要对等
第二点就是避免过度使用GConv
第三点是降低网络的复杂程度
第四点就是降低element-wise的操作
最后,作者对网络的改进做了解释:

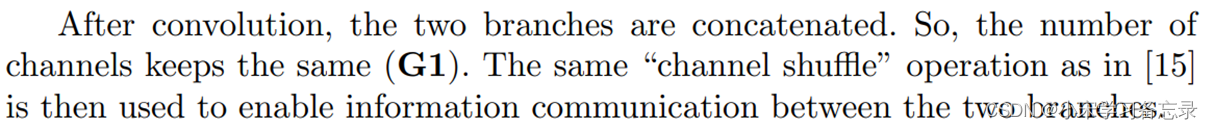

图37 ShuffleNetV2论文
第一段写道,input被划分为c-c'和 c'。根据G3,一个分支没有做任何操作,另一个分支输入等于输出,这符合G1准则,用普通卷积替换了组卷积,符合G2准则
第二段写道,两个分支的做concat操作,保持输入和输出相等,最后使用Channel Shuffle将不同通道进行信息融合。
第三段写道,在Channel Shuffle之后,and操作被concat替代,relu操作上移到了其中一个分支,不在作用于全局。而且concat,Channel Shuffle和chann spit都在一个单一分支,这个符合g4
最后,看一下ShuffleNetV2的网络设计图:
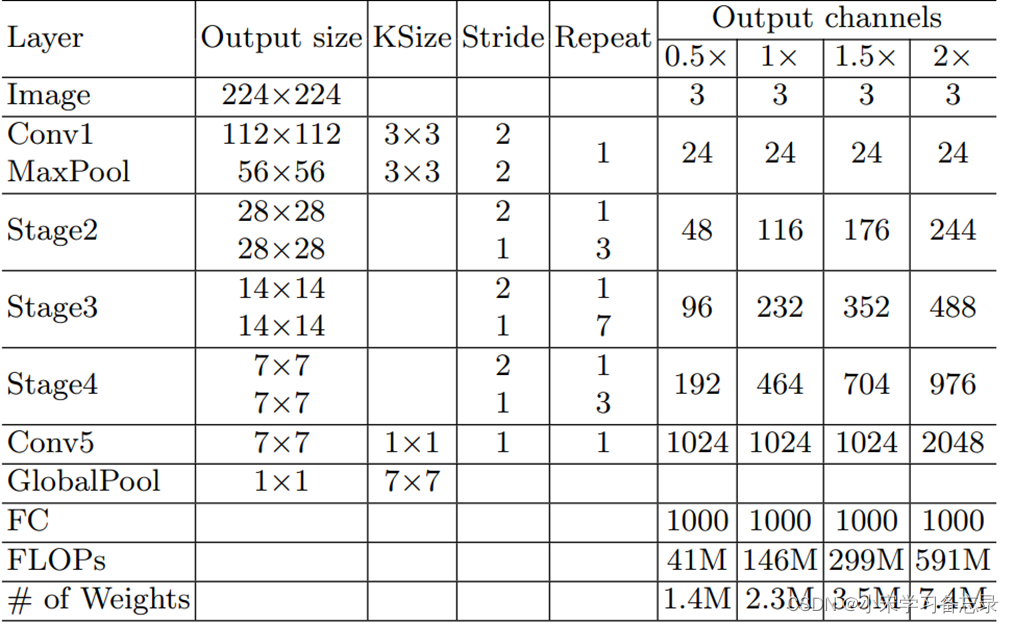
图38 ShuffleNetV2网络设计图
作者提到对比ShuffleNetNetV1,只有一个不同,就是在全局池化前面加上了一个7x7的卷积层 。
2.3 Yolov5-Lite网络
2.3.1 整体网络构架
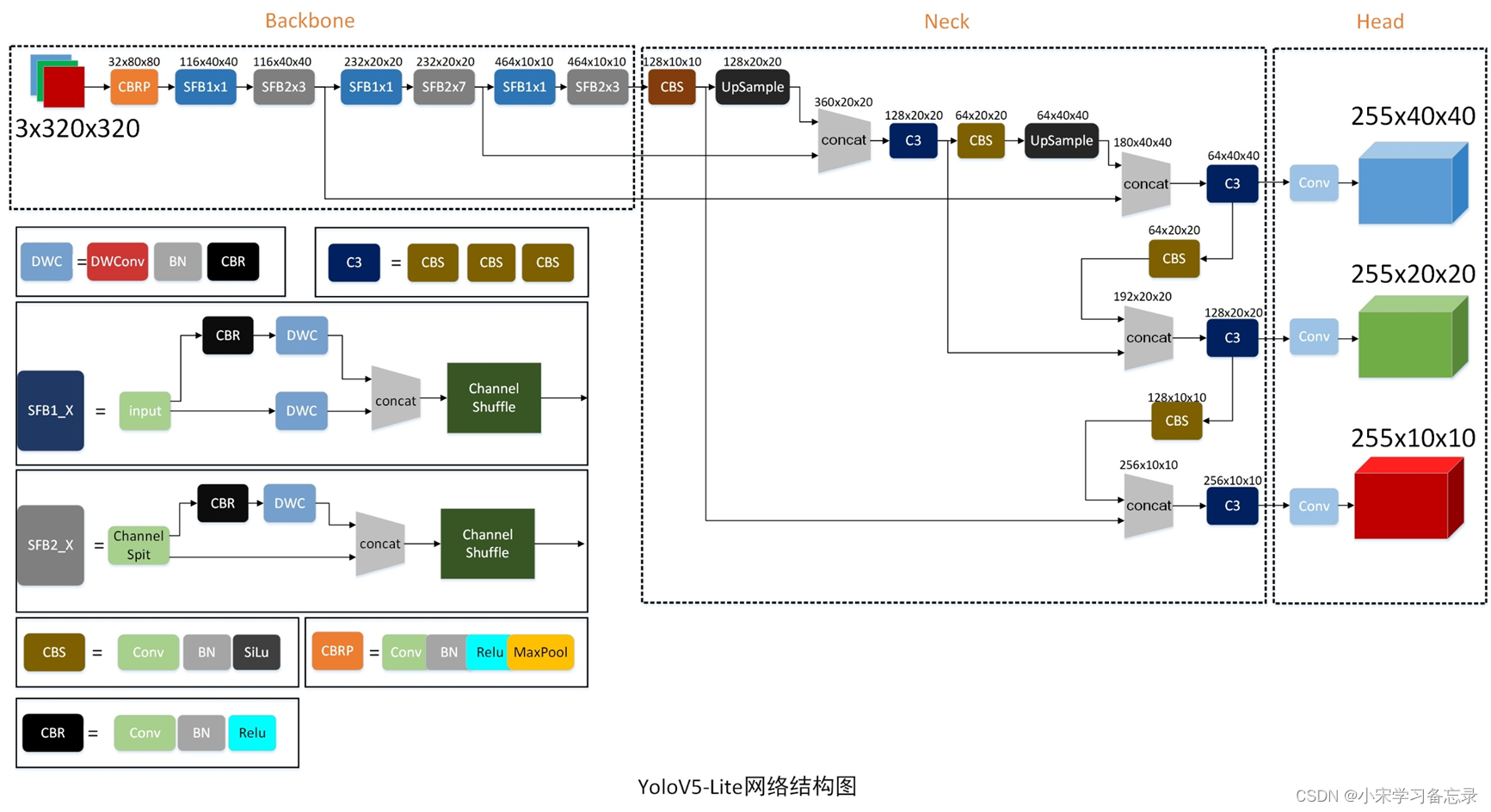
图39 Yolov5-Lite网络结构图
如上图所示,网络大致分为backbone、neck和head三部分,其中backbone中沿用了ShuffleNetV2的构架,首先是一个Conv层和最大池化层,进行下采样,然后就是3个stage操作,这个是完全一样的,但是作者ppogg取消了Channel数为1024的Conv层和5x5的全局池化。
接着就是neck层,其和yolov5是完全一样的,只有一个改进就是将CBL层换成了CBS层,也就是将激活函数由Relu换成了Silu。
最后就是head层,也是采用了和yolov5一样的输出。
2.3.2 YoloV5-Lite设计理念
对于Yolov5-Lite的设计理念,做了总结就是:
(1)摘除Focus层,避免多次采用slice操作
(2)避免多次使用C3 Leyer以及高通道的C3 Layer减少噪音
(3)对yolov5 head进行通道剪枝,剪枝细则参考G1
(4)摘除shufflenetv2 backbone的1024 conv和 5×5 pooling
至此,关于yolov5、ShuffleNetV2以及YoloV5-Lite的网络结构大概讲完了,作者水平有限,如果有任何错误的地方,希望大家积极在评论区讨论以便作者及时更正
参考文献:
ppog------YOLOv5-Lite:更轻更快易于部署的YOLOv5
三叔家的猫-----yolov5中的Focus模块的理解
混分巨兽龙某某------基于树莓派4B的YOLOv5-Lite目标检测的移植与部署(含训练教程)
路人贾-----【轻量化网络系列(5)】ShuffleNetV2论文超详细解读
版权归原作者 小宋学习备忘录 所有, 如有侵权,请联系我们删除。