
朴素贝叶斯是一系列简单的概率分类器,它基于应用贝叶斯定理,在特征之间具有强或朴素的独立假设。它们是最简单的贝叶斯模型之一,但通过核密度估计,它们可以达到更高的精度水平。
朴素贝叶斯基于贝叶斯定理,该定理根据可能与事件相关的条件的先验知识来描述事件的概率。这方面的一个例子是,一个人的健康问题可能与他的年龄有关。因此,贝叶斯定理允许通过对已知年龄个体的年龄进行调节来更准确地评估其风险,而不是假设该个体是整个群体的典型。
根据在线百科全书维基百科,贝叶斯定理引用如下。贝叶斯定理在 Udacity 的机器学习入门课程的第 2 课中介绍:-
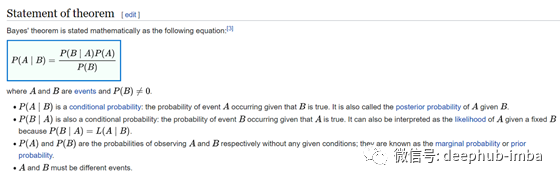
因为我想从课程中得到一些东西,所以我在互联网上进行了搜索,寻找一个适合使用朴素贝叶斯估计器的数据集。在我的搜索过程中,我找到了一个网球数据集,它非常小,甚至不需要格式化为 csv 文件。
我决定使用 sklearn 的 GaussianNB 模型,因为这是我正在学习的课程中使用的估算器。在概率论中,高斯分布是实值随机变量的一种连续概率分布。高斯分布在统计学中很重要,常用于自然科学和社会科学来表示分布未知的实值随机变量。
我使用 Google Colab 编写了初始程序,这是一个免费的在线 Jupyter Notebook。Google Colab 的一大优点是我可以将我的工作存储在 Google 驱动器中。Google colab 的坏处是没有撤消功能,因此需要注意不要覆盖或删除有价值的代码。
创建 Jupyter Notebook 后,我导入了我需要的库。我在这个项目中使用的库是 pandas、numpy、matplotlib、seaborn 和 sklearn。Pandas 创建和操作数据帧,numpy 快速执行代数计算,sklearn 执行机器学习活动,seaborn 和 matplotlib 使我能够绘制数据。
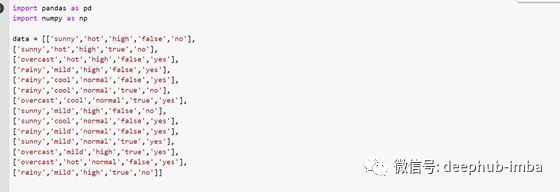
因为这个项目中使用的数据太小了,甚至没有必要把它放在一个 csv 文件中。在这种情况下,我决定将数据放入我自己创建的df中:-
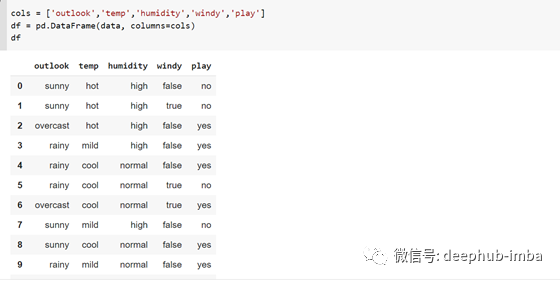
我定义了列的名称并创建了一个df,其中列用我给它们的名称标识:-
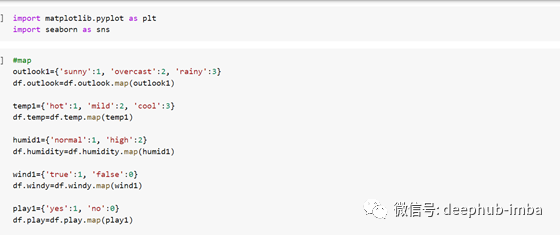
我决定映射这些值,因为如果创建了字典并为列中的简单类别分配了一个数字,则更容易识别单元格中的值:-
下面的屏幕截图显示了我绘制出所有列后的df。
我要注意的是,在我创建了这个程序之后,我回过头来对数据进行打乱,看看是否可以达到更高的精度,但在这种情况下,打乱没有效果。如果有人想打乱数据,使用的代码是:- df = df.sample(frac = 1)
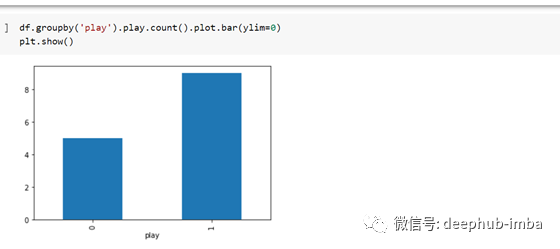
然后我分析了目标,可以看到 1 比 0 多,这表明有可能比非比赛日有更多的比赛天数:-
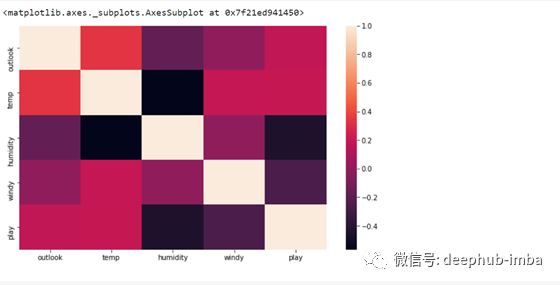
然后我创建了一个热图,它揭示了自变量对因变量的相互依赖性:-
然后我定义了目标,它是数据框的最后一列。
然后我删除了数据的最后一列:-
然后我分配了依赖变量 y 和独立变量 X。目标位于 y 变量中,其余数据框位于 X 变量中:-

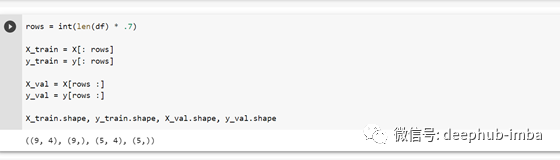
然后我将 X 和 y 变量分开以进行训练和验证:-
然后我使用 sklearn 的 GaussianNB 分类器来训练和测试模型,达到了 77.78% 的准确率:-

模型经过训练和拟合后,我在验证集上进行了测试,并达到了 60% 的准确率。我不得不说,我个人希望获得更高的准确度,所以我在 MultinomialNB 估计器上尝试了数据,它对准确度没有任何影响。
也可以仅对一行数据进行预测。在下面的示例中,我对 ([2,1,1,0]) 进行了预测,得出的预测为 1,这与数据集中的数据相对应。
提高该模型准确性的一种方法是增加数据。由于网球数据集非常小,增加数据可能会提高使用此模型实现的准确度:-

最后本文的代码:https://www.kaggle.com/tracyporter/tennis-gaussiannb
本文作者:Tracyrenee