
HDFS写数据流程
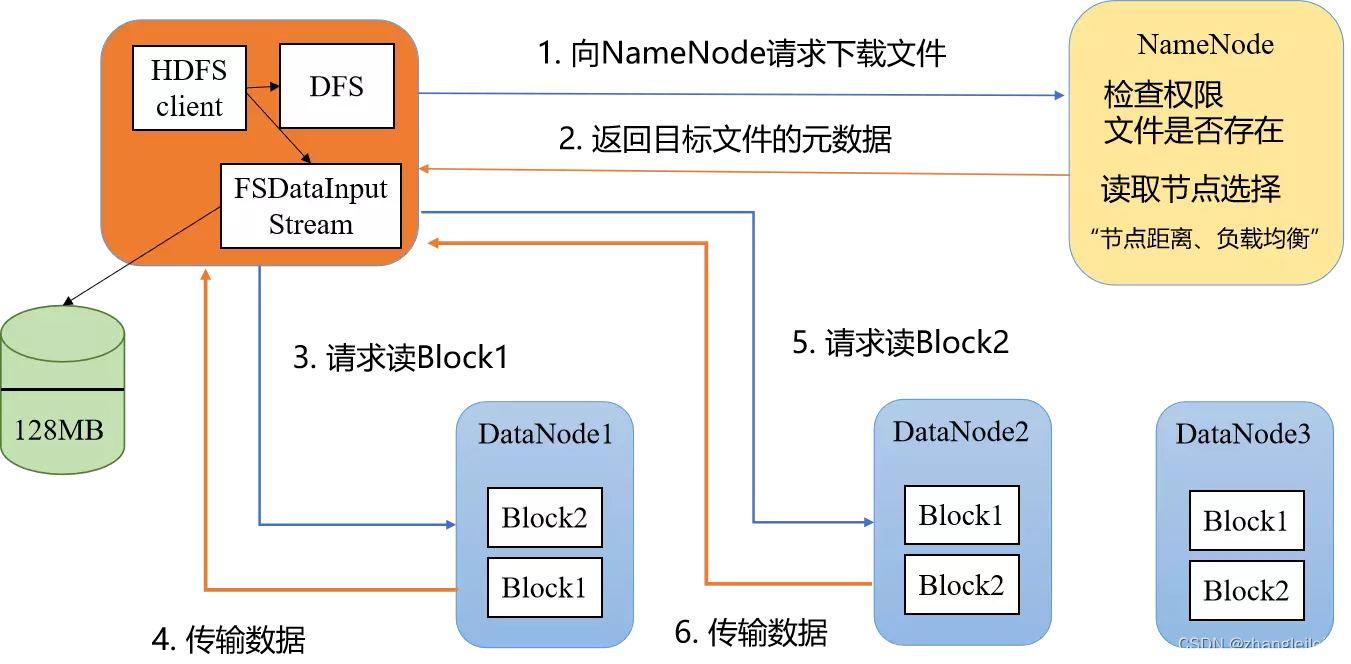
(1)客户端向NameNode发出写文件请求
(2)NameNode检查是否已存在文件、检查权限,Namenode应答可以上传。
(3)客户端请求上传第一个Block。客户端上传之前对文件进行切片,切片规则:按datanode的block块大小进行切片,hadoop2.x默认block大小为128m(例如:300m文件切分为3片:第一片128m,第二片128m,剩下44m单独为1片。)
(4)NameNode返回上传的DataNode信息,具体NameNode如何选择DataNode,选择哪些DataNode是hadoop机架感知特性和副本个数决定(默认个数为3)决定
(5)客户端拿到DataNode信息后,与DataNode1直接建立通信通道,DataNode1和DataNode2,DataNode2与DataNode3同时会建立通信通道,进行数据的副本传输。
(6)DataNode2和DataNode3完成数据通信后,依次按通信顺序,最终应答给DataNode1,DataNode1再应答client,完成数据的通信。
(7)开始上传数据。以packet为单位上传,packet默认大小为64k。
(注)上传到DataNode1中的数据先存到byteBuffer缓存中,达到block大小,再刷到block中进行物理存储。
(8)第一各切片完成传输以后,开始传输第二各切片,过程同切片一
副本存储选择
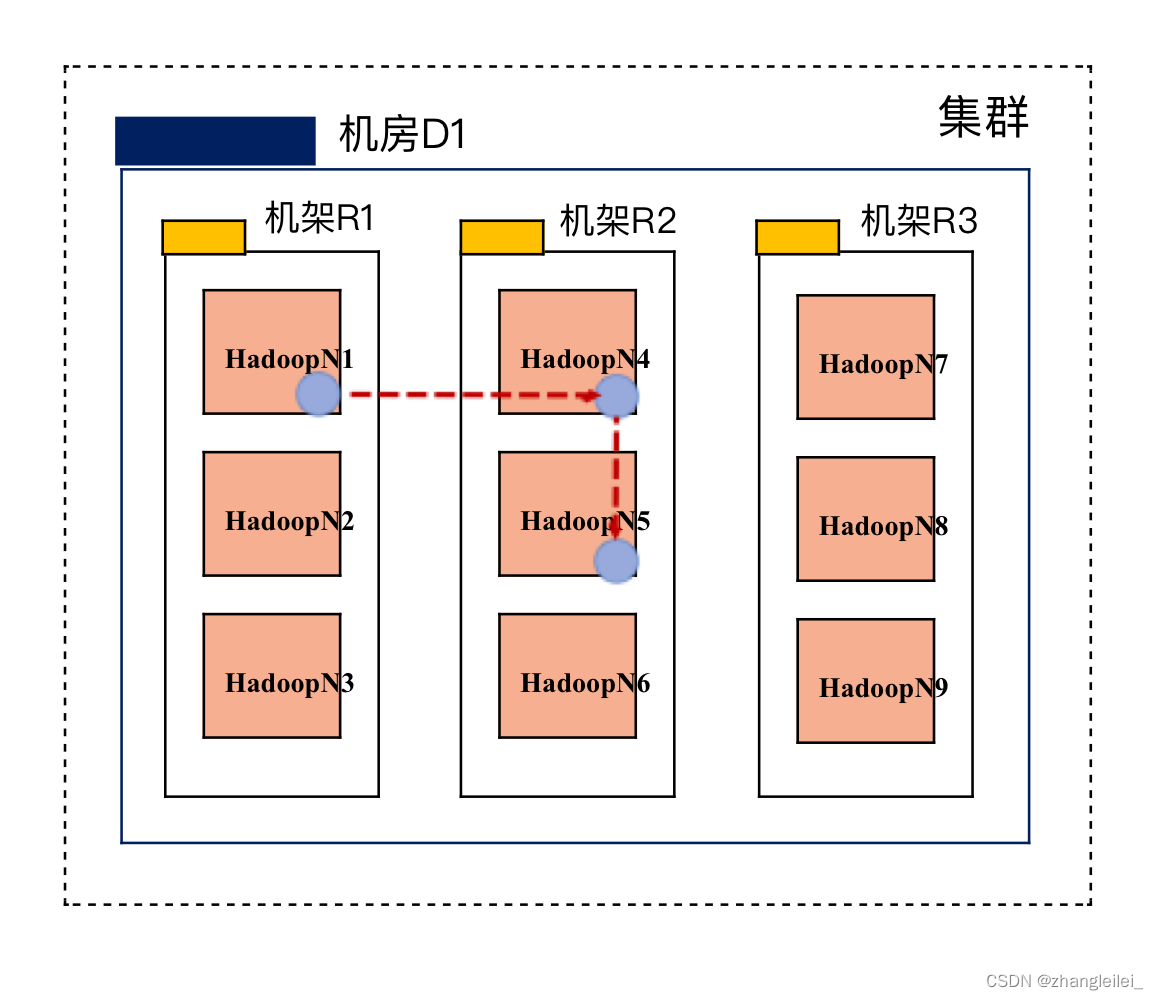 默认存储三个副本,现有集群,内有9台服务器,因此需要选择三台服务器进行副本存储
默认存储三个副本,现有集群,内有9台服务器,因此需要选择三台服务器进行副本存储
- 第一个副本在Client所在的节点上,若Client在集群外,则随机选取一个节点进行存储
- 第二个副本在另一个机架上随机选择一个节点(来保证可靠性,第一个副本所在机架噶了,可以用第二个机架上的副本)
- 第三个副本在第二个副本所在机架上随机选取一个节点(保证效率,毕竟机架噶了的概率很小,不需要再寻找第三个机架了)
客户端上传文件代码:
public static void main(String[] args) throws IOException {
// 获取客户端
URI uri = URI.create("hdfs://localhost:9000/user/tmp/hello.txt");
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(uri, config);
// 执行操作命令—上传文件
fs.copyFromLocalFile(new Path("/develop/input/hello.txt"), new Path(uri));
//关闭资源
fs.close();
}
客户端文件更名和移动代码
public static void main(String[] args) throws IOException {
// 获取客户端
URI uri = URI.create("hdfs://localhost:9000/user/tmp/hello.txt");
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(uri, config);
// 执行操作命令—更名和移动
fs.rename(new Path("/user/tmp/hello.txt"), new Path("/user/tmp/test.txt"));
fs.rename(new Path("/user/tmp/test.txt"), new Path("/user/task.txt"));
//关闭资源
fs.close();
}
本文转载自: https://blog.csdn.net/zhangleilei_/article/details/128193842
版权归原作者 一朵想摆烂的娇花 所有, 如有侵权,请联系我们删除。
版权归原作者 一朵想摆烂的娇花 所有, 如有侵权,请联系我们删除。