
目录
一、MySQL 应该掌握哪些知识点 ?
🎄 (1) MySQL 基础篇(初级工程师)
- ① MySQL 基础概念
- ② SQL 语句
- ③ 函数
- ④ 约束
- ⑤ 多表查询
- ⑥ 事务
🎄 (2) MySQL 进阶篇(中级工程师)
- ① 存储引擎
- ② 索引
- ③ SQL 优化
- ④ 视图、存储过程、触发器
- ⑤ 锁
- ⑥ InnoDB 核心
- ⑦ MySQL 管理
🎄 (3) 运维篇(高级工程师)
- ① 日志
- ② 主从复制
- ③ 分库分表
- ④ 读写分离
二、数据库相关概念
✏️ 数据库:存储数据的仓库(仓库中的数据是被有组织的存储的)【Database】
✏️ 数据库管理系统:操纵和管理数据库的大型软件【Database Management System】
✏️ SQL:操纵关系型数据库的编程语言(定义了一套操纵关系型数据库的同一标准)【Structured Query Language】
三、主流关系型数据库管理系统
📝 Oracle(非开源)
📝 MySQL(社区版是开源的)
📝 Sql Server(微软研发)
📝 PostgreSQL
📝 IBM Db2
📝 SQLite(安卓使用)
四、关系型数据库
🎄 关系型数据库(RDBMS):由多张相互关联的二维表组成的数据库
五、SQL 语句的分类
📌 ① DDL(Data Definition Language)
数据定义语言【用于定义数据库、表、字段 …】
📌 ② DML(Data Manipulation Language)
数据操作语言【用于对数据库表中的数据进行增、删、改】
📌 ③ DQL(Data Query Language)
数据查询语言【用于查询数据库中表的记录】
📌 ④ DCL(Data Control Language)
数据控制语言【用于创建数据库用户、控制数据库的访问权限】
六、DDL
🎄 Data Definition Language:数据定义语言
(1) 数据库操作
查询:
🎼 ① 查询所有数据库:
SHOWDATABASES;
🎼 ② 查询当前数据库
SELECTDATABASE();
🎼 ③ 创建数据库
CREATEDATABASE[IFNOTEXISTS] db_name;
IF NOT EXISTS表示 只有当数据库不存在的时候才创建,避免了下图的错误

CREATEDATABASEIFNOTEXISTS db_name DEFAULTCHARSET= utf8mb4
✏️ utf8mb4 字符集可存储 4 个字节的数据(可存储表情包)
✏️ utf8 字符集只能存储 3 个字节的数据
✏️ 推荐使用 utf8mb4📌
DEFAULT CHARSET用于设置数据的字符集
🎼 ④ 删除数据库
DROPDATABASE[IFEXISTS] db_name
📌
IF EXISTS只有存在才删除
🎼 ⑤ 使用数据库
USE db_name
(2) 表操作
🎄 ① 查询当前数据库的所有表
SHOWTABLES
🎄 ② 查询表结构
DESC table_name
🎄 ③ 查询指定表的建表语句
SHOWCREATETABLE table_name
🎄 ④ 创建表
CREATETABLE`student`(`id`INT(11)DEFAULTNULLCOMMENT'编号',`name`VARCHAR(20)DEFAULTNULLCOMMENT'姓名',`age`TINYINT(4)DEFAULTNULLCOMMENT'年龄',`gender`CHAR(1)DEFAULTNULLCOMMENT'性别')ENGINE=INNODBDEFAULTCHARSET=utf8mb4 COMMENT='这是学生表'
- ① 使用
VARCHAR类型必须指定长度- ② 最后一个字段的后面不要加
,【加了会报错】
(3) 字段的数据类型
🎄 数据库表的数据类型有三种:
① 数值类型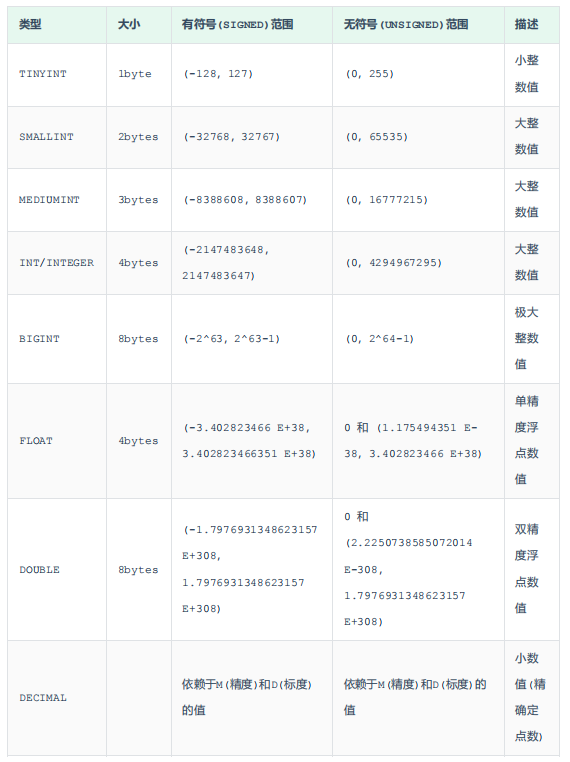
DECIMAL 数据类型的精度和标度:
eg:25.689 的精度是 5
eg:25.689 的标度是 3
🎄 age:tinyint unsigned
- unsigned【年龄不会有负数】
🎄 score:总分100分,最多出现一位小数
- score double(4,1)
- 分数有可能是:100.1【所以是4】
- 只会有一位小数【所以是1】
② 字符串类型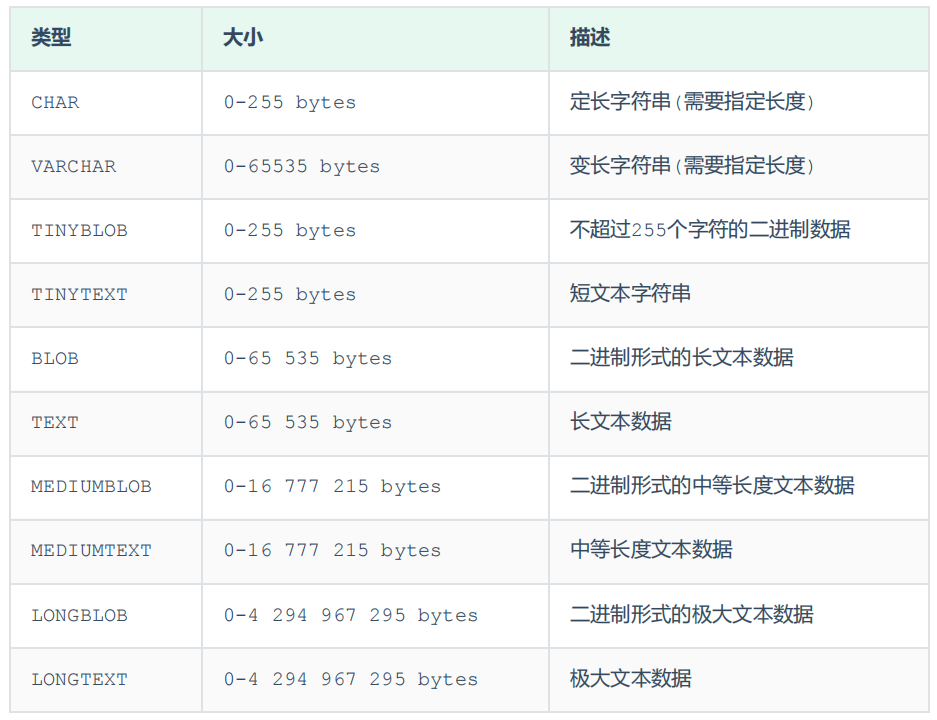
- 【变长字符串】varchar(10):最多只能存储10个字符,会根据实际情况指定占用的空间【性能比 char 差】
- 【定长字符串】char(10):最多只能存储10个字符,当存储的是1个字符的时候也是占用10字符的空间,为使用的字符用空格补位【性能比 varchar 好】
【姓名 name】用 varchar 类型比较好
【性别 gender】用 char 类型比较好
📝 varchar(n):n 表示的是最大字符数【占用的空间不固定,但占用的最大空间是固定的】
📝 char(n):n 表示的是总字符数【占用的空间是固定的】
③ 日期时间类型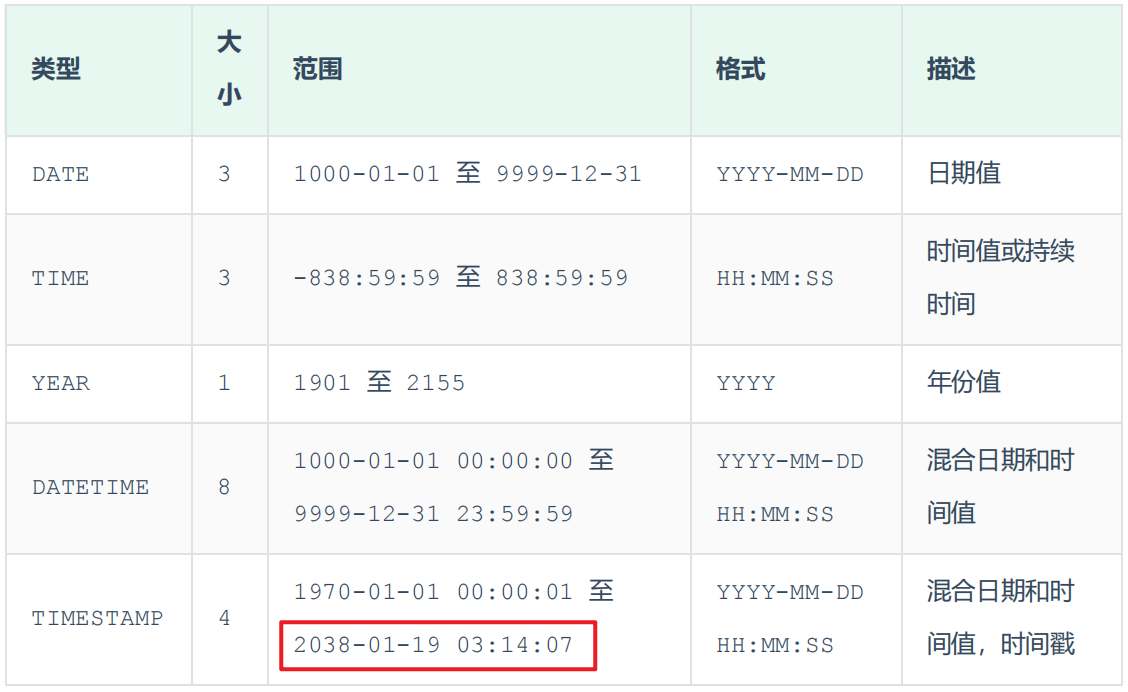
(4) 创建员工表

CREATETABLE employer (
id INTUNSIGNEDCOMMENT'编号',`work_no`VARCHAR(10)COMMENT'工号',`name`VARCHAR(10)COMMENT'姓名',
age TINYINT(3)UNSIGNEDCOMMENT'年龄',`gender`CHAR(1)COMMENT'性别',
id_number CHAR(18)COMMENT'身份证号',
entry_date DATECOMMENT'入职时间')COMMENT'员工表'
(5) 修改表结构
📌 ① 往表中新增字段
为 employer 表新增【昵称】字段, 字段名为 nickname,类型为 varchar(20)
ALTERTABLE employer ADD nickname VARCHAR(20)COMMENT'昵称';
📌 ② 修改表中的字段
- 修改字段的数据类型

把 employer 表中 id 字段的数据类型修改为 BIGINT, 也无符号
ALTERTABLE employer MODIFY id BIGINTUNSIGNED;
- 修改字段名和数据类型

修改 employer 表中 nickname 字段的字段名为 username,类型是 varchar(30)
ALTERTABLE employer CHANGE nickname username VARCHAR(30)COMMENT'用户名'
📌 ③ 删除表中的字段

删除 employer 表中的 age 字段
ALTERTABLE employer DROP age
📌 ④ 修改表名

把 employer 表的表名修改为 staff
ALTERTABLE employer RENAMETO staff
(6) 删除某一张表

删除数据库中的表名为 emp 的表,如果存在的话
DROPTABLEIFEXISTS emp
删除指定表,并重新创建表(类似删除表中的全部数据)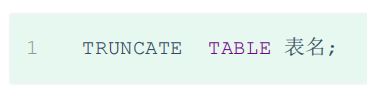
七、DML


DELETEFROM table_name
TRUNCATE table_name
八、DQL


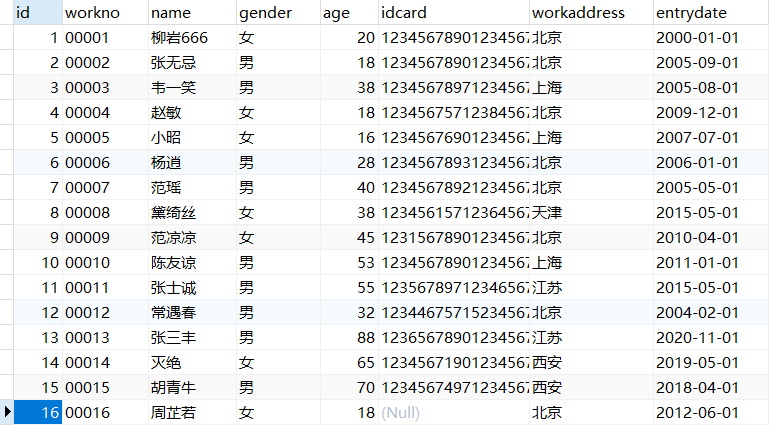
(1) 员工表
createtable emp (
id intcomment'编号',
workno varchar(10)comment'工号',
name varchar(10)comment'姓名',
gender char(1)comment'性别',
age tinyintunsignedcomment'年龄',
idcard char(18)comment'身份证号',
workaddress varchar(50)comment'工作地址',
entrydate varchar(33)comment'入职时间')comment'员工表';
INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(1,'00001','柳岩666','女',20,'123456789012345678','北京','2000-01-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(2,'00002','张无忌','男',18,'123456789012345670','北京','2005-09-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(3,'00003','韦一笑','男',38,'123456789712345670','上海','2005-08-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(4,'00004','赵敏','女',18,'123456757123845670','北京','2009-12-01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(5,'00005','小昭','女',16,'123456769012345678','上海','2007-07-01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(6,'00006','杨逍','男',28,'12345678931234567X','北京','2006-01-01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(7,'00007','范瑶','男',40,'123456789212345670','北京','2005-05-01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(8,'00008','黛绮丝','女',38,'123456157123645670','天津','2015-05-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(9,'00009','范凉凉','女',45,'123156789012345678','北京','2010-04-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(10,'00010','陈友谅','男',53,'123456789012345670','上海','2011-01-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(11,'00011','张士诚','男',55,'123567897123465670','江苏','2015-05-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(12,'00012','常遇春','男',32,'123446757152345670','北京','2004-02-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(13,'00013','张三丰','男',88,'123656789012345678','江苏','2020-11-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(14,'00014','灭绝','女',65,'123456719012345670','西安','2019-05-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(15,'00015','胡青牛','男',70,'12345674971234567X','西安','2018-04-
01');INSERTINTO emp (id, workno, name, gender, age, idcard, workaddress, entrydate)VALUES(16,'00016','周芷若','女',18,null,'北京','2012-06-01');
(2) distinct、as
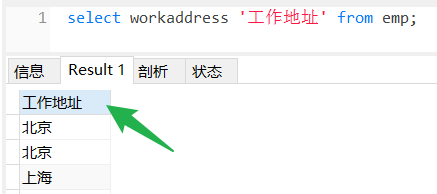

distinct: 去除查询结果的重复项
(3) where
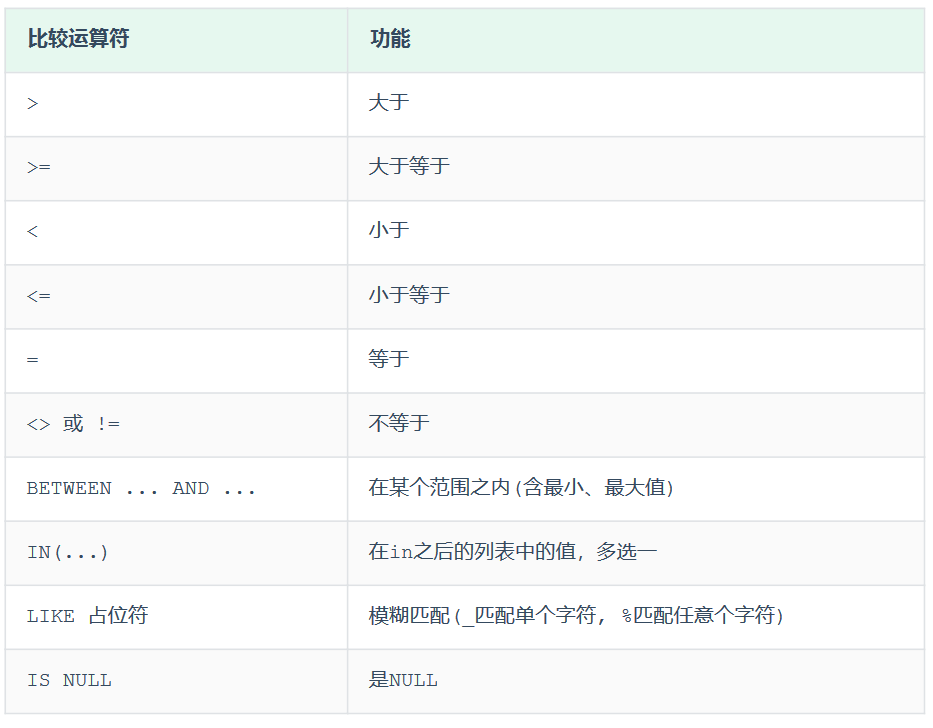
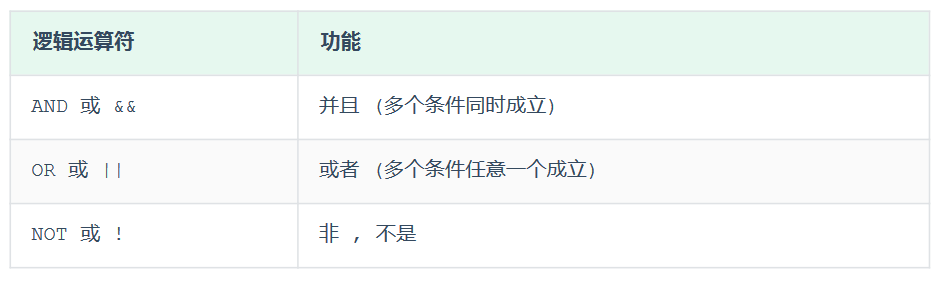
查询没有身份证号的员工信息
select*from emp where idcard isnull;
查询有身份证号的员工信息
select*from emp where idcard isnotnull;

查询年龄不等于88岁的员工信息
select*from emp where age !=88;select*from emp where age <>88;
查询年龄在 15 到 20 岁的员工信息(包含15和20岁)
select*from emp where age between15and20;select*from emp where age >=15&& age <=20;select*from emp where age >=15and age <=20;
查询年龄是 18、20 或 40 的员工信息
select*from emp where age =18or age =20or age =40;select*from emp where age in(18,20,40);
查询姓名为两个字的员工信息
select*from emp where name like'__'# 两个下划线
查询身份证号最后一位为 x 的员工信息
select*from emp where idcard like'%x';
(4) 聚合函数



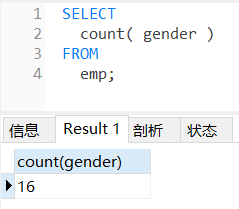
1、统计员工数量
selectcount(*)'employeeNum'from emp;selectcount(id)as'员工数量'from emp;
2、统计员工平均年龄
selectavg(age)'平均年龄'from emp;
3、统计员工最大年龄
selectmax(age)'最大年龄'from emp;
4、统计员工最小年龄
selectmin(age)'最小年龄'from emp;
5、统计西安地区员工的年龄之和
selectsum(age)'年龄和'from emp where workaddress ='西安';
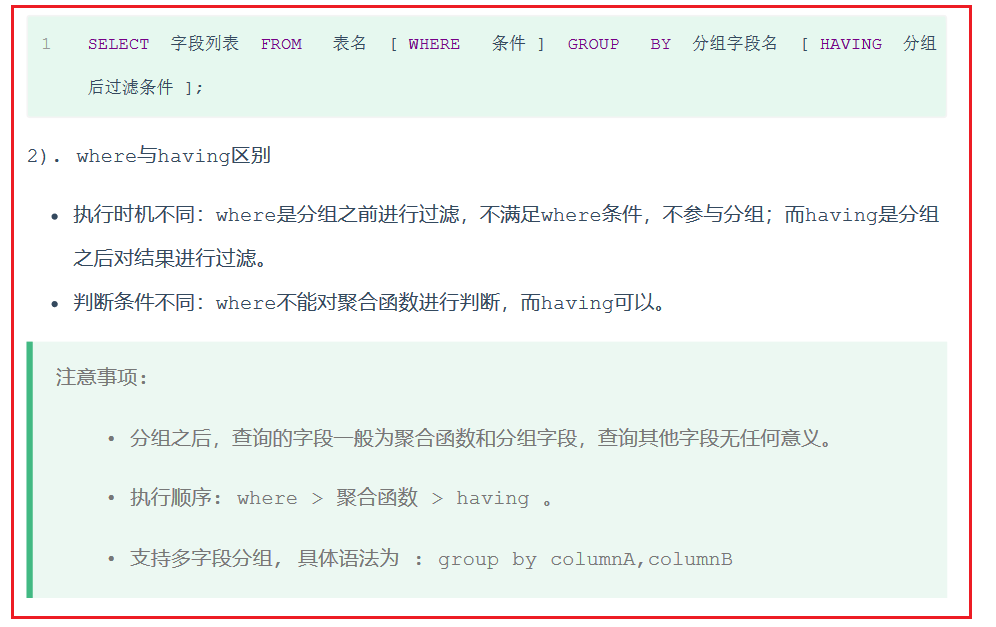
(5) group by、where 和 having 区别
分组(GROUP BY)一般要结合聚合函数一起使用。
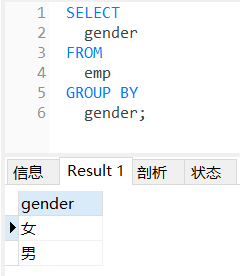
1、根据性别分组,统计男性员工和女性员工的数量
SELECT
gender,count( gender )'人数'FROM
emp
GROUPBY
gender;
2、根据性别分组,统计男性员工和女性员工的平均年龄
SELECT
gender,avg( age )'平均年龄'FROM
emp
GROUPBY
gender
3、查询年龄小于45岁的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
SELECTcount(*)'人数',
workaddress
FROM
emp
WHERE
age <45GROUPBY workaddress HAVINGcount(*)>=3;

(6) order by
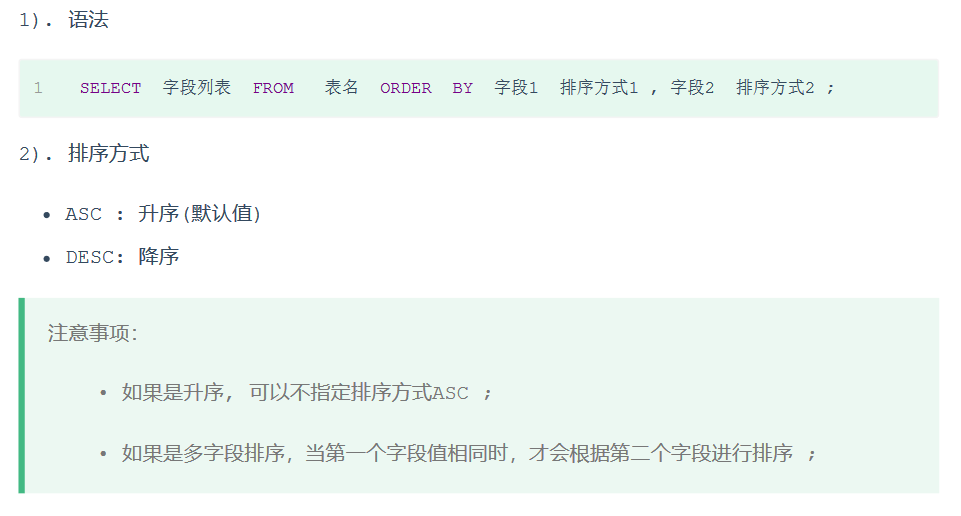
1、根据年龄对公司的员工进行升序排序
select name, age from emp orderby age asc;select name, age from emp orderby age;
2、根据入职时间,对员工进行降序排序
SELECT*FROM
emp
ORDERBY
entrydate DESC;
3、根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序
SELECT*FROM
emp
ORDERBY
age,
entrydate DESC;
(7) 分页查询

1、查询第1页员工数据, 每页展示10条记录
select*from emp limit0,10;select*from emp limit10;
2、查询第2页员工数据, 每页展示10条记录
select*from emp limit10,10;
(8) exercise
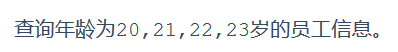
select*from emp where age >=20&& age <=23;select*from emp where age >=20and age <=23;select*from emp where age between20and23;select*from emp where age in(20,21,22,23);select*from emp where age =20or age =21or age =22or age =23;

SELECT*FROM
emp
WHERE
gender ='男'AND age BETWEEN20AND40AND`name`LIKE'___';

SELECT
gender,count(*)FROM
emp
WHERE
age <60GROUPBY
gender;

SELECT`name`,
age,
entrydate
FROM
emp
WHERE
age <=35ORDERBY
age,
entrydate DESC;

SELECT*FROM
emp
WHERE
gender ='男'AND age BETWEEN20AND40ORDERBY
age,
entrydate
LIMIT5;
(9) DQL 语句的执行顺序

版权归原作者 JavaLearnerZGQ 所有, 如有侵权,请联系我们删除。