
前言
分布式,堪称程序员江湖中的一把利器,无论面试还是职场,皆是不可或缺的技能。而Kafka,这款分布式发布订阅消息队列的璀璨明珠,其魅力之强大,无与伦比。对于Kafka的奥秘,我们仍需继续探索。
要论对Kafka的熟悉程度,恐怕阿里的大佬们最有话语权。今天,我们有幸分享一份来自Alibaba内部的“限量笔记”,其中详述了Kafka的精髓。不得不感叹,阿里技术官的深厚功力,让人佩服!这份笔记,无疑是Kafka学习者的宝典,值得每一位技术爱好者珍藏(免费领取方式放在文末啦)!
一、对Kafka的认识
1.Kafka的基本概念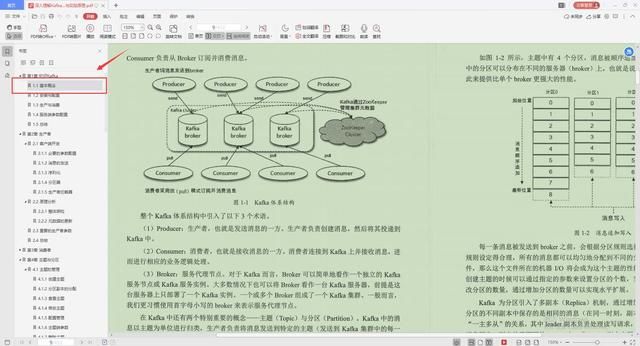
2.安装与配置
3.生产与消费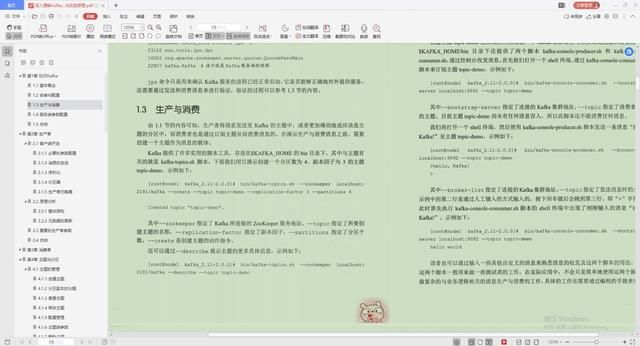
4.服务端参数配置
二、生产者
1.客户端开发
- 必要的参数配置
- 消息的发送
- 序列化
- 分区器
- 生产者拦截器

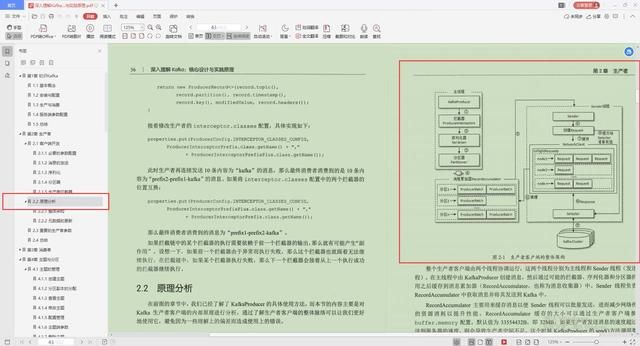
2.原理分析
- 整体架构
- 元数据的更新
3.重要的生产者参数
三、消费者
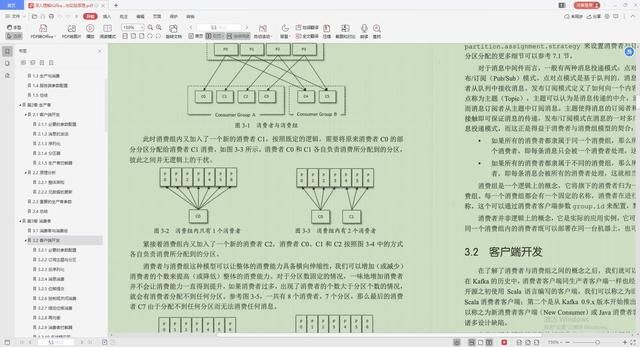
1.消费者与消费组
2.客户端开发
- 必要的参数配置
- 订阅主题与分区
- 反序列化
- 消息消费
- 位移提交
- 控制或关闭消费
- 指定位移消费
- 再均衡
- 消费者拦截器
- 多线程实现
- 重要的消费者参数
四、主题与分区
1.主题的管理
- 创建主题
- 分区副本的分配
- 查看主题
- 修改主题
- 配置管理
- 主题端参数
- 删除主题
2.初识KafkaAdminCilent
- 基本使用
- 主题合法性验证
3.分区的管理
- 优先副本的选举
- 分区重分配
- 复制限流
- 修改副本因子

4.如何选择合适的分区数
- 性能测试工具
- 分区数越多吞吐量就越高吗
- 分区数的上限
- 考量因素
五、日志存储
1.文件目录布局
2.日志格式的演变
- v0版本
- v1版本
- 消息压缩
- 变长字段
- v2版本

3.日志索引
- 偏移量索引
- 时间戳索引
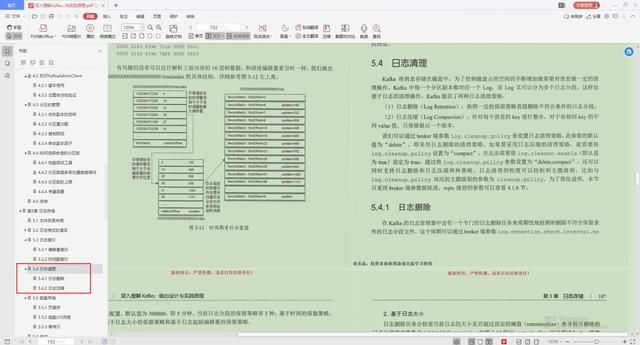
4.日志清理
- 日志删除
- 日志压缩
5.磁盘存储
- 页缓存
- 磁盘I/O流程
- 零拷贝

六、深入服务端
1.协议设计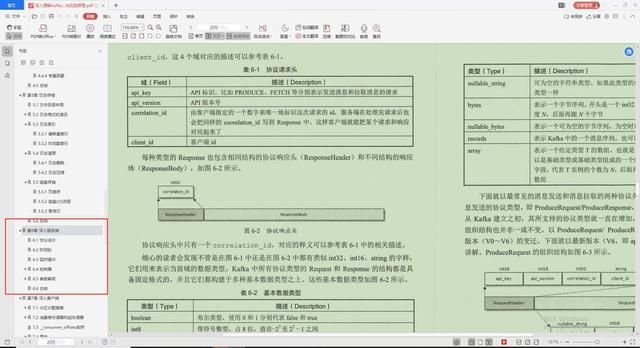
2.时间轮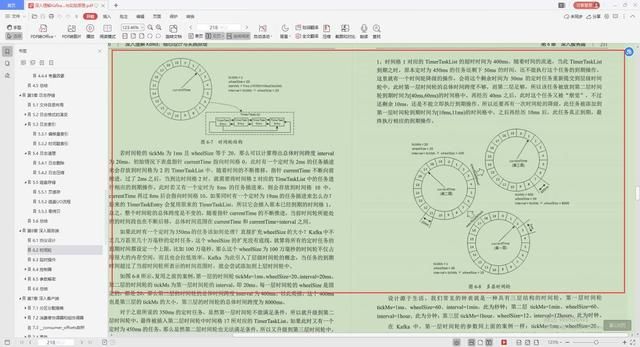
3.延时操作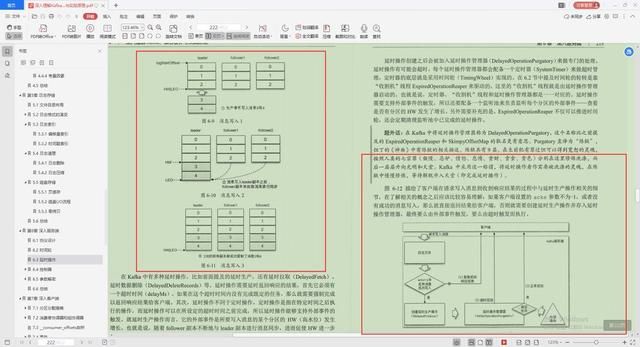
4.控制器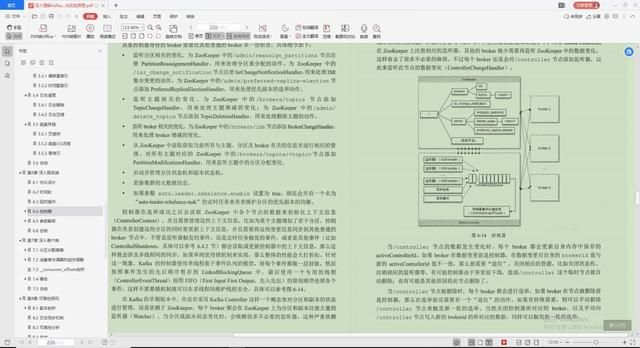
5.参数解密
七、深入客户端
1.分区分配策略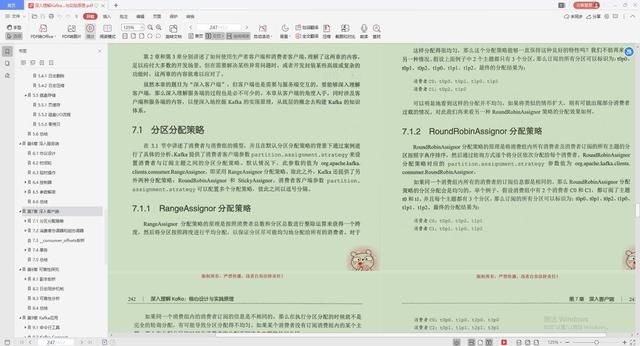
2.消费者协调器和组协调器
3._consumer_offsets剖析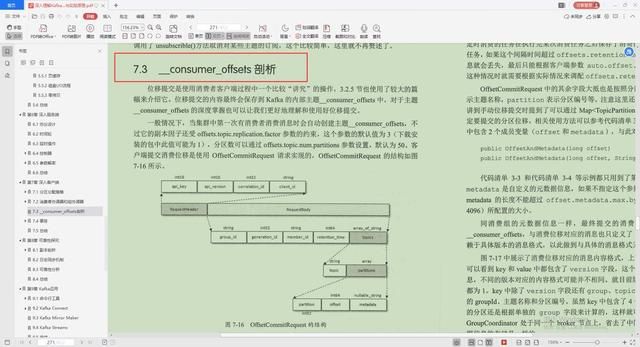
4.事务
八、可靠性探究
1.副本剖析
2.日志同步机制
3.可靠性分析
九、Kafka应用
1.命令行工具
2.Kafka Connect
3.Kafka Mirror Maker
4.Kafka Streams
十、Kafka监控
1.监控数据的来源
2.消费滞后
3.同步失效分区
4.监控指标说明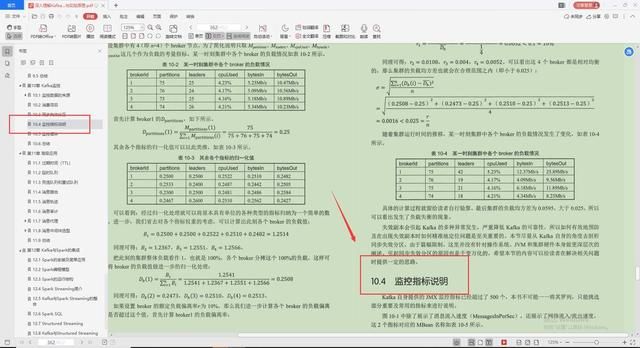
5.监控模块
十一、高级应用
1.过期时间(TTL)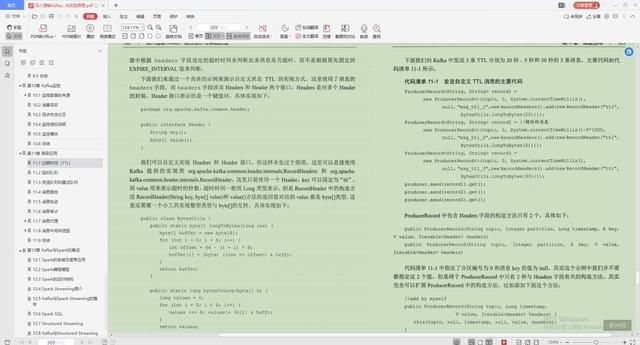
2.延时队列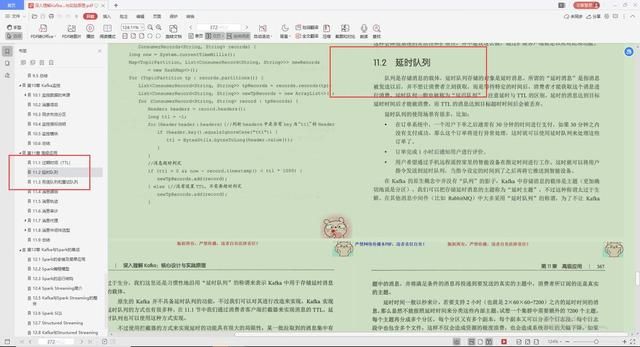
3.死信队列和重试队列
4.消息路由
5.消息轨迹
6.消息审计
7.消息代理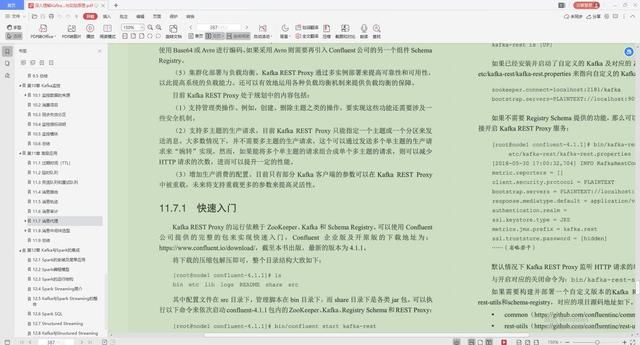
8.消息中间件选型
十二、Kafka与Spark的集成
1.Spark的安装及简单应用
2.Spark编程模型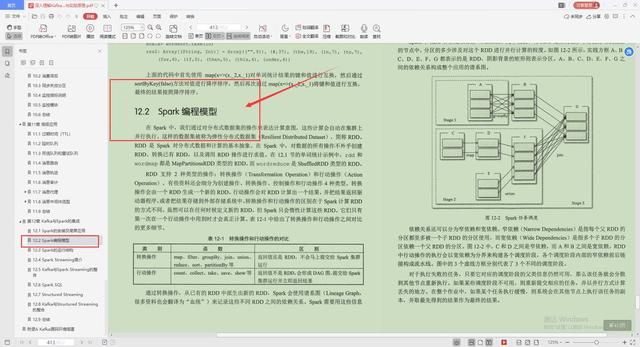
3.Spark的运行结构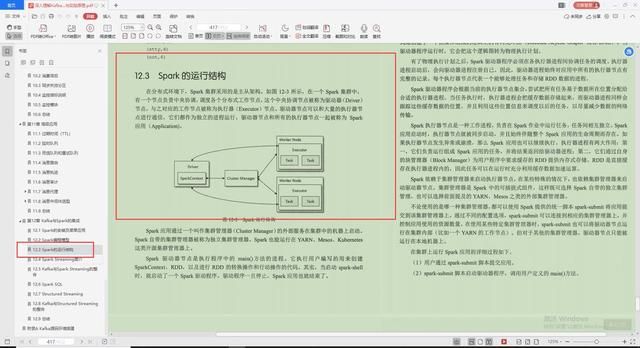
4.Spark Streaming简介
5.Kafka与Spark Streaming的整合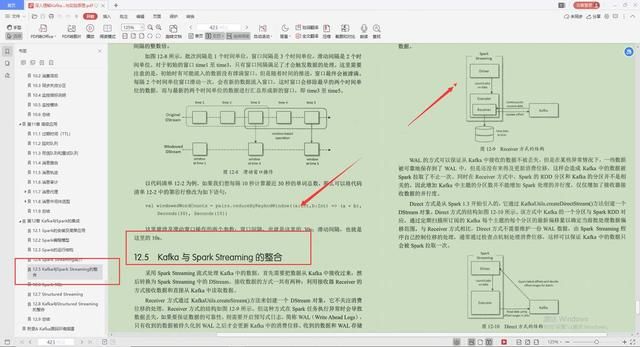
6.Spark SQL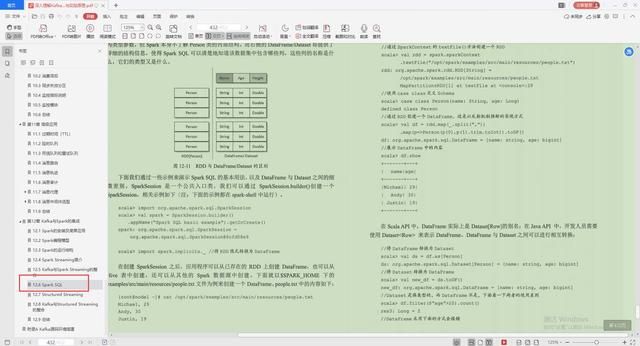
7.Structured Streaming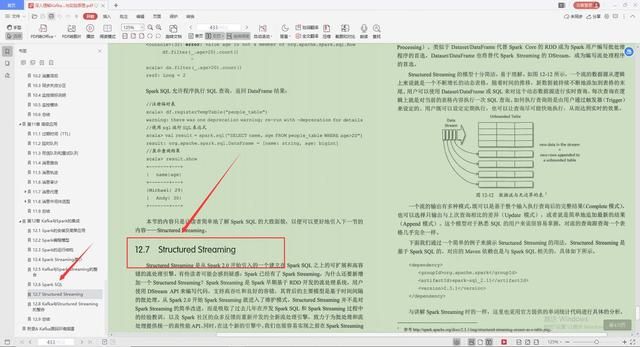
8.Kafka与Structured Streaming的整合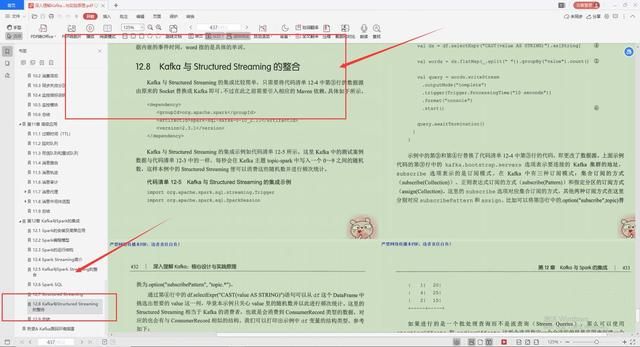
总结
我们常常仰望那些大厂的大神们,但要知道,他们也不过是平凡的人,只是比菜鸟程序员多付出了几分心思。如果你不努力,差距只会越拉越大。作为程序员,充实自己的知识和技能是至关重要的。
在我看来,付出的努力和回报是成正比的。学习Kafka并不难,这份Kafka限量笔记的内容将会对你的学习大有裨益。如果你想要这份完整的Kafka笔记,只需给我一些支持,我会很乐意分享。
获取方式:需要这Kafka笔记的朋友
点击文末下方传送门即可获取免费下载路径的方式!
版权归原作者 不会敲代码的谌 所有, 如有侵权,请联系我们删除。