
文章目录
前言
你还在为自己博客的访问量不高而烦恼吗?我教你如何提高访问量
我发现CSDN上,自己点击自己的博客,可以增加访问量,但是在一定时间内点击同一篇博客,访问量无法再次增加,需要等待一段时间。
通过这个切入点,我们完全可以实现一个非常简单的python小程序,来实现点击博客,提高访问量
1、整体逻辑
本次python小程序的核心就是使用selenium UI测试框架(没有安装的小伙伴需要安装)加上Chrome驱动,Chrome驱动要和Chrome版本大体一致,用其他驱动也可以,例如火狐
第一步:
建立一个python项目,并在该项目中建立一个python文件,名字随便(我的叫做increaseTraffic.py),并在当前目录下建立一个文本文件(用于保存xpath,取名为xpath)
第二步:打开浏览器,点击自己博客主页,并按下fn+F12(或者直接按F12)打开开发者模式
把鼠标移动到自己的第一篇文章上,右击,再点击检查
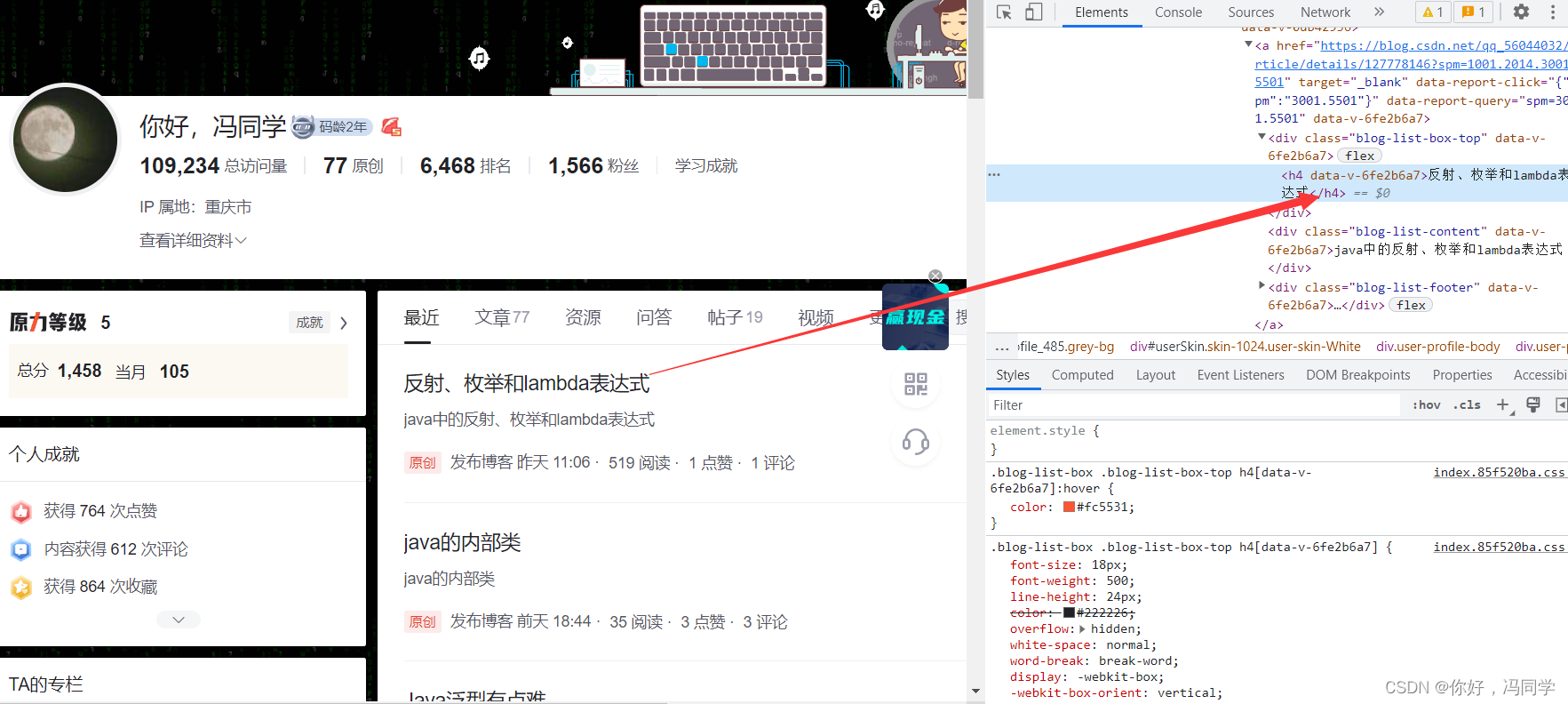
将鼠标放到开发者模式中的高亮部分,右击,再将鼠标放到Copy上,左边就会弹出侧边框,里面有一个CopyXpath,然后点击。将这个Xpath拷贝到之前建好的xpath文件中。
再次对第二篇文章进行重复操作,比较两者的Xpath。
例如我的前两篇文章的Xpath:
//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]/article/a/div[1]/h4
//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[2]/article/a/div[1]/h4
仔细对比,只有/article前面的div[1]里面的数字(可以理解为id)不同,代表类似于文章的标号,假如你有50篇文章,里面的id就是1-50,利用这个特性,就不要保存大量的Xpath,使用字符串拼接即可
因此将Xpath分为两部分(id前半部分和后半部分)保存到xpath文件中,例如

第二步:
读取xpath文件中的内容,并放在一个列表中
defReadfile():withopen("./xpath",'r', encoding="UTF-8")as f:# 不需要读取换行符,因为要进行xpath的拼接
filetxt = f.read().splitlines()return filetxt
# 将text.txt的数据读到列表中
filetxt = Readfile()
str1 = filetxt[0]
str2 = filetxt[1]
这里需要注意的是不能直接调用readlines(),因为它会读取文件中每行内容的换行,但我们不需要这个换行。
以下是读取换行和不读取换行最终拼接的Xpath的区别:
#不读取换行//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]/article/a/div[1]/h4
#读取换行//*[@id="userSkin"]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[1]/article/a/div[1]/h4
第三步:
打开Chrome浏览器,并访问指定的url链接
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://blog.csdn.net/qq_56044032?spm=1000.2115.3001.5343")
这里的url链接一定要填自己的,否则就是再给我刷访问量,哈哈
使用Xpath定位并点击有一个前提,右侧的滚动条要逐步向下滚动,否则有些文章可能没有加载,就会导致错误。
除此之外,点击一篇文章后需要关闭该文件,并且driver对象需要进行窗口切换,否则会将主窗口关掉
最后就是当滑动到底部,并且最后一篇文章点击并关闭后,滚动条需要回到最上方
whileTrue:for i inrange(1,80):if(i ==36or i ==38):
driver.execute_script("window.scrollBy(0,143)")continue
driver.find_element_by_xpath(str1 +str(i)+ str2).click()print(str1 +str(i)+ str2)
driver.switch_to.window(driver.window_handles[1])
time.sleep(2)
driver.close()
driver.switch_to.window(driver.window_handles[0])
driver.execute_script("window.scrollBy(0,143)")
time.sleep(2)
driver.execute_script("var q=document.documentElement.scrollTop=0")
time.sleep(2)
for中的range是文章数量,做闭右开区间
if(i ==36or i ==38):
driver.execute_script("window.scrollBy(0,143)")continue
这段代码的含义就是跳过除文章外的动态,因为我发了两次动态,它们的是36和38
它们的Xpath分别是
//[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[36]/div/a/div[1]/div[1]/div/p
和//[@id=“userSkin”]/div[2]/div/div[2]/div[1]/div[2]/div/div/div[38]/div/a/div[1]/div[1]/div/p
显然和文章的Xpath不同
跳过点击,但也要进行向下滚动
driver.execute_script(“window.scrollBy(0,143)”) 就是向下滑动143个像素点,保持点击的文章始终在屏幕的中间部分
driver.switch_to.window(driver.window_handles[1])
driver.switch_to.window(driver.window_handles[0])
这两句代码意为切换窗口
driver.execute_script("var q=document.documentElement.scrollTop=0")
这句代码意味,当全部文章都已经点击完毕,需要滑动到最上面,再开始下一轮的点击
2、代码实现
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
defReadfile():withopen("./xpath",'r', encoding="UTF-8")as f:# 不需要读取换行符,因为要进行xpath的拼接
filetxt = f.read().splitlines()return filetxt
# 将text.txt的数据读到列表中
filetxt = Readfile()
str1 = filetxt[0]
str2 = filetxt[1]# 打开Chrome浏览器,访问指定的url
driver = webdriver.Chrome()# Chrome浏览器窗口最大化
driver.maximize_window()# 到达url链接
driver.get("https://blog.csdn.net/qq_56044032?spm=1000.2115.3001.5343")
time.sleep(3)whileTrue:for i inrange(1,80):if(i ==36or i ==38):
driver.execute_script("window.scrollBy(0,143)")continue# 拼接文章的Xpath
driver.find_element_by_xpath(str1 +str(i)+ str2).click()print(str1 +str(i)+ str2)# 进行子窗口切换,以至于不是关闭的主窗口
driver.switch_to.window(driver.window_handles[1])
time.sleep(2)# 关闭子窗口
driver.close()# 切换主窗口
driver.switch_to.window(driver.window_handles[0])# 向下滑动
driver.execute_script("window.scrollBy(0,143)")
time.sleep(2)# 回到顶部
driver.execute_script("var q=document.documentElement.scrollTop=0")
time.sleep(2)
driver.quit()
版权归原作者 你好,冯同学 所有, 如有侵权,请联系我们删除。