
confluent官网:https://debezium.io/documentation/reference/stable/connectors/sqlserver.html
Debezium官网:https://debezium.io/documentation/reference/stable/connectors/sqlserver.html
一、什么是 Kafka Connect?
Kafka Connect 是 Apache Kafka® 的一个免费开源组件,可作为集中式数据中心,用于在数据库、键值存储、搜索索引和文件系统之间进行简单的数据集成。
您可以使用 Kafka Connect 在 Apache Kafka 和其他数据系统之间流式传输数据,并快速创建用于将大型数据集移入和移出 Kafka® 的连接器。
二、Kafka Connect 下载(sql server下载举例)
confluent官网下载地址:
https://www.confluent.io/hub/debezium/debezium-connector-sqlserver


三、Kafka Connect 启动
1、修改配置文件(文件在kafka的安装目录有)
vim /opt/kafka/connect-config/connect-distributed.properties
bootstrap.servers=192.168.26.25:9092
group.id=connect-cluster
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
offset.flush.interval.ms=10000
plugin.path=/data/qys/infra/kafka_2.12-3.6.1/plugins
topic.creation.default.partitions=1
topic.creation.default.replication.factor=1
主要修改内容:
- 指定好bootstrap server地址 bootstrap.servers
- 默认分区与分片 topic.creation.default.partitions=1 topic.creation.default.replication.factor=1
- 插件地址 plugin.path=
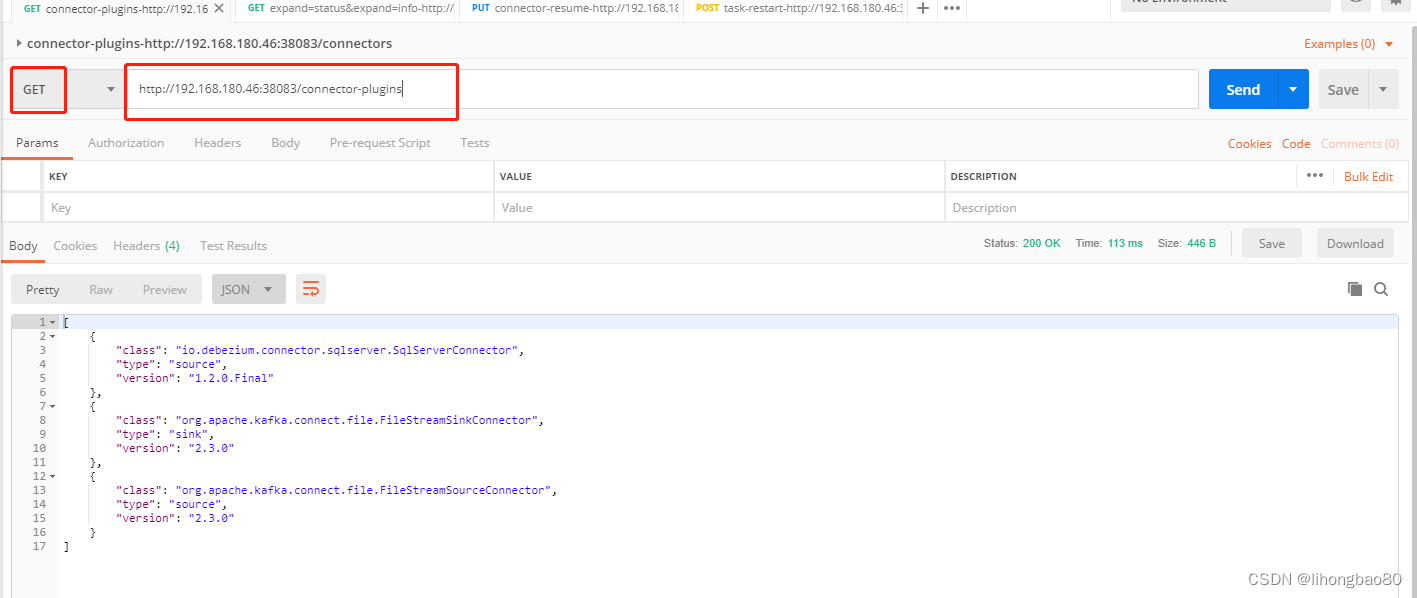
2、下载插件
参照
二、Kafka Connect 下载
3、启动kafka-connect进程(前提kafka已经启动)
/opt/kafka/bin/connect-distributed.sh -daemon /opt/kafka/config/connect-distributed.properties
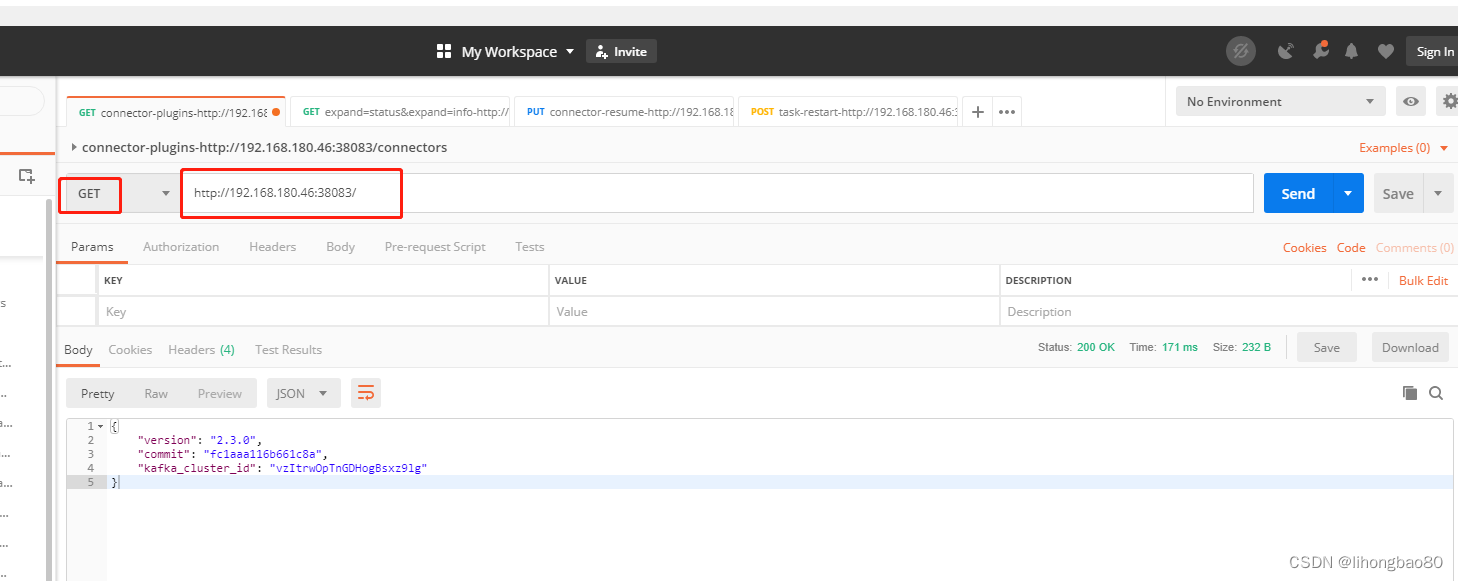
**
postman查看
**
四、docker-compose启动kafka-connect示例
1、修改配置文件(文件在kafka的安装目录有)
vim ./kafka-connect/conf/connect-distributed.properties(参照上文
三
的
1
)
2、下载sql server
参照
二、Kafka Connect 下载
3、docker-compose.yaml
version: '2.4'
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zk
ports:
-"2181:2181"
restart: always
volumes:
-./zookeeper_data:/opt/zookeeper-3.4.13/data
kafka1:
image: wurstmeister/kafka:2.12-2.3.0
container_name: kafka1
ports:
-"32771:9092"
environment:
TZ: Asia/Shanghai # 设置为所需的时区
KAFKA_ADVERTISED_HOST_NAME: 192.168.180.46
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
volumes:
-/var/run/docker.sock:/var/run/docker.sock
-./kafka_data/kafka1_data:/kafka
restart: always
depends_on:
- zookeeper
kafka2:
image: wurstmeister/kafka:2.12-2.3.0
container_name: kafka2
ports:
-"32772:9092"
environment:
TZ: Asia/Shanghai # 设置为所需的时区
KAFKA_ADVERTISED_HOST_NAME: 192.168.180.46
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
volumes:
-/var/run/docker.sock:/var/run/docker.sock
-./kafka_data/kafka2_data:/kafka
restart: always
depends_on:
- zookeeper
kafka3:
image: wurstmeister/kafka:2.12-2.3.0
container_name: kafka3
ports:
-"32773:9092"
environment:
TZ: Asia/Shanghai # 设置为所需的时区
KAFKA_ADVERTISED_HOST_NAME: 192.168.180.46
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_AUTO_CREATE_TOPICS_ENABLE: 'true'
volumes:
-/var/run/docker.sock:/var/run/docker.sock
-./kafka_data/kafka3_data:/kafka
restart: always
depends_on:
- zookeeper
kafka-connect:
image: wurstmeister/kafka:2.12-2.3.0
container_name: connect
ports:
-"38083:8083"
entrypoint:
-/opt/kafka/bin/connect-distributed.sh
-/opt/kafka/connect-config/connect-distributed.properties
volumes:
-/etc/localtime:/usr/share/zoneinfo/Asia/Shanghai
-/var/run/docker.sock:/var/run/docker.sock
-./kafka-connect/conf:/opt/kafka/connect-config-./kafka-connect/plugins:/opt/bitnami/kafka/plugin
restart: always
depends_on:
- zookeeper
kafka-client:
image: wurstmeister/kafka:2.12-2.3.0
entrypoint:
- tail
--f
-/etc/hosts
volumes:
-/var/run/docker.sock:/var/run/docker.sock
-./kafka-connect/conf:/opt/kafka/connect-config-./kafka-connect/plugins:/opt/kafka/plugins
restart: always
depends_on:
- zookeeper
kafdrop:
image: obsidiandynamics/kafdrop
container_name: kafdrop
restart: "no"
ports:
-"9000:9000"
environment:
KAFKA_BROKERCONNECT: "kafka1:9092,kafka2:9092,kafka3:9092"
TZ: Asia/Shanghai # 设置为所需的时区
depends_on:
- zookeeper
- kafka1
- kafka2
- kafka3
五、postman创建SQLserver的connec
1、sqlserver数据库开启cdc
-- 开启该库cdc
USE 库名
EXEC sys.sp_cdc_enable_db
GO
-- 开启表CDC
use 库名;
EXEC sys.sp_cdc_enable_table
@source_schema = N'schema名',
@source_name = N'表名',
@role_name = NULL,
@supports_net_changes = 1
GO
-- 关闭数据库CDC
USE 库名;
GO
EXEC sys.sp_cdc_disable_db
-- 关闭表的CDC功能
USE 库名;
GO
EXEC sys.sp_cdc_disable_table
@source_schema = N'schema名',
@source_name = N'表名',
@capture_instance = N'schema名_表名'
GO
-- 查看数据库开启cdc检查
SELECT name ,is_cdc_enabled FROM sys.databases WHERE is_cdc_enabled = 1
-- 查看表cdc开启情况
use Libby;SELECT name ,is_tracked_by_cdc FROM sys.tables WHERE is_tracked_by_cdc = 1
2、创建sqlserver的connect
postman创建connect
{"name": "cdc_mdata_test_3","config": {"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector","database.hostname": "192.168.180.44","database.port": "1433","database.user": "sdp","database.password": "shared@123","database.dbname": "Libby","table.whitelist": "MappingData.test","database.server.name": "cdc_mdata_test_3","database.history.kafka.bootstrap.servers": "192.168.180.46:32771","database.history.kafka.topic": "cdc_mdata_test_3","transforms": "Reroute","transforms.Reroute.type": "io.debezium.transforms.ByLogicalTableRouter","transforms.Reroute.topic.regex": "cdc_mdata_(.*)","transforms.Reroute.topic.replacement": "cdc_md_combine","errors.tolerance": "all"}}
postman查看创建的connect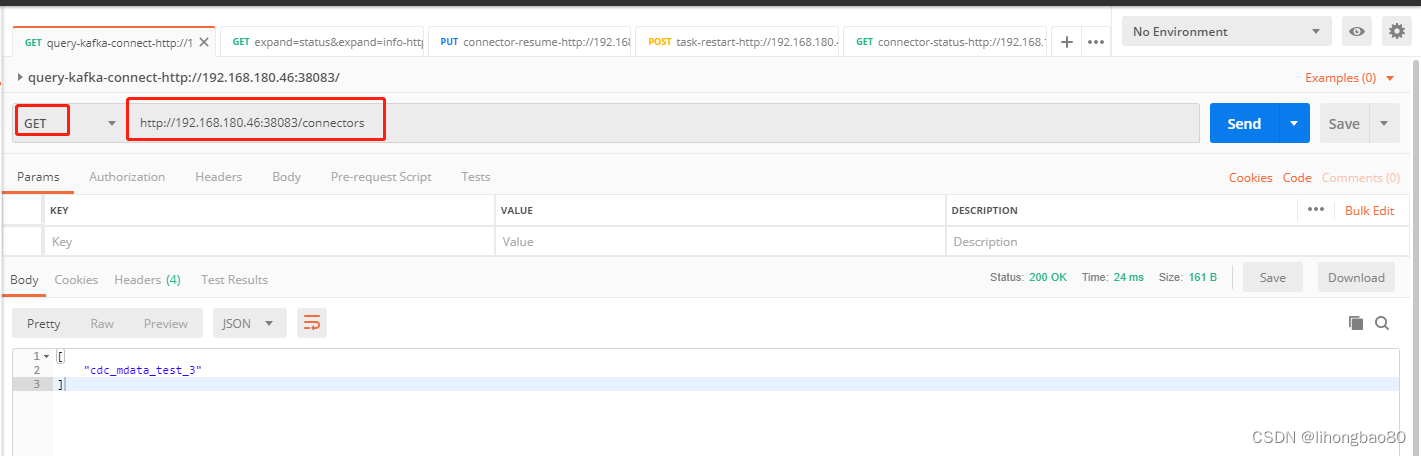
六、connect的restapi
1、参考网址:
https://docs.confluent.io/platform/current/connect/references/restapi.html
2、常用restapi举例
标签:
kafka
kafka-connector
本文转载自: https://blog.csdn.net/lihongbao80/article/details/136937970
版权归原作者 lihongbao80 所有, 如有侵权,请联系我们删除。
版权归原作者 lihongbao80 所有, 如有侵权,请联系我们删除。