
背景
2023年双11高峰之际,实时平台有一个消费Kafka写hudi的Flink SQL类型的实时任务,每天Kafka流入的高峰时段有近350万/分钟的流入量,而任务的消费速率平均在230万/分钟左右,这导致任务写hudi遇到较严重性能瓶颈和消息积压,对业务造成影响。任务的具体积压情况如下图1所示。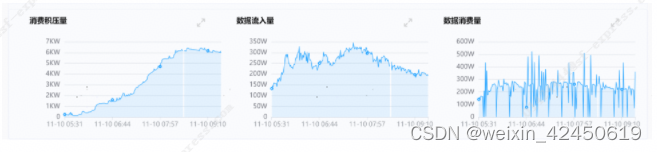
图1 任务消费积压图(X轴是时间,单位分钟,Y轴是消息数量)
针对上述情况,我们对任务进行了分析和优化,解决了此任务写hudi的性能问题,满足了高峰的要求。具体分析处理方法我们继续看。
2 问题排查和处理
首先我们进入任务的Flink Web UI页面,查看到任务在没有做checkpoint时的执行图,没有发现明显的背压情况,如下图所示。
图2 没有背压时的执行图
当任务做checkpoint时,会有严重的背压,如下图所示。这是写hudi的特性决定的,在做checkpoint时,hudi才会写入数据到HDFS上,并有可能做compaction。
图3 有背压时的执行图
2.1 分析并调整Kafka读取参数
可以看到,此Kafka有32个分区,分区数设置还是比较合理的。
由于任务不做checkpoint时没有背压,我们最初怀疑有可能是Kafka的消费能力有瓶颈,于是第一步对Kafka的性能进行调优和验证。
说明:实际上这个任务Kafka并不是最主要的问题,后面有分析。
这里想说一下,Kafka的读写性能都是十分强悍的,因此请不要轻易怀疑Kafka的性能问题。但对于每分钟几百万甚至上千万的消息流入量,我们还是应该关注Kafka的性能,类似这个任务的数据量。
这个任务的Flink SQL的初始语句如下所示。
createtable kafka.test (
__useless__ int,
kafka_ts TIMESTAMP(3) METADATA FROM'timestamp' VIRTUAL
)with('connector'='kafka','_version_'='V011'
本文转载自: https://blog.csdn.net/weixin_42450619/article/details/134832481
版权归原作者 weixin_42450619 所有, 如有侵权,请联系我们删除。
版权归原作者 weixin_42450619 所有, 如有侵权,请联系我们删除。