

一、介绍
1、背景
目前java主流常用微服务框架有Dubbo和SpringCloud,bubbo在国内很火,但是在2014年的时候因为不知名原因停更了。随后Spring在2016年的时候发布了SpringCloud。随后将netflix公司开源的组件集成了进来,诞生了SpringCloud-netflix版,然后由于netflix不在开发,进入维护模式后,在2020年发布了alibaba版本,nacos就产生于SpringCloud (alibaba)版本提供的组件中。
2、简介
**Nacos**(Dynamic Naming and Configuration Service)是构建以 “**服务**” 为中心的现代应用架构 (例如微服务范式、云原生范式) 的服务基础设施。致力于服务发现、配置和管理,且提供了一组简单易用的特性集。让微服务的发现、管理、共享、组合更加容易。
二、版本对比
CAP原则
consistency:数据一致性
availability:高可用性
partition tolerance:分区容错性
分布式架构只能满足x其中两种,不可能全部都满足
AC:单点集群,满足一致性,可用性,可扩展性不强
CP:保证数据一致性。在整个系统中保证数据时刻一致,强一致性,一旦数据不一致就会出现提示:用户系统异常
AP: 保证高可用,即保证某个服务故障仍然可以正常访问,牺牲了数据的一致性。一旦网络或者服务恢复就会进行数据同步保证数据最终一致性。
注册中心:特性更加适合AP,基于内存,保证高可用所以在Nacos中使用Distro协议;
配置中心:特性需要保证各节点配置是同步的,基于存储设备,所以使用的JRaft协议;
1、AP与CP结合
Nacos 1.x版本架构

Nacos 2.x版本架构

在新的 Nacos 架构中,已经完成了将⼀致性协议从原先的服务注册发现模块下沉到了 内核模块当中,并且尽可能的提供了统⼀的抽象接口,使得上层的服务注册发现模块以及配置管理模块,不再需要耦合任何⼀致性语义,解耦抽象分层后,每个模块能快速演进,并且性能和可用性 都大幅提升
2、长连接代替短连接
长连接
优点:可以省去较多的TCP建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户端适合使用长连接。
缺点:client端一般不会主动关闭连接,当client与server之间的连接一直不关闭,随着客户端连接越来越多,server会保持过多连
接。server端需要采取一些策略来控制
使用场景:长连接多用于操作频繁,点对点的通讯,而且连接数不能太多情况。
短连接
优点:对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。
缺点:客户端和服务器每进行一次HTTP操作,就建立一次连接,任务结束就中断连接。需要频繁的建立连接
使用场景:WEB网站的http服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,而像WEB网站这么频繁的成千上万甚至上亿客户端的连接用短连接
Nacos 1.X
Nacos 1.X 采用 Http 1.1 短连接模拟长连接,每 30s 发⼀个心跳跟 Server 对比 SDK 配置 MD 5 值是否跟 Server 保持⼀致,如果⼀致就 hold 住链接,如果有不⼀致配置,就把不⼀致的配置 返回,然后 SDK 获取最新配置值。
Nacos 2.X
Nacos 2.x 相比上面 30s ⼀次的长轮训,升级成长连接模式,配置变更,启动建立长连接,配置变更服务端推送变更配置列表,然后SDK 拉取配置更新,因此通信效率大幅提升。
3、服务架构
Nacos 1.X 版本
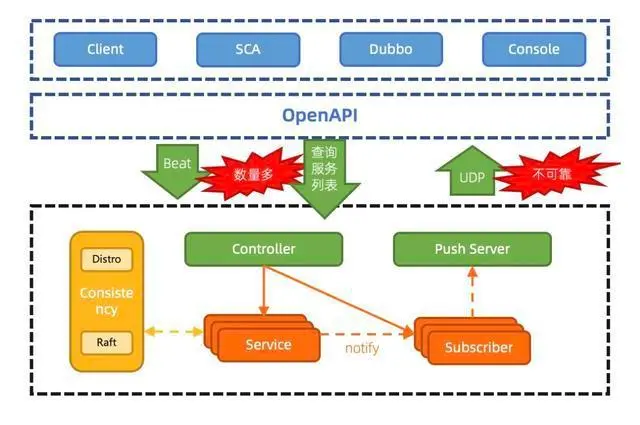
存在的问题
1、心跳数量多,导致 TPS 居高不下
通过心跳续约,当服务规模上升时,特别是类似 Dubbo 的接口级服务较多时,心跳及配置元数据的轮询数量众多,导致集群 TPS 很
高,系统资源高度空耗
2、通过心跳续约感知服务变化,时延长
心跳续约需要达到超时时间才会移除并通知订阅者,默认为 15s,时延较长,时效性差。若改短超时时间,当网络抖动时,会频繁触
发变更推送,对客户端服务端都有更大损耗
3、UDP 推送不可靠,导致 QPS 居高不下
由于 UDP 不可靠,因此客户端则需要每隔一段时间进行对账查询,保证客户端缓存的服务列表的状态正确,当订阅客户端规模上升
时,集群 QPS 很高,但大多数服务列表其实不会频繁改变,造成无效查询,从而存在资源空耗
4、基于 HTTP 短连接模型,TIME_WAIT 状态连接过多
HTTP 短连接模型,每次客户端请求都会创建和销毁 TCP 链接,TCP 协议销毁的链接状态是 WAIT_TIME,完全释放还需要一定时
间,当 TPS 和 QPS 较高时,服务端和客户端可能有大量的 WAIT_TIME 状态链接,从而会导致连接超时
5、配置模块的 30 秒长轮询引起的频繁 GC
配置模块使用 HTTP 短连接阻塞模型来模拟长连接通信,但是由于并非真实的长连接模型,因此每 30 秒需要进行一次请求和数据的
上下文切换,每一次切换都有引起造成一次内存浪费,从而导致服务端频繁 GC
Nacos 2.X 版本
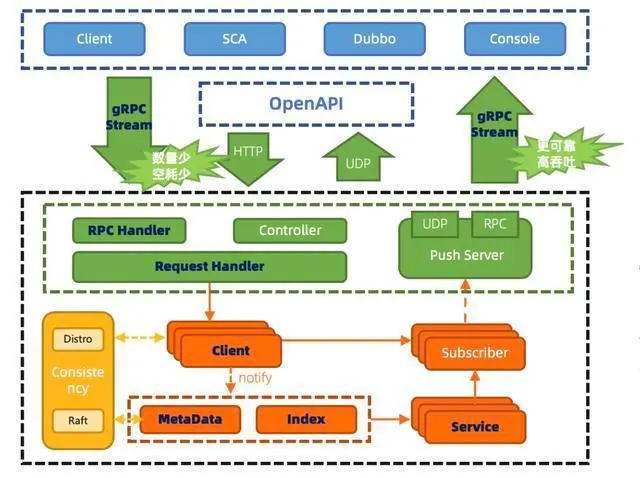
Nacos 2.X 在 1.X 的架构基础上 新增了对长连接模型的支持,同时保留对旧客户端和 openAPI 的核心功能支持。通信层通过 gRPC 和 Rsocket 实现了长连接 RPC 调用和推送能力。
1、客户端不再需要定时发送实例心跳,只需要有一个维持连接可用 keepalive 消息即可。重复 TPS 可以大幅降低。
2、TCP 连接断开可以被快速感知到,提升反应速度。
3、长连接的流式推送,比 UDP 更加可靠;nio 的机制具有更高的吞吐量,而且由于可靠推送,可以加长客户端用于对账服务列表的时间,甚至删除相关的请求。
重复的无效 QPS 可以大幅降低。
4、长连接避免频繁连接开销,可以大幅缓解 TIME_ WAIT 问题。
5、真实的长连接,解决配置模块 GC 问题。
6、更细粒度的同步内容,减少服务节点间的通信压力。
4、通信协议
功能/版本
1.x distro
2.x distro
1.x raft
2.x raft
注册/注销
http
grpc
grpc
http
订阅
http
grpc
grpc
grpc
心跳/健康检查
http
TCP
TCP
TCP/http/mysql
推送
udp
grpc
grpc
grpc
集群间数据同步
http/distro
grpc/distro
grpc/distro
jraft
5、同步协议
临时实例
临时实例:靠client的心跳或连接保活,当不存活时,直接下线实例;适用于主动注册的服务
永久实例:注册后不用保活,靠服务端健康检查来判断实例是否健康,不健康实例也不用下线;适用于ip不常变化的场景
在Nacos中他们的主要区别如下:
emphemral
true
false
名称
临时实例
永久实例
CAP
AP
CP
一致性协议
distro
raft
是否持久化
否
是
健康检查方式
心跳/连接
服务端检查(TCP、HTTP、MYSQL)
1、Distro协议
概念
Distro 协议是 Nacos 社区自研的⼀种 AP 分布式协议,是面向临时实例设计的⼀种分布式协议, 其保证了在某些 Nacos 节点宕机后,整个临时实例处理系统依旧可以正常工作。作为⼀种有状态 的中间件应用的内嵌协议, 保证了各个 Nacos 节点对于海量注册请求的统⼀协调和存储
设计思想
Nacos 每个节点是平等的都可以处理写请求,同时把新数据同步到其他节点。
每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据⼀致性。
每个节点独立处理读请求,及时从本地发出响应。
实现原理
1、数据初始化
新加入的Distro节点会进行全量数据拉取。具体操作是轮询所有的Distro节点,通过向其他的机器发送请求拉取全量数据。在全量拉取操作完成之后,Nacos的每台机器上都维护了当前的所有注册上来的非持久化实例数据。
2、数据校验
在Distro集群启动之后,各台机器之间会定期的发送心跳进行数据校验。如果某台机器校验发现与其他机器数据不一致,则会进行全量拉去请求将数据补齐。
3、写操作
当注册非持久化的实例的写请求打到某台Nacos服务器时,首先被Filter拦截,根据请求的IP端口信息转发到对应的Distro责任节点上处理请求。Distro协议还会定期执行Sync任务,将本机所负责的所有的实例信息同步到其他节点上。
4、读操作
读操作,由于每台机器上都存放了全量数据,因此在每⼀次读操作中,Distro机器会直接从本地拉取数据,快速响应
小结
这种机制保证了 Distro 协议可以作为⼀种 AP 协议,对于读操作都进行及时的响应。在网络分区 的情况下,对于所有的读操作也能够正常返回;当网络恢复时,各个 Distro 节点会把各数据分片的 数据进行合并恢复。
2、raft
6、推送机制代替轮询机制
推送机制:
客户端,通过客户端来选择可获节点,比如它第⼀次拉取的是⼀个正常节点,这个正常节点就会 跟它维护⼀个订阅关系,后面有变化就会有⼀个相应的实地变化推送给我。如果当前节点挂掉,他会通过重连, 在节点列表上,连上⼀个正常的节点。这时候会有新的 DNS 关系出现。
SDK ,在服务端寻找可获节点。服务端每个节点之间,会进行⼀个可活的探 测,选择其中⼀个可活节点用户维护这个订阅关系。当这个节点出现问题,连接断开后,SDK 重新发送订阅请求,服务端会再次选择另外⼀个可活的节点来维护这个订阅关系。这就保证整了推送过 程不会因为某个节点挂掉而没有推送
推送的效率方面,主要是用 UDP 的方式。
7、数据模型
1 - 服务
概念:
**服务指的是由应用程序提供的⼀个或⼀组软件功能的⼀种抽象概念(例如登陆或支付)。它和应用有所不同,应用的范围更广,和服务属于包含关系,即⼀个应用可 能会提供多个服务。为了能够更细粒度地区分和控制服务,Nacos 选择服务作为注册中心的最基本 概念。**
定义服务
命名空间(Namespace)
分组(Group)
服务名(Name)
服务元数据
健康保护阈值(ProtectThreshold)
实例选择器(Selector)
拓展数据(extendData)
2 - 服务实例
概念:
**服务实例是某个服务的具体提供能力的节点,⼀个实例仅从属于⼀个服务,而⼀个服务可以包含⼀个或多个实例。在许多场景下,实例又被称为服务提供者(Provider),而使用该服务的实例被称为服务消费者(Consumer)**
定义实例
网络 IP 地址:该实例的 IP 地址,在 Nacos2.0 版本后支持设置为域名。
网络端口:该实例的端口信息
健康状态(Healthy)
集群(Cluster)
拓展数据(extendData)
实例元数据
权重(Weight):实例级别的配置。权重为浮点数,范围为 0-10000。权重越大,分配给该实例 的流量越大
上线状态(Enabled):标记该实例是否接受流量,优先级大于权重和健康状态。用于运维人员 在不变动实例本身的情况下,快速地手动将某个实例从服务中移除
拓展数据(extendData)
3 - 小结
1、定义实例的网络ip地址支持域名
2、 Nacos2.0 版本中,实例数据被拆分为实例定义和实例元数据
原因如下:
实例数据使用场景不同
运维操作需要保证操作的原子性,不能够因为外部环境的影响 而导致操作被重置
3、Nacos2.0 版本中定义实例的这部分数据,会受到持久化属性的的影响,而实例元数据部分,会默认进行持久化,在对应实例删除后保
存一段时间。
三、问题记录
1、dubbbo 发布元数据失败
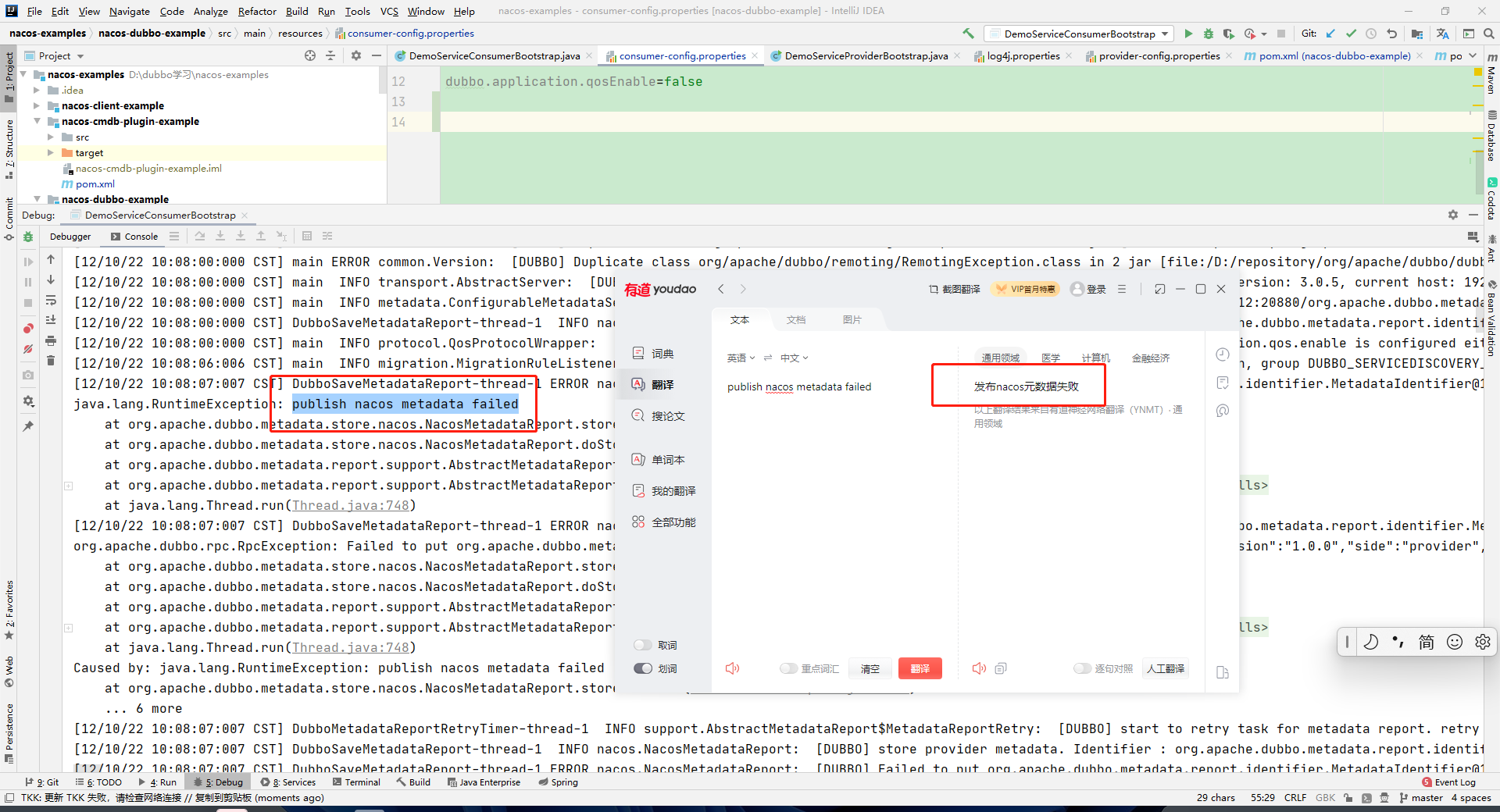
原因是nacos有安全验证,需要设置密码

4、拓展
1、ReferenceConfig
缓存ReferenceConfig
在Dubbo 中使用
ReferenceConfig
实例很重,因为封装了与注册中心的连接以及与提供者的连接,需要缓存。否则重复生成
ReferenceConfig
可能造成性能问题并且会有内存和连接泄漏。在 API 方式编程时,容易忽略此问题。
2.4.0
版本开始, dubbo 提供了简单的工具类
ReferenceConfigCache
用于缓存
ReferenceConfig
实例。
ReferenceConfig<XxxService> reference = new ReferenceConfig<XxxService>();
reference.setInterface(XxxService.class);
reference.setVersion("1.0.0");
......
ReferenceConfigCache cache = ReferenceConfigCache.getCache();
// cache.get方法中会缓存 Reference对象,并且调用ReferenceConfig.get方法启动ReferenceConfig
XxxService xxxService = cache.get(reference);
// Cache会持有ReferenceConfig,不要在外部再调用ReferenceConfig的destroy方法,导致Cache内的ReferenceConfig失效!
// 使用xxxService对象
xxxService.sayHello();
自定义key
ReferenceConfigCache
把相同服务 Group、接口、版本的
ReferenceConfig
认为是相同,缓存一份。即以服务 Group、接口、版本为缓存的 Key。在
ReferenceConfigCache.getCache
时,传一个
KeyGenerator
。可以自定义key。
KeyGenerator keyGenerator = new ...
ReferenceConfigCache cache = ReferenceConfigCache.getCache(keyGenerator );
2、dubbo的service改为dubboService
5、参考文献
nacos官网:什么是 Nacos
nacos版本更新大纲:Dubbo生态-Nacos三大使用建议,公开 Nacos3.0 规划图
nacos架构&原理:文件下载-阿里云开发者社区
nacos架构设计新模型:支持gRPC长链接,深度解读Nacos2.0架构设计及新模型
版权归原作者 .小白菜. 所有, 如有侵权,请联系我们删除。