

介绍
食物是我们生活中不可分割的一部分。据观察,当一个人选择吃东西时,通常会考虑食材和食谱。受食材和烹饪风格的影响,一道菜可能有数百或数千种不同的菜谱。网站上的菜谱展示了做一道菜所需要的食材和烹饪过程。但问题是,用户无法识别哪些菜可以用自己现有的食材烹饪。为了克服这些问题,机器学习方法能够根据用户可用的材料提出菜谱。
因此,在我们进一步研究机器学习如何在食品工业中使用之前,让我们先了解更多关于自然语言处理(NLP)的知识。
NLP是什么
自然语言是指人类用来相互交流的语言。这种交流可以是口头的,也可以是文本的。例如,面对面的对话,推特,博客,电子邮件,网站,短信,都包含自然语言。然而,要使计算机容易地理解和处理这种自然语言,就需要应用规则和算法,以便将非结构化数据转换为计算机能够理解的形式。
句法分析和语义分析是完成自然语言处理任务的主要技术。“句法”指的是词语在句子中的排列,使它们具有语法意义,而“语义”指的是文本所传达的意思
有了这些规则和字嵌入算法,我们将自然语言字转换为计算机可以理解的数字格式。
Word Embedding 字嵌入
单词嵌入是一种单词表示,它允许机器学习算法理解具有相似意思的单词。又称分布式语义模型或语义向量空间或向量空间模型;这意味着在向量空间中对相似单词的向量进行分类或分组。它背后的想法相当简单:你应该通过它的同伴来认识一个单词。因此,有相似邻居的词,即。用法上下文是差不多的,很可能有相同的意思或至少是高度相关的。
Word2Vec -一种单词嵌入方法
Word2Vec是一种单词嵌入方法,由Tomas Mikolov开发,被认为是最先进的。Word2Vec方法利用深度学习和基于神经网络的技术,将单词转换为相应的向量,使语义相似的向量在N维空间中相互接近,其中N表示向量的维数。
究竟为什么我们需要在分析食物配方和配料时嵌入文字呢?嗯,我们需要一些方法来将文本和分类数据转换为数字机器可读的变量,如果我们想比较一个配方和另一个配方。在本教程中,我们将学习如何使用Word2Vec:
- 暗示相似的概念——在这里,单词嵌入帮助我们暗示与被置于预测模型中的单词相似的成分。
- 创建一组相关词:用于语义分组,将特征相似的事物聚在一起,不相似的事物远远聚在一起。
- 找到不相关的概念
- 计算两个或更多单词之间的相似度
这篇文章的目的是为那些有兴趣进一步探索这一领域的人提供一个参考和起点。
食物的食谱数据集
让Word2Vec真正为您工作的秘密是在相关领域中拥有大量文本数据。在本教程中,我们将使用数据集,该数据集包含大约5000个不同烹饪方法和不同配料的食谱。
数据清理和预处理
让我们首先将菜谱加载到pandas dataframe并删除空行
#load the recipes dataset
filepath = "/kaggle/input/foodrecipes/recipes.csv"
df_recipes = pd.read_csv(filepath, encoding="ISO-8859-1")
#drop rows where cuisine, ingregients are NA
df_recipes.dropna(subset=['cuisine', 'ingredients'],inplace=True)
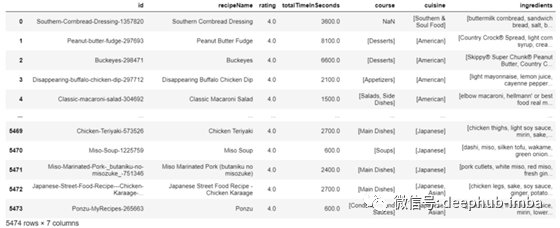
df_recipes
结果是大约5400个食谱,分别列有食谱名称、等级、课程类型、烹饪方法和每个食谱所需的配料表。
原始数据在有大量的打字错误、停止字\不必要的间隔、标点、数字等被删除的地方总是容易产生干扰。所涵盖的其他预处理包括,
配料以复数形式表示(例如用tomatoes 代替tomato; potatoes替代potato),需要转换为单数形式,以减少单词的维数。
大多数配料都以形容词作为前缀,例如干番茄、榨柠檬、新鲜香菜等。这些词(干的,压缩的,新鲜的等等)在生成有意义的词嵌入没有用处。因此,可以使用正则表达式函数来删除这些内容。
下面是清理和预处理配料数据的脚本:
#convert to lower case
df_recipes['ingredients'] = df_recipes['ingredients'].apply(lambda x: x.lower())
total_ingredients = []
all_receipes_ingredients = []
for i in range(len(df_recipes)):
all_ingredients = list()
#split each recipe into different ingredients
ingred = df_recipes.loc[i, "ingredients"][1:-1]
for ing in (ingred.split(',')):
ing = remove_stopwords(ing)
ing = strip_numeric(ing)
ing = re.sub(r'\(.*oz.\)|(®)|(.*ed)|(.*ly)|boneless|skinless|chunks|fresh|large|cook drain|green|frozen|ground','',ing).strip()
ing = strip_short(ing,2)
ing = strip_multiple_whitespaces(ing)
ing = strip_punctuation(ing)
ing = strip_non_alphanum(ing)
#convert plurals to singular e.g. tomatoes --> tomato
ing = (" ".join(TextBlob(ing).words.singularize()))
all_ingredients.append(ing)
total_ingredients.append(ing)
all_receipes_ingredients.append(all_ingredients)
counts_ingr = collections.Counter(total_ingredients)
print('Size Ingredients dataset (with repetition): \t{}'.format((len(total_ingredients))))
print('Unique Ingredients dataset: \t\t\t{}'.format((len(counts_ingr.values()))))
print('Size Receipes dataset: \t{}'.format((len(all_receipes_ingredients))))

从调查结果可以看出,5400多份食谱总共使用了5万种食材,其中2600多种食材经过预处理后看起来是独一无二的。
#add cleaned ingredients back to original dataframe
df_recipes['clean_ingredients'] = pd.Series(all_receipes_ingredients)
#record the number of ingredients for each recipe
df_recipes['ingredient_count'] = df_recipes.apply(lambda row: len(row['clean_ingredients']), axis = 1)
#convert time in seconds to minutes
df_recipes['timeMins'] = df_recipes.totalTimeInSeconds.apply(lambda x: x/60)
现在,让我们来探讨一下最常见和最不常见的配料。
#find the most common ingredients used across all recipes
print ("---- Most Common Ingredients ----")
print (counts_ingr.most_common(10))print ("\n")#find the most common ingredients used across all recipes
print ("---- Least Common Ingredients ----")
print (counts_ingr.most_common()[-10:])

让我们用词云可视化技术来可视化它。
#visualize the ingredients in WordCloud
from wordcloud import WordCloud
def plot_wordcloud(text, title=None, max = 1000, size=(12,8), title_size=16):
"""plots wordcloud"""
wordcloud = WordCloud(max_words=max).generate(text)
plt.figure(figsize=size)
plt.title(title, size=title_size)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plot_wordcloud(' '.join(total_ingredients), title='Ingredients')

训练Word2Vec
使用Gensim,创建Word2Vec模型非常简单。成分列表被传递给gensim的Word2Vec类。模型包。Word2Vec使用所有这些标记在内部创建词汇表。
#Train the Word2Vec model
num_features = 300
# Word vector dimensionality - The size of the dense vector to represent each token or word
#(i.e. the context or neighboring words). If you have limited data, then size should be a much smaller value
#since you would only have so many unique neighbors for a given word
min_word_count = 4
# Minimium frequency count of words. The model would ignore words that do not satisfy the min_count.
num_workers = 4 # How many threads to use behind the scenes?
context = 10
# The maximum distance between the target word and its neighboring word.
downsampling = 1e-2
# threshold for configuring which higher-frequency words are randomly downsampled
# Initialize and train the model
model = word2vec.Word2Vec(all_receipes_ingredients, workers=num_workers, \
size=num_features, min_count = min_word_count, \
window = context,sample = downsampling, iter=20)
# If you don't plan to train the model any further, calling
# init_sims will make the model much more memory-efficient.
model.init_sims(replace=True)
在上面的步骤中,使用成分列表构建词汇表,并开始训练Word2Vec模型。在幕后,我们训练一个具有单一隐含层的神经网络来基于上下文预测当前的单词。目标是学习隐含层的权值。这些权重就是我们要学习的单词向量。所得到的学习向量称为嵌入。
结果
第一个例子显示了与其他配料相似或至少相关的单词的简单查找(例如配料,如paneer, egg, mango, bread, rice)
# check the similar ingredients returned by the model for search_termssimilar_words = {search_term: [item[0] for item in model.wv.most_similar([search_term], topn=5)]
for search_term in ['paneer','egg','mango','bread', 'rice']}
similar_words

哇,看起来不错。让我们看看更多的配料
成分“巧克力”的类似或相关成分
model.wv.most_similar('chocolate')
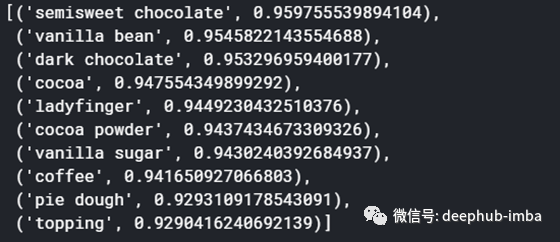
这种相似性把所有和“巧克力”密切相关的单词都显示出来了,比如黑巧克力,香草豆等等
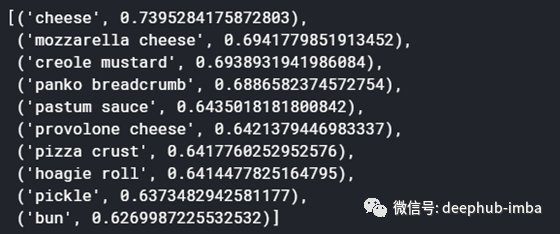
原料“蛋黄酱”的类似或相关成分
model.wv.most_similar('mayonnaise')
配料“鸡”中类似或相关的配料
model.wv.most_similar(‘chicken’)
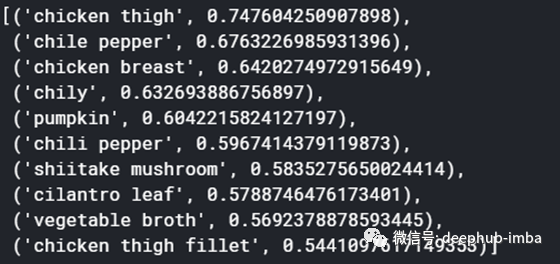
总的来说,这些结果是有意义的。所有相关的词都在相似的上下文中使用。现在让我们使用Word2Vec来计算词汇表中两个成分之间的相似性,方法是调用similarity(…)函数并传入相关的单词。
model.wv.similarity(‘paneer’, ‘chicken’)

在底层,模型使用每个指定单词的单词向量(嵌入)计算两个指定单词之间的余弦相似度。由此得出的分数是有意义的,因为“paneer”主要用于素食,而“chicken”用于非素食
另一个有趣的事情是识别食物类比,类似于单词类比。对于“面包是奶酪”这个类比,我们的目标是预测一个合理的类比“鸡肉是……”
x = ‘chicken’
b= ‘cheese’
a = ‘bread’
predicted = model.wv.most_similar([x, b], [a])[0][0]
print(“ {} is to {} as {} is to {} “.format(a, b, x, predicted))

评估Word2Vec
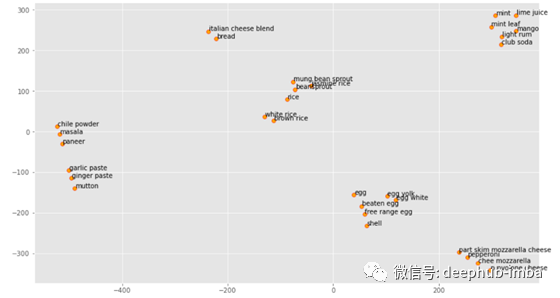
我们已经用word2vec创建了300个维度的嵌入。幸运的是,当我们想要可视化高维字嵌入时,我们可以使用降维技术。下面,我们可以看到t-SNE将常见成分投影到二维上的一些向量嵌入。下列成分的位置代表概率分布,而不是实际的空间位置。t-SNE图可能很难解释为超参数,可以大幅改变簇之间的大小和距离。然而,我们并没有试图解释簇,而是希望评估我们的模型是否从我们的菜谱中学到了一些有用的东西。
#visualization with Tsne
from sklearn.manifold import TSNE
words = sum([[k] + v for k, v in similar_words.items()], [])
wvs = model.wv[words]
tsne = TSNE(n_components=2, random_state=0, n_iter=1000, perplexity=2)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(wvs)
labels = words
plt.figure(figsize=(14, 8))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')
你可以看到,素食“奶酪”的原料就在附近,包括马萨拉,大蒜和生姜酱。这绝对是有道理的。同样,所有的食材,如“鸡蛋”、“芒果”也都在眼前。
接下来是什么?
上面的教程只讨论了食谱的配料部分。还有许多其他可以进一步实现的用例或探索想法。下面是一些问题,我将尝试在后面的文章中构建并得到答案。
- 根据所提供的食材进行烹饪分类/预测
- 给定一个菜谱,从语料库中查找相似的菜谱
- 根据所提供的食材推荐食谱。
- 使用一组给定的配料,什么食谱可以准备。
总结
在识别文本中的信息时,抓住单词之间的意义和关系是非常重要的。这些嵌入为自然语言处理和机器学习中更复杂的任务和模型提供了基础。试着找到一些你可以输入的有趣的数据集和你可以找出的关于关系的东西——在这里随意评论你发现的任何有趣的东西。
你可以在这里找到我的Kaggle笔记本/kernel:
https://www.kaggle.com/ajitrajput/exploring-food-recipes-using-word2vec/notebook
作者:Ajit Rajput
deephub翻译组
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
喜欢就请三连暴击!********** **********