
前沿-同系列文章
用粗快猛 + 大模型问答 + 讲故事学习方式快速掌握大数据技术知识,每篇都有上万字,如果觉得太长,看开始的20%,有所收获就够了,剩下的其他内容可以收藏后再看~
序号技术栈文章链接🔗1Hadoophttps://hadoop.blog.csdn.net/article/details/1405092342Sparkhttps://hadoop.blog.csdn.net/article/details/1405084553MySQLhttps://hadoop.blog.csdn.net/article/details/1405610094Kafkahttps://hadoop.blog.csdn.net/article/details/1405618205Flinkhttps://hadoop.blog.csdn.net/article/details/1405612086Airflowhttps://hadoop.blog.csdn.net/article/details/1405668997Hbasehttps://blog.csdn.net/u012955829/article/details/1405827638Linuxhttps://blog.csdn.net/u012955829/article/details/1405831269YARNhttps://blog.csdn.net/u012955829/article/details/140622116?spm=1001.2014.3001.550110HDFShttps://blog.csdn.net/u012955829/article/details/140621370?spm=1001.2014.3001.550111Pythonhttps://blog.csdn.net/u012955829/article/details/140621066?spm=1001.2014.3001.550112EMRhttps://blog.csdn.net/u012955829/article/details/140622519?spm=1001.2014.3001.5501
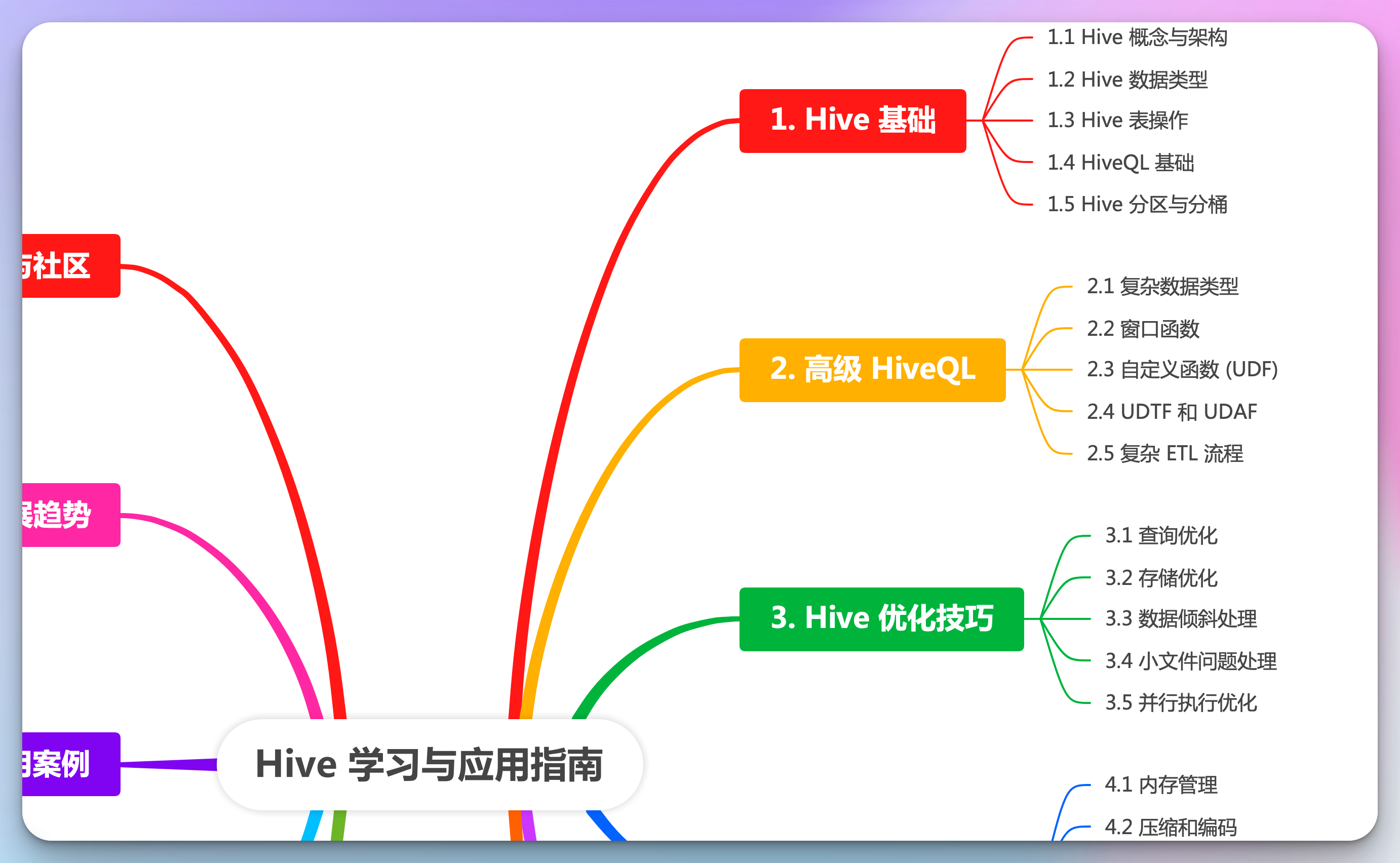
(本文大概图谱,完整思维导图见文末)
作为一名大数据开发者,我深知学习新技术的挑战。今天,我想和大家分享如何高效学习Hive的经验,希望能为正在或即将踏上大数据之路的你提供一些启发。
Part 1 初学Hive
Hive是什么?
在开始之前,让我们先简单了解一下Hive。Hive是一个建立在Hadoop之上的数据仓库工具,它能够将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。简单来说,Hive让我们可以用SQL的方式来查询和分析存储在Hadoop分布式文件系统中的海量数据。
我的"糙快猛"学习故事
还记得我刚接触大数据时的情景吗?作为一个零基础跨行的新手,面对繁杂的概念和技术,我曾一度感到迷茫。但很快,我领悟到了一个重要的学习方法:“糙快猛”。

什么是"糙快猛"?简单来说,就是:
- 糙:不追求一步到位的完美
- 快:以最快的速度掌握核心概念
- 猛:勇往直前,大胆实践
就拿学习Hive来说,我并没有一开始就钻研所有的理论知识,而是迅速搭建了一个Hive环境,开始动手实践。记得有一次,我需要分析一大堆日志数据。虽然对Hive还不是很熟悉,但我还是决定直接上手。
实践出真知:一个简单的Hive查询示例

让我们看一个具体的例子。假设我们有一张存储用户登录日志的表
user_logs
:
CREATETABLE user_logs (
user_id STRING,
login_time TIMESTAMP,
ip_address STRING
)ROW FORMAT DELIMITED
FIELDSTERMINATEDBY',';
现在,我们要统计每个用户的登录次数。以下是一个简单的HiveQL查询:
SELECT user_id,COUNT(*)as login_count
FROM user_logs
GROUPBY user_id
ORDERBY login_count DESCLIMIT10;
这个查询看起来很简单,对吧?但当我第一次写出这样的查询并成功运行时,那种成就感是无法言喻的!
为什么要"糙快猛"?
- 快速获得反馈:通过实践,我们可以快速了解自己掌握得如何,哪里还需要加强。
- 建立信心:每一个小成功都会增强我们的信心,激发学习动力。
- 发现真正的难点:实践中遇到的问题往往是最值得深入研究的。
- 培养实战能力:在"糙快猛"的过程中,我们不知不觉地培养了解决实际问题的能力。
如何更好地"糙快猛"?
- 利用大模型:像ChatGPT这样的大模型可以作为24小时助教,帮助我们快速理解概念,解决代码问题。
- 多动手:理论结合实践,遇到不懂的概念就去实验。
- 不怕犯错:错误是最好的老师,每次失败都是进步的机会。
- 保持节奏:找到适合自己的学习节奏,既不要松懈,也不要给自己太大压力。
- 培养审美:虽然我们追求"糙快猛",但也要逐步建立对代码质量、查询效率的审美。
结语
学习Hive,乃至于学习任何技术,都不需要一开始就追求完美。重要的是勇敢地迈出第一步,然后不断前进。记住,“在不完美的状态下前行才是最高效的姿势”。
Part 2 深入理解Hive

在"糙快猛"的学习过程中,我们不仅要快速上手,还要逐步深入理解Hive的核心概念和工作原理。以下是一些值得深入学习的方面:
1. Hive的架构
Hive的架构主要包括以下组件:
- 用户接口:包括CLI、JDBC/ODBC、WebUI
- 元数据存储:通常使用关系型数据库(如MySQL)存储表的schema和其他系统元数据
- 查询处理器:解析SQL,生成执行计划
- 执行引擎:默认使用MapReduce,也支持Tez、Spark等
理解这些组件如何协同工作,对于优化Hive查询和解决问题非常有帮助。
2. Hive数据类型和文件格式
Hive支持多种数据类型,包括基本类型(如INT、STRING)和复杂类型(如ARRAY、MAP、STRUCT)。同时,Hive也支持多种文件格式,如TextFile、SequenceFile、RCFile、ORC等。
了解这些数据类型和文件格式的特点,可以帮助我们根据实际需求选择最合适的存储方案。
3. 分区和分桶
分区和分桶是Hive中非常重要的概念,它们可以显著提高查询性能。
分区示例:
CREATETABLE user_logs_partitioned (
user_id STRING,
login_time TIMESTAMP,
ip_address STRING
)
PARTITIONED BY(dt STRING)ROW FORMAT DELIMITED
FIELDSTERMINATEDBY',';-- 加载数据到分区表INSERT OVERWRITE TABLE user_logs_partitioned
PARTITION(dt='2023-07-24')SELECT user_id, login_time, ip_address
FROM user_logs
WHERE TO_DATE(login_time)='2023-07-24';
分桶示例:
CREATETABLE user_logs_bucketed (
user_id STRING,
login_time TIMESTAMP,
ip_address STRING
)CLUSTEREDBY(user_id)INTO4 BUCKETS
ROW FORMAT DELIMITED
FIELDSTERMINATEDBY',';
进阶学习技巧
在掌握了基础之后,以下是一些进阶学习的建议:
- 深入源码:虽然"糙快猛"强调快速上手,但在有一定基础后,阅读Hive的源码可以帮助你更深入地理解其工作原理。
- 优化查询:学习如何分析和优化Hive查询是一项重要技能。了解Hive的执行计划、数据倾斜问题等概念。
EXPLAINSELECT user_id,COUNT(*)as login_countFROM user_logsGROUPBY user_id; - 自定义函数:学习如何编写自定义UDF(User-Defined Function)可以大大增强Hive的功能。
publicclassSimpleUDFextendsUDF{publicStringevaluate(String input){return input.toLowerCase();}} - 集成其他技术:学习如何将Hive与其他大数据技术(如Spark、HBase)集成使用。
- 参与开源社区:通过GitHub等平台参与Hive的开源项目,不仅可以提高编码能力,还能深入了解项目的发展方向。
实战项目:日志分析系统
为了将所学知识付诸实践,不妨尝试构建一个简单的日志分析系统。这个项目可以包括:
- 使用Flume收集日志数据
- 通过Hive创建外部表映射日志文件
- 编写HiveQL查询分析日志数据
- 使用Tableau或其他可视化工具展示分析结果
这样的项目能够帮助你综合运用Hive的各项功能,同时也能锻炼你的系统设计能力。
结语
记住,"糙快猛"的学习方法并不意味着浅尝辄止。它强调的是在学习过程中保持前进的动力,不断挑战自己。随着你在Hive领域的不断深入,你会发现还有很多值得探索的内容。
保持好奇心,不断实践,相信不久之后,你就能成为团队中的Hive大神!当你解决了一个复杂的数据分析问题,或者优化了一个效率低下的查询时,别忘了骄傲地说:“可把我牛逼坏了,让我叉会腰儿!”
Part3 Hive性能优化之道

在"糙快猛"地掌握了Hive的基础知识后,下一步就是学习如何优化Hive查询性能。这不仅能让你的查询跑得更快,还能让你在团队中脱颖而出。以下是一些常用的优化技巧:
1. 合理使用列式存储格式
ORC和Parquet是Hive中常用的列式存储格式,它们可以显著提高查询性能。例如:
CREATETABLE user_logs_orc (
user_id STRING,
login_time TIMESTAMP,
ip_address STRING
)
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");INSERTINTOTABLE user_logs_orc SELECT*FROM user_logs;
2. 使用索引
虽然Hive不支持像传统数据库那样的索引,但我们可以创建一些特殊的索引来提高查询性能:
CREATEINDEX idx_user_id ONTABLE user_logs_orc (user_id)AS'COMPACT'WITH DEFERRED REBUILD;ALTERINDEX idx_user_id ON user_logs_orc REBUILD;
3. 优化JOIN操作
大表JOIN是Hive中常见的性能瓶颈。以下是一些优化技巧:
- 使用Map Join:当一个表足够小时,可以将其完全加载到内存中。
SET hive.auto.convert.join=true;SET hive.mapjoin.smalltable.filesize=25000000; - 倾斜数据处理:对于数据分布不均匀的情况,可以使用倾斜数据优化。
SET hive.optimize.skewjoin=true;SET hive.skewjoin.key=100000;
4. 合理设置参数
一些Hive配置参数可以显著影响查询性能:
SET mapred.reduce.tasks =32;-- 设置reduce任务数SET hive.exec.parallel=true;-- 开启并行执行SET hive.exec.parallel.thread.number=16;-- 设置并行度
实际案例研究:电商平台用户行为分析
让我们通过一个实际案例来综合运用我们所学的Hive知识。假设我们是一个大型电商平台的数据分析师,需要分析用户的购物行为。
步骤1:数据建模
首先,我们需要创建相应的表结构:
CREATETABLE user_behavior (
user_id STRING,
item_id STRING,
category_id STRING,
behavior_type STRING,timestampBIGINT)
PARTITIONED BY(dt STRING)
STORED AS ORC;
步骤2:数据ETL
假设我们每天都有新的日志数据需要导入:
INSERT OVERWRITE TABLE user_behavior
PARTITION(dt='2023-07-25')SELECT user_id, item_id, category_id, behavior_type,timestampFROM raw_logs
WHERE TO_DATE(FROM_UNIXTIME(timestamp))='2023-07-25';
步骤3:数据分析
现在我们可以进行一些有意思的分析了:
- 计算每个类别的点击量、收藏量、加购量和购买量:
SELECT
category_id,SUM(CASEWHEN behavior_type ='pv'THEN1ELSE0END)as pv_count,SUM(CASEWHEN behavior_type ='fav'THEN1ELSE0END)as fav_count,SUM(CASEWHEN behavior_type ='cart'THEN1ELSE0END)as cart_count,SUM(CASEWHEN behavior_type ='buy'THEN1ELSE0END)as buy_count
FROM user_behavior
WHERE dt ='2023-07-25'GROUPBY category_id;
- 计算用户的购买转化率:
WITH user_funnel AS(SELECT
user_id,MAX(CASEWHEN behavior_type ='pv'THEN1ELSE0END)as has_pv,MAX(CASEWHEN behavior_type ='fav'THEN1ELSE0END)as has_fav,MAX(CASEWHEN behavior_type ='cart'THEN1ELSE0END)as has_cart,MAX(CASEWHEN behavior_type ='buy'THEN1ELSE0END)as has_buy
FROM user_behavior
WHERE dt ='2023-07-25'GROUPBY user_id
)SELECTSUM(has_pv)as pv_users,SUM(has_fav)as fav_users,SUM(has_cart)as cart_users,SUM(has_buy)as buy_users,SUM(has_buy)/SUM(has_pv)as conversion_rate
FROM user_funnel;
Part 4 与大数据生态系统的集成

Hive并不是孤立存在的,它是大数据生态系统中的一员。学习如何将Hive与其他工具集成使用,可以让你的技能更加全面。
1. Hive on Spark
使用Spark作为Hive的执行引擎可以显著提高查询性能:
SET hive.execution.engine=spark;
2. Hive与HBase集成
Hive可以直接查询HBase中的数据:
CREATE EXTERNAL TABLE hbase_table_emp(
id INT,
name STRING,
role STRING
)
STORED BY'org.apache.hadoop.hive.hbase.HBaseStorageHandler'WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,f1:name,f1:role")
TBLPROPERTIES ("hbase.table.name"="emp");
3. Hive与Kafka集成
使用Kafka连接器,我们可以将Kafka中的数据实时导入Hive:
CREATE EXTERNAL TABLE kafka_table (
id INT,
name STRING,
age INT)
STORED BY'org.apache.hadoop.hive.kafka.KafkaStorageHandler'
TBLPROPERTIES ("kafka.topic"="test-topic","kafka.bootstrap.servers"="localhost:9092");
持续学习的建议
- 关注Hive的发展:定期查看Apache Hive的官方文档和release notes,了解新特性和改进。
- 参与社区:加入Hive用户邮件列表,参与讨论,这是学习和解决问题的好方法。
- 阅读源码:尝试阅读Hive的源代码,这可以帮助你更深入地理解Hive的工作原理。
- 实践,实践,再实践:尝试在工作中解决实际问题,或者参与一些开源项目。
- 分享知识:尝试写博客或者在团队中分享你的Hive使用经验,教是最好的学习方式。
结语
学习Hive是一个不断深入的过程。从"糙快猛"的入门,到逐步掌握高级特性,再到能够优化复杂查询和设计大规模数据仓库,每一步都充满挑战和乐趣。
记住,在大数据的世界里,技术更新很快,保持学习的激情和好奇心至关重要。当你解决了一个复杂的数据分析问题,优化了一个效率低下的查询,或者设计了一个高效的数据仓库时,别忘了骄傲地说:“可把我牛逼坏了,让我叉会腰儿!”
Part 5 Hive内部原理深究
要真正掌握Hive,了解其内部工作原理是必不可少的。这不仅能帮助你更好地优化查询,还能在遇到问题时快速定位原因。
1. Hive查询的生命周期
了解Hive查询的执行过程可以帮助我们更好地理解和优化查询:
- 解析:Hive将HQL转换为抽象语法树(AST)
- 编译:将AST转换为运算符树
- 优化:进行逻辑和物理优化
- 执行:生成执行计划并提交到Hadoop集群执行
2. Hive的元数据管理
Hive的元数据存储在关系型数据库中(默认是Derby,生产环境常用MySQL)。了解元数据的结构可以帮助我们更好地管理Hive:
-- 查看表的元数据DESC FORMATTED my_table;-- 查看分区信息SHOW PARTITIONS my_table;
3. Hive的序列化和反序列化
Hive使用SerDe(Serializer/Deserializer)来读写数据。了解不同SerDe的特点可以帮助我们选择最适合的数据存储格式:
-- 使用自定义SerDeCREATETABLE my_csv_table (
id INT,
name STRING
)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'WITH SERDEPROPERTIES ("separatorChar"=",","quoteChar"="'","escapeChar"="\\");
高级优化技巧
除了之前提到的基本优化技巧,还有一些高级技巧可以进一步提升Hive的性能:
1. 动态分区优化
动态分区可以自动创建分区,但如果使用不当可能会创建大量小文件。可以通过以下设置来优化:
SET hive.exec.dynamic.partition=true;SET hive.exec.dynamic.partition.mode=nonstrict;SET hive.exec.max.dynamic.partitions=1000;SET hive.exec.max.dynamic.partitions.pernode=100;
2. 小文件合并
小文件会导致创建大量Map任务,影响性能。可以通过以下设置来合并小文件:
SET hive.merge.mapfiles=true;SET hive.merge.mapredfiles=true;SET hive.merge.size.per.task=256000000;
3. 压缩和编码
合理使用压缩和编码可以减少I/O,提高查询速度:
SET hive.exec.compress.intermediate=true;SET hive.exec.compress.output=true;SET mapred.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
故障排除和性能诊断
在使用Hive的过程中,难免会遇到各种问题。以下是一些常见问题及其解决方案:
1. 数据倾斜
症状:某些Reducer任务运行时间明显长于其他任务。
解决方案:
- 对倾斜的键进行预处理
- 使用倾斜Join优化
SET hive.optimize.skewjoin=true;SET hive.skewjoin.key=100000;
2. Out of Memory错误
症状:任务失败,日志中出现OutOfMemoryError。
解决方案:
- 增加mapper/reducer的内存
SET mapred.child.java.opts=-Xmx1024m; - 如果是数据倾斜导致,参考上述数据倾斜的解决方案
3. 查询速度慢
症状:查询执行时间过长。
诊断步骤:
- 使用EXPLAIN命令查看查询计划
- 检查表的分区和索引是否合理
- 查看是否有数据倾斜
- 检查Join的顺序是否优化
EXPLAINEXTENDEDSELECT/*+ MAPJOIN(b) */ a.val, b.val
FROM a JOIN b ON(a.key= b.key);
Part 6 Hive在企业级数据仓库中的应用
在实际的企业环境中,Hive常常作为大规模数据仓库的核心组件。让我们探讨一下Hive在企业级应用中的一些最佳实践和常见架构。
1. 分层数据仓库架构
在企业级数据仓库中,通常采用分层架构来组织数据:
- ODS(操作数据存储)层:存储原始数据,通常是从源系统直接导入的数据。
- DWD(数据仓库明细)层:存储经过清洗和规范化的明细数据。
- DWS(数据仓库服务)层:存储轻度汇总的数据,用于提供常用的统计指标。
- ADS(应用数据服务)层:存储高度汇总的数据,直接服务于应用和报表。
示例:创建DWS层的销售汇总表
CREATETABLE dws_sales_daily (
date_key DATE,
product_id STRING,
category_id STRING,
sales_amount DECIMAL(18,2),
sales_quantity INT)
PARTITIONED BY(dt STRING)
STORED AS ORC;INSERT OVERWRITE TABLE dws_sales_daily PARTITION(dt='2023-07-26')SELECT
o.order_date AS date_key,
p.product_id,
p.category_id,SUM(o.price * o.quantity)AS sales_amount,SUM(o.quantity)AS sales_quantity
FROM
dwd_orders o
JOIN
dim_product p ON o.product_id = p.product_id
WHERE
o.dt ='2023-07-26'GROUPBY
o.order_date, p.product_id, p.category_id;
2. 实时数据集成
随着实时数据需求的增加,许多企业开始探索如何将实时数据集成到Hive中。以下是一些常见的方法:
- Hive事务表:Hive支持ACID事务,允许进行实时的插入、更新和删除操作。
CREATETABLE realtime_sales (
id INT,
product_id STRING,
sale_amount DECIMAL(18,2),
sale_time TIMESTAMP)CLUSTEREDBY(id)INTO4 BUCKETS
STORED AS ORC
TBLPROPERTIES ('transactional'='true');-- 插入新的销售记录INSERTINTO realtime_sales VALUES(1,'P001',99.99,CURRENT_TIMESTAMP);-- 更新销售金额UPDATE realtime_sales SET sale_amount =89.99WHERE id =1;
- Hive Streaming:通过Hive Streaming API,可以将实时数据流写入Hive表。
HiveEndPoint endPoint =newHiveEndPoint("jdbc:hive2://localhost:10000/default","realtime_sales",Arrays.asList(""),null);StreamingConnection connection = endPoint.newConnection(true);RecordWriter writer = connection.newWriter();
writer.write(newBytesWritable("P001".getBytes()),newBytesWritable("99.99".getBytes()));
writer.flush();
writer.close();
3. 数据质量管理
在企业环境中,确保数据质量至关重要。以下是一些使用Hive进行数据质量管理的方法:
- 数据验证查询:定期运行验证查询来检查数据的完整性和一致性。
-- 检查空值SELECTCOUNT(*)AS null_count
FROM my_table
WHERE important_column ISNULL;-- 检查重复值SELECT id,COUNT(*)AS dup_count
FROM my_table
GROUPBY id
HAVINGCOUNT(*)>1;
- 使用Hive UDF进行数据清洗:创建自定义UDF来进行复杂的数据清洗和验证。
publicclassDataCleansingUDFextendsUDF{publicStringevaluate(String input){// 实现数据清洗逻辑return cleanedData;}}
ADD JAR /path/to/data-cleansing-udf.jar;CREATETEMPORARYFUNCTION clean_data AS'com.example.DataCleansingUDF';INSERT OVERWRITE TABLE cleaned_table
SELECT clean_data(column1), clean_data(column2)FROM raw_table;
Hive vs 其他大数据技术

随着大数据生态系统的不断发展,出现了许多新的技术。让我们比较一下Hive与其他一些流行的大数据技术:
1. Hive vs Presto
- Hive:适合大规模批处理查询,支持复杂的ETL作业。
- Presto:适合交互式查询,查询速度更快,但对大规模ETL支持较弱。
选择建议:如果需要进行复杂的数据转换和大规模批处理,选择Hive;如果需要快速的交互式查询,选择Presto。
2. Hive vs Spark SQL
- Hive:成熟稳定,与Hadoop生态系统深度集成。
- Spark SQL:查询速度更快,支持更多的数据处理范式(如流处理)。
选择建议:如果已有大量Hive查询和UDF,继续使用Hive;如果需要更快的查询速度和更灵活的数据处理能力,考虑使用Spark SQL。
3. Hive vs Impala
- Hive:支持更复杂的查询和转换,可以处理更大规模的数据。
- Impala:查询延迟更低,适合交互式查询场景。
选择建议:对于需要低延迟的BI工具集成,选择Impala;对于复杂的数据处理和大规模批处理,选择Hive。
Hive的未来:趋势和展望

尽管Hive已经是一个成熟的技术,但它仍在不断发展。以下是一些Hive的未来趋势:
- 与云原生技术的集成:随着云计算的普及,Hive正在加强与云原生技术的集成,如支持对象存储、弹性计算资源等。
- 实时数据处理能力的增强:虽然Hive主要用于批处理,但它正在增强实时数据处理能力,如改进的事务支持、与流处理系统的集成等。
- AI和机器学习的深度集成:预计未来Hive将提供更多内置的机器学习算法和功能,方便数据科学家直接在Hive中进行模型训练和预测。
- 性能优化:持续的查询优化、更智能的资源管理、更高效的存储格式等。
- 安全性和治理的增强:随着数据隐私法规的加强,Hive可能会提供更强大的数据加密、访问控制和审计功能。
案例研究:全球零售巨头的Hive应用
让我们通过一个虚构的案例来看看Hive如何在实际企业中发挥作用。
背景:全球零售巨头 RetailTech 每天处理数百万笔交易,需要一个强大的数据仓库来支持其业务决策和客户洞察。
挑战:
- 每天需要处理和分析超过1PB的新数据
- 需要支持从实时销售监控到长期趋势分析的各种查询
- 数据安全和隐私保护至关重要
解决方案:
- 数据架构:- 使用Hive作为核心数据仓库- ODS层存储原始交易数据- DWD层进行数据清洗和标准化- DWS层创建常用的汇总指标- ADS层为不同的应用场景提供专门的数据集市
- 实时数据集成:- 使用Kafka收集实时交易数据- 通过Hive Streaming将实时数据写入Hive事务表- 定期将实时数据合并到批处理表中
- 查询优化:- 使用ORC存储格式并启用Zlib压缩- 根据查询模式优化分区策略- 为常用查询创建物化视图
- 安全性:- 启用Kerberos认证- 使用Apache Ranger进行细粒度的访问控制- 对敏感数据列进行加密
- 高级分析:- 使用Hive UDF实现复杂的业务逻辑- 集成Spark ML进行客户行为预测- 使用Tableau连接Hive进行可视化分析
结果:
- 成功构建了一个每天可以处理1.5PB数据的数据仓库
- 支持超过1000名分析师同时进行查询,95%的查询在30秒内完成
- 实现了从实时销售监控到复杂的客户行为分析的全方位数据应用
- 显著提高了库存管理效率,减少了30%的库存成本
- 通过个性化推荐提高了15%的客户转化率
结语
从"糙快猛"的入门学习,到深入理解Hive的内部原理,再到在企业级环境中应用Hive构建大规模数据仓库,Hive的学习之路是漫长而充满挑战的。但正是这些挑战让我们不断成长,让我们能够在大数据的海洋中游刃有余。
作为一个Hive专家,你不仅需要掌握技术细节,还需要理解业务需求,平衡性能、成本和安全性,并且能够与其他大数据技术协同工作。当你成功地设计了一个高效的企业级数据仓库,解决了一个棘手的性能问题,或者用Hive驱动的数据洞察帮助公司做出了重要决策时,你就可以自豪地说:“可把我牛逼坏了,让我叉会腰儿!”

记住,在这个数据驱动的时代,你掌握的不仅仅是一个技术工具,而是改变世界的力量。每一行查询背后,都可能隐藏着改变公司命运、影响数百万人生活的洞察。保持好奇,不断学习,相信数据的力量,你就能在这个精彩的大数据世界中创造奇迹!
思维导图
版权归原作者 数据小羊 所有, 如有侵权,请联系我们删除。