
✅作者简介:大家好我是@每天都要敲代码,一位材料转码农的选手,希望一起努力,一起进步!
📃个人主页:@每天都要敲代码的个人主页
🔥系列专栏:MySQL专栏
💬推荐一款模拟面试、刷题神器,从基础到大厂面试题 👉点击跳转刷题网站进行注册学习
一:分组函数
(1)分组函数又叫做多行处理函数;
多行处理函数的特点:输入多行,最终输出的结果是1行(2)所有的分组函数都是对“某一组”数据进行操作的!
(3)5个分组函数自动忽略空NULL,不需要在手动添加 is not null 条件

1. count 计数
(1)取得所有的员工数
select count(*) from emp; --和某个字段无关,统计的是总记录数

(2)取得津贴不为null员工数
注:采用count(字段名称),不会取得为null的记录
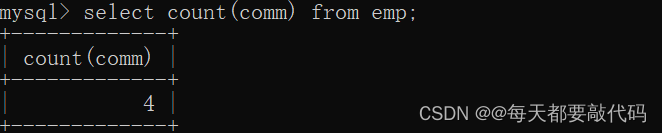
select count(comm) from emp; --统计的是comm不为NULL的个数
(3)count(*)和count(某个具体的字段),有什么区别
count(*):不是统计某个字段中数据的个数,而是统计总记录条数。(和某个字段无关)
count(comm):表示统计comm字段中不为NULL的数据总数量。
2. sum 求和
sum可以取得某一个列的和,null会被忽略
(1)取得薪水的合计
select sum(sal) from emp;

(2)取得津贴的合计
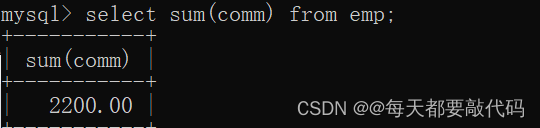
select sum(comm) from emp;
 ()
()
(3) 取得薪水的合计(sal+comm);ifnull()空处理函数的使用
select sum(sal+comm) from emp;

从结果上看,明显不对; 原因在于comm字段有null值,最终结合在一块的一行的结果就是null,sum会忽略掉,正确的做法是将comm字段转换成0
重点:所有数据库都是这样规定的,只要有NULL参与的运算结果一定是NULL
这就需要ifnull() 空处理函数:ifnull(可能为NULL的数据,被当做什么处理) : 属于单行处理函数;例如:IFNULL(comm,0)
select sum(sal+IFNULL(comm,0)) from emp;

(4)计算每个员工的年薪
select ename,(sal+comm)*12 as yearsal from emp; --错误写法
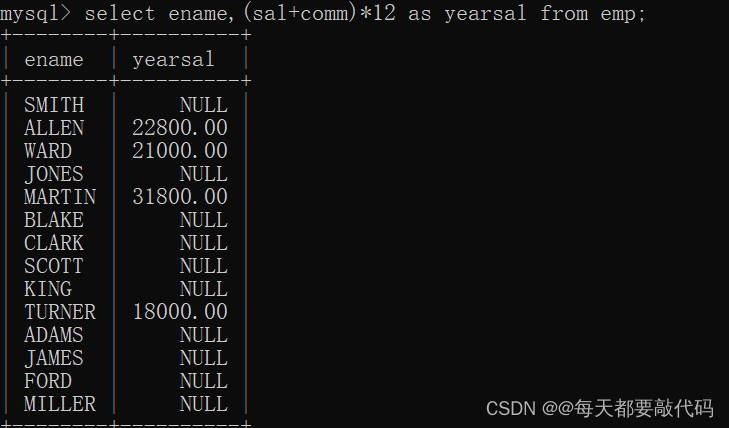
我们发现有些人的年薪居然是NULL,明显是不符合逻辑的;主要原因在于有些人的津贴comm为NULL;数据+NULL,在数据库中最终会看成NULL处理!
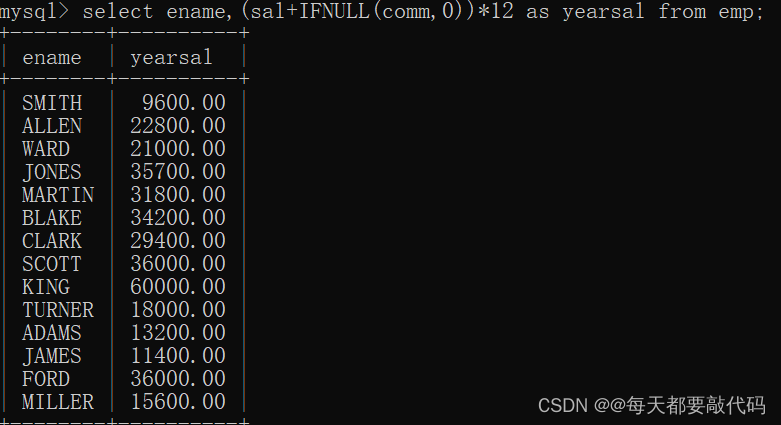
select ename,(sal+IFNULL(comm,0))*12 as yearsal from emp; -- 正确写法
3. avg 平均值
取得某一列的平均值,null会被忽略
(1)取得平均薪水
select avg(sal) from emp;

(2)找出工资高于平均工资的员工
select ename,sal from emp where sal > avg(sal); -- 错误写法
-- ERROR 1111 (HY000): Invalid use of group function,无效的使用了分组函数
-- group by是在where之后执行的,而分组函数avg又是在group by分组之后才能使用
-- 所以where后面不能直接跟分组函数
原因:SQL语句当中有一个语法规则,分组函数不可直接使用在where子句当中
解释:因为group by是在where执行之后才执行;分组函数avg必须在分完组才能用,而where的时候group by还没有执行,还没有分组,不能用分组函数!
select 5 .. from 1 .. where 2 --第一次的过滤 .. --这里不能直接使用分组函数 group by 3 --分组,先分组才能使用分组函数 .. having 4 --第二次的过滤 .. order by 6 ..再例如:select ename,sal from emp where avg(sal) ; 错误的用法,虽然默认会有一个group by,但是它的执行需要在where执行完成之后,才会默认执行!此时在where avg(sal)后面直接使用分组函数,并没有先分组,是错误的用法!
第一步:找出平均工资
select avg(sal) from emp;

第二步:找出工资高于平均工资的员工
select ename,sal from emp where sal > 2073.214286;
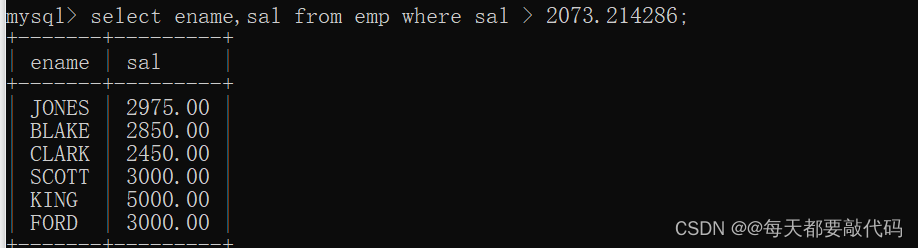
第三步:两个SQL语句联合使用
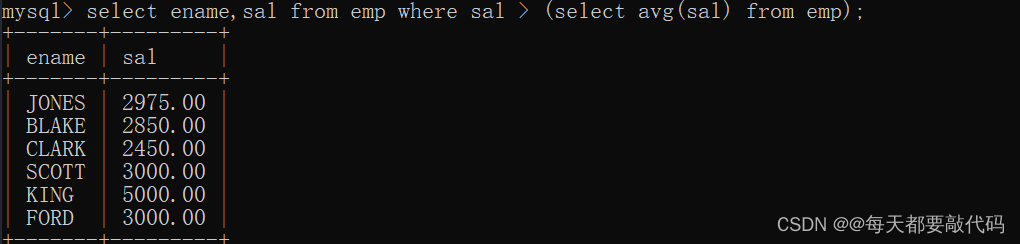
select ename,sal from emp where sal > (select avg(sal) from emp); --正确写法
4. max 最大值
取得某个一列的最大值,null会被忽略
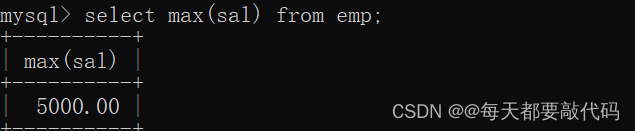
(1)取得最高薪水
select max(sal) from emp;
(2)取得最晚入职得员工,hiredate表示入职时间
select max(str_to_date(hiredate,'%Y-%m-%d')) from emp;
select max(hiredate) from emp; --原表就是标准格式,str_to_date不用也行

5. min 最小值
取得某个一列的最小值,null会被忽略
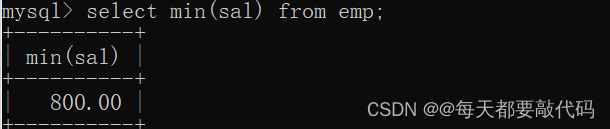
(1)取得最低薪水
select min(sal) from emp;
(2)取得最早入职得员工
select min(str_to_date(hiredate, '%Y-%m-%d')) from emp;

(3)组合查询:可以将上述这些分组函数都放到select中一起使用
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp;

补充:distinct 关键字
(1)查看所有的工作
select job from emp;
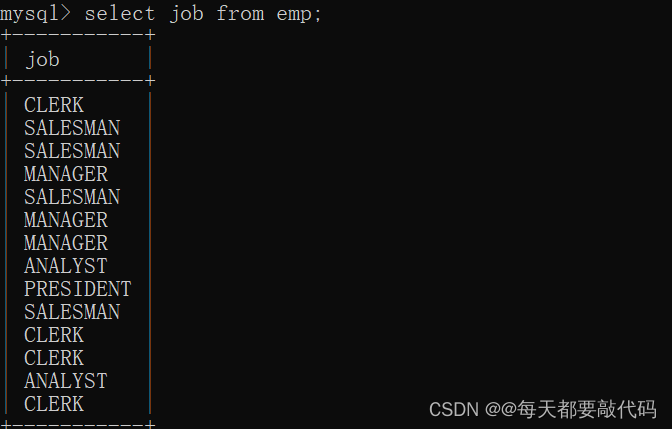
查出来有14种结果,有很多重复的,利用distinct关键字就可以进行剔重!
select distinct job from emp;

(2)distinct只能出现在所有字段的最前面,表示后面的字段联合去重
select ename,distinct job from emp; --错误语法
-- ename查询的结果是14条,distinct job 查询的结果是5条,根本无法匹配
-- 所以,distinct只能出现在所有字段的最前面
不使用distinct:
select deptno,job from emp order by deptno;
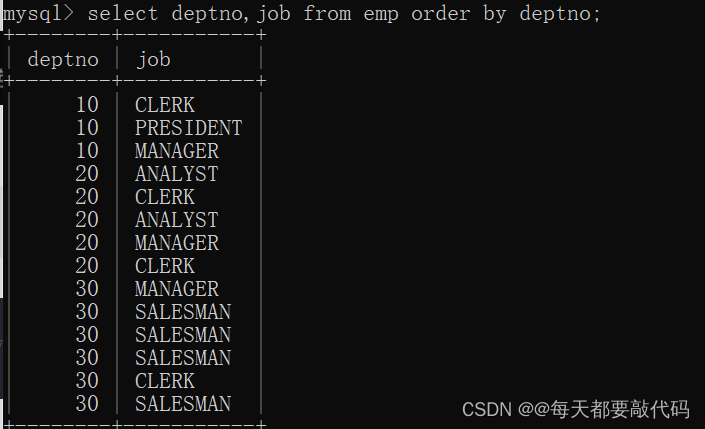
使用distinct对deptno和job联合剔重:
select distinct deptno,job from emp order by deptno;
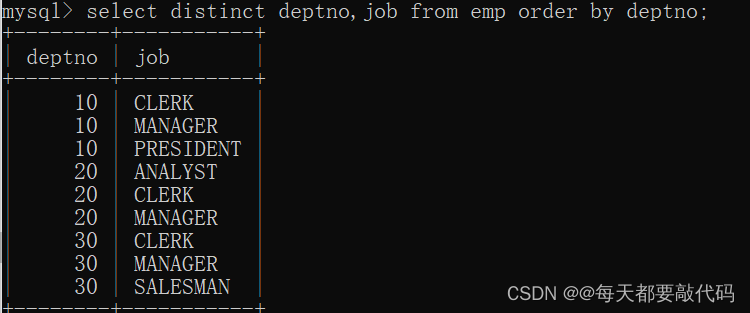
(3)取得工作岗位的个数
select count(distinct job) from emp;
不进行剔重:
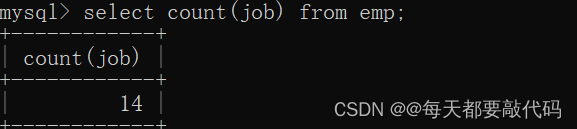
进行剔重:

二 :分组查询
分组查询主要涉及到两个子句,分别是:group by和having
group by : 按照某个字段或者某些字段进行分组(名字相同的为一组)
having :having是对分组之后的数据进行再次过滤
1. group by
注意:分组函数一般都会和group by联合使用,这也是为什么它被称为分组函数的原因!
并且任何一个分组函数(count sum avg max min)都是在group by语句执行结束之后才会执行的;当一条sql语句没有group by的话,整张表的数据会自成一组。
(1)找出每个工作岗位的最高薪资
先查看所有岗位的信息:
select * from emp;
找到所有岗位里的最高薪资:
select job,max(sal) from emp;

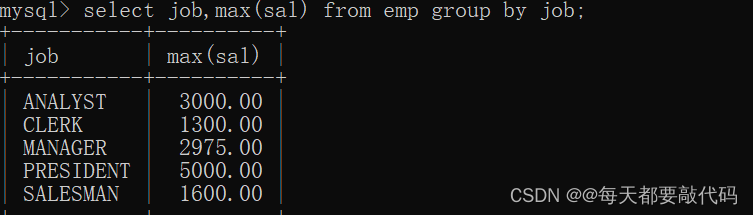
找出每个工作岗位的最高薪资,这就要先对每个岗位分组,然后找到每个组里的最大值:
select job,max(sal) from emp group by job;
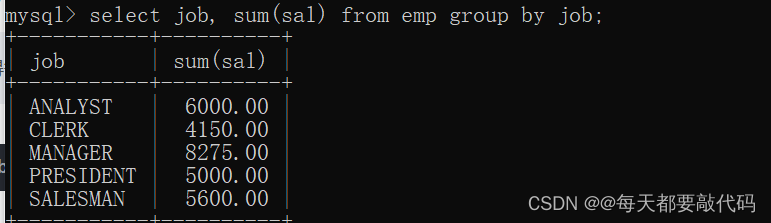
(2)取得每个工作岗位的工资合计,要求显示岗位名称和工资合计
select job, sum(sal) from emp group by job;
如果在使用order by进行排序;使用了order by,order by必须放到group by后面;例如:
select job, sum(sal) from emp group by job order by job;
以下是多个字段联合起来一块分组
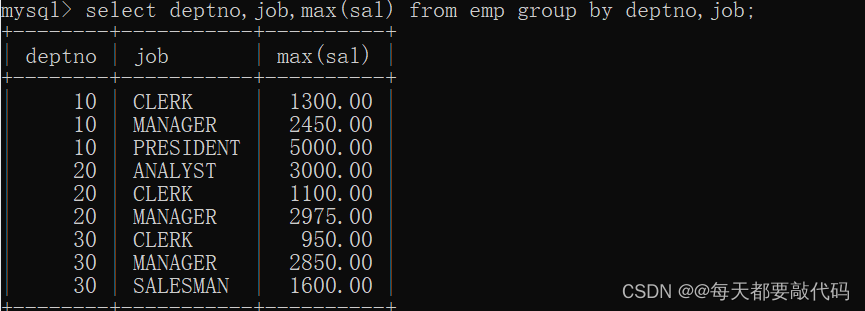
(3)找出每个部门不同工作岗位的最高薪资。
select deptno,job,max(sal) from emp group by deptno,job;
-- 先根据部分进行分组,部门相同在根据工作岗位分组
(4)按照工作岗位和部门编码分组,取得的工资合计
select job,deptno,sum(sal) from emp group by job,deptno;
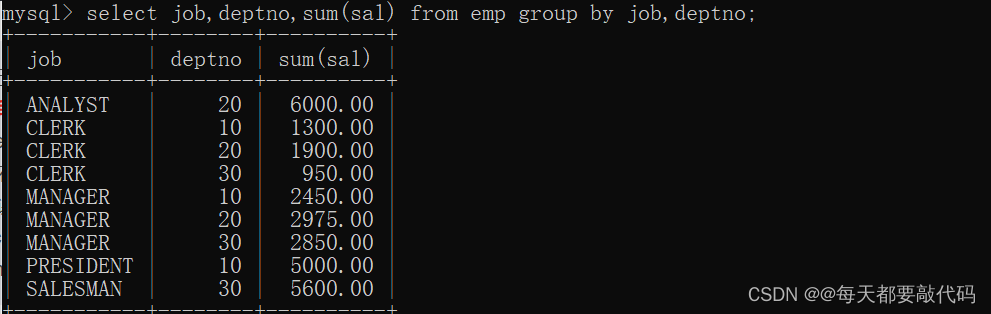
(5)记住一个规则:当一条语句中有group by的话,select后面只能跟分组函数和参与分组的字段。
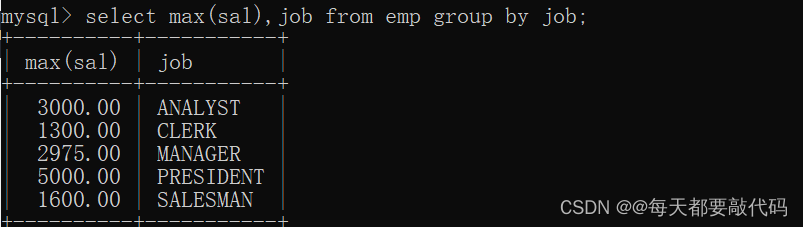
例如:查看每个工作岗位中工资最高的
select max(sal),job from emp group by job;
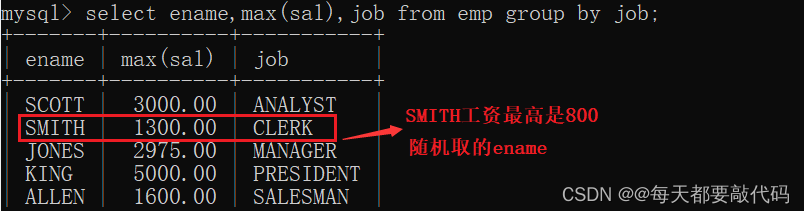
我们在加上名字ename字段:select ename,max(sal),job from emp group by job;以上在mysql当中,查询结果是有的,但是结果没有意义,在Oracle数据库当中会报错,语法错误。Oracle的语法规则比MySQL语法规则严谨。
2. having
如果想对分组数据再进行过滤需要使用having子句;也可以使用where,使用where效率较高,因为where会提前缩小范围!使用where解决不了的,在使用having!
(1)找出每个部门的最高薪资,要求显示薪资大于2900的数据。【having 和 where 都可】
第一种方法:使用having过滤;先分组,在把小于2900的过滤掉;效率较低
select deptno,max(sal) from emp group by deptno having max(sal)>2900;
-- 先进行分组,分组以后在每一组例筛选max(sal) > 2900的

第二种方法:使用where过滤;先使用where过滤掉小于2900的数据,在分组;效率较高
max数据是原数据,不要计算,这里where后面使用sal也可以
select deptno,max(sal) from emp where sal > 2900 group by deptno;
-- 直接先使用where过滤掉sal < 2900的,数据减少很多;在进行分组,效率较高

(2)找出每个部门的平均薪资,要求显示薪资大于2000的数据【只能使用having】
第一种方法:使用having过滤,可以
select deptno, avg(sal) from emp group by deptno having avg(sal) >2000;

第二种方法:使用where过滤,不可以;avg数据是通过计算获得的数据,where后面只能写成avg(sal),而where后面又不能直接跟分组函数
select deptno,avg(sal) from emp where avg(sal) > 2000 group by deptno;
-- where后面不能使用分组函数,只能使用having
三:DQL语句总结
一个完整的select语句格式如下:
select 字段 5
from 表名 1
where ……. 2
group by …….. 3
having ……. 4 (就是为了过滤分组后的数据而存在的,不可以单独的出现)
order by …….. 6
以上语句的执行顺序
- 首先执行where语句过滤原始数据
- 执行group by进行分组
- 执行having对分组数据进行操作
- 执行select选出数据
- 最后执行order by排序
原则:能在where中过滤的数据,尽量在where中过滤,效率较高。having的过滤是专门对分组之后的数据进行过滤的!
结束语
今天的分享就到这里啦!快快通过下方链接注册加入刷题大军吧!各种大厂面试真题在等你哦!
💬刷题神器,从基础到大厂面试题👉点击跳转刷题网站进行注册学习
版权归原作者 @每天都要敲代码 所有, 如有侵权,请联系我们删除。