
文章目录
前言
MySQL 最重要的部分就是在增删查改这四个操作上,我们在实际的开发中也会频繁运用到这些操作,尤其是查找,这部分有很多门道在里面,需要好好理解,多敲几遍代码熟悉熟悉
(由于博主本人在写博客的时候觉得 sql 关键字大写太累眼,故后续的 sql 语句将全部使用小写,因为它不区分大小写)
1. 新增
**插入关键词:
insert
**
1.1 全插入
insert[into] 表名 values(值,值 ......);
- 这里演示的是全插入,及插入的值要和表对应列的数量,数据类型以及顺序相匹配
into在此可以省略,但博主并不建议
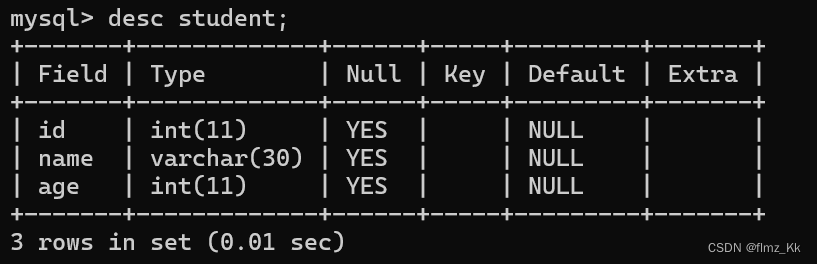
在插入前我们要先选定数据库,然后可以用
desc 表名
先查看表的结构
接下来我们就可以向
student
插入一条数据,并查询表里的内容
-- 演示insertinto student values(1,'张三',19);
使用
select * from 表名就可以查询表的实际内容,在下面的查询知识点中我们会介绍,这里提前使用一下
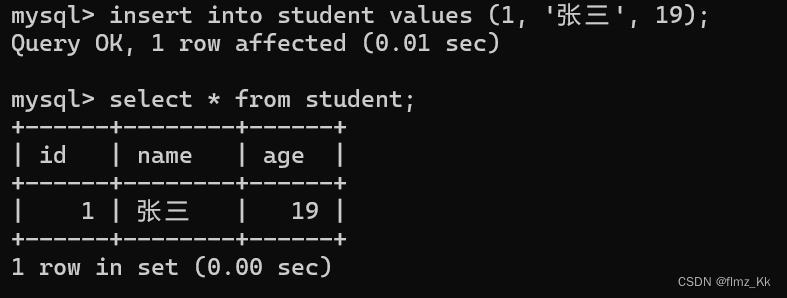
这样就成功插入了一条数据 ~
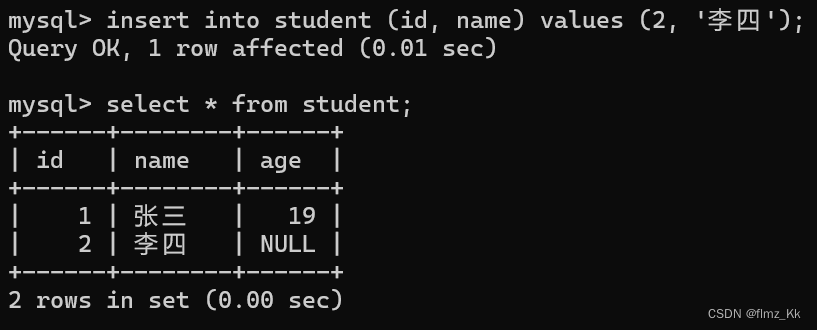
那如果我们在插入数据时,缺乏一些信息,比如我们知道
id
为 2 的人叫 “李四”,但是并不知道他的年龄,这时候该怎么办?
而且一行一行的插入效率很低,有什么办法可以提高插入效率吗?
1.2 指定某些列名插入
insertinto 表名 (列名,列名 ......)values(值,值 ......);
- 插入时也是要和指定列的数据类型以及顺序相匹配,没有指定到的列如果有默认值,那就是默认值;如果允许为
null,那就是null;如果前面的都不满足,则会报错
-- 演示insertinto student (id, name)values(2,'李四');
1.3 多行插入
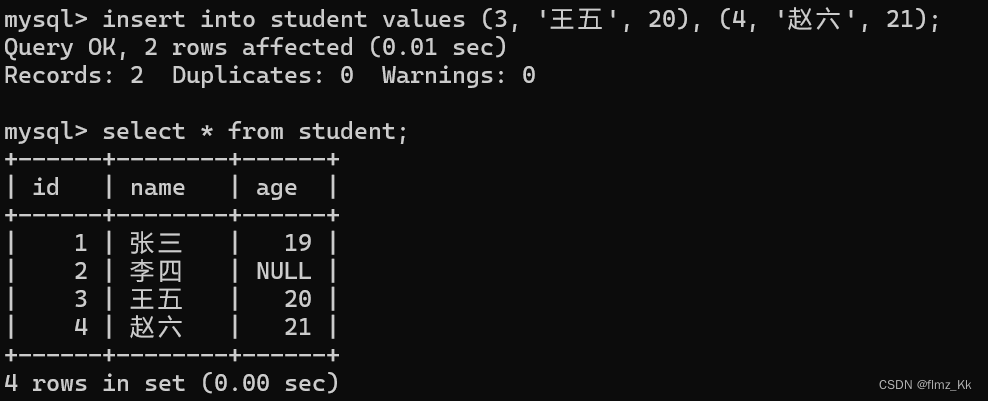
insertinto 表名 values(值,值 ......),(值,值 ......),......;
- 非常简单,在后面多加几个括号就行,其他规则和上面一致
-- 演示insertinto student values(3,'王五',20),(4,'赵六',21);
1.4 边查询边插入
insertinto 表1select*from 表2;
- 要求两张表的列数、类型、顺序必须要相匹配
- 比较少用,了解即可
2. 约束
对于数据库存储的数据,我们往往会做出一些“限制”“要求”,防止错误的数据被插入到数据表中。MySQL 中定义了一些维护数据库完整性的规则,一般叫做“约束”,常见的约束类型如下
约束类型说明非空约束:not null指定某列不能存储 null 值唯一性约束:unique指定某列的每一行必须由唯一值默认值约束:default没有给某列赋值时就为默认值主键约束:primary key用于唯一的标识表中的每一行,相当于 not null 和 unique 的结合外键约束:foreign key用于在两个表之间建立链接,确保数据的引用完整性check约束:check用于限制某列中的值必须满足特定的条件
这些约束都是用在创建表的时候跟在某几列的后面,用来约束插入数据时的数据合法性,因此在建表前要先设计好列的约束
2.1 非空约束
创建表时,指定某列不能存储 null 值,而且修改时也不能为空
-- 演示-- 创建一张包含 id、name 的学生表,要求 id 非空createtable student (
id intnotnull,
name varchar(20));
2.2 唯一性约束
创建表时,指定某列的每一行必须由唯一值。在插入或者修改前会查询该列在表中的每一行,若重复就会报错
-- 演示-- 创建一张包含 id、name 的学生表,要求 id 非空,name 非空且不能重名createtable student (
id intnotnull,
name varchar(20)uniquenotnull);
2.3 默认值约束
在插入数据时,如果不指定该列的值,那就会自动变成默认值
-- 演示-- 创建一张包含 id、name、age 的学生表,要求 id 非空,name 非空且不能重名,age 默认值为 19createtable student (
id intnotnull,
name varchar(20)uniquenotnull,
age intdefault19);
我们在使用
desc 表名
的时候,看到的
default
指的就是默认值
2.4 主键约束
primary key
表示主键,用于唯一的标识表中的每一行,它会自动成为非空的,并且每个值都是唯一的。例如一个学生表中,学生的学号
id
就可以设置为主键,因为一个班级里的学生学号不可能重复
-- 演示-- 创建一张包含 id、name、age 的学生表,要求 id 为主键,name 不能重名,age 默认值为 19-- 方法一:跟在某一个字段后面createtable student1 (
id intprimarykey,
name varchar(20)unique,
age intdefault19);-- 方法二:在最后设置主键(常用于多个主键的设置)createtable student2 (
id int,
name varchar(20)unique,
age intdefault19,primarykey(id));
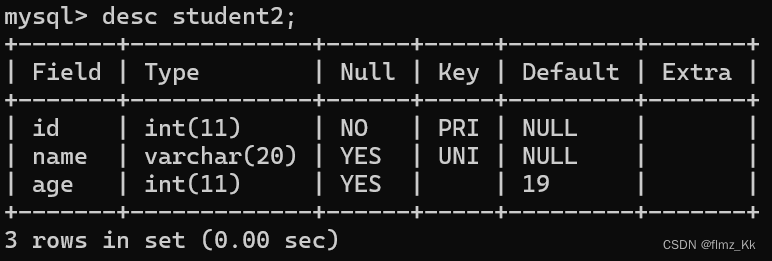
再来使用
desc 表名
来查看表的结构,能发现跟之前的“素表”有很多不同点
特点:
- 主键是一个表的身份标识,一般不允许一个表中同时有多个主键。不过在特殊情况下也会有把多个列共同作为一个主键,也叫做联合主键
- 主键在插入或者修改的时候也会触发查询,若存在重复或为
null,就会报错 - 主键是
not null和unique的结合,不需要再用not null了
对于整数类型的主键,我们常搭配自增长
auto_increment
来使用。在插入数据对应字段不给值时,数据库会自动分配,使用原先的数据最大值 + 1
-- 演示-- 创建一张包含 id、name 的学生表,要求 id 为主键搭配 auto_increment,name 不能重名createtable student (
id intprimarykeyauto_increment,
name varchar(20)unique);-- 向表中插入数据,id 不指定值,name 为 '张三'insertinto student(name)values('张三');-- 向表中再两组插入数据,id 为 100,name 为 '李四';-- 第二组 id 不指定,name 为 '王五' insertinto student values(100,'李四');insertinto student(name)values('王五');
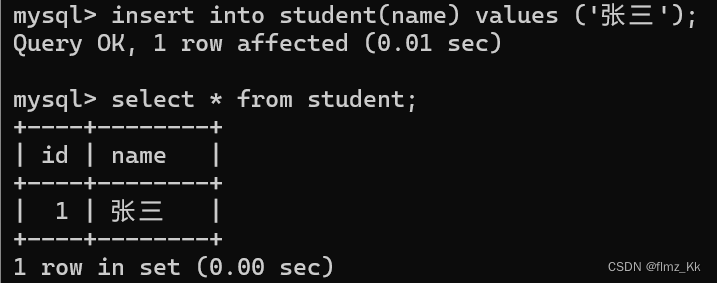
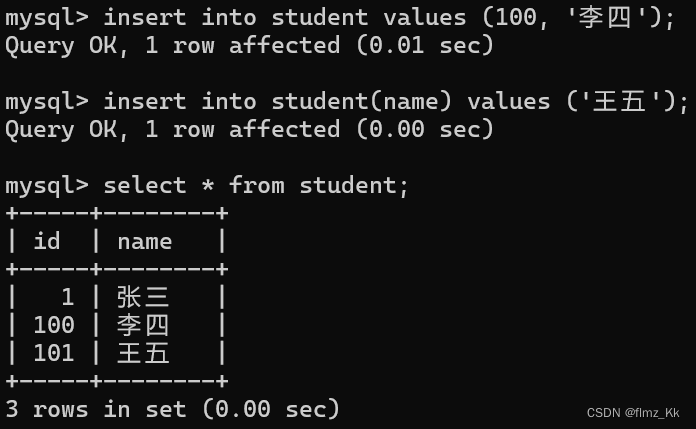
这就是自增长
auto_increment
的用法
2.5 外键约束
外键约束用于在两个表之间建立链接,关联其他表的主键或者唯一键,确保数据的引用完整性。此时有两张表,一张班级表,包含班级号等信息;另一张学生表,上面也有班级号,表示该学生来自哪个班级。此时学生表上的班级号就必须要跟班级表上存在的班级号对应上,这时就需要外键来约束学生表上的班级号,避免出现错误或不存在班级号
......,foreignkey(本表中的列)references 主表表名(被引用的列)
- 外键我们一般习惯放在最后写,可以同时设置多个外键
- 设置外键的表叫做“子表”,被引用的表叫做“父表”,父表子表的列都是要真是存在的,父表中的被引用的列的数据会制约子表中的数据
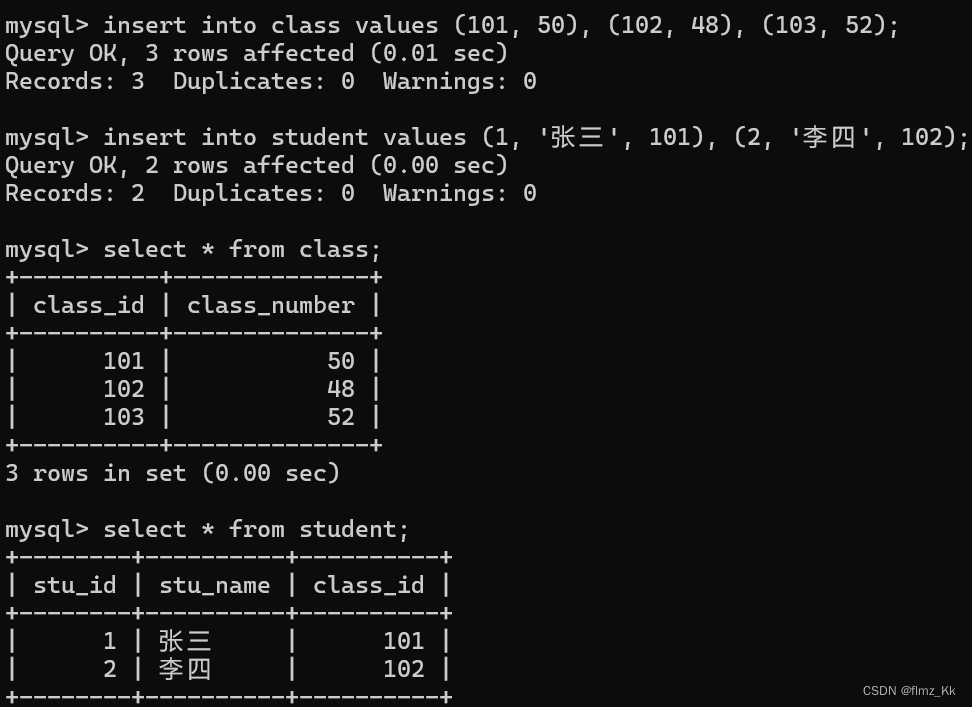
-- 演示-- 创建一张包含班级号、班级人数的班级表,要求班级号为主键,班级人数为非空createtable class (
class_id intprimarykey,
class_number intnotnull);-- 再创建一张包含学号、学生姓名、学生所属班级的学生表,要求学号为主键,学生姓名非空,班级号和 class 表建立外键createtable student (
stu_id intprimarykey,
stu_name varchar(20)notnull,
class_id int,foreignkey(class_id)references class(class_id));
-- 演示-- 再往 class 表中插入几组数据,接着往 student 表中插入数据,检验外键约束insertinto class values(101,50),(102,48),(103,52);-- 合法插入insertinto student values(1,'张三',101),(2,'李四',102);
-- 演示-- 非法插入,此时我们往学生表中故意插入错误的班级号insertinto student values(3,'王五',201);

因为
class
表中没有 201 号班级,所以数据库会报错,这就是外键的作用
在设置外键后,我们就无法直接删除父表,因为此时外键还在发挥作用,所以只能先删子表,再删父表(该操作十分危险,不推荐这样做)
2.6 check 约束
因为 MySQL 中并不能直接支持
check约束,所以这里仅作简单介绍
check约束确保数据库表中某个列的值必须满足特定的条件。这个条件是一个布尔表达式,只有当表达式的结果为
true
时,插入或更新的数据才会被允许
-- 演示-- 创建一张包含学号、学生姓名、年龄的学生表,要求学号为主键,学生年龄必须大于等于 18createtable student (
id intprimarykey,
name varchar(20),
age int,check(age >=18));
check约束中的表达式可以是任何有效的布尔表达式,包括比较操作符、逻辑操作符、算术运算等check约束有助于保证数据的准确性和一致性,但过多的使用可能会对数据库性能产生影响,因为数据库需要在每次插入或更新数据时检查这些约束
2.7 外键的逻辑删除
场景:一家卖文具的店铺,店家手头上有两张数据表,分别是商品表(goods_id,goods_name …),订单表(order_id, …, goods_id);订单表上有商品表上对应的商品编号,即两张表的 goods_id 建立了外键
店家之前在买一款铅笔,过阵子他发现该笔的销售额十分低,想要下架。此时,下架这个操作要怎么执行
错误的想法:直接把商品表上该款铅笔的商品编号给删掉不就好了
but,这样操作的话,之前卖出去的该款铅笔的订单要怎么处理,它可不能删除,而且两张表又使用外键通过商品编号联系到了一起,无法直接删除父表中的商品编号
正确的做法:在创建商品表之初,就再多设计一列商品状态
goods_state
,上架为 1,下架则为 0,这样既简单又轻松,不需要删除任何东西
这就是所谓的逻辑删除,所以所以,在创建表之前,我们就应该把多数情况考虑进去,这样可以大大减少后期改动,降低成本
3. 查询 - 初阶
**查询关键词:
select
**
对于所有查询,生成的都是虚表,及临时数据,不会影响到原始数据
3.1 全列查询
select*from 表名;
- 我们在上面展示的查询操作就是全列查询,它可以显示表里的所有行所有列
- 但是在数据量大的时候不建议使用,因为该操作很吃系统资源,而且查询速度也会很慢,严重的甚至会让整个数据库挂掉,还是有点危险的
3.2 指定列查询
select 列名,列名 ......from 表名;
还是上面的这个表,此时我们只想查询姓名和年龄这两列
-- 演示select name, age from student;
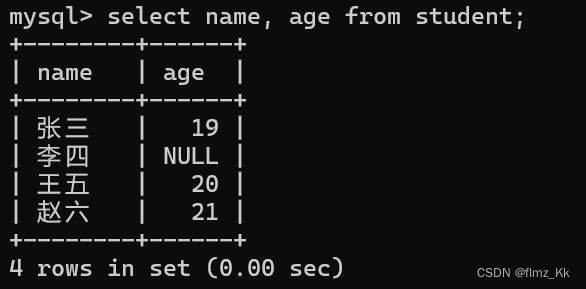
3.3 指定表达式查询
select 表达式 from 表名;
想象一个情景:我们想要知道学生是否成年,就可以在查询时让年龄都减 18 岁,通过正负零来加速判断。这时候就可以使用指定表达式查询(意思就是边查边计算,一些简单的加减乘除)
-- 演示select name, age -18from student;
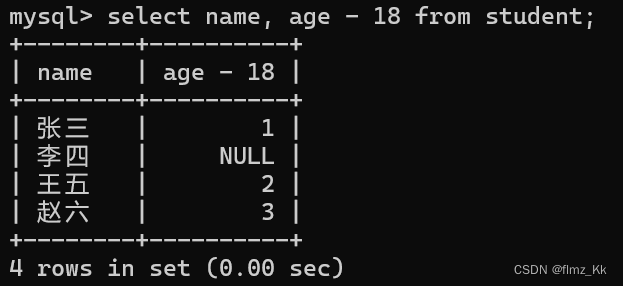
我们可以发现,除了李四我们在插入时没给他添加年龄之外,其他学生都是已成年
3.4 别名查询
select 列名 [as] 别名 from 表名;
在上面的指定表达式查询中,
age - 18
这个表达式变成了列名,在表中非常破坏美感。别着急,
sql
也考虑到了这一点,它允许我们使用
as
来给列起别名(当然,
as
其实也可以省略,但是本人非常不建议)
-- 演示select name, age -18as new_age from student;
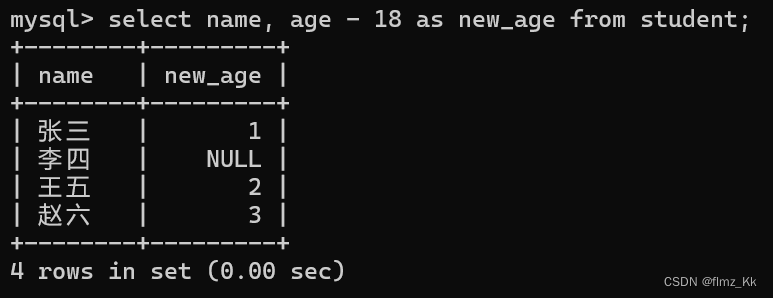
你看看,是不是美观多了~
3.5 去重查询
selectdistinct 列名 from 表名;
多个行的数据如果出现相同的值,就只会保留一份
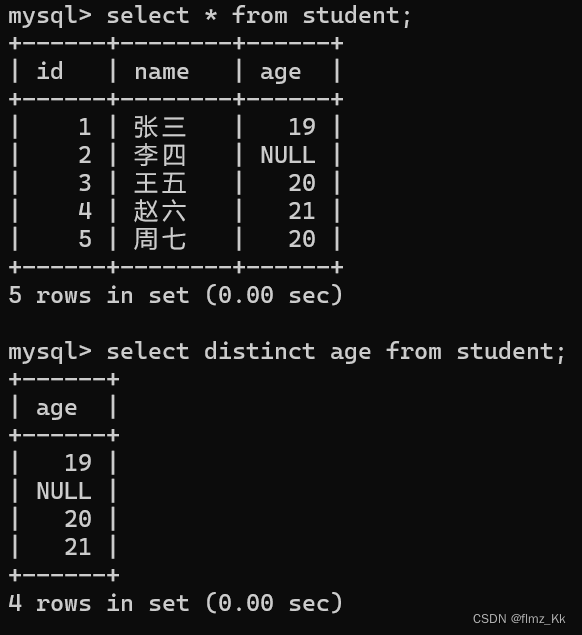
-- 演示-- 为了演示,我们再插入一组数据insertinto student values(5,'周七',20);-- 此时周七和王五的年龄相同-- 去重查询年龄selectdistinct age from student;
注意:在使用去重操作时,如果
distinct
修饰多列时,则需要多列里有完全相同的数据时才能去重
-- 演示selectdistinct name, age from student;
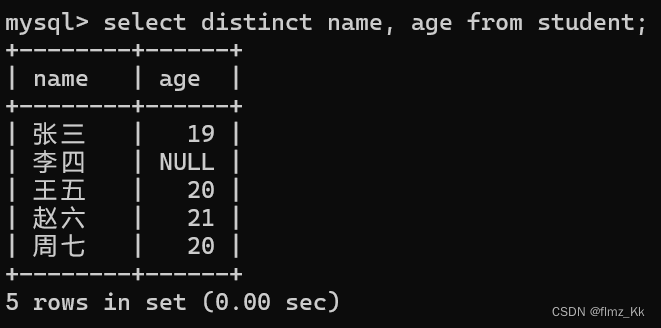
这里就是因为名字不一样而导致去重失败
3.6 排序查询
select 列名 from 表名 orderby 列名 [asc|desc];
- 这里
order by后面的列名意思是以该列为准则来排序 asc为升序(从小到大),desc为降序(从大到小)- 如果列名后不指定排序规则不写,那就默认是
asc - 对于中文字符,排序的大小关系取决于该数据库的配置和所使用的排序规则;我们更常使用具体数字大小来排序,而如果出现
null,它参与任何运算的结果依然是null,视为比任何值都小
-- 演示select name, age from student orderby age asc;
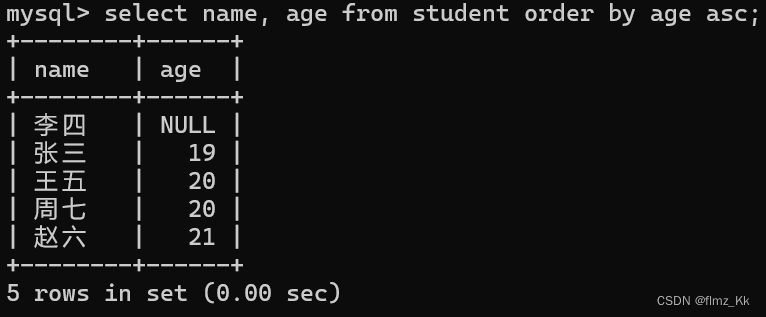
- 注意:没有
order by子句的查询,返回的顺序都是随机未定义的,不能信任这个顺序 - 如果排序时两个数据相等,那这两行数据的顺序就是不可预测的,如上图中的王五和周七
而且我们也可以对多个字段进行排序,排序的优先级根据书写的顺序
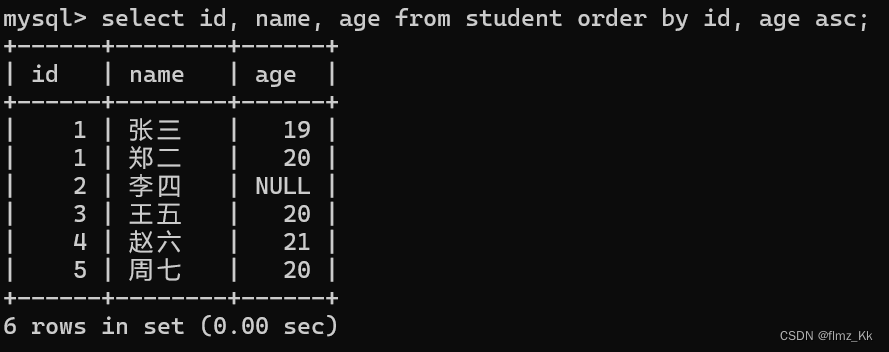
-- 演示-- 插入一组数据,id 为 1,年龄为 20insertinto student values(1,'郑二',20);-- 再来对 id 和 age 一起排序(id 在前,就先对 id 排序,如果 id 相同,则再根据 age 来排序)select id, name, age from student orderby id, age asc;
3.7 条件查询
**条件查询关键字:
where
**
select 列名 from 表名 where 条件;
原理:条件查询会遍历表里的每一行记录,把每一行的数据都带入条件中。若成立,则放入结果集合中,若不成立,就跳过,最后打印出结果集合 —— 成立的行所组成的临时表
从原理中我们也可以看出,当数据量非常大时,条件查询的效率会变得很低。但是别担心,MySQL 中还有一个名叫索引的机制,有了它加快查询的效率,后面我们也会讲到索引
where
后面的条件一般是由列名+运算符组成的子句(也可以是表达式或者列的别名)
在
sql
中,运算符我们之前学到的 C语言 以及 Java 类似,但有些许不同,大体可以分为两种
比较运算符
运算符说明>、<、>=、<=大于、小于、大于等于、小于等于**=等于,但是 null = null 的结果为 null**<=>等于,但是 null = null 的结果为 true!= 或者 <>不等于,且不能用于 null 的判断is null等于 null 就返回 trueis not null不等于 null 就返回 truein (a1、a2 …)筛选匹配,如果等于 in 里面的任一值,就返回 truebetween a1 and a2范围匹配,[a1,a2] 左闭右闭,如果在这个范围内,则返回 truelike模糊匹配,% 匹配零个或多个任意字符,_ 严格匹配一个任意字符
- 等于为
=,要跟 Java 的==区分开 - 判断是否等于
null时,可以使用<=>,也可以用is null;判断不等于null时, 只能使用is not null,不可以用!= 和 <=> like是一个比较低效的操作,使用要节制
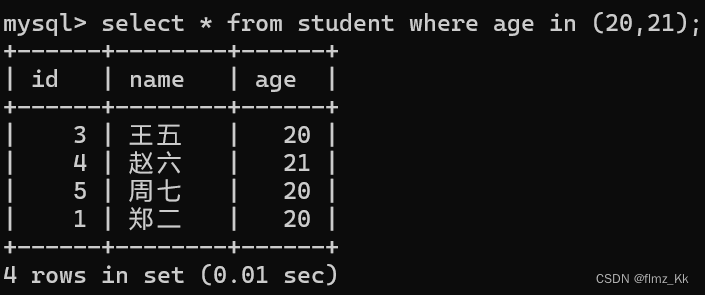
- 筛选匹配:in 的使用
select 列名 from 表名 where 列名 in(a1、a2 ......);-- 演示-- 查询学生表中年龄为 20 和 21 的学生select*from student where age in(20,21);
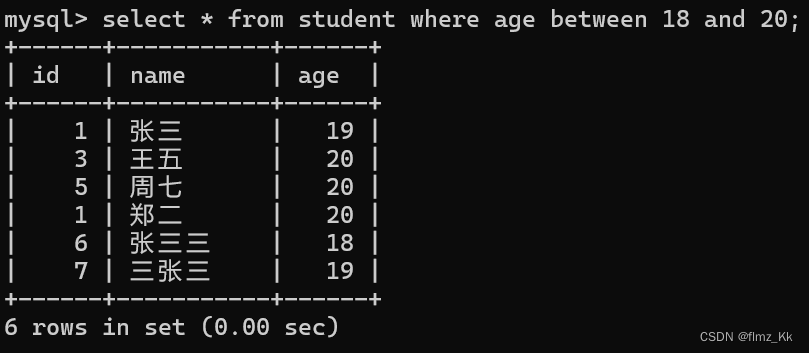
-- 2. 范围匹配:between 的使用select 列名 from 表名 where 列名 between a1 and a2;-- 先插入三组数据:id 为 6、7、8,姓名为 '张三三'、'三张三'、'',年龄为 18,19,22insertinto student values(6,'张三三',18),(7,'三张三',19),(8,'',22);-- 演示-- 查询学生表中年龄为 18 到 20 的学生select*from student where age between18and20;
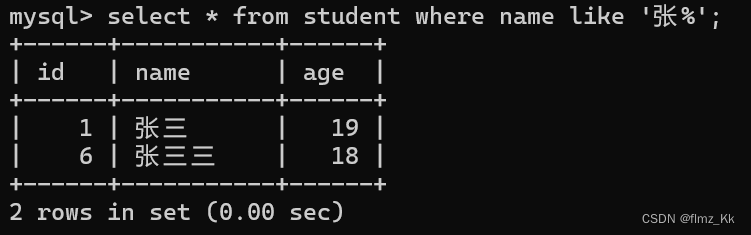
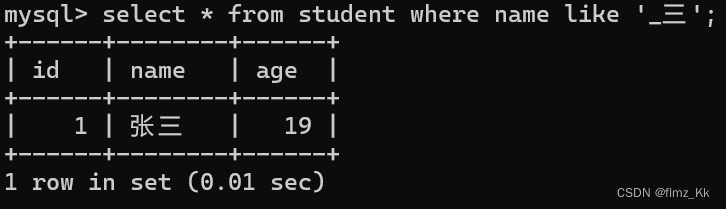
-- 3. 模糊匹配:like 的使用select 列名 from 表名 where 列名 like'[% | _]';-- 演示-- 查询学生表中姓名以'张'为开头的学生select*from student where name like'张%';-- 查询学生表中姓名以'三'为结尾的学生select*from student where name like'_三';
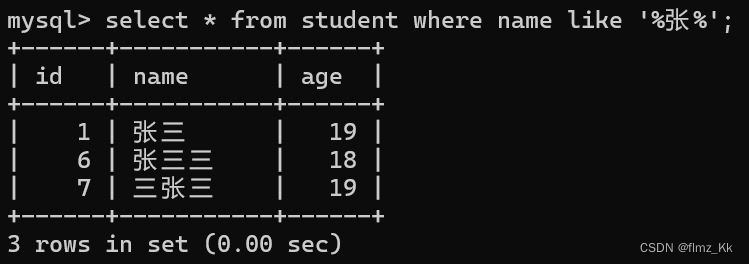
-- 演示-- 查询学生表中姓名出现'张'字的学生select*from student where name like'%张%';-- 查询学生表中姓名为零个字符的学生且 id 为 8 的学生(and 下面会讲到)select*from student where name like'%'and id =8;
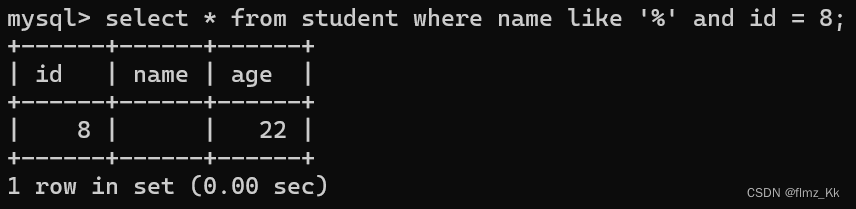
总结:
① 张% —— 查询以 ‘张’ 开头的
② %张 —— 查询以 ‘张’ 结尾的
③ %张% —— 查询包含 ‘张’ 的
逻辑运算符
运算符说明and与,多个条件都为 true,就返回 trueor或,任意一个条件为 true,就返回 truenot非,条件为 true,就返回 false
and的优先级高于or,但是在使用and和or的时候,用小括号来确定执行顺序更加靠谱(养成一个好习惯)
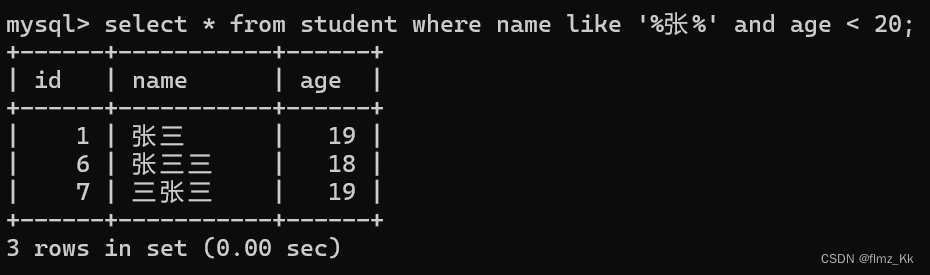
-- 演示-- 查询学生表中名字里有 '张' 字而且年龄小于 20 的学生select*from student where name like'%张%'and age <20;
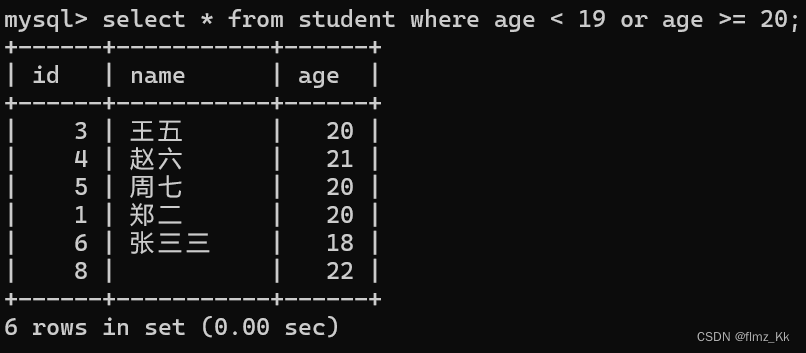
-- 演示-- 查询学生表中年龄小于 19 或者大于等于 20 的学生select*from student where age <19or age >=20;
3.8 分页查询
-- 从 0 开始,筛选 n 条结果select 列名 from 表名 limit n;-- 从 s 开始,筛选 n 条结果(表中起始下标为 0)select 列名 from 表名 limit s, n;-- 更建议使用下面这种方式,每次查询 n 条结果,每次偏移量为 sselect 列名 from 表名 limit n offset s;
- 分页查询可以限制一次查询最多能查出多少条结果
- 使用场景:当数据量非常多的时候,使用
select *一次性全部展示出来效率很低,而且用户查询也不方便> 此处展示的就是分页查询在实际场景中的用法> >
-- 演示-- 查询年龄前三小的学生信息,要排除为 null 的情况select*from student where age isnotnullorderby age asclimit3;-- 按 id 进行分页,每一页 3 条记录,分别显示第 1、2、3 页,若 id 相同,再按照 age 排序select*from student orderby id, age asclimit3offset0;# 从第 0 条查起select*from student orderby id, age asclimit3offset3;# 从第 3 条查起select*from student orderby id, age asclimit3offset6;# 从第 6 条查起
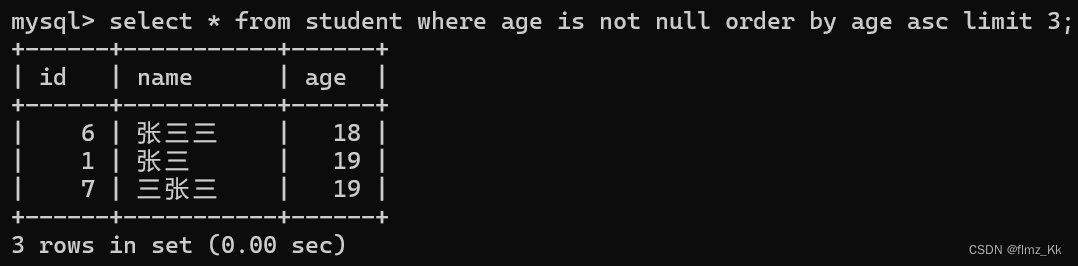
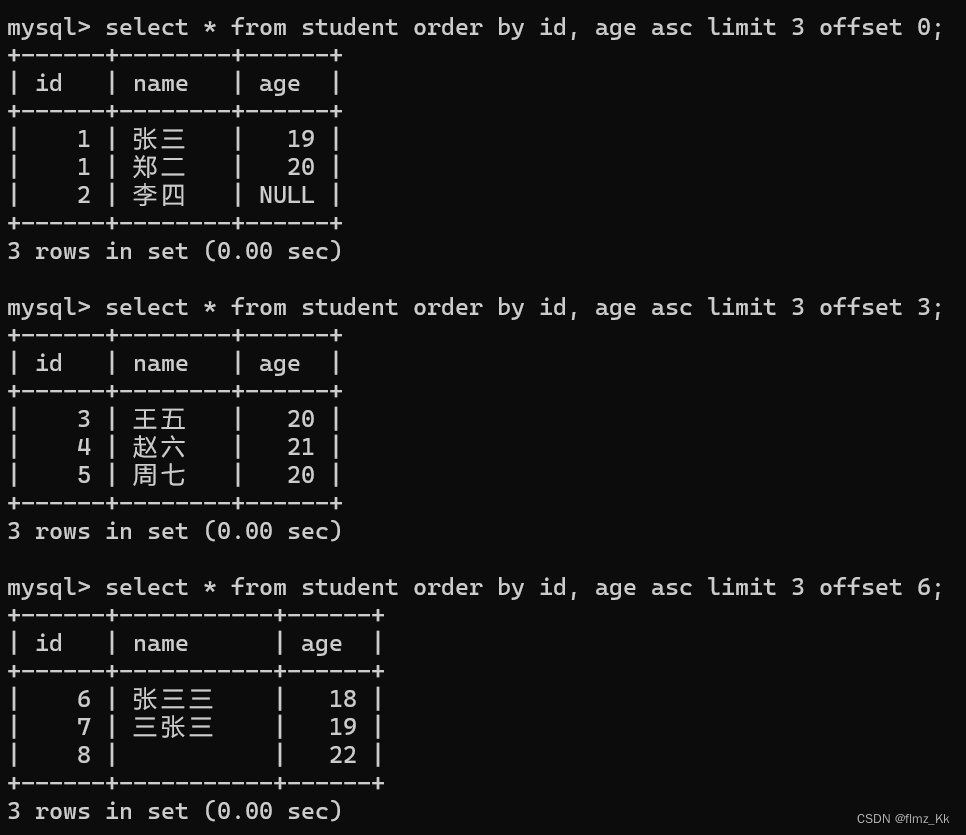
由上面的例子我们也可以看出,当条件、排序和分页一起查询的时候
**顺序应该是:
select 列名 from 表名 where 条件 order by 列名 [asc|desc] limit n offset s**
4. 查询 - 进阶
也不算什么进阶,单纯是上面的小标题太多了,分开写好看点😋
硬要说也是也区别的,下面这些查询针对的是行和行之间的操作,也不难,看完也就能懂了
4.1 聚合查询
在我们实际的开发中,常常需要统计某一列的最大值、最小值、平均值等等。聚合查询就可以满足这些要求,但在使用聚合查询的时候需要搭配聚合函数,所以我们先介绍聚合函数
聚合函数使用规则:只有在
select
子句、
having
子句和
order by
子句中才能使用聚合函数。在
where
子句中使用聚合韩式就是错误的
函数说明count( )计算一组值的数量(行数)sum( )计算一组数值的总和avg( )计算一组数值的平均值max( )返回一组数值的最大值min( )返回一组数值的最小值
- 所有的函数都可以使用
distinct来对查询的数据去重,例如count(distinct 列名) - 函数内部可以是列名,也可以是表达式
- 除了
count,其他函数遇到不是数字的行是没有意义的,它们只能计算具体的数字 - 对于查询结果的列名,都是可以起别名的
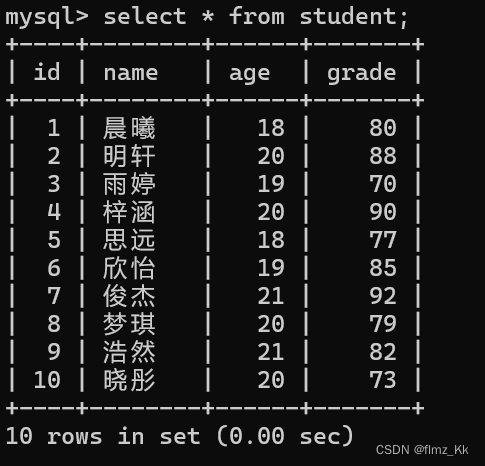
测试数据:
-- 学生表:id、name、age、gradecreatetable student (
id intprimarykeyauto_increment,
name varchar(20),
age int,
grade int);-- 插入数据,因为使用了自增长 auto_increment,所以 id 就不写了insertinto student(name, age, grade)values('晨曦',18,80),('明轩',20,88),('雨婷',19,70),('梓涵',20,90),('思远',18,77),('欣怡',19,85),('俊杰',21,92),('梦琪',20,79),('浩然',21,82),('晓彤',20,73);
- count:
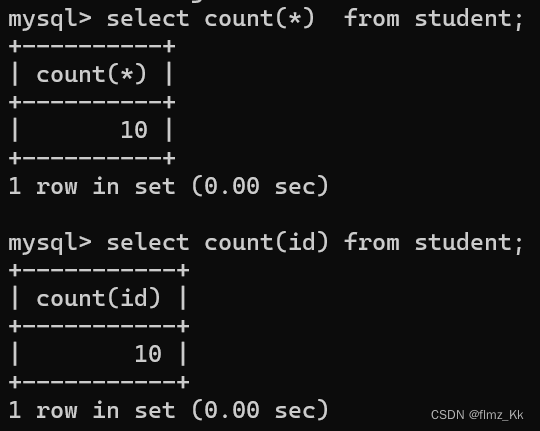
-- 查询这张表有多少个记录(多少行),如果某个记录存在空值,查询结果也会算上这一列selectcount(*)from 表名;-- 查询这一列的记录个数(多少行),如果这列存在空值,查询结果不会包含空值(重名也会计算)selectcount(列名)from 表名;
-- 演示-- 查询学生人数,两种方法一样selectcount(*)from student;selectcount(id)from student;
- sum:
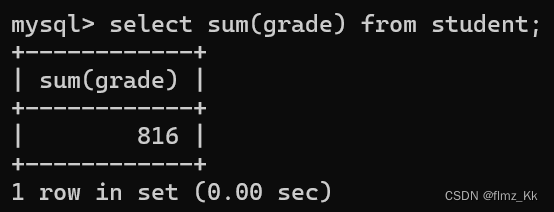
-- 计算某一列数据的总和,不是数字类型则无意义,遇到空值不参与计算,会直接跳过selectsum(列名/表达式)from 表名;
-- 演示-- 查询学生成绩的总和selectsum(grade)from student;
- avg:
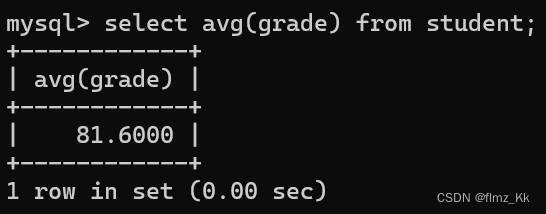
-- 计算某一列数据的平均值,不是数字类型则无意义,遇到空值不参与计算,会直接跳过selectavg(列名/表达式)from 表名;
-- 演示-- 查询学生的平均成绩selectavg(grade)from student;
- max:
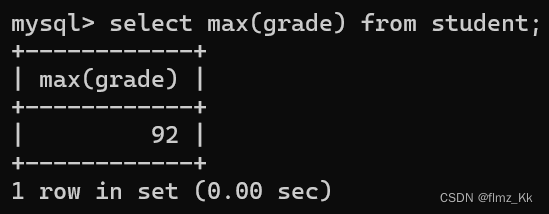
-- 计算某一列数据的最大值,不是数字类型则无意义,遇到空值不参与计算,会直接跳过selectmax(列名/表达式)from 表名;
-- 演示-- 查询本次考试的最高分selectmax(grade)from student;
- min:
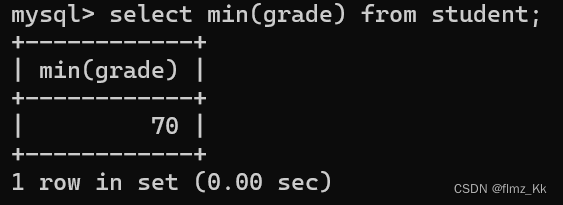
-- 计算某一列数据的最小值,不是数字类型则无意义,遇到空值不参与计算,会直接跳过selectmin(列名/表达式)from 表名;
-- 演示-- 查询本次考试的最低分selectmin(grade)from student;
分组查询:
group by
select 列名 from 表名 ......groupby 分组的列名;
- 分组查询允许我们根据一个或多个列对结果集进行分组,把列的相同的行归到一组中,完成分组
- 分完组后还可以对每个组进行聚合函数的操作
group by子句通常在where子句之后但在order by子句之前
测试数据:
-- 员工表:编号、姓名、岗位、薪资createtable emp (
id intprimarykeyauto_increment,
name varchar(20),
role varchar(20),
salary int);-- 插入多组数据insertinto emp(name, role, salary)values('张伟','经理',10000),('李娜','前端',12000),('王强','后端',18000),('赵敏','经理',15000),('孙悦','前端',9000),('周杰','后端',11000),('吴芳','老板',28000),('陈晨','后端',8000),('林峰','前端',15000),('郭静','经理',17000);
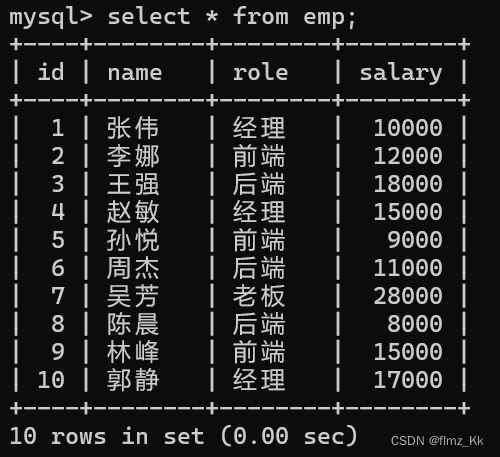
-- 演示-- 查询每个岗位的平均薪资select role,avg(salary)from emp groupby role;
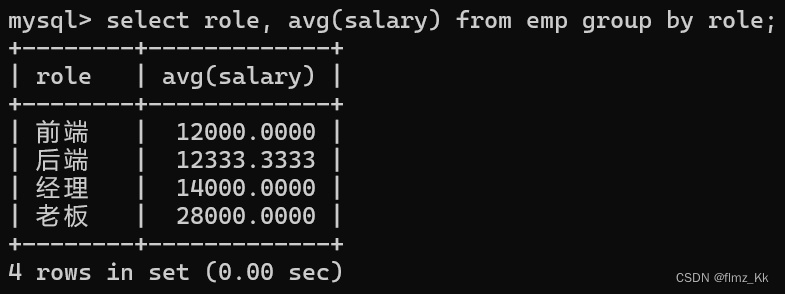
当然,我们也可以搭配
order by
来给分组后的结果进行排序
-- 演示-- 查询每个岗位薪资总和的升序排序select role,count(*),sum(salary)from emp groupby role orderbysum(salary);
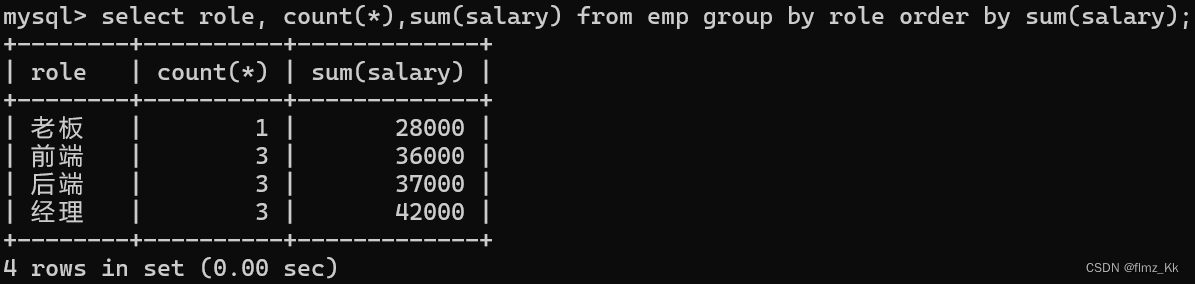
having:分组后的条件筛选
-- 演示-- 查询每个岗位薪资总和的升序排序,但是排除老板select role,count(*),sum(salary)from emp groupby role having role <>'老板'orderbysum(salary);

- 要注意,
having是在分组后才能使用,而where是在分组前才能使用,两者的顺序不要搞反了
-- 演示-- 统计每个岗位的平均薪资,排除 1 号员工“张伟”,同时也排除平均薪资超过20000的select role,avg(salary)from emp where id <>1groupby role havingavg(salary)<20000;

4.2 联合查询
联合查询就是把多张表联合到一起进行多表查询,而多表查询就是对多张表的数据取笛卡尔积
笛卡尔积:指的是两个或多个表之间进行的一种特殊的连接操作,每个表中的每一行都会与另一个表中的每一行配对,形成一个结果集。笛卡尔积没有任何限制,万物皆可笛卡尔积。符号为
×
例子:现有两张表,R 表有 A、B 两列,有三行数据,S 表有 C、D、E 三列,也是有三行数据,现将它们进行笛卡尔积操作,如下图所示
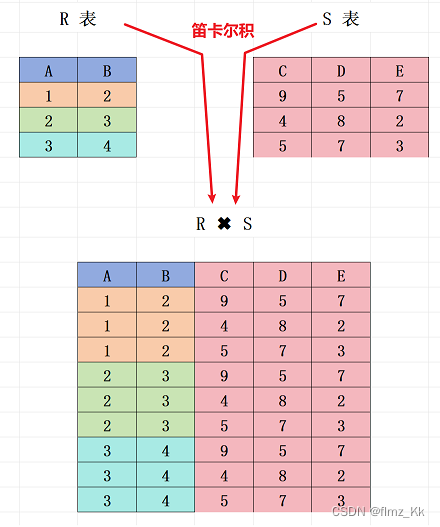
- 我们可以发现,笛卡尔积是把两个表的每一行都进行了组合,当两张表的行数为
n和m的时候,笛卡尔积后会得到n * m行数据
上面我们简单介绍了一下笛卡尔积,就是为了给接下来的联合查询做铺垫
试想一个场景,现在我们手头上有两张表:学生表,里面有学号、姓名、班级号;班级表,里面有班级号、班级名、班级人数。此时我们想要知道每个学生所在的班级名是什么,要怎么做该能查询到这个结果呢?
分析:我们要查询每个学生所在的班级名,学生姓名在学生表了,而班级名却在班级表里,此时我们就可以通过笛卡尔积联合两张表,查询到每个学生对应的班级名了
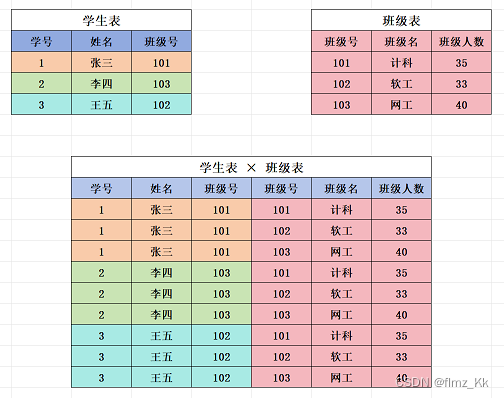
根据笛卡尔积,我们能发现,两个表的班级号相等的行就是我们的目标查询结果。但是表中也出现了很多不合理的记录,班级号不相匹配的记录就是无意义的
为了排除这些无意义的记录,我们可以再优化优化,加个条件:只查询 学生表的班级号 = 班级表的班级号 的这些记录,这就是真正意义上的联合查询
select 列名 from 表1, 表2where 连接条件 and 其他条件;select 列名 from 表1[inner]join 表2on 连接条件 and 其他条件;
- 当两张表中有相同列名时,查询时需要在列名加上 ”表名.“ 来指定要查询的是那张表中的列,如
学生表.班级号和班级表.班级号 - 若只想要简单的进行笛卡尔积,把后面的
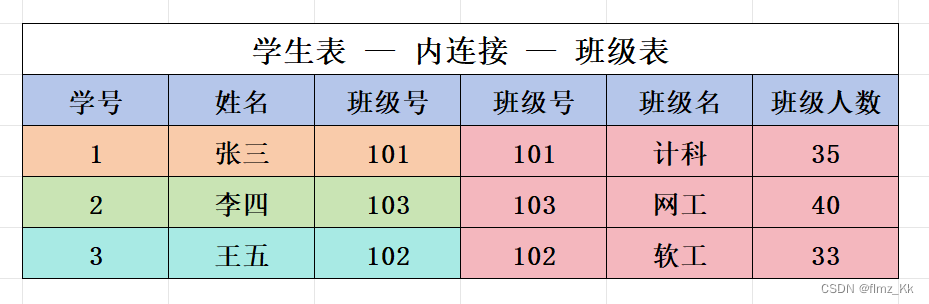
where 条件去掉就好 - 上面两种写法都是 OK 的,它就是相当于把两个表进行笛卡尔积,然后再根据条件筛选出有效信息,这种操作叫做内连接
- 查询时给表起别名,能查询结果看起来更加简洁
内连接:允许我们指定一个或多个连接条件,基于这个条件来合并两个表的行,即把两个表进行笛卡尔积
先学生表 × 班级表,再加上条件:学生表.班级号 = 班级表.班级号
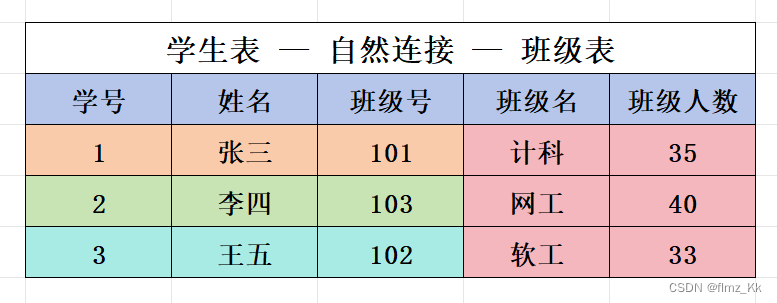
自然连接:是一种特殊的内连接,它是指连接两个表,并且只保留那些在两个表中都有的列,同时去除重复的列。符号为
⋈
当然啦,在写
sql
语句时,查询哪一列都能由我们指定,根据具体问题来写就好
-- 演示-- 根据上图回答问题:查询每个学生所在的班级名-- 先创建两张表,学生表(Student)和班级表(class)createtable student (
stu_id intprimarykey,
stu_name varchar(20),
class_id int,foreignkey(class_id)references class(class_id));createtable class (
class_id intprimarykey,
class_name varchar(20),
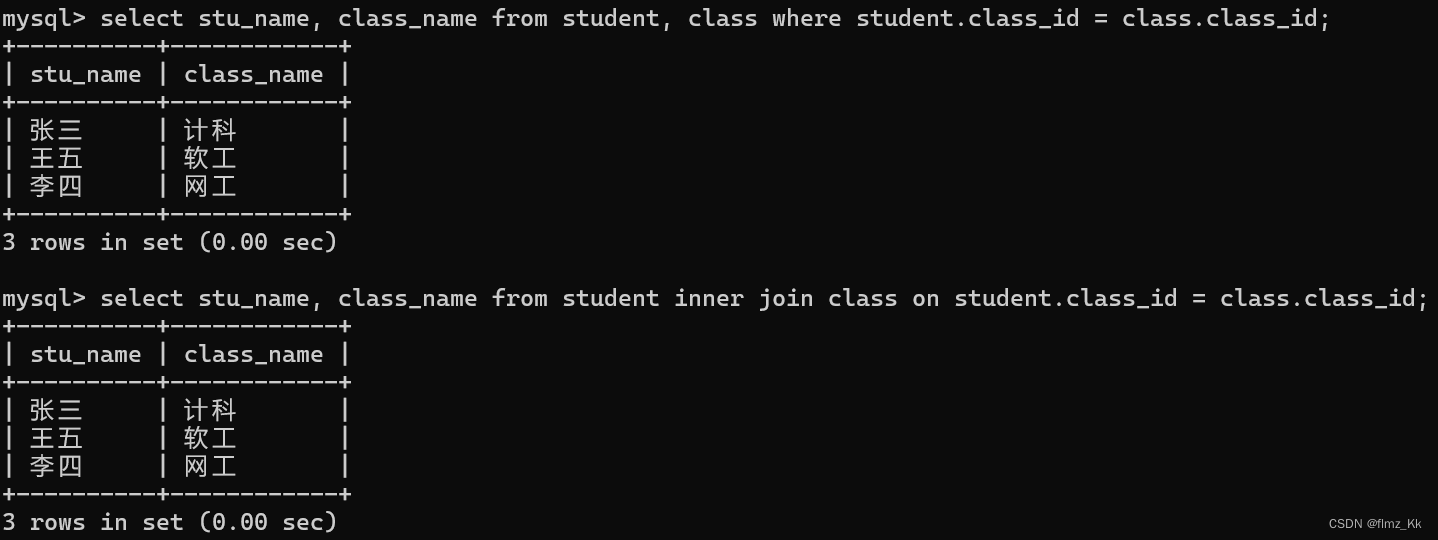
class_number int);-- 根据上面的分析,查询每个学生所在的班级名select stu_name, class_name from student, class where student.class_id = class.class_id;#方法一select stu_name, class_name from student innerjoin class on student.class_id = class.class_id;#方法二
外连接:与内连接相对,外连接操作会返回两个表中至少有一个匹配的行,而内连接只返回两个表中都有匹配的行
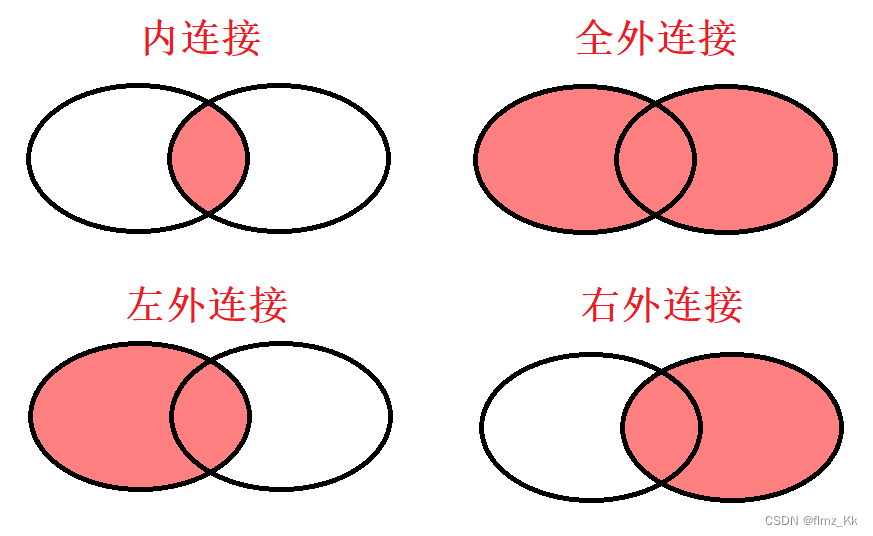
外连接分为三种:左侧的表完全显示就是左外连接,右侧的表完全显示就是右外连接,左右两侧的表都显示就是全外连接
下面我们还是拿图举例子,在学生表和班级表中都新增一行,注意新增行的班级号

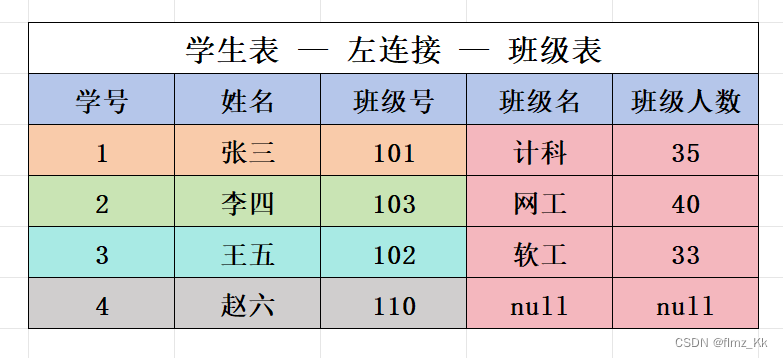
左外连接:
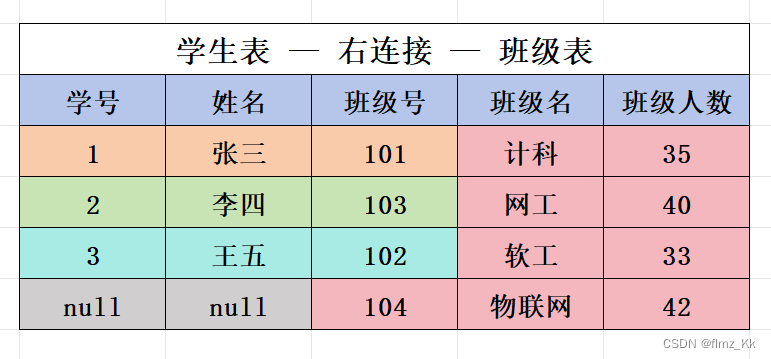
右外连接:
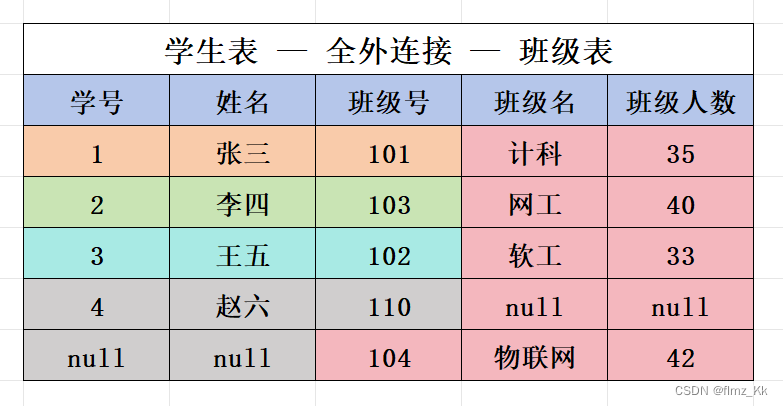
全外连接:
通过上图我们可以知道,外连接和内连接的主要区别在于两者在处理没有匹配的记录的不同:
内连接:
- 只返回两个表中匹配的记录
- 如果某个表中的记录没有在另一个表中找到匹配项,则这些记录不会被包含在结果集中
- 内连接通常用于需要精确匹配的情况
外连接:
- 外连接返回两个表中的所有记录,包括不匹配的记录
- 外连接分为左外连接、右外连接和全外连接,它们在处理不匹配记录时有不同的行为 - 左外连接:返回左表的所有记录,右表中的匹配记录会显示,没有匹配的记录会用
null填充- 右外连接:返回右表的所有记录,左表中的匹配记录会显示,没有匹配的记录会用null填充- 全外连接:返回两个表中的所有记录,不匹配的记录会在相应的表中用null填充(注意:MySQL 并不支持支持全外连接) - 外连接只能使用
...... join ...... on
-- 左外连接,表 1 完全显示select 列名 from 表1leftjoin 表2on 连接条件;-- 右外链接,表 2 完全显示select 列名 from 表1rightjoin 表2on 连接条件;# 写列名时要注意写清楚是哪个表中的列
下面我们将演示一下上面例子中的左外连接和右外连接在 MySQL 中的 sql 语句
(注意:因为在上面我们创建学生表时班级号用外键参照了班级表中的班级号,因此是插入不了 110 这个班级号的,博主下面演示的学生表是新建的,没有设置外键所以才可以正常插入 110 班级号)
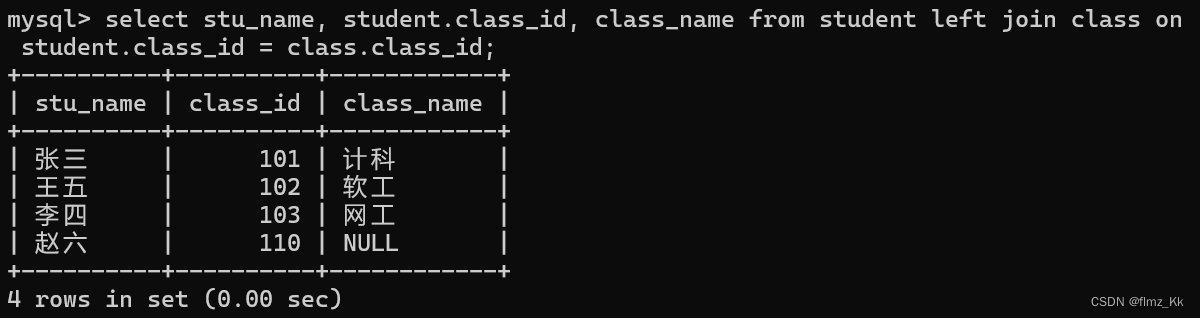
-- 演示-- 使用查询每个学生的班级名称(左外连接)select stu_name, student.class_id, class_name from student leftjoin class on student.class_id = class.class_id;
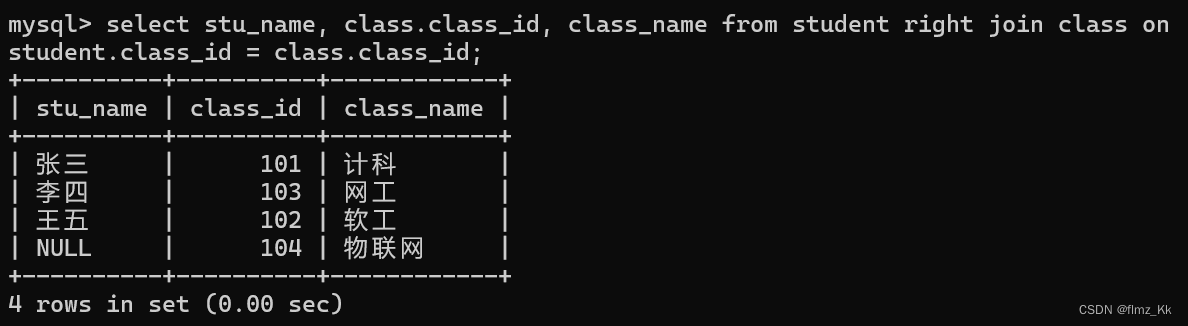
-- 演示-- 使用查询每个班级名称对应的学生姓名(右外连接)select stu_name, class.class_id, class_name from student rightjoin class on student.class_id = class.class_id;
在使用外连接的时候要注意两张表的顺序以及使用的是
left
还是
right
,别搞反了
4.3 自连接查询
顾名思义,就是自己和自己进行笛卡尔积,实现自连接查询。本质上就是把一张表中的行关系转换称列关系
select 列名 from 本表 as 别名1, 本表 as 别名2where 查询条件;
在自连接中,必须要使用不同的别名来引用相同的表,以在加入查询条件时混淆。不使用别名会产生混淆,MySQL 也会报错
-- 演示-- 还是上面的 student 表,使用自连接select*from student as s1, student as s2;
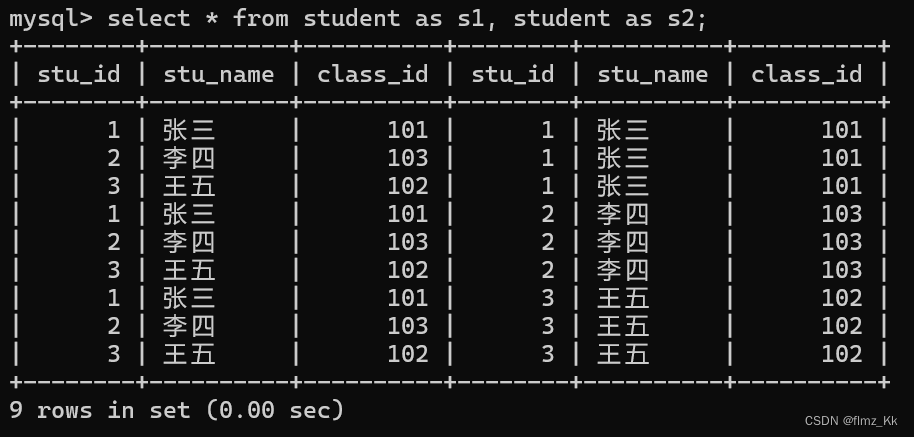
当然里面还是有很多无意义数据,因此我们得使用
where
来筛选出有意义的信息出来
-- 演示select*from student as s1, student as s2 where s1.stu_id = s2.stu_id;
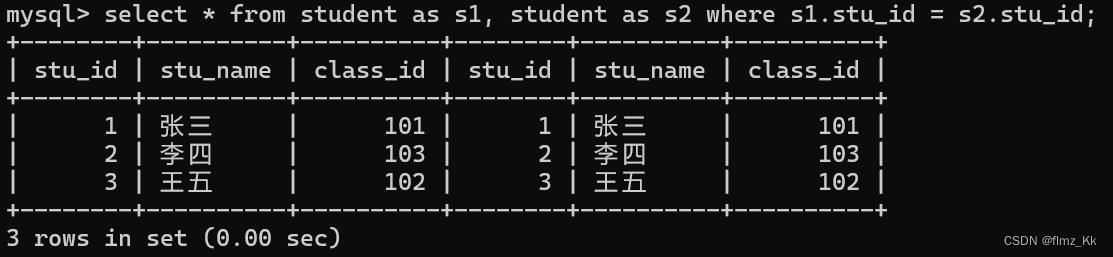
自连接用来找出表中重复的记录。例如,如果你想找出哪些客户有多个订单,可以使用自连接来比较订单表中的客户ID。它还有很多应用场景,像层次结构查询、关联表中的相同实体等等
4.4 嵌套查询
嵌套查询又叫子查询,指的是嵌入在其他 sql 语句中的
select
语句。简单来说就是套娃,一个查询语句嵌套在另一个查询语句内部的查询
单行子查询:
操作符:=、>、>=、<、<=、<>
-- 演示-- 假设现在有个员工表,里面有属性:员工编号、员工姓名、薪水-- 现在我们想要查询薪水大于平均薪水的员工姓名select emp_name, salary from emp where salary >(selectavg(salary)from emp);
多行子查询:
操作符说明in等于列表中的任意一个any比较一个值和一个子查询返回的结果集中的任意一行all比较一个值和一个子查询返回的所有行exists用于检查子查询是否返回任何行
4.5 合并查询
**关键词:
union
**
select 列名 from 表名 [where 条件]unionselect 列名 from 表名 [where 条件]
- 合并查询会取得两个表的并集。要求两个表的列的类型、数量、类型都要相等
union会自动去掉两个表的重复行,union all就不会去重
-- 演示-- 查询学生表中学号小于 3 的学生或者成绩大于等于 80 的学生select*from student where id <3unionselect*from student where grade >=80;-- 其实我们也可以用 orselect*from student where id <3or grade >=80;
想要显示出重复行使用
union all
就可以
5. 修改
**关键词:
update
**
update 表名 set 列名 = 新值, 列名 = 新值 ...[where...][orderby...][limit...];
update修改的是硬盘里真实的值,会永久保存的,跟我们前面的查询不一样
-- 演示-- 将学生表里叫'张三'的学生改为'李四'update student set name ='李四'where name ='张三';-- 将成绩倒数前三的同学的分数都加 10 分update student set grade = grade +10orderby grade limit3;
6. 删除
**关键词:
delete
**
deletefrom 表名 [where...][orderby...][limit...];
delete总是使用where子句来指定要删除的记录。如果不使用where子句,那么整个表的所有记录都会被删除- 如果表之间存在外键约束,比如其他表中存在依赖于该记录的外键,删除记录可能会失败
- 如果外键约束设置为级联删除,数据库会自动删除所有引用该主键记录的外键表中的相关记录
- 执行删除操作前要非常小心,因为一旦执行,就无法恢复被删除的数据(除非有备份),或者我们可以使用逻辑删除(前面有讲)
-- 演示-- 删除表中叫做'张三'的学生deletefrom student where name ='张三';
结语
本篇博客我们主要介绍了数据表的新增、约束、查询、更新、删除一系列操作,其中最重要的就是查询了,通过篇幅比重也能看出来。因为在之后的实际开发工作中,查询可能是我们天天要打交道的操作,像条件查询、排序查询、分页查询、聚合查询、联合查询、嵌套查询等等都是很重要的查询手段,而其中有很多注意事项博主这也没有讲到,十分抱歉没办法面面俱到。同时关于增删改,我们也需要非常熟悉这些操作
本篇博客的篇幅近 1w 字,是博主写博客有史以来字最多的一篇,本来是想拆成两篇来写的,但是把重要的查询操作割裂开来讲感觉不是很好,因此还是花了近一周课余时间来写本篇博客,希望能给您带来一点点帮助
希望大家能够喜欢本篇博客,有总结不到位的地方还请多多谅解。若有纰漏,希望大佬们能够在私信或评论区指正,博主会及时改正,共同进步!
版权归原作者 flmz_Kk 所有, 如有侵权,请联系我们删除。