
前言
在业务上,对数据的更新是非常频繁的,mysql 来说就是一条update 语句。大家有没有感觉update 语句对普通索引的更新总是很快,这是为啥呢?是不是很好奇更新语句的执行流程是怎么样的呢?
由于语句执行错误,数据被污染,我们会让DBA 帮我们恢复到更新前的状态,这又是怎么完成的呢?
对于这些问题,会在接下来的文章详细讲解,本章引擎是innodb 引擎。
为了方便讲解,我将画一个流程图,这个流程图包括各层需要的日志文件。
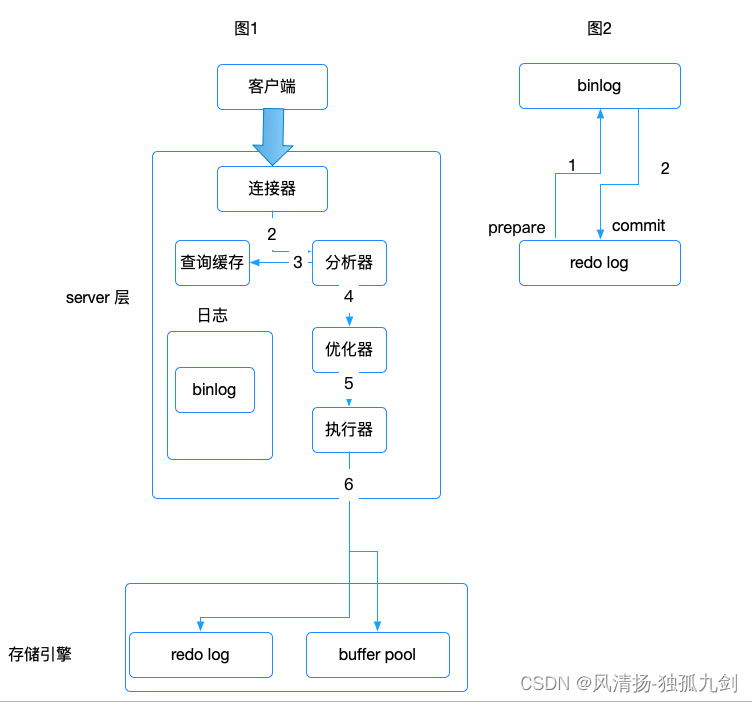
对流程图主要模块解释
连接器
是主要连接数据库,连接器负责跟客户端建立连接、获取权限、维持和管理连接。客户端具体怎么连接的如下图。
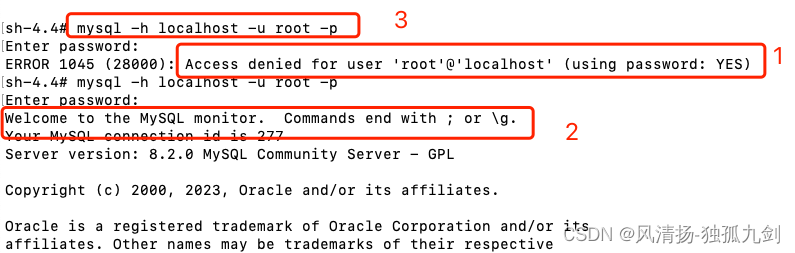
如上图 3 就是连接命令,如果输密码错误,那么就会返回1的信息,如果密码正确,连接器会到权限表里查出你拥有的权限。之后所以的操作都依赖次权限,不在验证权限,除非重新登录。也就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
一个简单的连接,首先需要tcp 三次握手,其实还需要获取当前连接的权限。这个过程也是挺复杂的,为了提高效率,建议大家用长连接。这样就提高的查询效率,在系统优化时,我们会用连接池去管理这些长连接,在系统启动时都会创建一定数量的连接,以后每次使用的时候,就从连接池拿一个连接,避免了每次因为连接mysql需要tcp 三次握手,获取当前连接权限的资源消耗,提高了系统的响应,这是一个优化点。
长连接是不是越多越好了,当然不是,mysql 在执行过程中临时使用的内存时管理在连接对象里的,这些资源在连接断开时候才释放。 太多的连接会占用太多的内存,内存占用太大,会被操作系统强行OOM掉,mysql 就会异常重启。
长连接如果长时间没有用,mysql 连接器就会自动断开,参数是由 wait_timeout 控制的,默认8小时。如果连接关闭后,在次发动请求,会收到一个错误提醒 Lost connection to MySQL server during query。如果这个时候你要继续就会重连,不过在连接池设计时, 使用连接前会先去ping,如果没有返回错误,关掉这个连接,重新建一个连接,为了避免一个连接占用太多的内存,在连接池设计中,连接都是有生命周期的,到了时间就释放掉。在mysql 客户端,如果执行了一个特别大的操作,通常会执行 mysql_reset_connection 重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
查询缓存
查询缓存,在以前版本还有,我的mysql8.0 版本已经去掉了,它的存储是key,value 形式。以前查询的记录会放到缓存,再次查询从查询缓存返回。如果表更新,这个表的所有缓存都清空。弊大于利。
分析器
分析器包括词法分析和语法分析,先进行词法分析,sql 语句都是由字符串和空格组成。分析出sql 语句的关键字,select ,update。mysql 在server 层需要知道你做什么,告诉存储引擎需要给我什么东西或进行什么操作,还要分析出表名,对哪个表操作。还有字段名,对某些字段进行操作。然后需要进行语法分析,分析出sql 是否有语法错误,有语法错误,就会返回 You have an error in your SQL syntax。
优化器
优化器决定sql 用哪个索引,会根据引擎要扫描的行数,回表等因素计算成本,会选择一个成本最低的,效率高的索引。对于join 表,会根据表的行数决定表的连接数序,哪个表是左表。
执行器
执行器已经拿到表名了,还要看这个连接对表有没有执行权限,如果有,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
日志模块
日志模块主要是讲redo log 和 binlog
redo log 是innodb 引擎特有的,是在引擎层。为mysql 提供了crash-safe的能力,可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,它记录的是某页做了什么修改。大小是固定的,这个可以根据磁盘去设置。由于大小是固定的,所以是循环写,会把以前的记录覆盖掉。
binlog 是在server 层,所有的存储引擎都可以用,也叫归档日志。它有几种模式,statement 记录sql 语句, row 记录每一行数据修改形式,mixed 是混合模式。主要用在数据恢复,主从,还有比如CDC 去消费binlog 去完成相关业务。
这两个日志缺一不可,缺少了 redo log 。mysql 崩溃有可能造成数据丢失,缺少binlog 数据就没法备份。
两阶段提交
我们在分布式事务也有一种两阶段提交,都是为了保证数据的一种,mysql 的两阶段提交,是为了保证数据库与数据备份的数据一致性,说白了就是保证binlog 与 redo log 数据的一致性。
我们拿更新过程来说吧,比如一个语句是 update t set a=1 where 1=1. 如上图2 所示
- 首先会判断buffer pool 是否有这条记录,如果没有,就根据索引,从页里读出来,放到buffer pool 里,会记录它属于某个页的具体信息
- 会在redo log 里记录某页进行了什么修改,此时的redo log 是 prepare 状态,同时也会在 buffer pool 的 chang buffer 进行相应的记录
- 存储引擎层会通知 server 层,在binlog 记录这条语句的修改
- binlog 记录完成了,通知redo log 把prepare 改成commit 状态。
上面就是两阶段提交的基本步骤。
大家有时在想 binlog 写完,redo log 还没 commit 前发生 crash,那崩溃恢复的时候 MySQL 会怎么处理?毕竟这个过程确实存在。
- 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
- 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:如果是就提交事务,否则就会滚
那么分析到现在就是怎么判断 binlog 是否存在并完整呢?
- statement 格式的 binlog,最后会有 COMMIT;
- row 格式的 binlog,最后会有一个 XID event。
另外,在 MySQL 5.6.2 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性。对于 binlog 日志由于磁盘原因,可能会在日志中间出错的情况,MySQL 可以通过校验 checksum 的结果来发现
那么怎么恢复呢?
这两个日志有一个共同的数据字段 叫 XID。mysql 崩溃恢复的时候会去扫码 redo log. 如果 redo log 有commit ,就直接提交,恢复 change buffer 相关的内容。如果没有commit 就去bin log 找是否有对应的 XID,有的话,binlog 也直接提交,没有的话,就回滚。
版权归原作者 风清扬-独孤九剑 所有, 如有侵权,请联系我们删除。