
Kafka集群环境搭建
一、环境说明
二、安装步骤
一、环境说明
目前的Kafka版本还是需要借助zookeeper来存储cluster、brokers、consumer等相关元信息,在当前版本即
在本案例中,我们采用了外部的zookeeper,即搭建了三节点的集群zookeeper环境,以其作为Kafka2_12_3.1.0版本的元数据存储库。
zookeeper环境配置如下:
节点 安装路径 dataDir路径
hd1 /opt/module/apache-zookeeper-3.5.7-bin /opt/module/apache-zookeeper-3.5.7-bin/zkData
hd2 /opt/module/apache-zookeeper-3.5.7-bin /opt/module/apache-zookeeper-3.5.7-bin/zkData
hd3 /opt/module/apache-zookeeper-3.5.7-bin /opt/module/apache-zookeeper-3.5.7-bin/zkData
kafka环境配置如下:
节点 安装路径 Log路径
hd1 /opt/module/kafka_2.12-3.0.0 /opt/module/kafka_2.12-3.0.0/logs
hd2 /opt/module/kafka_2.12-3.0.0 /opt/module/kafka_2.12-3.0.0/logs
hd3 /opt/module/kafka_2.12-3.0.0 /opt/module/kafka_2.12-3.0.0/logs
二、安装步骤
上传Kafka安装包,解压安装
修改server.properties文件,只需要修改如下几项即可:
broker.id=0
log.dirs=/opt/data/kafka212_300/datas
zookeeper.connect=hd1:2181,hd2:2181,hd3:2181/kafka
group.initial.rebalance.delay.ms=0
其他配置默认即可
分发整个Kafka安装目录到其他节点
scp -r /opt/module/kafka_2.12-3.0.0 root@hd2:/opt/module
scp -r /opt/module/kafka_2.12-3.0.0 root@hd3:/opt/module
到其他两个节点分别修改server.properties中的broker.id为:1和2,
注意:broker.id 不得重复
启动Kafka集群
先启动zookeeper集群(自行启动)
/opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
依次在hd1、hd2,hd3上启动Kafka集群,执行如下命令:
/opt/module/kafka_2.12-3.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.0.0/config/ &
整合集群上启动命令写成脚本
zk.sh zookeeper.sh启动脚本
#!/bin/bash
case $1 in
"start"){
for i in hd1 hd2 hd3
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start"
done
};;
"stop"){
for i in hd1 hd2 hd3
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh stop"
done
};;
"status"){
for i in hd1 hd2 hd3
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh status"
done
};;
*)
echo "Input Args Error..."
echo "$0 [start|stop|status]..."
;;
esac
kf.sh kafka.sh启动脚本
#!/bin/bash
kafka_start() {
for i in hd1 hd2 hd3
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.12-3.0.0/config/server.properties"
done
}
kafka_stop() {
for i in hd1 hd2 hd3
do
echo " --------关闭 $i Kafka-------"
ssh $i "/opt/module/kafka_2.12-3.0.0/bin/kafka-server-stop.sh "
done
}
case $1 in
"start")
kafka_start
;;
"stop")
kafka_stop
;;
"restart")
kafka_stop
kafka_start
;;
*)
echo "Input Args Error..."
echo "$0 [start|stop|restart]..."
;;
esac
注意:
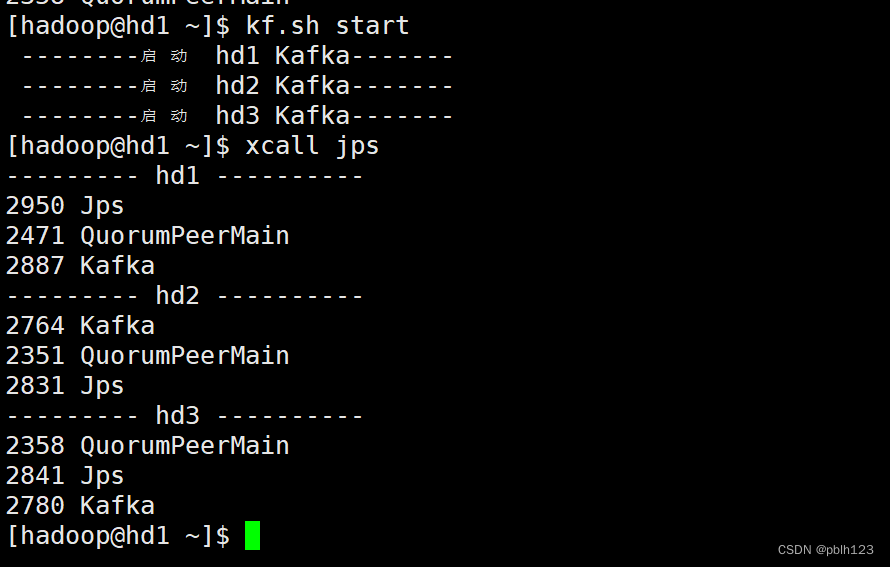
验证: 三节点上执: jps命令即可看到进程名称为:Kafka
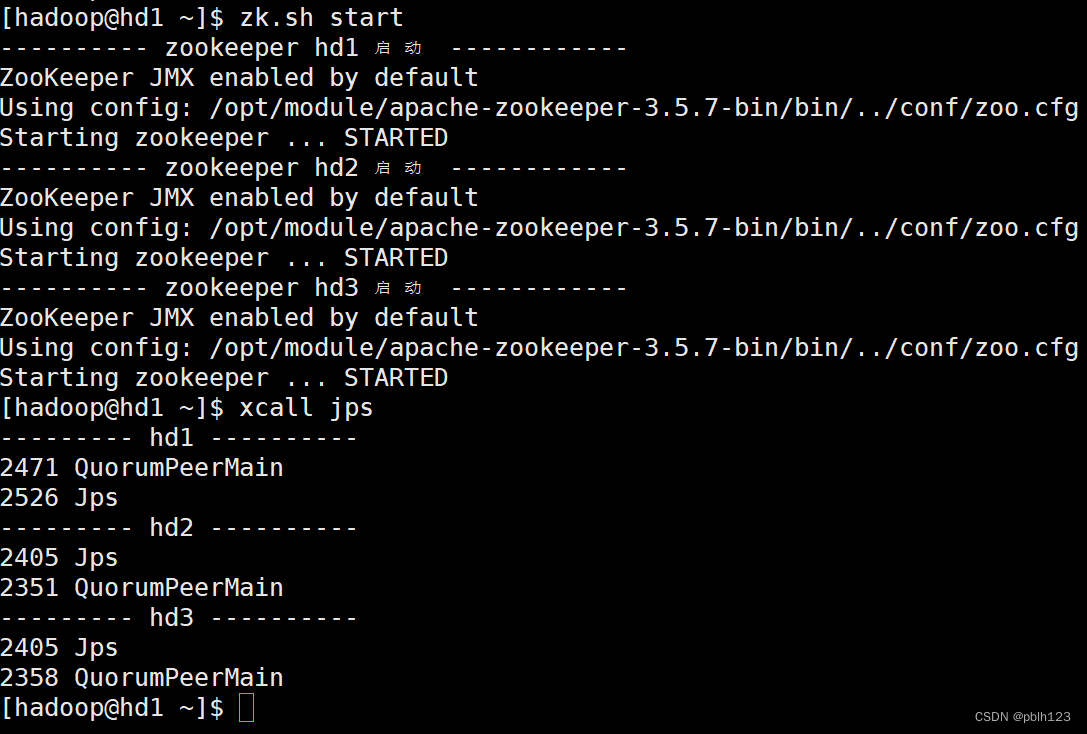
zookeeper启动
kafka启动
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。