
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2022-2024年最全的计算机软件毕业设计选题大全:1000个热门选题推荐✅
Java项目精品实战案例《100套》
Java微信小程序项目实战《100套》
Python项目实战《100套》
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
文章目录
前言:
嗨喽,大家好,今天为大家带来的是基于大数据的Boss直聘招聘可视化系统,Python基于Django的Boss直聘招聘可视化项目,该项目使用 Django 框架,Mysql 数据库,request,selenium 框架进行爬虫,实现招聘数据的采集,清洗等,该项目总体来说还是挺不错的,界面美观,下面针对这个项目做具体介绍。
基于Python Django 的Boss直聘招聘可视化分析系统(附源码)
1:项目涉及技术:
项目后端语言:python django
项目页面布局展现:前端bootstrap
项目数据可视化呈现:html, css,echars
项目数据操作:mysql数据库
项目数据获取方式:爬虫(selenium,Xpath)
2 Django 介绍
Django 是在 2005 年由 Adrian Holovaty 和 Simon Willison 等人开发,最初是为新闻网站开发的。它是一个开源项目,遵循 BSD 许可证。Django 的名字来源于 Adrian Holovaty 的母亲,她是一位爵士音乐家。
Django 的主要特点
- MTV 架构:Django 使用模型(Model)、视图(View)、模板(Template)的架构模式。
- 自动管理数据库:Django 自带一个强大的 ORM(对象关系映射)系统,可以自动将 Python 对象映射到数据库表。
- 自动生成 admin 界面:Django 可以自动为你的数据库模型生成一个后台管理界面。
- 支持多种数据库:Django 支持多种数据库系统,如 PostgreSQL、MySQL、SQLite 等。
- 安全性:Django 提供了很多内置的安全功能,如防止 SQL 注入、跨站脚本(XSS)、跨站请求伪造(CSRF)等。
- 国际化和本地化:Django 支持多语言,可以轻松地将网站内容翻译成不同的语言。
- 中间件支持:Django 允许开发者通过中间件来扩展或修改框架的行为。
Django 的优点
- 快速开发:Django 提供了很多内置的功能和工具,可以快速搭建起一个网站。
- 可扩展性:Django 的设计允许它随着项目的成长而扩展。
- 社区支持:Django 有一个活跃的社区,提供了大量的第三方库和插件。
- 文档齐全:Django 的官方文档非常全面,对于初学者和有经验的开发者都很有帮助。
- 安全性:Django 内置了很多安全特性,减少了开发者需要考虑的安全问题。
Django 的缺点
- 重量级:对于一些小型项目,Django 可能显得过于庞大和复杂。
- 学习曲线:对于初学者来说,Django 的学习曲线可能比较陡峭。
- 定制性:虽然 Django 提供了很多内置的功能,但有时候这些功能可能限制了项目的定制性。
- 性能:在某些情况下,Django 的性能可能不如一些更轻量级的框架,如 Flask。
- 依赖性:Django 依赖于 Python,这意味着它不能像其他语言那样轻松地跨平台运行。
总的来说,Django 是一个功能强大、适合快速开发的 Web 框架,尤其适合那些需要快速构建复杂 Web 应用的项目。然而,对于需要高度定制化或轻量级解决方案的项目,可能需要考虑其他框架。
3 Python 爬虫功能实现
Python Selenium是一个用于自动化Web浏览器操作的工具,广泛应用于Web应用程序测试、网页数据抓取和任务自动化等场景。Selenium支持多种编程语言的API,并且可以模拟用户在浏览器中的操作,如点击、输入等。它允许用户编写自动化程序,通过浏览器驱动直接对浏览器进行操作,获取用户在浏览器上可以获得的信息。
爬虫的基本原理是模拟人的浏览器行为,通过发送HTTP请求来获取网页内容。爬虫程序需要具备网络请求、网页解析、数据存储、并发控制和反反爬虫策略等功能。爬虫技术可以用于搜索引擎、数据挖掘分析、自动化测试和个人信息保护等多种应用场景。然而,爬虫技术也面临着反爬虫机制、数据清洗去重、法律道德问题以及对目标网站影响等挑战。
要实现一个爬虫,首先需要确定目标网站和所需数据类型,然后设计爬虫逻辑,包括请求范围、数据提取规则、错误处理和优化策略。在实际项目实施中,可能需要使用分布式爬虫、代理IP和反反爬虫技术等策略来提高效率和稳定性。最后,抓取的数据需要进行清洗、验证和存储,以便后续分析和应用。
在编写爬虫时,可以使用Python的requests库来发送HTTP请求,获取网页内容。对于动态网页,可以使用Selenium库来模拟用户操作,获取JavaScript渲染后的内容。数据抓取后,可以使用BeautifulSoup库来解析HTML,提取所需的数据。在数据提取过程中,可能需要使用正则表达式等技术来清洗和组织数据。
需要注意的是,爬虫应该尊重目标网站的robots.txt协议,合理设置请求频率,避免对目标网站造成过大负担。同时,应该遵守相关法律法规,尊重用户隐私和知识产权。在实际应用中,还应该考虑使用代理IP和伪装技术来避免被封禁IP地址,并与目标网站管理员建立良好的沟通渠道。
当然,下面我将提供一些简单的示例代码,展示如何使用Python进行基本的网页爬取和Selenium自动化操作。
使用Requests库进行简单的网页爬取
import requests
from bs4 import BeautifulSoup
# 目标网页URL
url ='http://example.com'# 发送HTTP GET请求
response = requests.get(url)# 检查请求是否成功if response.status_code ==200:# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text,'html.parser')# 提取网页标题
title = soup.find('title').text
print('网页标题:', title)# 提取所有链接for link in soup.find_all('a'):print(link.get('href'))else:print('请求失败,状态码:', response.status_code)
使用Selenium进行动态网页爬取
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 初始化WebDriver
driver = webdriver.Chrome()# 打开网页
driver.get('http://example.com')# 等待页面加载
time.sleep(3)# 简单睡眠等待,实际应用中应使用更智能的等待条件# 找到元素并进行操作,例如输入文本
input_element = driver.find_element(By.NAME,'q')
input_element.send_keys('Python')
input_element.send_keys(Keys.RETURN)# 等待搜索结果
time.sleep(3)# 获取搜索结果页面的标题print(driver.title)# 关闭浏览器
driver.quit()
使用代理和Headers进行爬取
import requests
# 目标网页URL
url ='http://example.com'# 设置请求头,模拟浏览器访问
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'}# 设置代理IP
proxies ={'http':'http://10.10.1.10:3128','https':'https://10.10.1.10:1080',}# 发送带有Headers和代理的HTTP GET请求
response = requests.get(url, headers=headers, proxies=proxies)if response.status_code ==200:print(response.text)else:print('请求失败,状态码:', response.status_code)
请注意,上述代码仅为示例,实际使用时需要根据目标网站的具体情况进行调整。同时,使用Selenium进行爬取时,应确保遵守目标网站的使用条款,避免对网站造成不必要的负担。
4:项目功能:
1 登录注册
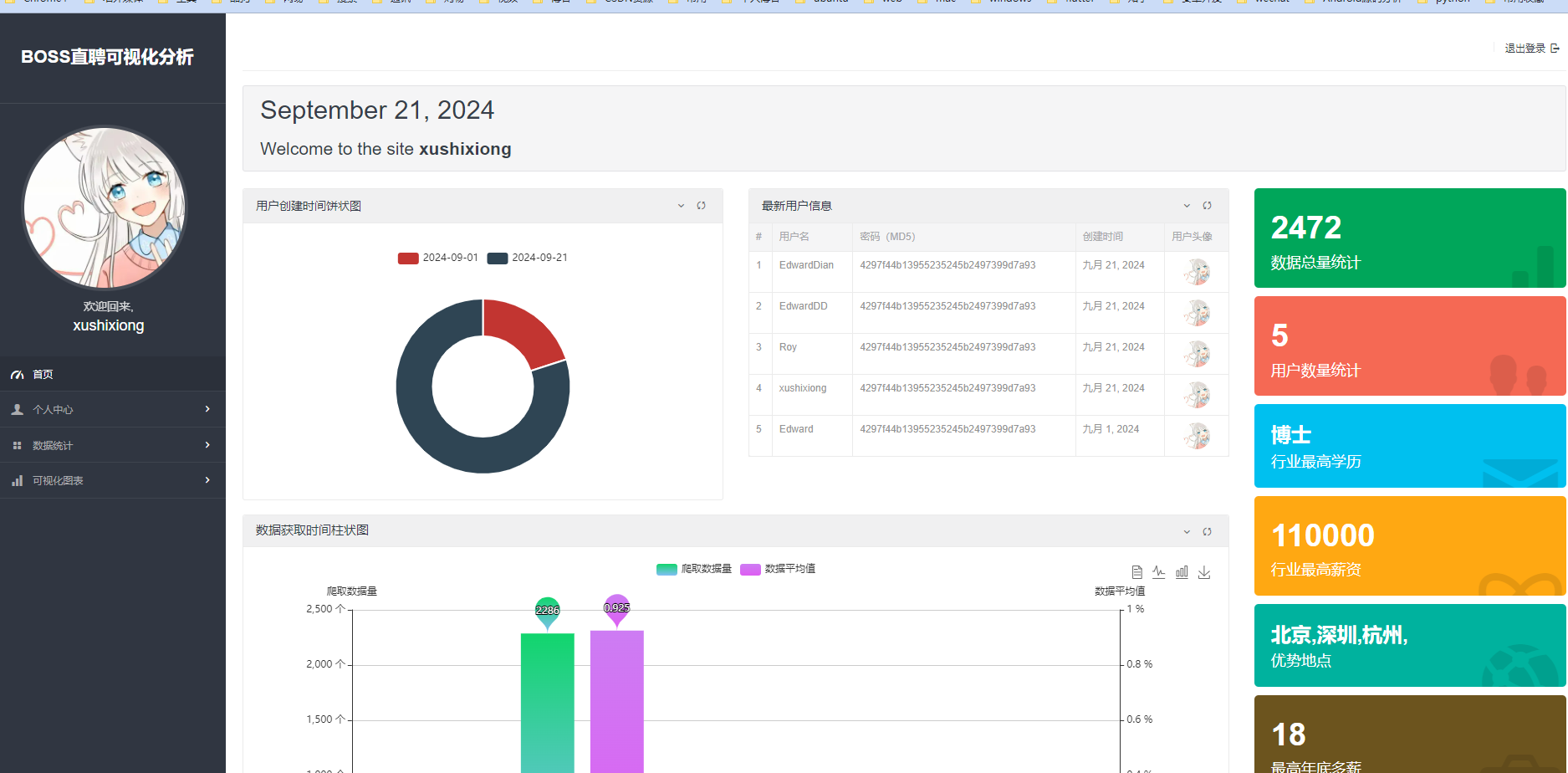
爬取数据后启动项目会把数据都存放在数据库里,(数据库有3个表,一个工作岗位信息表,一个用用户信息表,一个工作收藏表),然后进入项目的登陆注册页面,以及会对用户的账号密码经行校验和存储,校验成功后进入首页:
首页招聘数据
左侧为导航状态栏,个人中心有修改个人信息和修改密码的子页面,数据统计有数据总览和岗位收藏的子页面,数据可视化有 薪资,公司信息,员工人数以及企业融资等信息的可视化页面。
招聘数据
这里的招聘数据,是我们爬虫的数据,存储在 mysql 数据库当中,如果我们想要展示,可以通过读取数据库进行展示,同时进行分页

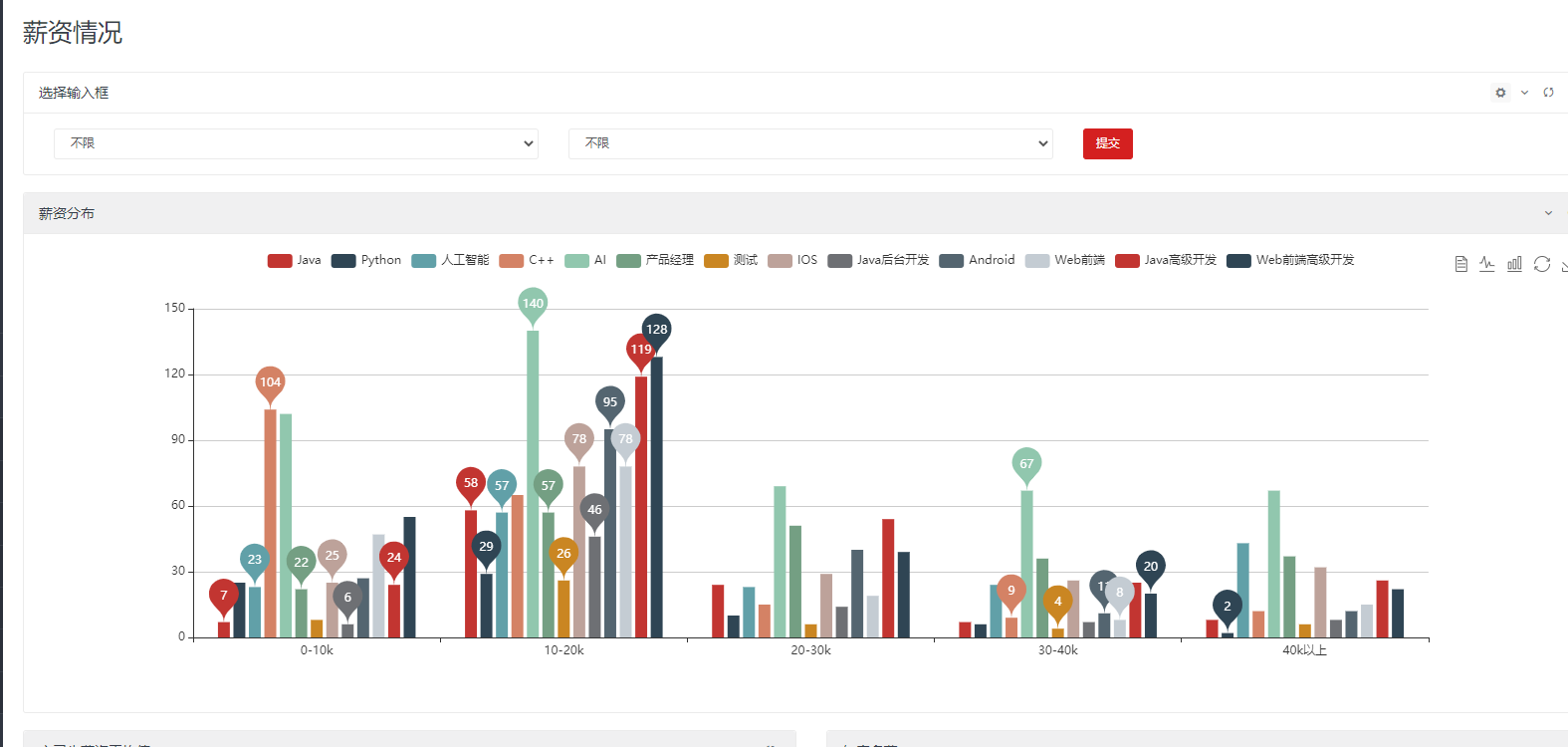
薪资情况
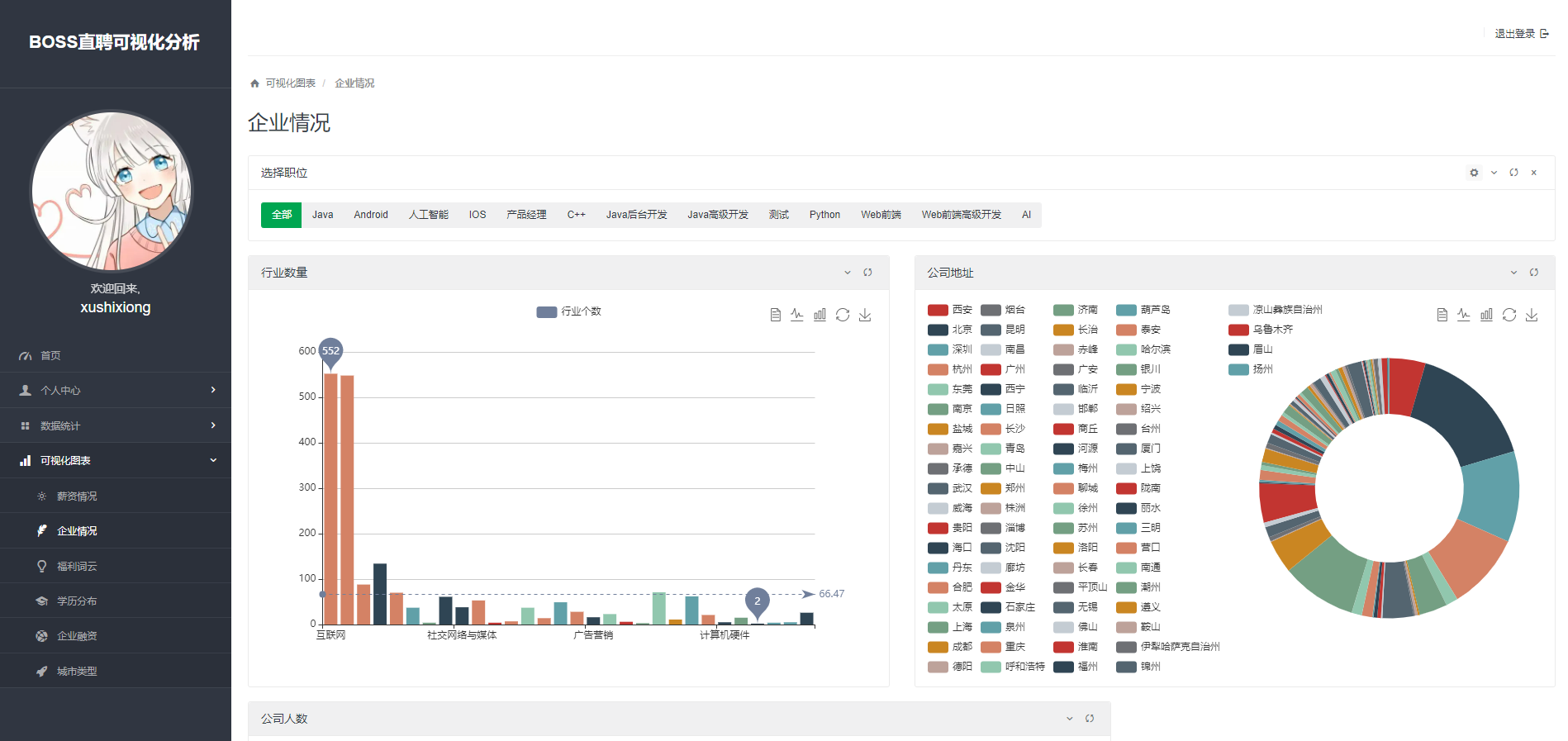
企业情况
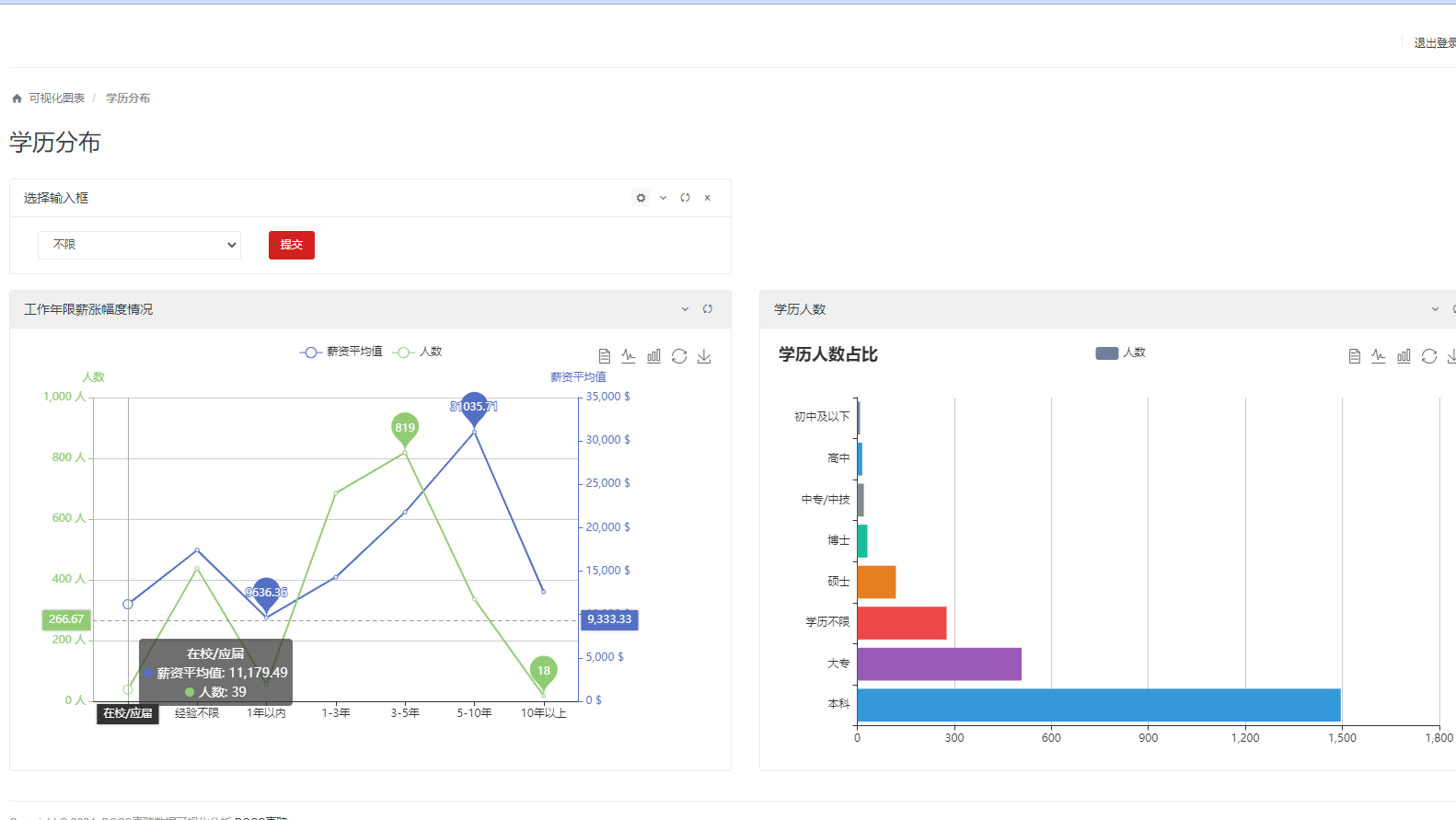
学历分布
推荐阅读
基于Python的微博大数据舆情分析可视化系统
Python 基于微博舆情分析系统的设计与实现,GUI可视化界面(课程设计,附源码,教程)
基于Python的微博舆论分析,微博情感分析可视化系统(V2.0)
基于Python的微博热搜、微博舆论可视化系统(V3.0)
Python基于微博的旅游情感分析、舆论分析可视化系统
更多毕业设计
2023年Java毕业设计如何选题?500道创新创意毕业设计题目推荐
微信小程序毕业设计项目合集
Java毕业设计-SpringBoot+Vue毕业设计项目合集
Java毕业设计-Java SSM+JSP 项目合集
Java毕业设计-Java JSP 项目合集
Android 毕业设计-项目合集
版权归原作者 程序员徐师兄 所有, 如有侵权,请联系我们删除。