
原生定时任务先天缺陷
1、不支持分片任务:处理有序数据时,多机器分片执行任务处理不同数据
2、不支持生命周期统一管理:不重启服务情况下关闭、启动服务
3、不支持集群:存在任务重复执行的问题
4、不支持失败重试:出现异常后任务终结,不能根据执行状态控制任务重新执行
5、不支持动态调整:不重启服务的情况下修改任务参数
6、无报警机制:任务失败后没有报警机制
7、任务数据难以统计:任务数据量大时,对于任务执行情况无法高效的统计执行情况
简介
xxl-job是大众点评员工徐雪里于2015年发布的分布式任务调度平台,是一个轻量级分布式任务调度框架,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。
至今,XXL-JOB已接入多家公司的线上产品线,接入场景如电商业务,O2O业务和大数据作业等。截止最新统计时间为止,已接入登记在册的公司有446家,有大众点评、中国移动、海尔、联想、京东、网易、拉卡拉、360金融、滴滴、优信二手车等等。
特性
1、简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
2、动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
3、调度中心(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心;
4、执行器(分布式):任务分布式执行,任务"执行器"支持集群部署,可保证任务执行;
5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
7、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
8、故障转移:任务路由策略选择"故障转移"情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
9、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
10、任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务;
11、任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试;
12、任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
13、分片广播任务:执行器集群部署时,任务路由策略选择"分片广播"情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
14、动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
15、事件触发:除了"Cron方式"和"任务依赖方式"触发任务执行之外,支持基于事件的触发任务方式。调度中心提供触发任务单次执行的API服务,可根据业务事件灵活触发。
16、任务进度监控:支持实时监控任务进度;
17、Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志;
18、GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
19、脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS、PHP、PowerShell等类型脚本;
20、命令行任务:原生提供通用命令行任务Handler(Bean任务,"CommandJobHandler");业务方只需要提供命令行即可;
21、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
22、一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
23、自定义任务参数:支持在线配置调度任务入参,即时生效;
24、调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞;
25、数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性;
26、邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件;
27、推送maven中央仓库: 将会把最新稳定版推送到maven中央仓库, 方便用户接入和使用;
28、运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
29、全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行;
30、跨语言:调度中心与执行器提供语言无关的 RESTful API 服务,第三方任意语言可据此对接调度中心或者实现执行器。除此之外,还提供了 “多任务模式”和“httpJobHandler”等其他跨语言方案;
31、国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文;
32、容器化:提供官方docker镜像,并实时更新推送dockerhub,进一步实现产品开箱即用;
33、线程池隔离:调度线程池进行隔离拆分,慢任务自动降级进入"Slow"线程池,避免耗尽调度线程,提高系统稳定性;
34、用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色;
35、权限控制:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作;
系统设计思路
调度模块(调度中心): 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover
执行模块(执行器): 负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求;
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑;
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性
架构图
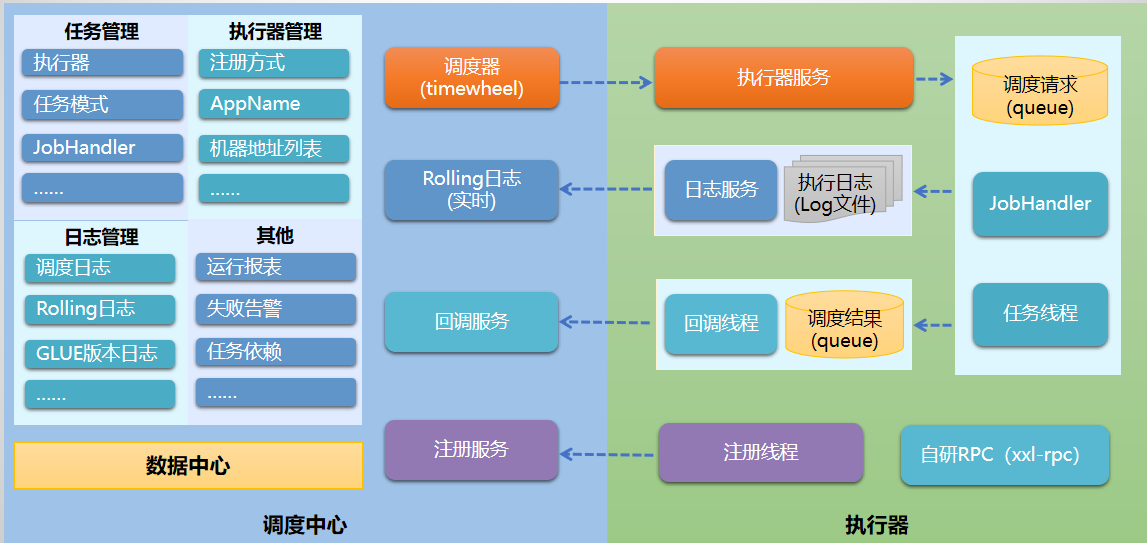
工作原理
任务执行器根据配置的调度中心的地址,自动注册到调度中心
达到任务触发条件,调度中心下发任务
执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
执行器的回调线程消费内存队列中的执行结果,主动上报给调度中心
当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
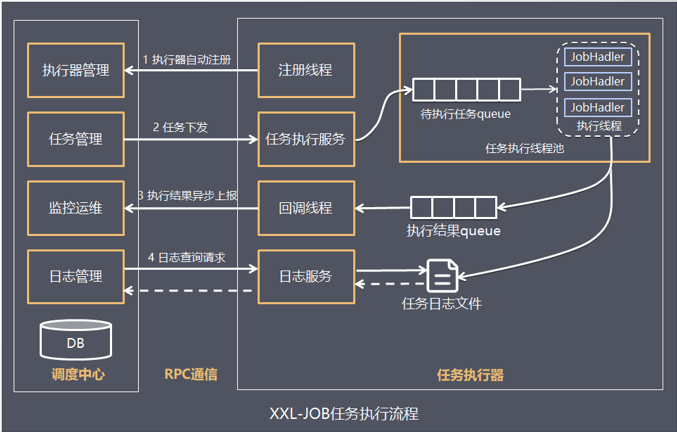
任务配置属性说明
1、路由策略:当执行器集群部署时,提供丰富的路由策略,包括:
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
2、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略:
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
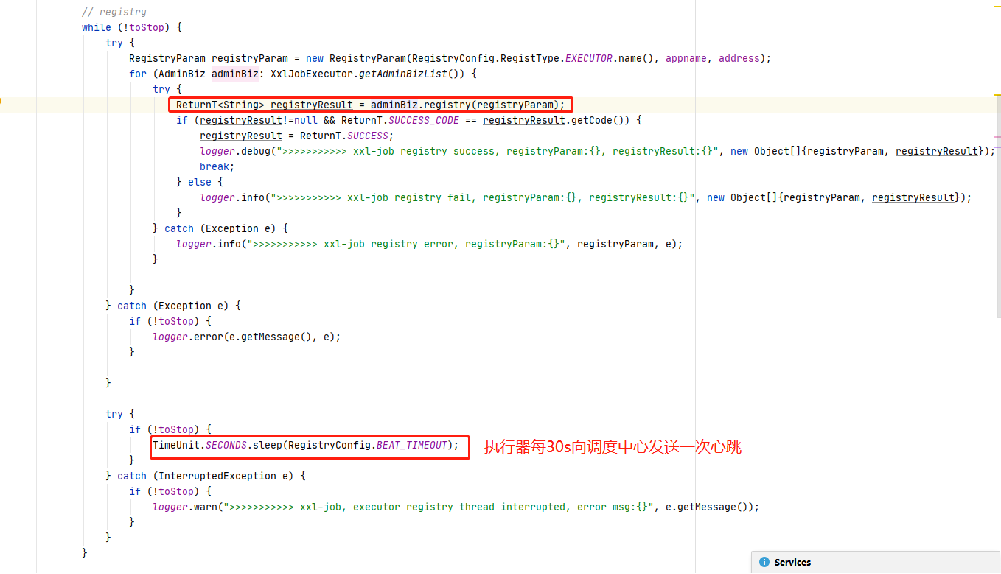
执行器心跳检测原理
执行器流程:执行器实例每30s向调度中心发送一次心跳
调度中心流程:每30s检测一次执行器状态,将最近90s没有发送心跳执行器实例从执行器列表中删除,并更新执行器列表对应的地址
执行器相关代码:
调度中心代码 :

心跳检测流程

调度任务流程
调度中心启动后,会启动两个线程
scheduleThread:扫描出任务下次执行时间小于(当前时间+5s)的任务
ringThread:就是不断从容器中读取当前时间点需要执行的任务,读取出来的任务会交给一个快慢线程池去将任务传递给调度器去执行。
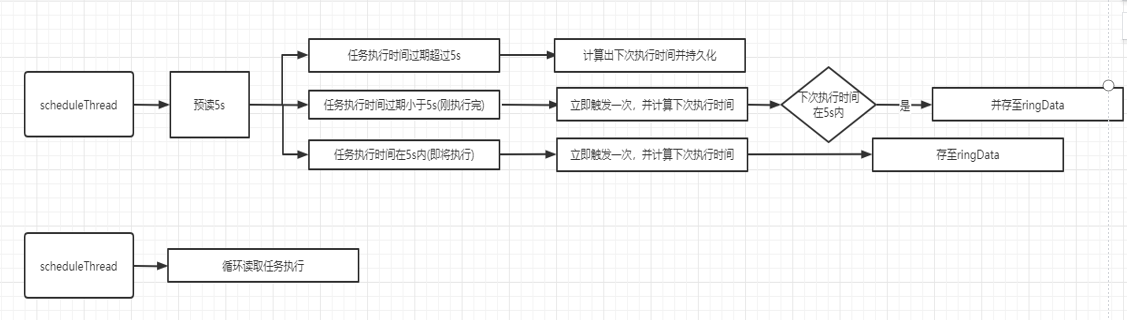
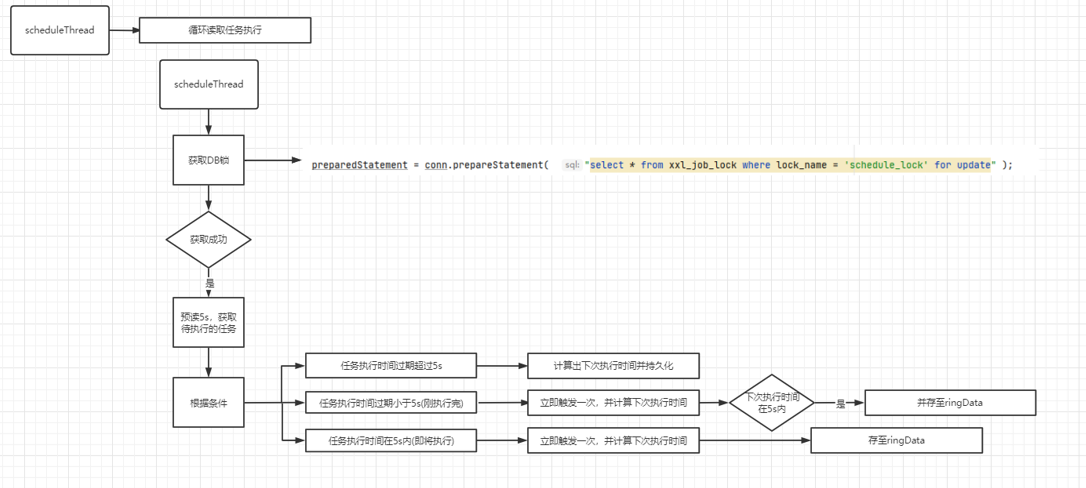
ringData流程
时间轮出自Netty中的HashedWheelTimer,是一个环形结构,可以用时钟来类比,钟面上有很多bucket,每一个bucket上可以存放多个任务,使用一个List保存该时刻到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应bucket上所有到期的任务。任务通过取模决定应该放入哪个bucket。和HashMap的原理类似,newTask对应put,使用List来解决 Hash 冲突。


以上图为例,假设一个bucket是1秒,则指针转动一轮表示的时间段为8s,假设当前指针指向 0,此时需要调度一个3s后执行的任务,显然应该加入到(0+3=3)的方格中,指针再走3s次就可以执行了;如果任务要在10s后执行,应该等指针走完一轮零2格再执行,因此应放入2,同时将round(1)保存到任务中。检查到期任务时只执行round为0的,bucket上其他任务的round减1。
执行器工作原理

任务总体执行流程
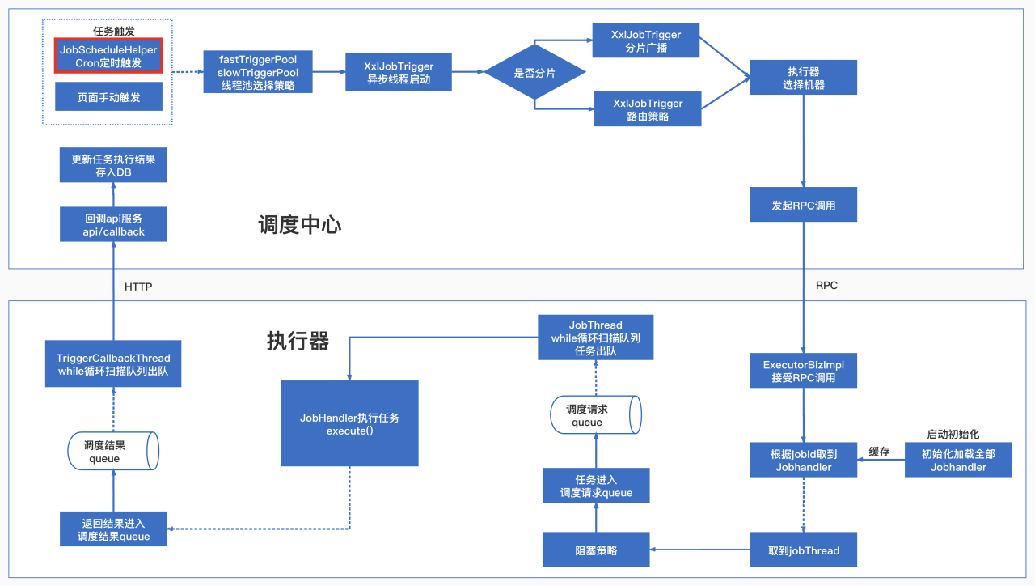
调度中心核心线程
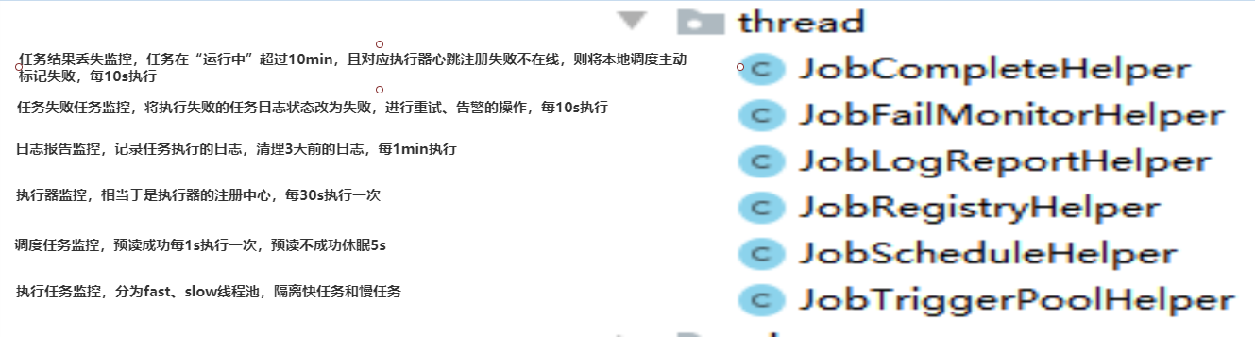
执行器核心线程
调度中心集群
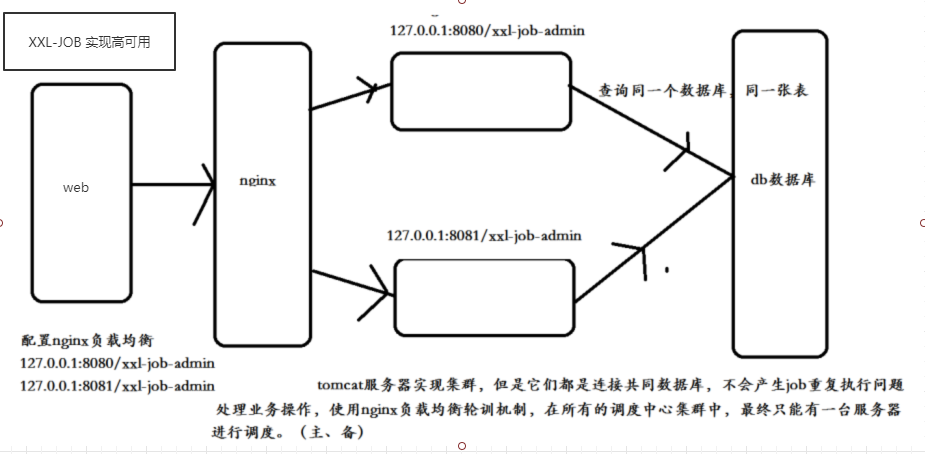
调度中心集群部署时,几点要求和建议:
DB配置保持一致;
集群机器时钟保持一致(单机集群忽视);
建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行。
注意事项
1.时钟同步问题
调度中心和任务执行器需要时间同步,同步时间误差需要在3分钟内,否则抛出异常。
参考:com.xxl.rpc.remoting.provider.XxlRpcProviderFactory#invokeService
if (System.currentTimeMillis() - xxlRpcRequest.getCreateMillisTime() > 3601000) {
xxlRpcResponse.setErrorMsg("The timestamp difference between admin and executor exceeds the limit.");
return xxlRpcResponse;
}
2.时区问题
任务由调度中心触发,按照在调度中心设置任务的cron表达式触发时,需要注意部署调度中心的机器所在的时区,按照该时区定制化cron表达式。
3 .任务执行中服务宕掉问题
调度中心完成任务下发,执行器在执行任务的过程中,如果执行器突然服务宕掉,会导致任务的执行问题在调度中心是执行中,调度中心并不会发起失败重试。即使任务设置了超时时间,执行器宕掉导致任务长时间未执行完成,调度中心界面也不会看到任务超时,因为任务超时是由执行器检测的并上报给调度中心的。
4 .优雅停机问题
执行器执行任务基于线程池异步执行,当需要重启时需要注意线程池中还有未执行完成任务的问题,需要优雅停机,可以直接基于XxlJobExecutor.destroy()优雅停机,注意该方法在v2.0.2之前的版本存在bug导致无法优雅停机,v2.0.2及之后的版本才修复。
- 失败重试问题
当执行器节点部分服务不可用,例如节点磁盘损坏,但在调度中心仍然处于在线时,调度中心仍可能基于路由策略(包括故障转移策略)路由到该未下线的节点,并不断重试,不断失败,导致重试次数耗尽。所以路由策略尽量不要采用固定化策略,例如固定第一个、固定最后一个。
版权归原作者 code.song 所有, 如有侵权,请联系我们删除。