
前言
对kafka有一定了解的同学应该知道,kafka发送到topic的数据是分区存储的,而后,对于消费者来说,只需要指定kafka服务的IP、端口号,以及指定具体的topic名称即可,而不需要具体关系消费哪个分区的数据;
但在kafka内部,这个过程还是挺复杂的,我们知道,在编写kafka消费端逻辑代码时,需要在代码中配置 "group"参数,即消费端消费某个topic的数据时,需要指定具体的消费组名称,否则,程序根本无法跑起来;
下图展示了kafka从producer发送消息,到consumer消费消息时,消息进行流动的一个大致的示意图*(这里忽略了内部其他的逻辑);

本文由于是探讨消费组分区消费再均衡的问题,仅从消费端出发,针对某个消费者组内的多个消费者消费topic的数据,结合上图做一个简单的说明;
假设kafka集群服务已经开启并且生产者已经推送了一定数据的消息到具体的topic的情况下,这时候启动消费端,接下来做的事情大概如下:
- 每个consumer都发送JoinGroup请求(每个分区所在的broker都存在一个叫做coordinator的协调器);
- coordinator从消费组中选出一个consumer作为leader;
- coordinator把要消费的topic情况发送给leader 消费者;
- leader消费者会负责制定消费方案并把方案上报coordinator;
- Coordinator就把第四步的消费方案下发各个consumer;
- 每个消费者都会和coordinator保持心跳(默认3s),一旦超时 (session.timeout.ms=45s),该消费者会被移除,并触发再平衡,或者消费者处理消息的过长(max.poll.interval.ms5分钟),也会触发再平衡;
问题引出
了解了上面的消费端消费的大致原理后,于是我们提出这样一个问题
一个consumer group中由多个consumer组成,一个 topic包含多个partition,那么对于一个消费者组内的多个consumer来说,到底由哪个consumer来消费哪个partition的数据
Kafka主流分区分配策略
1、Range 范围分区(默认的)
假如有10个分区,3个消费者,把分区按照序号排列0,1,2,3,4,5,6,7,8,9;消费者为C1,C2,C3,那么用分区数除以消费者数来决定每个Consumer消费几个Partition,除不尽的前面几个消费者将会多消费一个
最后分配结果如下:
C1:0,1,2,3
C2:4,5,6
C3:7,8,9
2、RoundRobin 轮询分区
把所有的partition和consumer列出来,然后轮询consumer和partition,尽可能的让把partition均匀的分配给consumer;
3、Sticky粘性分区
即在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销
可以通过配置参数partition.assignment.strategy,修改分区的分配策略。默认策略是Range + CooperativeSticky。Kafka可以同时配置多个分区分配策略
分区消费再平衡问题
为什么要探讨这个问题呢?我们知道,在实际生产环境中,为了提升服务的高可用性,kafka服务通常是集群部署的,这个小编曾经所在的项目也是如此;
由于kafka的性能极高,在高并发的场景下,经常会碰到这么一种情况,要么生产端生产消息的速度过快,导致消费者的消费能力跟不上;要么消费端的消费速度过快,生产者生产数据能力跟不上;
遇到上面的问题时,自然会采取不同的策略,具体来说,通常在架构设计之初,会对生产端和消费端各自的能力做数据上的评估,基本的架构是,kafka集群部署,生产端通常至少2个服务,如果消费速度跟不上,考虑再增加消费端服务实例;
基于上面的情况,我们脑海里基本上能够呈现出这样一副完整的架构图了,和本文开篇的差不多;
现在考虑下面的问题:
如果某个消费者组内的多个消费者,突然挂掉一个怎么办呢?
从文章开篇我们了解到,一旦当消费者组中的各个消费者按照最初的消费方案计划执行后,后续将会持续按照这个计划消费特定分区的数据,但是这时候,如果消费者组中的某个消费者断掉了,这时候面临的直接问题就是:
少了一个消费者,这个消费者之前消费的一个或者多个分区的数据由于没有消费者消费而遇到阻碍?对于kafka的broker来说,这时候就会进行分区分配及再平衡,即空出来的分区的数据将会按照一定的策略分配给消费组中的其他消费者消费;
这个过程即为消费组分区消费再平衡问题;
根据一开始消费端消费逻辑中配置的分区分配策略的不同,这个再平衡时的结果也不同,下面针对几种不同的分区分配策略做具体的一一说明;
前置准备
1、搭建kafka3节点的集群并启动服务;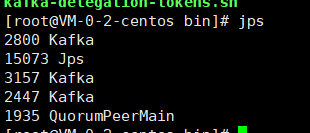
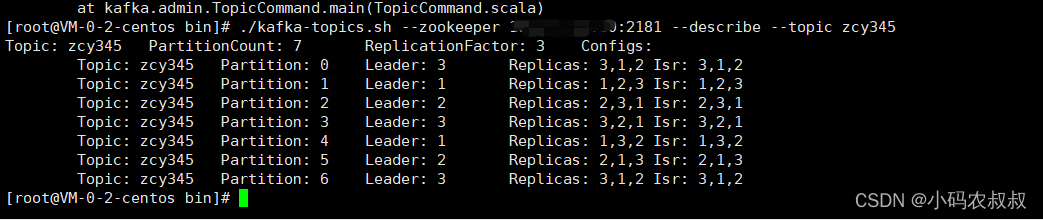
2、创建一个7个分区,3个副本的topic;
./kafka-topics.sh --zookeeper IP:2181 --create --topic zcy345 --partitions 7 --replication-factor 3

分区分配策略之Range再平衡
Range 是对每个 topic 而言的。
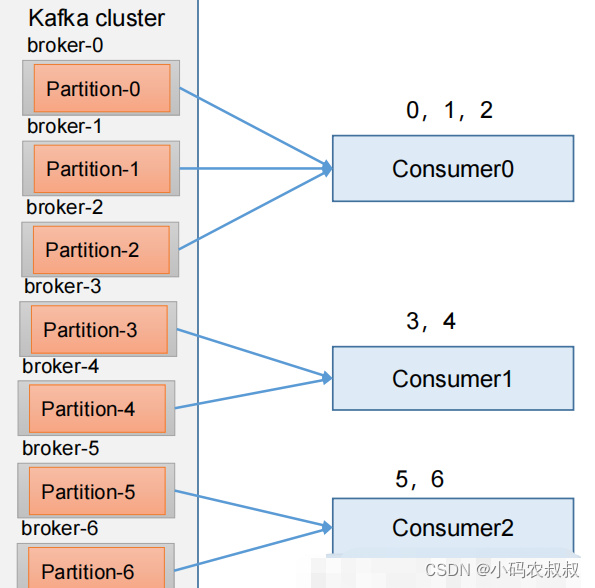
首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序;
假如现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2;
例如,7/3 = 2 余 1 ,除不尽,那么 消费者 C0 便会多消费 1 个分区。 8/3=2余2,除不尽,那么C0和C1分别多消费一个。
通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费 1 个分区。
注意:如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有 N 多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消 费的分区会比其他消费者明显多消费 N 个分区。
容易产生数据倾斜
代码演示
1、生产端代码
import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;publicclassProducerRange{publicstaticvoidmain(String[] args)throws Exception {// 1. 创建 kafka 生产者的配置对象
Properties properties =newProperties();// 2. 给 kafka 配置对象添加配置信息:bootstrap.servers
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"IP:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");// 3. 创建 kafka 生产者对象
KafkaProducer<String, String> kafkaProducer =newKafkaProducer<String, String>(properties);
System.out.println("开始发送数据");// 4. 调用 send 方法,发送消息for(int i =0; i <10; i++){
kafkaProducer.send(newProducerRecord<>("zcy345","congge "+ i));}// 5. 关闭资源
kafkaProducer.close();}}
2、消费端代码
import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;import java.util.ArrayList;import java.util.Properties;publicclassRangeConsumer1{publicstaticvoidmain(String[] args)throws Exception {
Properties properties =newProperties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"IP:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");// 配置消费者组(组名任意起名) 必须
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test-group");// 创建消费者对象
KafkaConsumer<String, String> kafkaConsumer =newKafkaConsumer<>(properties);// 注册要消费的主题(可以消费多个主题)
ArrayList<String> topics =newArrayList<>();
topics.add("zcy345");
kafkaConsumer.subscribe(topics);
System.out.println("消费者1准备接收数据......");// 拉取数据打印while(true){// 设置 1s 中消费一批数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));// 打印消费到的数据for(ConsumerRecord<String, String> consumerRecord : consumerRecords){
System.out.println(consumerRecord);}}}}
将上面的消费者代码复制出3份,然后先分别启动消费者,再启动生产者代码,观察控制台输出结果,观看 3 个消费者分别消费哪些分区的数据
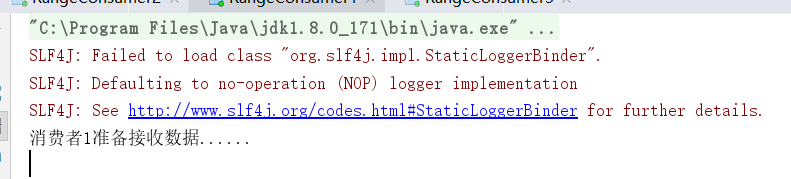
运行生产端代码之后,效果如下,从当前的情况来看,
consumer1:消费 0 ,1 ,2 的分区数据;
consumer2: 消费3,4的分区数据;
consumer3: 消费5,6的分区数据;



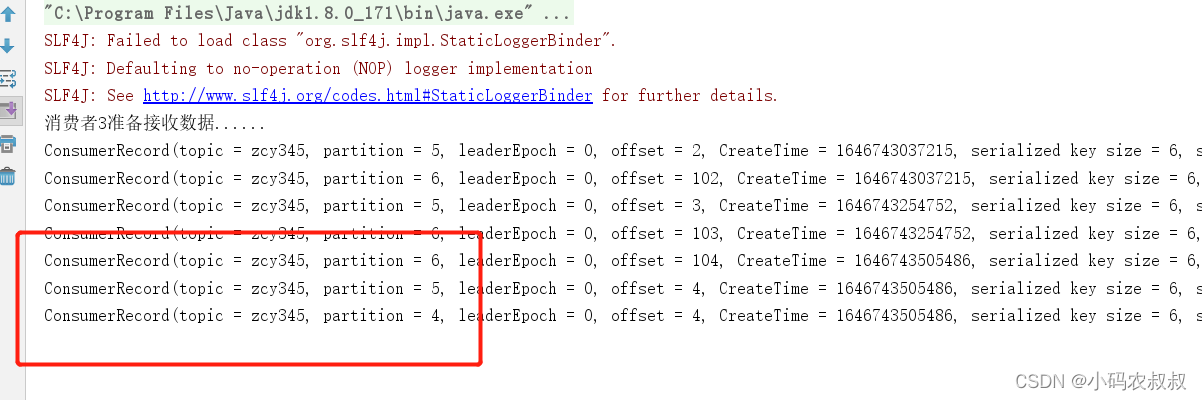
这时候,停止 1号消费者,快速重新发送消息观看结果(45s 以内,越快越好)
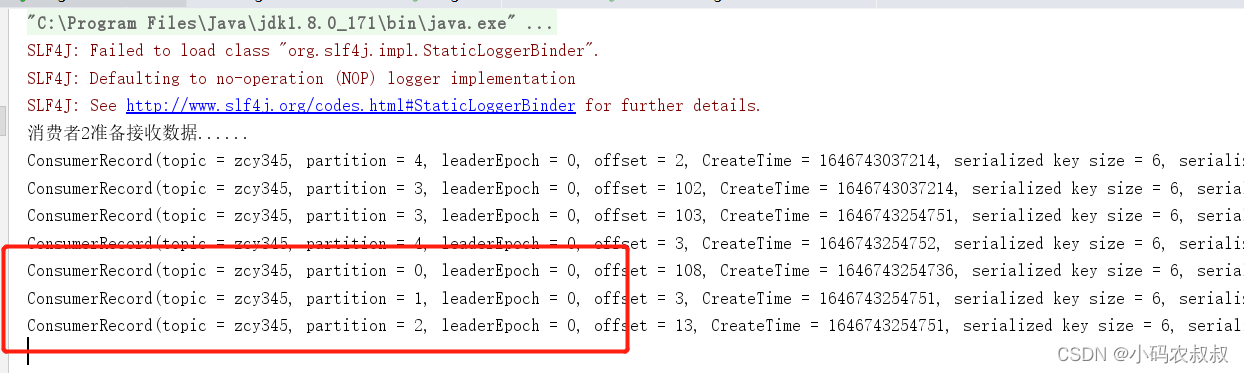
这时候,等了一段世间后发现,消费者1原本消费的0,1,2 的分区的数据整体被分配到 2 号消费者身上去了
说明:1 号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行
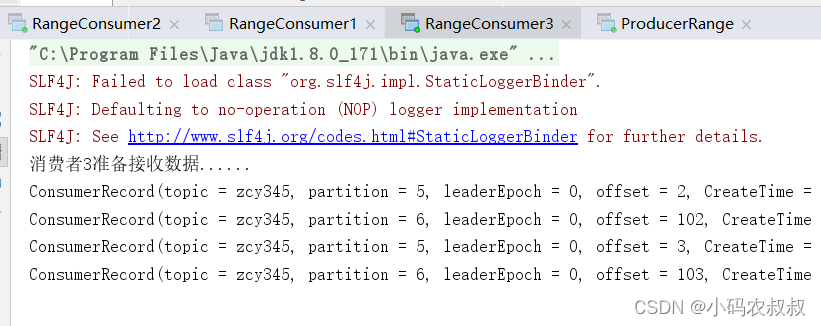
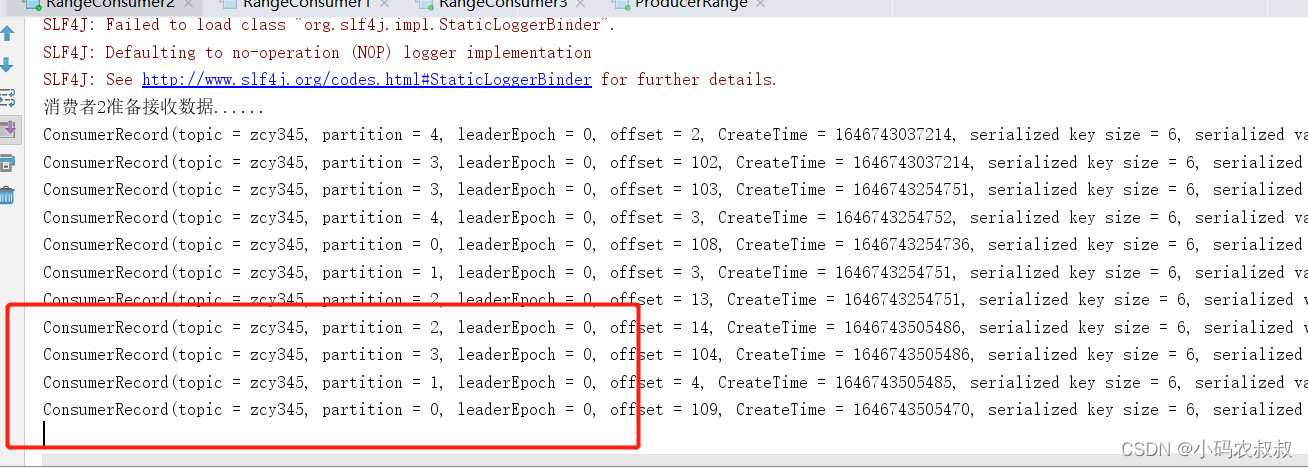
再次重新发送消息观看结果(45s 以后):
2号消费者:消费到 0、1、2、3 号分区数据。 3 号消费者:消费到 4、5、6 号分区数据
分区分配策略之RoundRobin再平衡
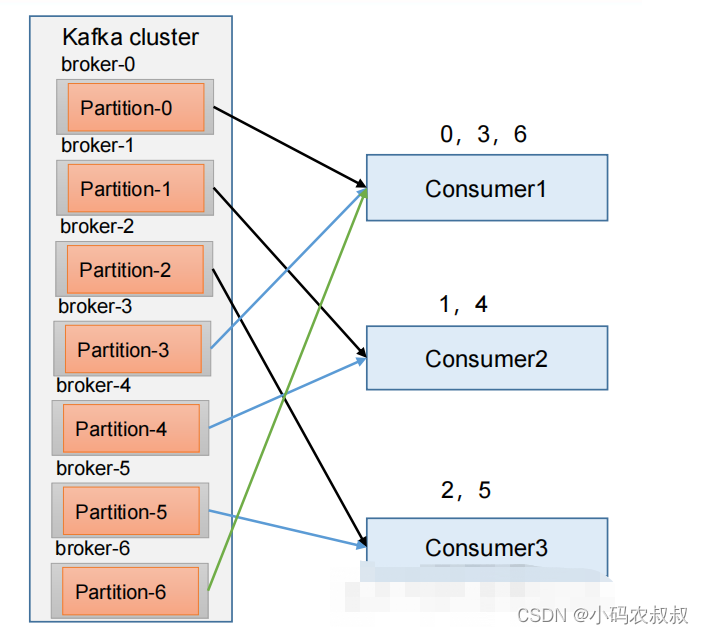
RoundRobin 针对集群中所有Topic而言
RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者
过程展示
只需要修改下消费端代码的配置即可,如下:
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
重启 3 个消费者,重复发送消息的步骤,观看分区结果如下:
consumer1 : 消费分区 2和5的数据;
consumer2 : 消费分区 1和4的数据;
consumer3 : 消费分区 0、3、6的数据;
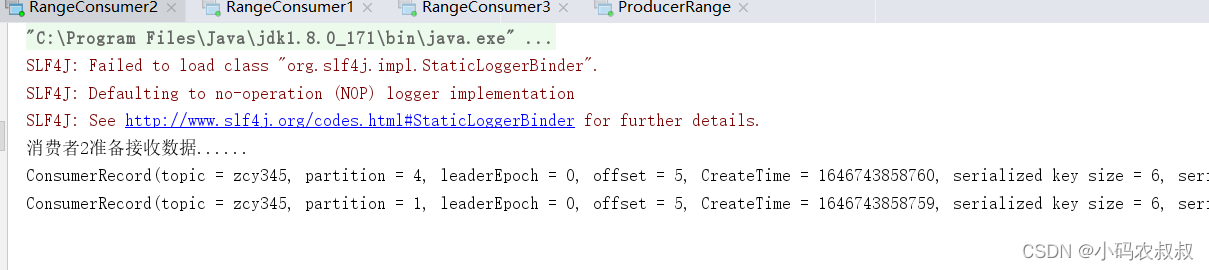
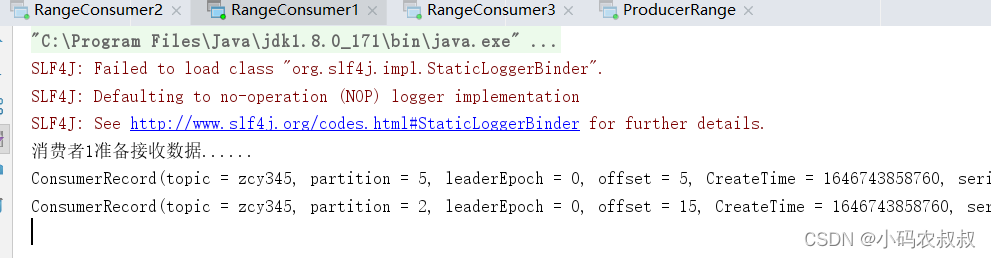
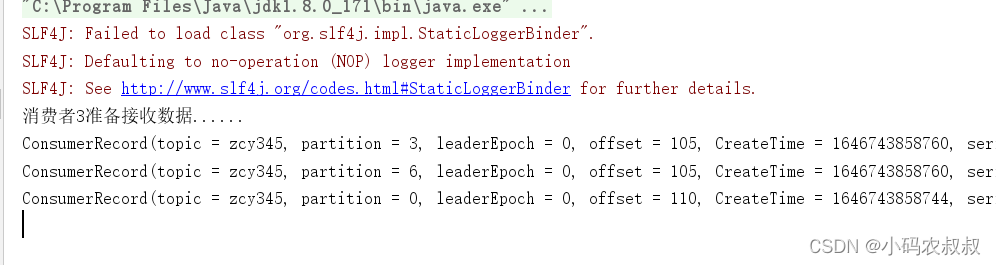
停止掉 1号消费者,快速重新发送消息观看结果(45s 以内,越快越好):
- 2号消费者消费1,4,5分区数据;
- 3号消费者消费0,2,6分区数据;
1号消费者的任务会按照 RoundRobin 的方式,把数据轮询分成 0 、6 和 3 号分区数据,
分别由 1 号消费者或者 2 号消费者消费。
说明:1号消费者挂掉后,消费者组需按超时时间 45s 来判断它是否退出,所以需
要等待,时间到了 45s 后,判断它真的退出就会把任务分配给其他 broker 执行

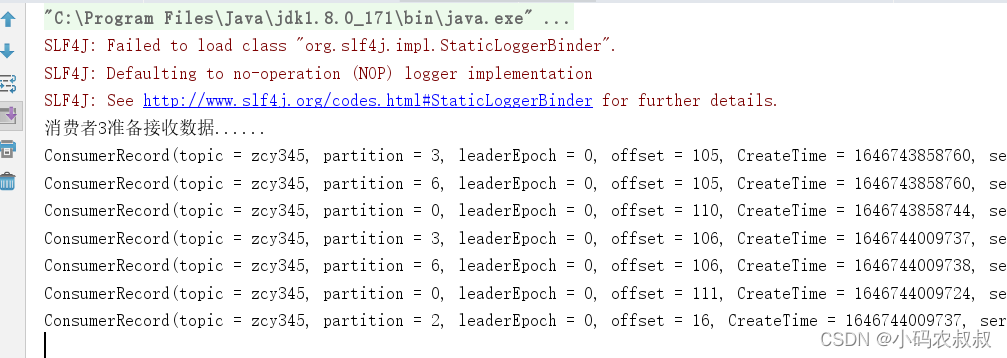
再次重新发送消息观看结果(45s 以后):
- 2 号消费者:消费到 0、2、4、6 号分区数据
- 23号消费者:消费到 1、3、5 号分区数据
说明:消费者 0 已经被踢出消费者组,所以重新按照 RoundRobin 方式分配
分区分配策略之Sticky再平衡
粘性分区:即分配的结果带有“粘性”。即在执行一次新的分配之前,会考虑上一次分配的结果,尽量少的调整分配变动,节省系统资源开销;
粘性分区是 Kafka 从 0.11.x 版本开始引入的,首先会尽量均衡的放置分区到消费者上面,在出现同一消费者组内消费者出现问题的时候,会尽量保持原有分配的分区不变化。
实验需求
7 个分区;准备 3 个消费者的主题,采用粘性分区策略,并进行消费,观察消费分配情况。然后再停止其中一个消费者,再次观察消费分配情况
仍然使用上面的消费者,需要修改下分区策略代码,如下:
ArrayList<String> startegys =newArrayList<>();
startegys.add("org.apache.kafka.clients.consumer.StickyAssignor");
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, startegys);
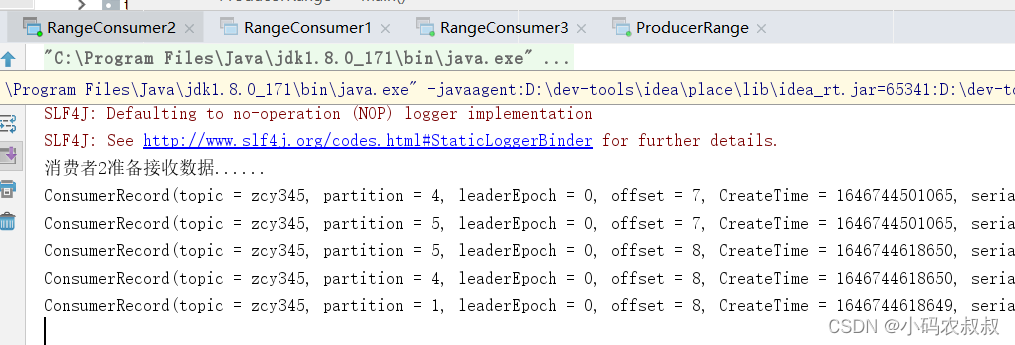
启动3个消费者,然后发送消息,可以看到会尽量保持分区的个数近似划分分区,目前的效果是:
- 消费者1,消费0,1,2分区数据
- 消费者2,消费4,5分区数据
- 消费者3,消费3,6分区数据
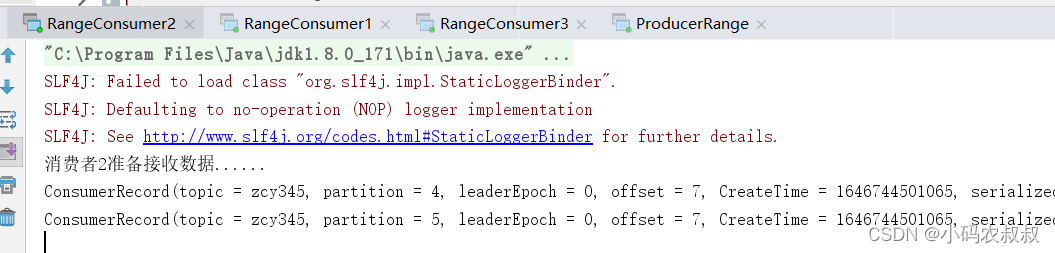
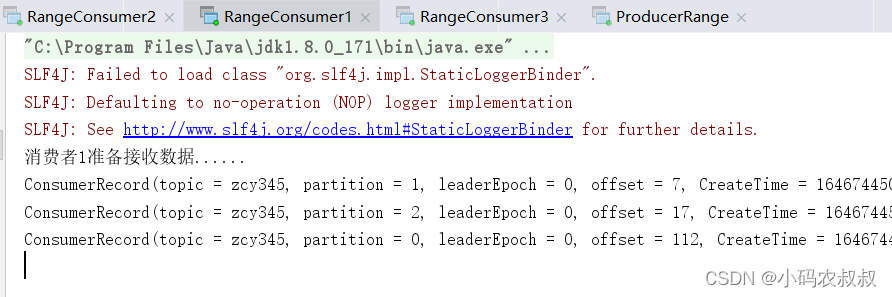
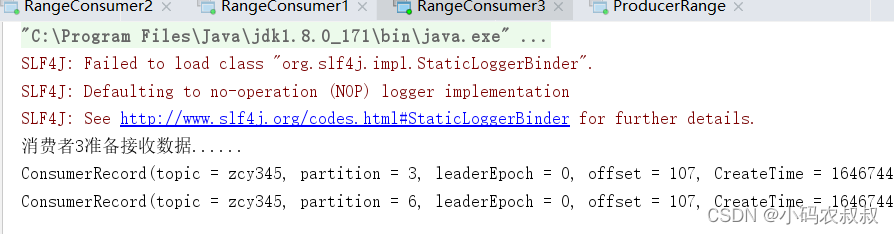
停止掉 1 号消费者,快速重新发送消息观看结果(45s 以内,越快越好)
- 消费者2,消费1,4,5分区数据
- 消费者3,消费0,2,3,6分区数据
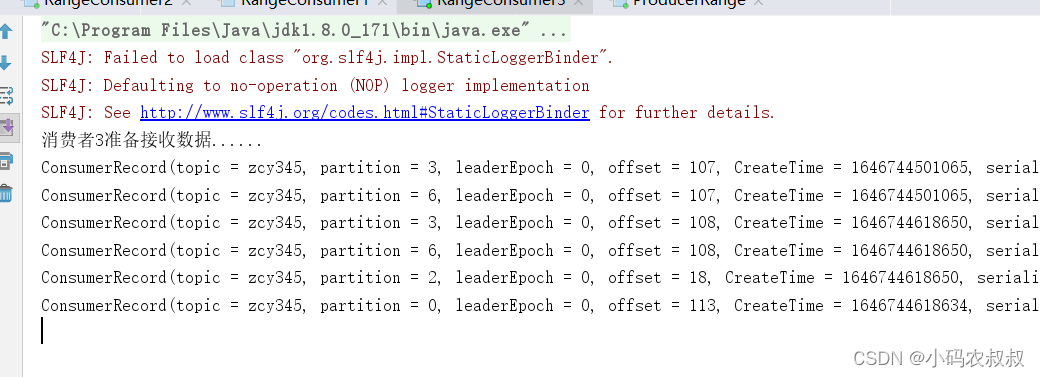
0 号消费者的任务会按照粘性规则,尽可能均衡的随机分成 0 和 1 号分区数据,分别
由 1 号消费者或者 2 号消费者消费
说明:1号消费者挂掉后,消费者组需要按照超时时间 45s 来判断它是否退出,所以需
要等待,时间到 45s 后,判断它真的退出,就会把任务分配给其他 broker 执行
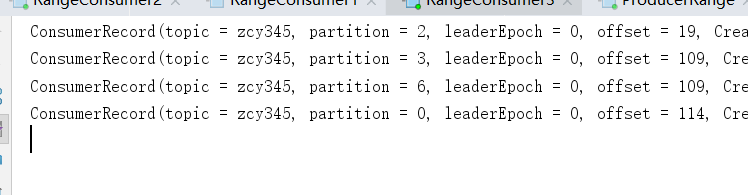
再次重新发送消息观看结果(45s 以后):
- 消费者2,消费1,4,5 分区数据
- 消费者3,消费0,2,3,6 分区数据

版权归原作者 小码农叔叔 所有, 如有侵权,请联系我们删除。