
目录
PySpark实战笔记系列第五篇
- 10-用PySpark建立第一个Spark RDD(PySpark实战笔记系列第一篇)
- 11-pyspark的RDD的变换与动作算子总结(PySpark实战笔记系列第二篇))
- 12-pyspark的RDD算子注意事项总结(PySpark实战笔记系列第三篇)
- 13-pyspark的共享变量用法总结(PySpark实战笔记系列第四篇)
- 14-pyspark的DataFrame使用总结(PySpark实战笔记系列第五篇)
前言
在Spark中,除了RDD这种数据容器外,另一种一种更容易操作的一个分布式数据容器DataFrame,它更像传统关系型数据库的二维表,除了包括数据自身以外,还包括数据的结构信息(Schema),可以利用类似SQL的语言来进行数据访问。
DataFrame可以从多种数据来源上进行构建,比如结构化数据文件、Hive中的表、外部数据库或现有RDD。
DataFrame使用总结
DataFrame的构建
方法1:通过列表构建
列表的元素是元组,这个数据结构可以代表一种二维数据。然后利用spark.createDataFrame()方法来构建,示例如下:
import findspark
findspark.init()#############################################from pyspark.sql
import SparkSession
spark = SparkSession.builder \
.master("local[2]") \
.appName("DataFrameDemo") \
.getOrCreate();############################################
a =[('Jack',32),('Smith',33)]
df = spark.createDataFrame(a)#[Row(_1='Jack', _2=32), Row(_1='Smith', _2=33)]print(df.collect())
df.show()15# +-----+---+ # | _1| _2|# +-----+---+# | Jack| 32|# |Smith| 33|# +-----+---+# 指定列名
df2 = spark.createDataFrame(a,['name','age'])#[Row(name='Jack', age=32), Row(name='Smith', age=33)]print(df2.collect())
df2.show()# +-----+---+# | name|age|# +-----+---+# | Jack| 32|# |Smith| 33|3# +-----+---+
方法2:通过Row对象构建
到DataFrame对象是由Row这个数据结构构成的,因此也可以用Row,然后利用**spark.createDataFrame() 方法 **来创建DataFrame对象。示例如下:
# 通用的开头# ......#################################################from pyspark.sql import Row
a =[('Jk',32),('Sm',33)]
rdd = sc.parallelize(a)# 创建包含列名的Row
RMes= Row('name','age')# rdd对象的元素进行映射,转换成一个RMes对象,并返回一个新RDD对象
rmes = rdd.map(lambda r: RMes(*r))
df = spark.createDataFrame(rmes)# [Row(name='Jk', age=32), Row(name='Sm', age=33)]print(df.collect())
df.show()# +-----+---+# | name|age|# +-----+---+# | Jk | 32|# |Sm | 33|# +-----+---+
方法3:通过表Schema构建
上述两个方法都没能给定每个字段的类型,比如列名name是字符串类型,而列名age是数值类型。而通过用StructType方法创建了一个表Schema则可以实现,类似定义数据库中的表结构。再利用spark.createDataFrame()方法来创建DataFrame对象。示例如下:
# 通用的开头# ......#################################################from pyspark.sql.types import*
a =[('Jk',32),('Sm',33)]
rdd = sc.parallelize(a)# 用StructType方法创建了一个表Schema
schema = StructType([
StructField("name", StringType(),True),
StructField("age", IntegerType(),True)])# 创建DataFrame
df = spark.createDataFrame(rdd, schema)# Row(name='Jk', age=32), Row(name='Sm', age=33)]print(df.collect())
df.show()# +-----+---+# | name|age|# +-----+---+# | Jk | 32|# |Sm | 33|# +-----+---+
df.printSchema()# root# |-- name: string (nullable = true)# |-- age: integer (nullable = true)
方法4:rdd结合字符串构建
借助StructType方法可以创建类型化的DataFrame对象,但是操作起来有点繁琐。下面示例一个简单一点的方法,同样可以创建具备字段类型的DataFrame对象。
# 通用的开头# ......#################################################
a =[('Jk',32),('Sm',33)]
rdd = sc.parallelize(a)# 创建DataFrame:使用一个字符串对表结构中的字段类型进行定义
df = spark.createDataFrame(rdd,"name:string, age:int")# Row(name='Jk', age=32), Row(name='Sm', age=33)]print(df.collect())
df.show()# +-----+---+# | name|age|# +-----+---+# | Jk | 32|# |Sm | 33|# +-----+---+
df.printSchema()# root# |-- name: string (nullable = true)# |-- age: integer (nullable = true)
DataFrame的方法
方法名使用形式参数说明作用示例showdf.show()用表格的方式对数据进行打印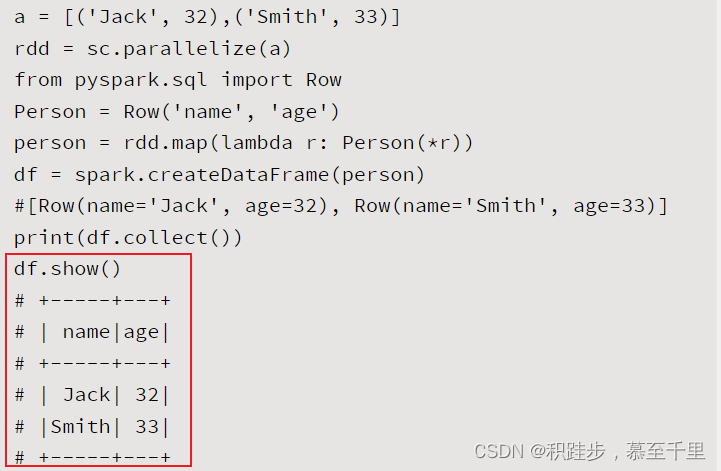 printSchemadf.printSchema()打印df对象的Schema结构定义
printSchemadf.printSchema()打印df对象的Schema结构定义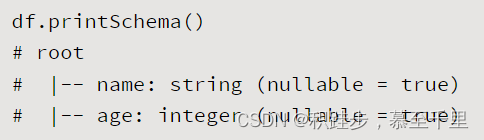 createOrReplaceTempViewdf.createOrReplaceTempView(viewName)viewName:string,指定创建的表名将DataFrame映射为一个数据库表
createOrReplaceTempViewdf.createOrReplaceTempView(viewName)viewName:string,指定创建的表名将DataFrame映射为一个数据库表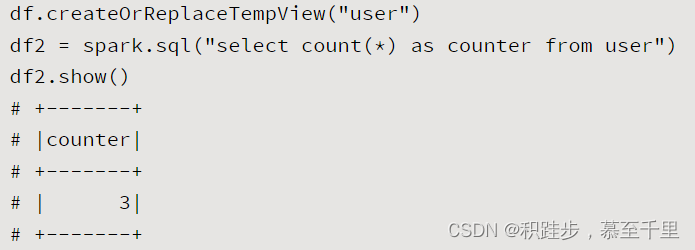 selectdf.select(colNames)colNames:string,需要读取的列名称读取指定列的信息
selectdf.select(colNames)colNames:string,需要读取的列名称读取指定列的信息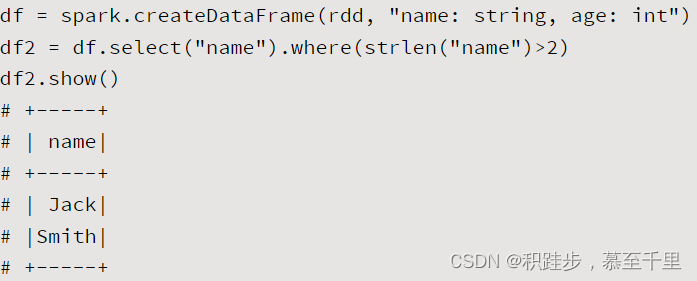 selectExprdf.selectExpr(*colMes)对列进行计算
selectExprdf.selectExpr(*colMes)对列进行计算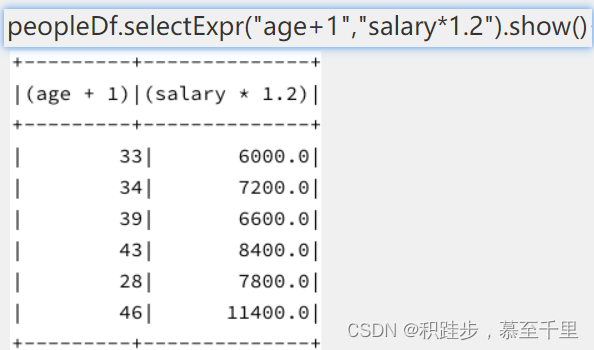 aggdf.agg(dictMes)dictMes:dict,其中key为列名,value为聚合的函数名对DataFrame的指定列按照指定的方式进行聚合
aggdf.agg(dictMes)dictMes:dict,其中key为列名,value为聚合的函数名对DataFrame的指定列按照指定的方式进行聚合 describe*df.describe(listMes)listMes:默认None,描述统计的列名称对指定字段进行描述统计
describe*df.describe(listMes)listMes:默认None,描述统计的列名称对指定字段进行描述统计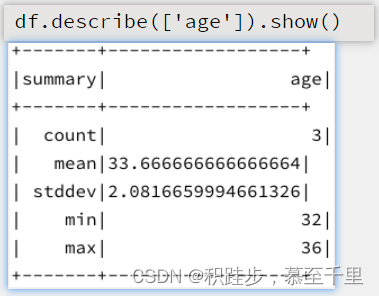 summarydf.summary()*给出DataFrame对象的概览统计结果
summarydf.summary()*给出DataFrame对象的概览统计结果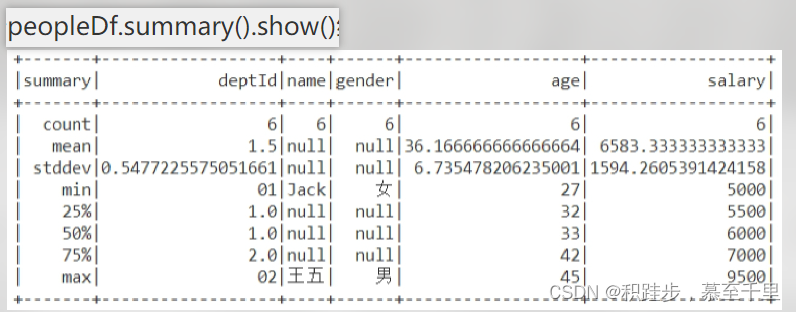 filterdf.filter(filterCondtion)filterCondtion:指定的过滤条件逻辑关系式对数据进行过滤
filterdf.filter(filterCondtion)filterCondtion:指定的过滤条件逻辑关系式对数据进行过滤 joindf.join(otherDF,join_key,how=“inner”)第三个参数默认为inner,其他选项为:inner,cross,outer,full,full_outer,left,left_outer,right,right_outer,left_semi,left_anti多个DataFrame进行关联
joindf.join(otherDF,join_key,how=“inner”)第三个参数默认为inner,其他选项为:inner,cross,outer,full,full_outer,left,left_outer,right,right_outer,left_semi,left_anti多个DataFrame进行关联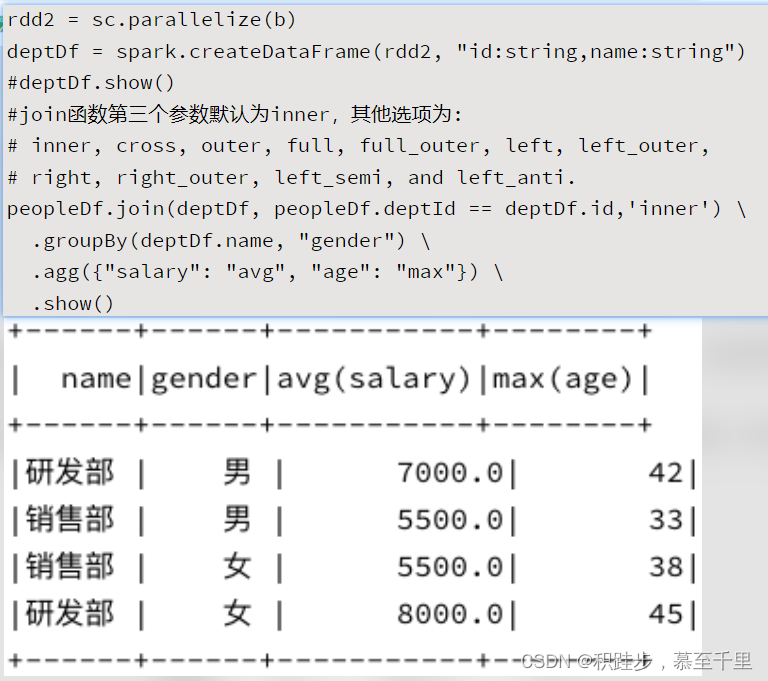 distinctdf.distinct()对DataFrame对象中的数据进行去重操作
distinctdf.distinct()对DataFrame对象中的数据进行去重操作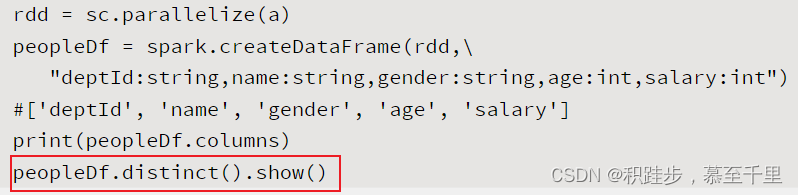 dropdf.drop(*col_names)col_names:需要删除的列名称删除某些不需要的数据列信息(**从列上移除*)
dropdf.drop(*col_names)col_names:需要删除的列名称删除某些不需要的数据列信息(**从列上移除*) exceptAlldf.exceptAll(otherDF)从一个DataFrame的数据中移除掉另外一个DataFrame中的数据(*从行上移除**)
exceptAlldf.exceptAll(otherDF)从一个DataFrame的数据中移除掉另外一个DataFrame中的数据(*从行上移除**) intersectAlldf.intersectAll(otherDF)求两个DataFrame的交集df1.intersectAll(df2).sort(“C1”,“C2”).show()na.filldf.na.fill(dictMes)dictMes:dict,指定列空值的替换方式对空值进行替换操作
intersectAlldf.intersectAll(otherDF)求两个DataFrame的交集df1.intersectAll(df2).sort(“C1”,“C2”).show()na.filldf.na.fill(dictMes)dictMes:dict,指定列空值的替换方式对空值进行替换操作 toJSONdf.toJSON()将DataFrame转成JSON格式
toJSONdf.toJSON()将DataFrame转成JSON格式 withColumndf.withColumn(colName,df)增加计算列
withColumndf.withColumn(colName,df)增加计算列 withColumnRenameddf.withColumnRenamed(old,new)修改列名同上write.csvdf.write.csv(csvfilepath,mode)df.write.csv函数给定的参数是数据存储的路径,而不是文件名。将DataFrame数据以csv格式进行存储
withColumnRenameddf.withColumnRenamed(old,new)修改列名同上write.csvdf.write.csv(csvfilepath,mode)df.write.csv函数给定的参数是数据存储的路径,而不是文件名。将DataFrame数据以csv格式进行存储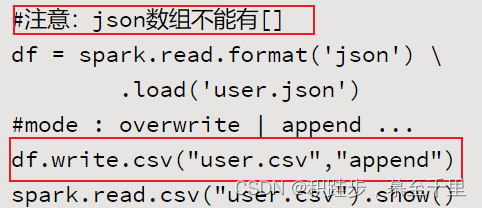
参考文档:
- https://spark.apache.org/docs/latest/api/python/reference/pyspark.html
- 《Python大数据处理库PySpark实战》
博主写博文就是方便对自己所学所做的事做一备份记录或回顾总结。欢迎留言,沟通学习。
刚开始接触,请多指教,欢迎留言交流!
本文转载自: https://blog.csdn.net/weixin_42521211/article/details/137651067
版权归原作者 积跬步,慕至千里 所有, 如有侵权,请联系我们删除。
版权归原作者 积跬步,慕至千里 所有, 如有侵权,请联系我们删除。