
在传统的机器学习中,为了获得最先进的(SOTA)性能,我们经常训练一系列整合模型来克服单个模型的弱点。但是,要获得SOTA性能,通常需要使用具有数百万个参数的大型模型进行大量计算。SOTA模型(例如VGG16 / 19,ResNet50)分别具有138+百万和23+百万个参数。在边缘设备部署这些模型是不可行的。
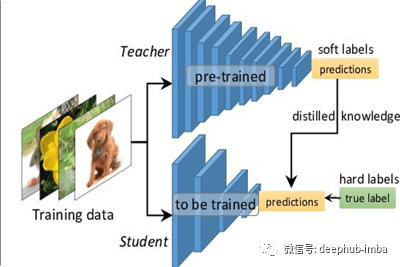
智能手机和IoT传感器等边缘设备是资源受限的设备,无法在不影响设备性能的情况下进行训练或实时推断。因此,研究集中在将大型模型压缩为小型紧凑的模型,将其部署在边缘设备时性能损失最小至零。
以下是一些可用的模型压缩技术,尽管它不限于以下内容:
- 修剪和量化
- 低阶分解
- 神经网络架构搜索(NAS)
- 知识蒸馏
在这篇文章中,重点将放在[1]提出的知识蒸馏上,参考链接[2]提供了上面列出的模型压缩技术列表的详尽概述。
知识蒸馏
知识蒸馏是利用从一个大型模型或模型集合中提取的知识来训练一个紧凑的神经网络。利用这些知识,我们可以在不严重影响紧凑模型性能的情况下,有效地训练小型紧凑模型。
大、小模型
我们称大模型或模型集合为繁琐模型或教师网络,而称小而紧凑的模型为学生网络。
一个简单的类比是,一个大脑小巧紧凑的学生为了考试而学习,他试图从老师那里吸收尽可能多的信息。然而老师只是教所有的东西,学生不知道在考试中会出哪些问题,尽力吸收所有的东西。
在这里,压缩是通过将知识从教师中提取到学生中而进行的。
在提取知识之前,繁琐的模型或教师网络应达到SOTA性能,此模型由于其存储数据的能力而通常过拟合。尽管过拟合,但繁琐的模型也应该很好地推广到新数据。繁琐模型的目的是使正确类别的平均对数概率最大化。较可能正确的类别将被分配较高的概率得分,而错误的类别将被赋予较低的概率。
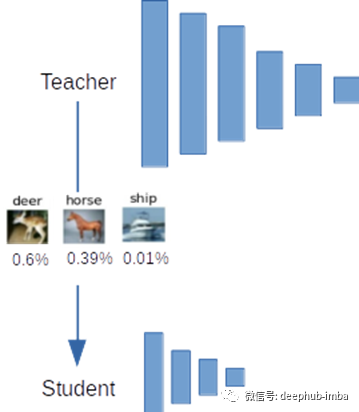
下面的示例显示了在给定的“鹿”图像上进行推理时以及softmax之后的结果。下图。要获得预测,我们采用最大类概率评分的argmax,这将使我们有60%的机会是正确的。

然而,鉴于上面的图。(为了说明的目的),我们知道与“船”相比,“马”与“鹿”非常相似。因此,在推断过程中,我们有60%是正确的,39%是错误的。由于“鹿”与“马”之间存在一定的空间相似性,因此网络预测“马”的准确性是不容置疑的。如果在网络中提供“我认为这幅图60%是鹿,39%是马”的信息,如[deer: 0.6, horse: 0.39, ship: 0.01],那么网络就会提供更多的信息(高熵)。使用类概率作为目标类比仅仅使用原始目标提供了更多的信息。
蒸馏
教师将预测类别概率的知识提取给学生作为“软目标”。这些数据集又称为“转移集”,其目标为教师提供的类别概率,如上图所示。蒸馏过程是通过在softmax函数中引入一个超参数T(温度)来进行的,这样教师模型就可以为学生模型生成一个适当的传递集目标的软目标集合。
软目标擅长帮助模型泛化,并且可以充当正则化函数来防止模型过于自信。
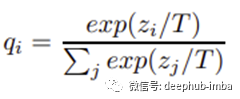
训练教师和学生模型
首先,我们训练繁琐/教师模型,因为我们要求繁琐的模型很好地归纳为新数据。在蒸馏过程中,学生模型目标函数是两个不同目标函数Loss1和Loss2的加权平均值。
loss1 软目标的交叉熵损失
温度T > 1乘以权重参数alpha的教师q和学生p的两个温度softmax的交叉熵损失(CE)。
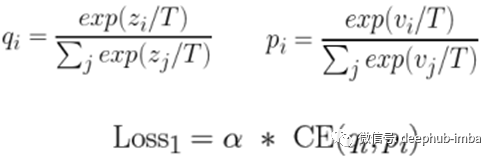
loss2 硬目标的交叉熵损失
正确标签和T = 1的学生硬目标的交叉熵(CE)损失。Loss2很少注意(1- alpha)学生模型为匹配软目标而制定的硬目标(student_pred) q来自教师模型。
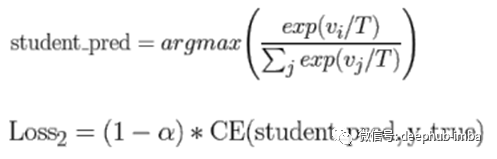
学生模型的目标是蒸馏损失,它是Loss1和Loss2之和。
然后在训练学生模型时,以最大程度地减少其蒸馏损失。
结果
MNIST实验
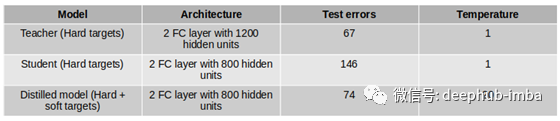
下表1是论文[1]的结果,该论文显示了使用在MNIST数据集上训练了60,000个训练案例的教师、学生和提炼模型的性能。所有模型都是两层神经网络,分别具有1200、800和800个神经元,分别用于教师,学生和提炼模型。当使用精简模型与学生模型进行比较时,温度设置为20时,教师和精简模型之间的测试误差相当。但是,仅使用具有硬目标的学生模型时,其推广性就变的很差。
语音识别实验
下表2是论文[1]的另一个结果。教师模型是由85M参数组成的语音模型,该参数是根据2000个小时的英语口语数据进行训练的,其中包含大约700M的训练示例。表2中的第一行是在100%的训练示例上训练的基线模型,其准确性为58.9%。第二行仅使用3%的训练示例进行训练,这会导致严重的过度拟合。最后,第三行是用3%的训练样本用同样的3%的软目标训练得到的同样的语音模型,只用3%的训练数据就可以达到57%的准确率。

结论
知识蒸馏是一种用于将计算带到边缘设备的模型压缩技术。目标是拥有一个紧凑的小型模型来模仿繁琐模型的性能。这是通过使用软目标来实现的,这些目标充当正则化器,以允许小型紧凑的学生模型泛化并从教师模型中恢复几乎所有信息。
根据Statista[3]的数据,到2025年,联网设备的安装总数预计将达到215亿。随着大量的边缘设备的出现,为边缘设备带来计算是使边缘设备更智能的一个日益增长的挑战。知识蒸馏允许我们执行模型压缩而不影响性能的边缘设备。
引用
[1] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. “Distilling the knowledge in a neural network.” arXiv preprint arXiv:1503.02531 (2015).
[2] An overview of model compression techniques for deep learning in space
[3] IoT number of connected devices worldwide
作者:Kelvin
deephub翻译组