
Flink集群搭建
Flink集群搭建
集群规划
节点node01node02node03角色JobManager
TaskManagerTaskManagerTaskManager
下载并解压安装包
wget https://repo.huaweicloud.com/apache/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
在node01节点下载flink安装包,同时解压、重命名。
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz
mv flink-1.17.0 flink
修改集群配置
进入flink的conf目录,修改集群配置
vim /usr/local/program/flink/conf/flink-conf.yaml
1.修改
flink-conf.yaml
文件
JobManager节点配置
# jobmanager.rpc.address: localhost
# jobmanager.bind-host: localhost
jobmanager.rpc.address: node01
jobmanager.bind-host:0.0.0.0
# rest.address: localhost
# rest.bind-address: localhost
rest.address: node01
rest.bind-address:0.0.0.0
TaskManager节点配置
# taskmanager.host: localhost
# taskmanager.bind-host: localhost
taskmanager.host: node01
taskmanager.bind-host:0.0.0.0
注意:需要在
/etc/hosts
文件中配置各个节点信息
172.29.234.1 node01 node01
172.29.234.2 node02 node02
172.29.234.3 node03 node03
2.修改
workers
文件
指定
node01、node02、node03等节点为TaskManager
# localhost
node01
node02
node03
3.修改
masters
文件
# localhost:8081
node01:8081
分发安装目录
在
node01节点安装、配置好后,将Flink安装目录分发给另外两个节点服务器。
[root@node01 program]# pwd
/usr/local/program
[root@node01 program]# ls
flink jdk8
[root@node01 program]# scp -r flink node02:/usr/local/program/flink
[root@node01 program]# scp -r flink node03:/usr/local/program/flink
在node02、node03节点,修改
flink-conf.yaml
配置
1.node02节点
# taskmanager.host: localhost
taskmanager.host: node02
2.node03节点
# taskmanager.host: localhost
taskmanager.host: node03
启动集群
Flink附带了相关的bash脚本,可以用于启动、停止集群。
# 启动集群
./bin/start-cluster.sh
# 停止集群
./bin/stop-cluster.sh
在
node01
节点服务器上执行
start-cluster.sh
脚本以启动Flink集群
[root@node01 bin]# cd /usr/local/program/flink/bin
[root@node01 bin]# ./start-cluster.sh
Startingcluster.
Starting standalonesession daemon on host node01.
Starting taskexecutor daemon on host node01.
Starting taskexecutor daemon on host node02.
Starting taskexecutor daemon on host node03.
查看进程情况
[root@node01 bin]# jps
6788StandaloneSessionClusterEntrypoint7256Jps7116TaskManagerRunner
[root@node02 conf]# jps
16884TaskManagerRunner16959Jps
[root@node03 conf]# jps
17139TaskManagerRunner17214Jps
访问Web UI
当如上所示一样后,代表启动成功,此时可以访问
http://node01:8081
对flink集群和任务进行监控管理。
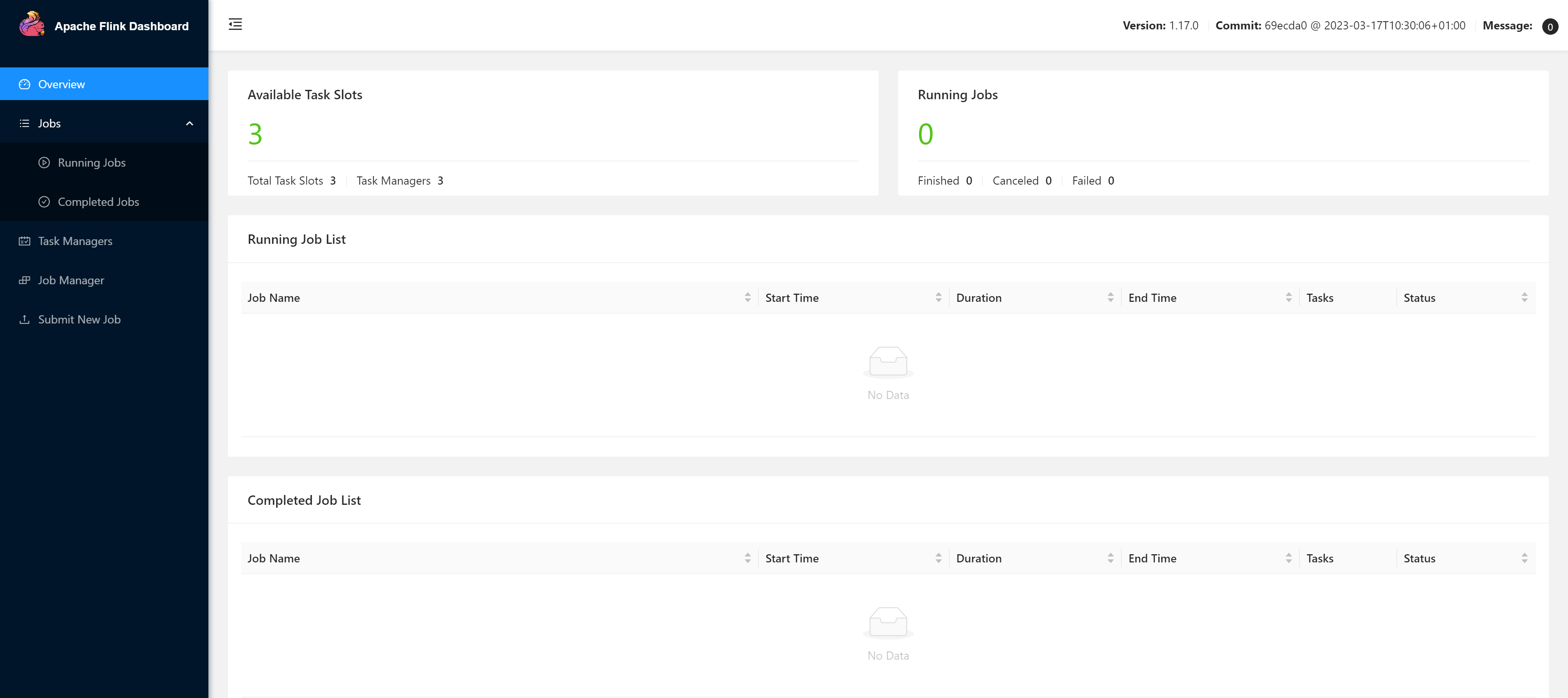
注意:关闭防火墙,否则可能无法访问,或者集群的
TaskManager
数量、Slot数量显示异常
systemctl stop firewalld
提交任务
[root@node01 bin]# flink run ../examples/streaming/WordCount.jar
查看运行结果
[root@node01 bin]# tail flink-*-taskexecutor-*.out
也可以通过Flink的 Web UI来监视集群的状态和正在运行的作业
Flink集群HA高可用
概述
集群实际上只有一个JobManager,是存在单点故障的,官方提供了Standalone Cluster HA模式来实现集群高可用。
集群可以有多个JobManager,但只有一个处于active状态,其余的则处于备用状态,Flink使用 ZooKeeper来选举出Active JobManager,并依赖其来提供一致性协调服务,所以需要预先安装 ZooKeeper 。
Flink本身提供了内置ZooKeeper插件,可以直接修改
conf/zoo.cfg,并且使用
/bin/start-zookeeper-quorum.sh直接启动。
集群规划
节点node01node02node03角色JobManager
TaskManagerJobManager
TaskManagerTaskManager
配置flink
基于Flink集群的node01节点配置的情况下,修改
conf/flink-conf.yaml
文件,增加如下配置:
# 配置使用zookeeper来开启高可用模式
high-availability.type: zookeeper
# 配置zookeeper的地址,采用zookeeper集群时,可以使用逗号来分隔多个节点地址
high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181
# 在zookeeper上存储flink集群元信息的路径
high-availability.zookeeper.path.root:/flink
# 集群id 放置集群的所有必需协调数据
high-availability.cluster-id:/cluster_one
# 持久化存储JobManager元数据的地址,zookeeper上存储的只是指向该元数据的指针信息
high-availability.storageDir: hdfs://node01:9000/flink/recovery
配置master、workers
修改conf/masters文件,配置master节点
node01:8081
node02:8081
修改conf/workers文件,配置worker节点
node01
node02
node03
配置ZK
编辑
vim zoo.cfg
文件
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
分发安装目录
在
node01节点安装、配置好后,将Flink安装目录分发给另外两个节点服务器。
[root@node01 program]# pwd
/usr/local/program
[root@node01 program]# ls
flink jdk8
[root@node01 program]# scp -r flink node02:/usr/local/program/flink
[root@node01 program]# scp -r flink node03:/usr/local/program/flink
在node02、node03节点,修改
flink-conf.yaml
配置
1.node02节点
jobmanager.rpc.address: node02
taskmanager.host: node02
2.node03节点
taskmanager.host: node03
启动HA集群
分发Flink相关配置到其他节点,然后确保Hadoop和ZooKeeper已经启动后,使用以下命令来启动集群:
[root@node01 flink]# bin/start-cluster.sh
StartingHA cluster with2masters.
Starting standalonesession daemon on host node01.
Starting standalonesession daemon on host node02.
Starting taskexecutor daemon on host node01.
Starting taskexecutor daemon on host node02.
Starting taskexecutor daemon on host node03.
访问
http://node01:8081
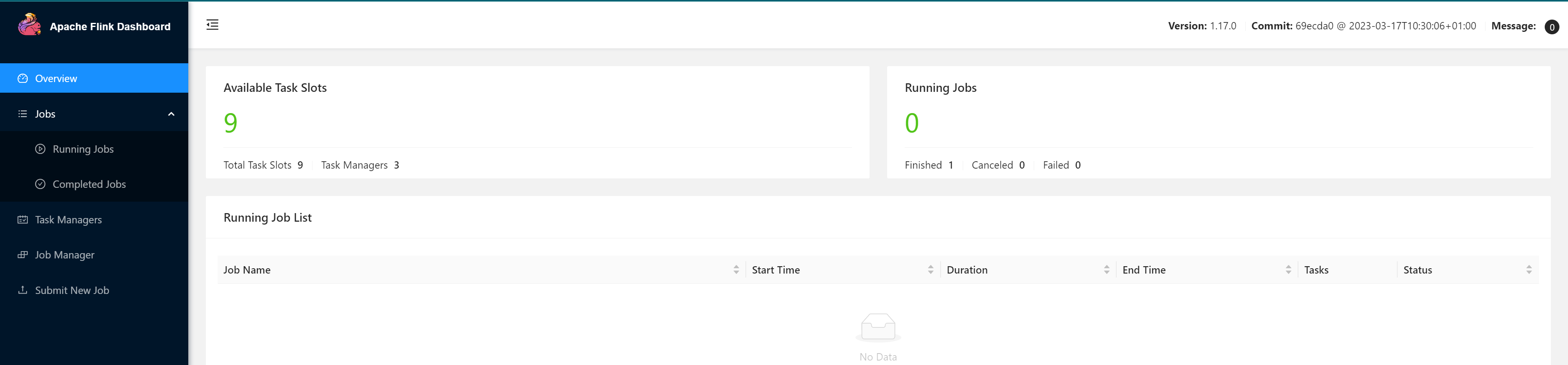
访问
http://node02:8081
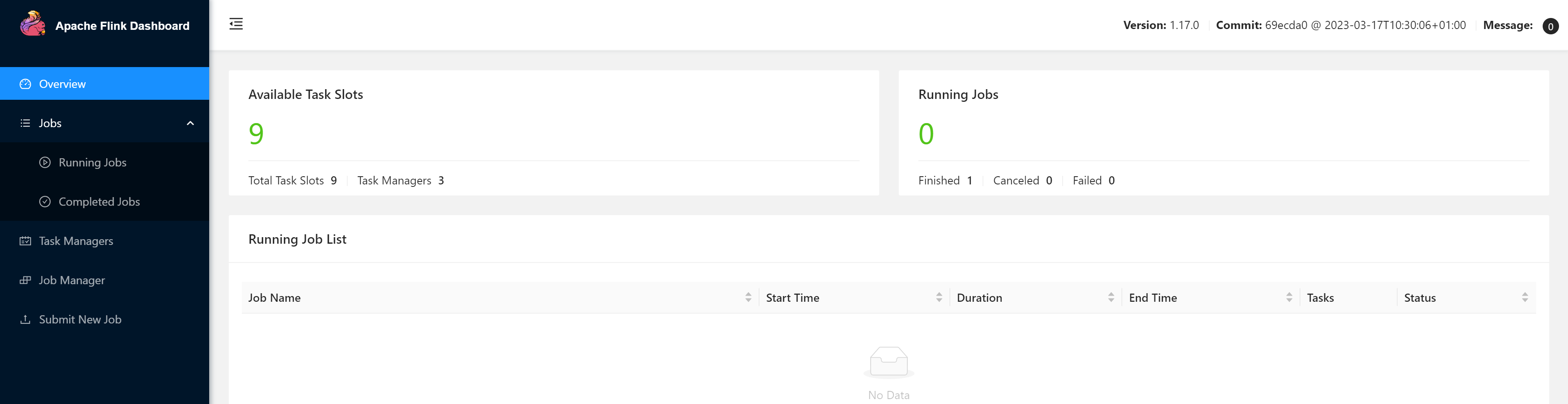
测试
查看ZK:JobManager节点信息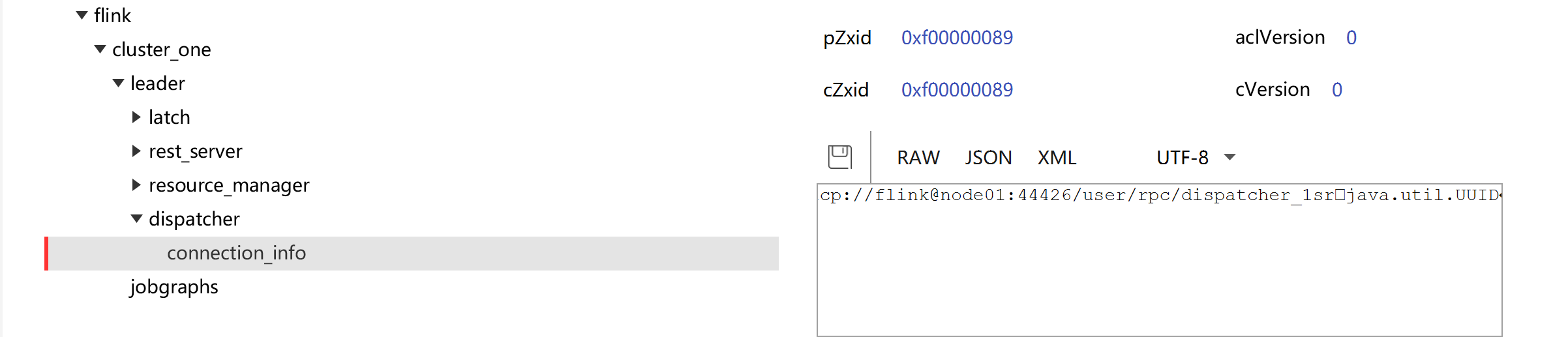
kill node01节点上的JobManager进程
[root@node01 flink]# jps
2564DataNode3508NodeManager18741Jps7784QuorumPeerMain16666TaskManagerRunner2363NameNode16300StandaloneSessionClusterEntrypoint3117ResourceManager[root@node01 flink]# kill -916300
查看Active JobManager是否变化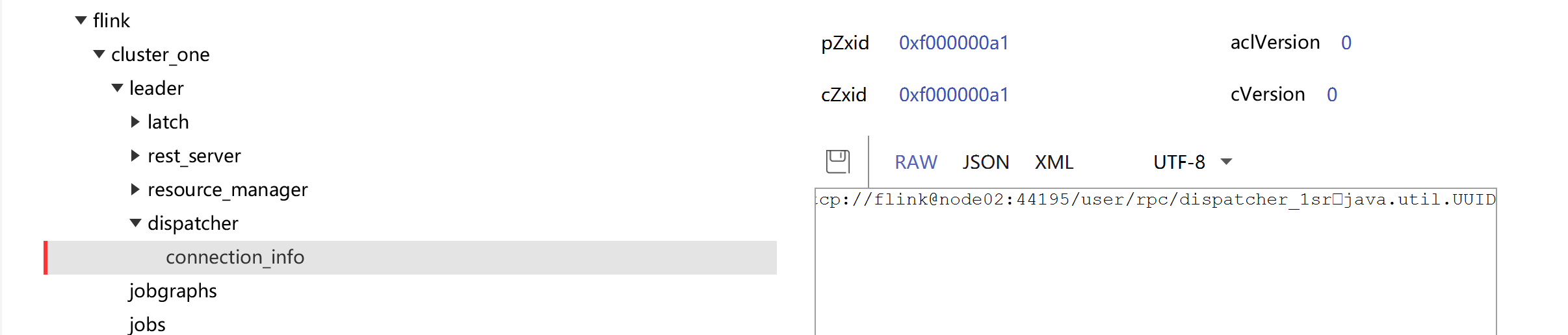
Flink参数配置
flink-conf.yaml文件中有大量的配置参数,基本常见参数如下:
# jobmanager地址
jobmanager.rpc.address: node01
# JobManager 的 JVM 堆内存大小,默认为 1024m
jobmanager.heap.size:1024m
# rpc通信端口
jobmanager.rpc.port:6123
# 进程使用的全部内存大小,可以根据集群规模进行适当调整
jobmanager.memory.process.size:1600m
# Taskmanager 的 JVM 堆内存大小,默认为 1024m
taskmanager.heap.size:1024m
# 进程使用的全部内存大小,可以根据集群规模进行适当调整
taskmanager.memory.process.size:1728m
# 每个TaskManager能够分配的Slot数量进行配置,默认为1
# 通常设置为 CPU 核心的数量,或其一半
# Slot就是TaskManager中具体运行一个任务所分配的计算资源
taskmanager.numberOfTaskSlots:1
# flink任务执行的并行度,默认为1
# 优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量
parallelism.default:1
# 重启策略
jobmanager.execution.failover-strategy: region
# 存储临时文件的路径,如果没有配置,则默认采用服务器的临时目录,如 LInux 的 /tmp 目录
io.tmp.dirs:/tmp
参考Flink的官方手册:更多配置
配置历史服务器
概述
运行Flink job的集群一旦停止,只能去yarn或本地磁盘上查看日志,对于Job任务信息的查看、异常问题的排查非常不友好。
Flink提供了历史服务器,用来在相应的Flink集群关闭后查询已完成作业的统计信息。通过History Server可以查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
Flink任务停止后,JobManager会将已经完成任务的统计信息进行存档,History Server进程则在任务停止后可以对任务统计信息进行查询。
配置
创建存储目录
[root@node01 flink]# hadoop fs -mkdir -p /logs/flink-job
在flink-config.yaml中添加如下配置
#==============================================================================
# HistoryServer
#==============================================================================
# TheHistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directorytoupload completed jobs to. Addthis directory tothe list of
# monitored directories of the HistoryServer as well (see below).
#jobmanager.archive.fs.dir: hdfs:///completed-jobs/
jobmanager.archive.fs.dir: hdfs://node01:9000/logs/flink-job
# The address under which the web-based HistoryServer listens.
#historyserver.web.address:0.0.0.0
historyserver.web.address: node01
# The port under which the web-based HistoryServer listens.
#historyserver.web.port:8082
historyserver.web.port:8082
# Comma separated list of directories tomonitorfor completed jobs.
#historyserver.archive.fs.dir: hdfs:///completed-jobs/
historyserver.archive.fs.dir: hdfs://node01:9000/logs/flink-job
# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval:10000
historyserver.archive.fs.refresh-interval:5000
启动、停止历史服务器
启动历史服务器
[root@node01 flink]# bin/historyserver.sh start
Starting historyserver daemon on host node01.
停止历史服务器
[root@node01 flink]# bin/historyserver.sh stop
Stopping historyserver daemon (pid:30749) on host node01.
提交一个Job任务
[root@node01 flink]# bin/flink run -t yarn-per-job -c com.atguigu.wc.WordCountStreamUnboundedDemo/root/FlinkTutorial-1.17-1.0-SNAPSHOT.jar
2023-06-1223:41:00,719INFOorg.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient[]-SASL encryption trust check: localHostTrusted =false, remoteHostTrusted =false2023-06-1223:41:00,742INFOorg.apache.hadoop.hdfs.protocol.datatransfer.sasl.SaslDataTransferClient[]-SASL encryption trust check: localHostTrusted =false, remoteHostTrusted =false2023-06-1223:41:00,761INFOorg.apache.flink.yarn.YarnClusterDescriptor[]-Cannot use kerberos delegation token manager, no valid kerberos credentials provided.2023-06-1223:41:00,766INFOorg.apache.flink.yarn.YarnClusterDescriptor[]-Submitting application master application_1686577483648_0012
2023-06-1223:41:00,792INFOorg.apache.hadoop.yarn.client.api.impl.YarnClientImpl[]-Submitted application application_1686577483648_0012
2023-06-1223:41:00,792INFOorg.apache.flink.yarn.YarnClusterDescriptor[]-Waitingfor the cluster tobe allocated
2023-06-1223:41:00,793INFOorg.apache.flink.yarn.YarnClusterDescriptor[]-Deploying cluster, current state ACCEPTED2023-06-1223:41:04,565INFOorg.apache.flink.yarn.YarnClusterDescriptor[]-YARN application has been deployed successfully.2023-06-1223:41:04,565INFOorg.apache.flink.yarn.YarnClusterDescriptor[]-FoundWebInterface node02:38887 of application 'application_1686577483648_0012'.Job has been submitted withJobID cd41d983c93d8eb906c9aa899dcdefd0
访问
http://node01:8088/cluster
查看Hadoop
访问Web UI查看提交任务信息
查看历史Job信息
在浏览器地址栏输入:
http://node01:8082
查看已经停止的 job 的统计信息
停止提交任务
[root@node01 flink]# bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_1686577483648_0012 cd41d983c93d8eb906c9aa899dcdefd0
访问
http://node01:9870/explorer.html#/logs/flink-job
查看HDFS中的归档文件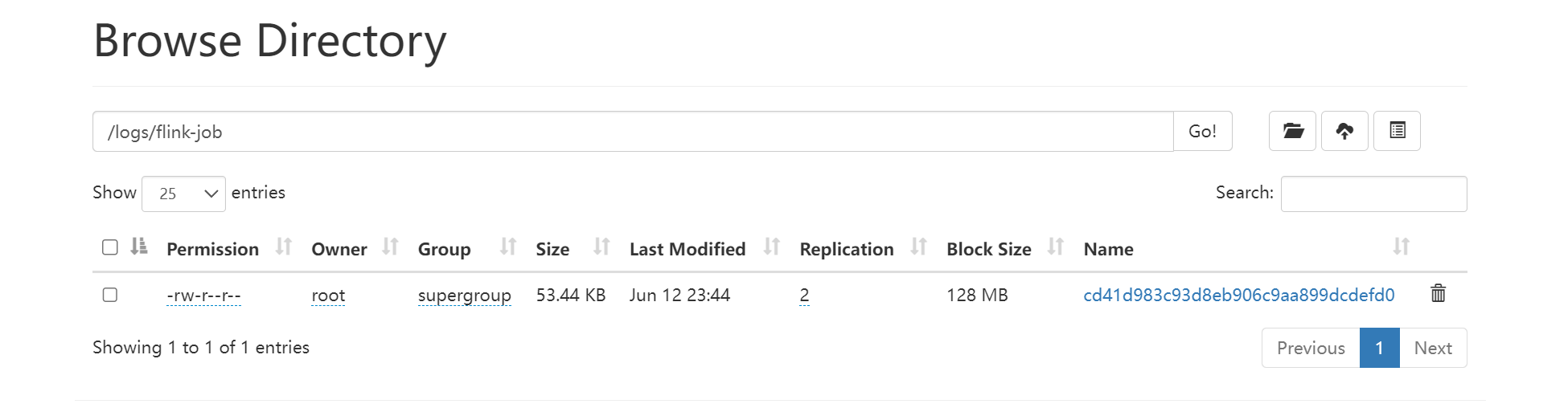
等一段时间,几分钟后查看历史服务器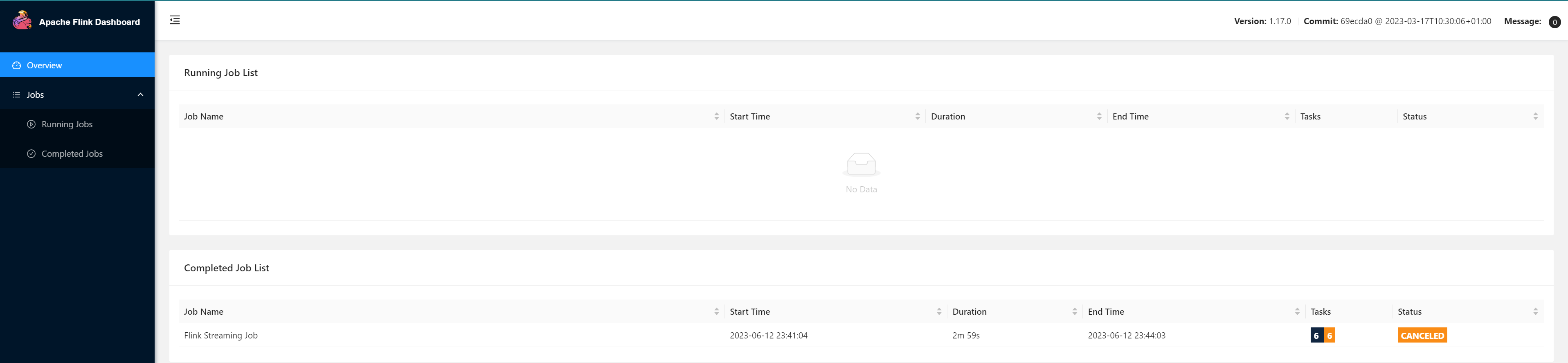
查看Job具体信息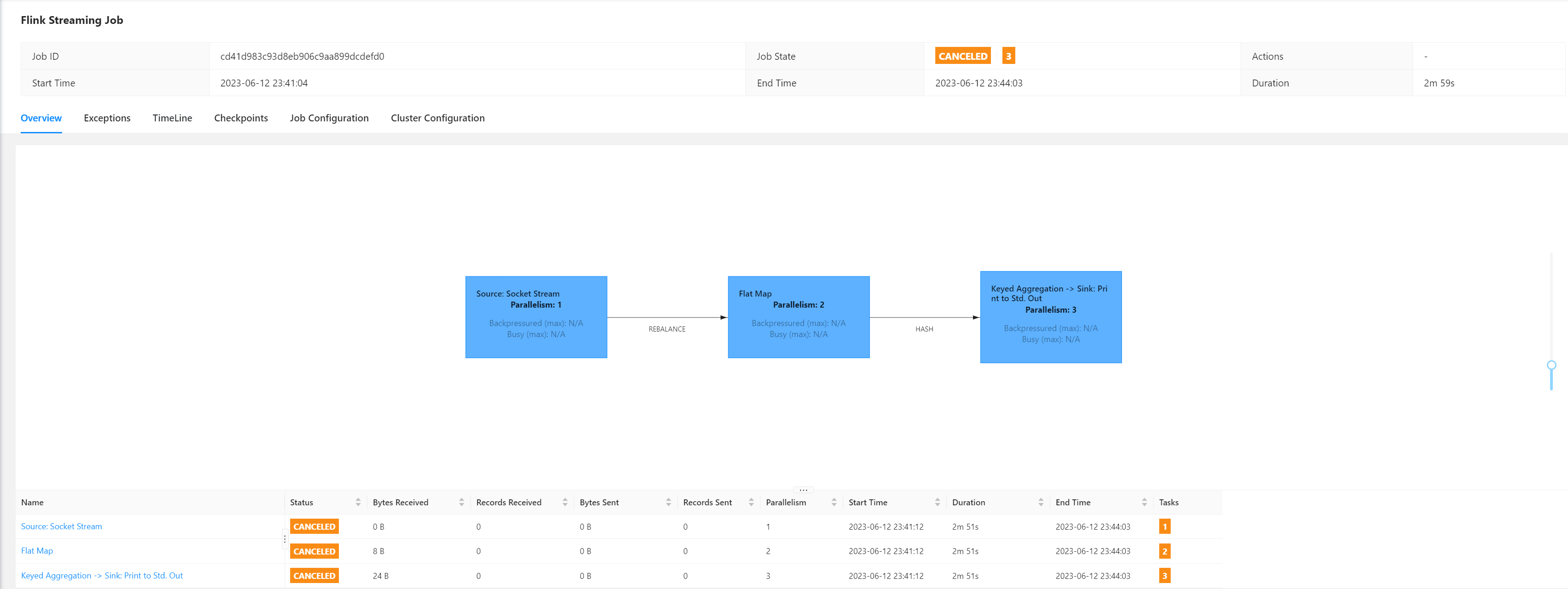
版权归原作者 CodeDevMaster 所有, 如有侵权,请联系我们删除。