
- jvm内存优化
- 内存优化
- netty优化
- akka优化
- 并行度优化
- 对象重用
- checkpoint优化
- 网络内存调优
- 状态优化
- flink数据倾斜优化
- flink背压
jvm内存参数调优
Flink是依赖内存计算,计算过程中内存不够对Flink的执行效率影响很大。可以通过监控GC(Garbage Collection),评估内存使用及剩余情况来判断内存是否变成性能瓶颈,并根据情况优化。
监控节点进程的YARN的Container GC日志,如果频繁出现Full GC,需要优化GC。
GC的配置:在客户端的"conf/flink-conf.yaml"配置文件中,在“env.java.opts”配置项中添加参数:
-Xloggc:<LOG_DIR>/gc.log -XX:+PrintGCDetails -XX:-OmitStackTraceInFastThrow -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=20 -XX:GCLogFileSize=20M
此处默认已经添加GC日志。
调整老年代和新生代的比值。在客户端的“conf/flink-conf.yaml”配置文件中,在“env.java.opts”配置项中添加参数:“-XX:NewRatio”。如“ -XX:NewRatio=2”,则表示老年代与新生代的比值为2:1,新生代占整个堆空间的1/3,老年代占2/3。

可以通过设置 **
jobmanager.memory.enable-jvm-direct-memory-limit
**** **对 JobManager 进程的 JVM 直接内存进行限制
Flink内存调优
flink进程内存

** jobmanager相关配置:**

taskamanger相关配置:
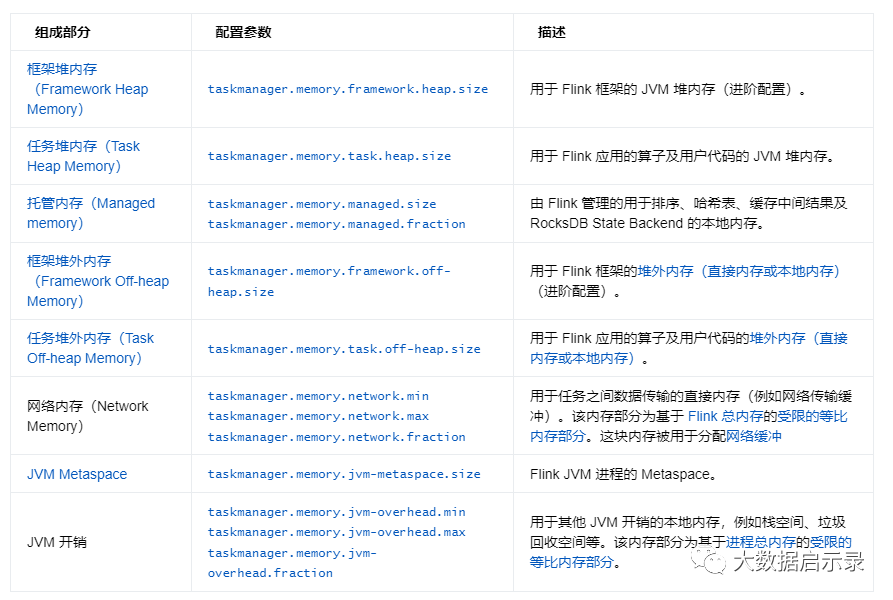
yarn相关的配置:
yarn.appmaster.vcores YARN应用程序主机使用的虚拟核心(vcore)的数量。yarn.containers.vcores 每个YARN容器的虚拟核心数(vcore)。默认情况下,vcore数设置为每个TaskManager的插槽数(如果已设置),否则设置为1。为了使用此参数,您的群集必须启用CPU调度。您可以通过设置来做到这一点org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler。yarn.scheduler.maximum-allocation-vcoresyarn.scheduler.minimum-allocation-vcoresFlink单个task manager的slot数量必须介于这两个值之间yarn.scheduler.maximum-allocation-mbyarn.scheduler.minimum-allocation-mbFlink的job manager 和task manager内存不得超过container最大分配内存大小。yarn.nodemanager.resource.cpu-vcores yarn的虚拟CPU内核数,建议设置为物理CPU核心数
netty优化
Netty Shuffle环境
Network Communication (via Netty)
akka优化
akka.ask.callstack 捕获异步请求的调用堆栈。注意,如果有数百万个并发RPC调用,这可能会增加内存占用。akka.ask.timeout 用于期望并阻止Akka呼叫的超时。如果Flink由于超时而失败,则应尝试增加此值。超时可能是由于计算机运行缓慢或网络拥塞引起的。超时值需要一个时间单位说明符(ms / s / min / h / d)。akka.client-socket-worker-pool.pool-size-factor 池大小因子使用以下公式确定线程池大小:ceil(available processors * factor)。然后,结果大小受pool-size-min和pool-size-max值限制。akka.client-socket-worker-pool.pool-size-max 要限制基于因素的最大线程数。akka.client-socket-worker-pool.pool-size-min 最小线程数以上限为基础。akka.client.timeout 60s 客户端上所有阻塞呼叫的超时。akka.fork-join-executor.parallelism-factor 并行度因子用于通过以下公式确定线程池大小:ceil(available processors * factor)。然后,所得到的大小由并行度最小值和并行度最大值限制。akka.fork-join-executor.parallelism-max 最大线程数上限为基于因子的并行数。akka.fork-join-executor.parallelism-min 最小线程数以基于因素的并行度为上限。akka.framesize 10485760b(10MB) 在JobManager和TaskManager之间发送的消息的最大大小。如果Flink因消息超出此限制而失败,则应增加该限制。消息大小需要大小单位说明符。akka.fork-join-executor.parallelism-factor 并行度因子用于使用以下公式确定线程池大小:ceil(可用处理器*因子)。然后,结果大小由并行度最小值和并行度最大值限制。akka.fork-join-executor.parallelism-max 基于并行度的最大线程数上限akka.fork-join-executor.parallelism-min 基于并行度的最大线程数下限akka.framesize JobManager和TaskManager之间发送的最大消息大小。如果Flink失败是因为消息超过了这个限制,那么您应该增加它。消息大小需要大小单位说明符。akka.retry-gate-closed-for 远程连接断开后,闸门应关闭几毫秒。akka.server-socket-worker-pool.pool-size-factor 池大小因子用于使用以下公式确定线程池大小:ceil(可用处理器*因子)。然后,结果大小由池大小最小值和池大小最大值限定。akka.server-socket-worker-pool.pool-size-max 基于上限因子的最大线程数。akka.server-socket-worker-pool.pool-size-min 基于上限因子的最小线程数akka.tcp.timeout 所有出站连接超时。如果由于网络速度慢而在连接TaskManager时遇到问题,则应增加此值。akka.startup-timeout 超时之后,远程组件的启动被视为失败。
并行度优化
当分区导致数据倾斜时,需要考虑优化分区。避免非并行度操作,有些对DataStream的操作会导致无法并行,例如WindowAll。keyBy尽量不要使用String。
并行度控制任务的数量,影响操作后数据被切分成的块数。调整并行度让任务的数量和每个任务处理的数据与机器的处理能力达到最优。查看CPU使用情况和内存占用情况,当任务和数据不是平均分布在各节点,而是集中在个别节点时,可以增大并行度使任务和数据更均匀的分布在各个节点。增加任务的并行度,充分利用集群机器的计算能力,一般并行度设置为集群CPU核数总和的2-3倍。
taskmanger 个数:
num_of_tm = ceil(parallelism / slot) 即并行度除以slot个数,结果向上取整。
算子层面并行度设置:
通过调用**setParallelism()**方法来指定
执行环境层次
Flink程序运行在执行环境中。执行环境为所有执行的算子、数据源、data sink定义了一个默认的并行度。
执行环境的默认并行度可以通过调用setParallelism()方法指定。例如:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStream<String> text = [...]
DataStream<Tuple2<String, Integer>> wordCounts = [...]
wordCounts.print();
env.execute("Word Count Example");
客户端层次
并行度可以在客户端将job提交到Flink时设定。对于CLI客户端,可以通过“-p”参数指定并行度。例如:./bin/flink run -p 10 ../examples/WordCount-java.jar
对象重用
对象重用的本质就是在算子链中的下游算子使用上游对象的浅拷贝。若关闭对象重用,则必须经过一轮序列化和反序列化,相当于深拷贝,所以就不能100%地发挥算子链的优化效果。
但正所谓鱼与熊掌不可兼得,若启用了对象重用,那么我们的业务代码中必然不能出现以下两种情况,以免造成混乱:
- 在下游修改上游发射的对象,或者上游存入其State中的对象;
- 同一条流直接对接多个处理逻辑(如stream.map(new AFunc())的同时还有stream.map(new BFunc()))。
总之,在enableObjectReuse()之前,需要谨慎评估业务代码是否会带来副作用。社区大佬David Anderson曾在Stack Overflow上给出了一个简单明晰的回答,可参见这里。
env.getConfig().enableObjectReuse();
当调用了 enableObjectReuse 方法后, Flink 会把中间深拷贝的步骤都省略掉,SourceFunction 产生的数据直接作为 MapFunction 的输入,可以减少 gc 压力。但需要特别注意的是,这个方法不能随便调用,必须要确保下游 Function 只有一种(也就是一个流只会被一个算子处理),或者下游的多个 Function 均不会改变对象内部的值。否则可能会有线程安全的问题。
checkpoint优化
**监控checkpoint **
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/ops/monitoring/checkpoint_monitoring/
Checkpoint 时间间隔,需要根据业务场景对时效性的要求而定。如果时效性要求不高,可以设置到分钟级别,比如5分钟、10分钟;如果对时效性要求很高,结合 flink 控制页面 Checkpoints 的Summary 中的 End to End Duration,通过最大值、最小值和平均值,合理设置时间间隔。注意,时间间隔需要比 End to End Duration 的时间要长,否则,可能会导致上一个 checkpoint 没结束,下一个 checkpoint 已经开始。为了避免这一情况的发生,除了设置时间间隔,两次 checkpoint 的最小时间间隔也可以起到作用,该配置决定在上一次 checkpoint 结束之后,至少等待多长时间开始下一次的 checkpoint。
设置原则:
- Checkpoint 时间间隔不易过大。一般来说,Checkpoint 时间间隔越长,需要生产的 State 就越大。如此一来,当失败恢复时,需要更长的追赶时间。
- Checkpoint 时间间隔不易过小。如果 Checkpoint 时间间隔太小,那么 Flink 应用程序就会频繁 Checkpoint,导致部分资源被占有,无法专注地进行数据处理。
- Checkpoint 时间间隔大于 Checkpoint 的生产时间。当 Checkpoint 时间间隔比 Checkpoint 生产时间长时,在上次 Checkpoint 完成时,不会立刻进行下一次 Checkpoint,而是会等待一段时间,之后再进行新的 Checkpoint。否则,每次 Checkpoint 完成时,就会立即开始下一次 Checkpoint,系统会有很多资源被 Checkpoint 占用,而真正任务计算的资源就会变少。
- 开启本地恢复。如果 Flink State 很大,在进行恢复时,需要从远程存储上读取 State 进行恢复,如果 State 文件过大,此时可能导致任务恢复很慢,大量的时间浪费在网络传输方面。此时可以设置 Flink 应用程序本地 State 恢复,应用程序 State 本地恢复默认没有开启,可以设置参数 state.backend.local-recovery 值为 true 进行激活。
- 设置 Checkpoint 保存数。Checkpoint 保存数默认是 1,也就是只保存最新的 Checkpoint 的 State 文件,当进行 State 恢复时,如果最新的 Checkpoint 文件不可用时 (比如文件损坏或者其他原因),那么 State 恢复就会失败,如果设置 Checkpoint 保存数 3,即使最新的 Checkpoint 恢复失败,那么 Flink 也会回滚到上一次 Checkpoint 的状态文件进行恢复。考虑到这种情况,可以通过 state.checkpoints.num-retained 设置 Checkpoint 保存数。
// 使⽤ RocksDBStateBackend 做为状态后端,并开启增量 Checkpoint
RocksDBStateBackend rocksDBStateBackend = new
RocksDBStateBackend("hdfs://hadoop01:8020/flink/checkpoints", true);
env.setStateBackend(rocksDBStateBackend);
// 开启 Checkpoint,间隔为 1 分钟
env.enableCheckpointing(TimeUnit.MINUTES.toMillis(1));
// 配置 Checkpoint
CheckpointConfig checkpointConf = env.getCheckpointConfig();
checkpointConf.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
// 最小间隔 2 分钟
checkpointConf.setMinPauseBetweenCheckpoints(TimeUnit.MINUTES.toMillis(2))
// 超时时间 10 分钟
checkpointConf.setCheckpointTimeout(TimeUnit.MINUTES.toMillis(10));
// 保存 checkpoint
checkpointConf.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
配置Task本地恢复
Task 本地恢复 默认禁用,可以通过 Flink 的 **CheckpointingOptions.LOCAL_RECOVERY **配置中指定的键 state.backend.local-recovery 来启用。此设置的值可以是 true 以启用或 false(默认)以禁用本地恢复。
注意,unaligned checkpoints 目前不支持 task 本地恢复。
参考公众号链接:flink状态调优
参考官网:
https://nightlies.apache.org/flink/flink-docs-master/zh/docs/ops/state/large_state_tuning/
网络内存调优
缓冲消胀机制(Buffer Debloating)
缓冲消胀机制尝试通过自动调整缓冲数据量到一个合理值来解决这个问题。
缓冲消胀功能计算 subtask 可能达到的最大吞吐(始终保持繁忙状态时)并且通过调整缓冲数据量来使得数据的消费时间达到配置值。
可以通过设置
t
**
askmanager.network.memory.buffer-debloat.enabled
**为
true
来开启缓冲消胀机制。通过设置 **
taskmanager.network.memory.buffer-debloat.target
为
duration
** 类型的值来指定消费缓冲数据的目标时间。默认值应该能满足大多数场景。
这个功能使用过去的吞吐数据来预测消费剩余缓冲数据的时间。如果预测不准,缓冲消胀机制会导致以下问题:
- 没有足够的缓存数据来提供全量吞吐。
- 有太多缓冲数据对 checkpoint barrier 推进或者非对齐的 checkpoint 的大小造成不良影响。
如果您的作业负载经常变化(即,突如其来的数据尖峰,定期的窗口聚合触发或者 join ),您可能需要调整以下设置:
- taskmanager.network.memory.buffer-debloat.period:这是缓冲区大小重算的最小时间周期。周期越小,缓冲消胀机制的反应时间就越快,但是必要的计算会消耗更多的CPU。
- taskmanager.network.memory.buffer-debloat.samples:调整用于计算平均吞吐量的采样数。采集样本的频率可以通过 taskmanager.network.memory.buffer-debloat.period 来设置。样本数越少,缓冲消胀机制的反应时间就越快,但是当吞吐量突然飙升或者下降时,缓冲消胀机制计算的最佳缓冲数据量会更容易出错。
- taskmanager.network.memory.buffer-debloat.threshold-percentages:防止缓冲区大小频繁改变的优化(比如,新的大小跟旧的大小相差不大)。
您可以使用以下指标来监控当前的缓冲区大小:
estimatedTimeToConsumeBuffersMs:消费所有输入通道(input channel)中数据的总时间。debloatedBufferSize:当前的缓冲区大小。
限制
**多个输入和合并 **
当前,吞吐计算和缓冲消胀发生在 subtask 层面。
如果您的 subtask 有很多不同的输入或者有一个合并的输入,缓冲消胀可能会导致低吞吐的输入有太多缓冲数据,而高吞吐输入的缓冲区数量可能太少而不够维持当前吞吐。当不同的输入吞吐差别比较大时,这种现象会更加的明显。我们推荐您在测试这个功能时重点关注这种 subtask。
**缓冲区的尺寸和个数 **
当前,缓冲消胀仅在使用的缓冲区大小上设置上限。实际的缓冲区大小和个数保持不变。这意味着缓冲消胀机制不会减少作业的内存使用。您应该手动减少缓冲区的大小或者个数。
此外,如果您想减少缓冲数据量使其低于缓冲消胀当前允许的量,您可能需要手动的设置缓冲区的个数。
高并行度
目前,使用默认配置,缓冲区去块机制可能无法在高并行度(约200以上)下正确执行。如果您观察到吞吐量降低或检查点时间高于预期,我们建议将浮动缓冲区(taskmanager.network.memory.foating buffers per gate)的数量从默认值增加到至少等于并行度的数量。
发生问题的并行度的实际值因作业而异,但通常应该超过几百。
**网络缓冲生命周期 **
Flink 有多个本地缓冲区池 —— 每个输出和输入流对应一个。每个缓冲区池的大小被限制为
channels * taskmanager.network.memory.buffers-per-channel + taskmanager.network.memory.floating-buffers-per-gate
缓冲区的大小可以通过
taskmanager.memory.segment-size
来设置。
**输入网络缓冲 **
输入通道中的缓冲区被分为独占缓冲区(exclusive buffer)和流动缓冲区(floating buffer)。每个独占缓冲区只能被一个特定的通道使用。一个通道可以从输入流的共享缓冲区池中申请额外的流动缓冲区。剩余的流动缓冲区是可选的并且只有资源足够的时候才能获取。
在初始阶段:
- Flink 会为每一个输入通道获取配置数量的独占缓冲区。
- 所有的独占缓冲区都必须被满足,否则作业会抛异常失败。
- Flink 至少要有一个流动缓冲区才能运行。
**输出网络缓冲 **
不像输入缓冲区池,输出缓冲区池只有一种类型的缓冲区被所有的 subpartitions 共享。
为了避免过多的数据倾斜,每个 subpartition 的缓冲区数量可以通过**
taskmanager.network.memory.max-buffers-per-channel
**来限制。
不同于输入缓冲区池,这里配置的独占缓冲区和流动缓冲区只被当作推荐值。如果没有足够的缓冲区,每个输出 subpartition 可以只使用一个独占缓冲区而没有流动缓冲区。
**透支缓冲区(Overdraft buffers) **
另外,每个 subtask 输出数据时可以至多请求** ****
taskmanager.network.memory.max-overdraft-buffers-per-gate
**(默认 5)个额外的透支缓冲区(overdraft buffers)。只有当前 subtask 被下游 subtasks 反压且当前 subtask 需要 请求超过 1 个网络缓冲区(network buffer)才能完成当前的操作时,透支缓冲区才会被使用。可能发生在以下情况:
- 序列化非常大的 records,不能放到单个网络缓冲区中。
- 类似 flatmap 的算子,即:处理单个 record 时可能会生产多个 records。
- 周期性地或某些事件触发产生大量 records 的算子(例如:
WindowOperator的触发)。
在这些情况下,如果没有透支缓冲区,Flink 的 subtask 线程会被阻塞在反压,从而阻止例如 Unaligned Checkpoint 的完成。为了缓解这种情况,增加了透支缓冲区的概念。这些透支缓冲区是可选的,Flink 可以仅仅使用常规的缓冲区逐渐取得进展,也就是 说
0
是
taskmanager.network.memory.max-overdraft-buffers-per-gate
可以接受的配置值。
**缓冲区的数量 **
独占缓冲区和流动缓冲区的默认配置应该足以应对最大吞吐。如果想要最小化缓冲数据量,那么可以将独占缓冲区设置为
0
,同时减小内存段的大小。
**选择缓冲区的大小 **
在往下游 subtask 发送数据部分时,缓冲区通过汇集 record 来优化网络开销。下游 subtask 应该在接收到完整的 record 后才开始处理它。
如果缓冲区太小,或者缓冲区刷新太频繁(execution.buffer-timeout配置参数),这可能会导致吞吐量降低,因为在Flink的运行时,每个缓冲区的开销明显高于每个记录的开销。
根据经验,我们不建议考虑增加缓冲区大小或缓冲区超时,除非您可以在实际工作负载中观察到网络瓶颈(下游操作员空闲、上游背压、输出缓冲区队列已满、下游输入队列为空)。
如果缓冲区太大,会导致:
- 内存使用高
- 大量的 checkpoint 数据量(针对非对齐的 checkpoints)
- 漫长的 checkpoint 时间(针对对齐的 checkpoints)
execution.buffer-timeout较小时内存分配使用率会比较低,因为缓冲区还没被塞满数据就被发送下去了。
**选择缓冲区的数量 **
缓冲区的数量是通过
taskmanager.network.memory.buffers-per-channel
和
taskmanager.network.memory.floating-buffers-per-gate
来配置的。
为了最好的吞吐率,我们建议使用独占缓冲区和流动缓冲区的默认值(except you have one of limit cases)。如果缓冲数据量存在问题,更建议打开缓冲消胀。
您可以人工地调整网络缓冲区的个数,但是需要注意:
- 您应该根据期待的吞吐量(单位
bytes/second)来调整缓冲区的数量。协调数据传输量(大约两个节点之间的两个往返消息)。延迟也取决于您的网络。
使用 buffer 往返时间(大概
1ms
在正常的本地网络中),缓冲区大小和期待的吞吐,您可以通过下面的公式计算维持吞吐所需要的缓冲区数量:
number_of_buffers = expected_throughput * buffer_roundtrip / buffer_size
比如,期待吞吐为
320MB/s
,往返延迟为
1ms
,内存段为默认大小,为了维持吞吐需要使用10个活跃的缓冲区:
number_of_buffers = 320MB/s * 1ms / 32KB = 10
- 流动缓冲区的目的是为了处理数据倾斜。理想情况下,流动缓冲区的数量(默认8个)和每个通道独占缓冲区的数量(默认2个)能够使网络吞吐量饱和。但这并不总是可行和必要的。所有 subtask 中只有一个通道被使用也是非常罕见的。
- 独占缓冲区的目的是提供一个流畅的吞吐量。当一个缓冲区在传输数据时,另一个缓冲区被填充。当吞吐量比较高时,独占缓冲区的数量是决定 Flink 中缓冲数据的主要因素。
当低吞吐量下出现反压时,您应该考虑减少独占缓冲区。
总结:
可以通过开启缓冲消胀机制来简化 Flink 网络的内存配置调整。您也可能需要调整它。
如果这不起作用,您可以关闭缓冲消胀机制并且人工地配置内存段的大小和缓冲区个数。针对第二种场景,我们推荐:
- 使用默认值以获得最大吞吐
- 减少内存段大小、独占缓冲区的数量来加快 checkpoint 并减少网络栈消耗的内存量
flink状态优化
使用rocksdb状态后端开启增量检查点
Tuning MemTable
memtable 作为 LSM Tree 体系里的读写缓存,对写性能有较大的影响。以下是一些值得注意的参数。为方便对比,下文都会将 RocksDB 的原始参数名与 Flink 配置中的参数名一并列出,用竖线分割。
- write_buffer_size | state.backend.rocksdb.writebuffer.size单个 memtable 的大小,默认是64MB。当 memtable 大小达到此阈值时,就会被标记为不可变。一般来讲,适当增大这个参数可以减小写放大带来的影响,但同时会增大 flush 后 L0、L1 层的压力,所以还需要配合修改 compaction 参数,后面再提。
- max_write_buffer_number | state.backend.rocksdb.writebuffer.countmemtable 的最大数量(包含活跃的和不可变的),默认是2。当全部 memtable 都写满但是 flush 速度较慢时,就会造成写停顿,所以如果内存充足或者使用的是机械硬盘,建议适当调大这个参数,如4。
- min_write_buffer_number_to_merge | state.backend.rocksdb.writebuffer.number-to-merge在 flush 发生之前被合并的 memtable 最小数量,默认是1。举个例子,如果此参数设为2,那么当有至少两个不可变 memtable 时,才有可能触发 flush(亦即如果只有一个不可变 memtable,就会等待)。调大这个值的好处是可以使更多的更改在 flush 前就被合并,降低写放大,但同时又可能增加读放大,因为读取数据时要检查的 memtable 变多了。经测试,该参数设为2或3相对较好。
Tuning Block/Block Cache
block 是 sstable 的基本存储单位。block cache 则扮演读缓存的角色,采用 LRU 算法存储最近使用的 block,对读性能有较大的影响。
- block_size | state.backend.rocksdb.block.blocksizeblock 的大小,默认值为4KB。在生产环境中总是会适当调大一些,一般32KB比较合适,对于机械硬盘可以再增大到128~256KB,充分利用其顺序读取能力。但是需要注意,如果 block 大小增大而 block cache 大小不变,那么缓存的 block 数量会减少,无形中会增加读放大。
- block_cache_size | state.backend.rocksdb.block.cache-sizeblock cache 的大小,默认为8MB。由上文所述的读写流程可知,较大的 block cache 可以有效避免热数据的读请求落到 sstable 上,所以若内存余量充足,建议设置到128MB甚至256MB,读性能会有非常明显的提升。
Tuning Compaction
compaction 在所有基于 LSM Tree 的存储引擎中都是开销最大的操作,弄不好的话会非常容易阻塞读写。建议看官先读读前面那篇关于 RocksDB 的 compaction 策略的文章,获取一些背景知识,这里不再赘述。
- compaction_style | state.backend.rocksdb.compaction.stylecompaction 算法,使用默认的 LEVEL(即 leveled compaction)即可,下面的参数也是基于此。
- target_file_size_base | state.backend.rocksdb.compaction.level.target-file-size-baseL1层单个 sstable 文件的大小阈值,默认值为64MB。每向上提升一级,阈值会乘以因子 target_file_size_multiplier(但默认为1,即每级sstable最大都是相同的)。显然,增大此值可以降低 compaction 的频率,减少写放大,但是也会造成旧数据无法及时清理,从而增加读放大。此参数不太容易调整,一般不建议设为256MB以上。
- max_bytes_for_level_base | state.backend.rocksdb.compaction.level.max-size-level-baseL1层的数据总大小阈值,默认值为256MB。每向上提升一级,阈值会乘以因子 max_bytes_for_level_multiplier(默认值为10)。由于上层的大小阈值都是以它为基础推算出来的,所以要小心调整。建议设为 target_file_size_base 的倍数,且不能太小,例如5~10倍。
- level_compaction_dynamic_level_bytes | state.backend.rocksdb.compaction.level.use-dynamic-size这个参数之前讲过。当开启之后,上述阈值的乘法因子会变成除法因子,能够动态调整每层的数据量阈值,使得较多的数据可以落在最高一层,能够减少空间放大,整个 LSM Tree 的结构也会更稳定。对于机械硬盘的环境,强烈建议开启。
Generic Parameters
- max_open_files | state.backend.rocksdb.files.open顾名思义,是 RocksDB 实例能够打开的最大文件数,默认为-1,表示不限制。由于sstable的索引和布隆过滤器默认都会驻留内存,并占用文件描述符,所以如果此值太小,索引和布隆过滤器无法正常加载,就会严重拖累读取性能。
- max_background_compactions/max_background_flushes|state.backend.rocksdb.thread.num后台负责 flush 和 compaction 的最大并发线程数,默认为1。注意 Flink 将这两个参数合二为一处理(对应 DBOptions.setIncreaseParallelism() 方法),鉴于 flush 和 compaction 都是相对重的操作,如果 CPU 余量比较充足,建议调大,在我们的实践中一般设为4。
参考公众号链接:flink状态调优
flink数据倾斜优化
参考公众号链接:flink数据倾斜常见优化指南
背压优化
反压监控指标:
- **
backPressureTimeMsPerSecond**,subtask 被反压的时间 - **
idleTimeMsPerSecond**,subtask 等待某类处理的时间 - **
busyTimeMsPerSecond**,subtask 实际工作时间 在任何时间点,这三个指标相加都约等于1000ms。
web ui观测:
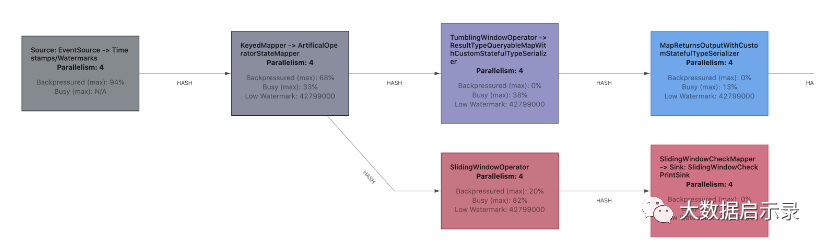
闲置的 tasks 为蓝色,完全被反压的 tasks 为黑色,完全繁忙的 tasks 被标记为红色。中间的所有值都表示为这三种颜色之间的过渡色。
Job Overview观测反压状态:
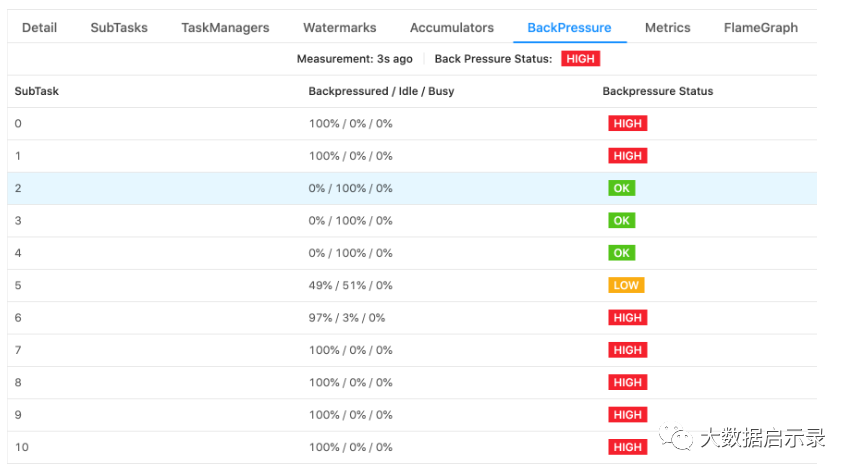
常见解决方式:
消除背压源头,通过优化 Flink 作业,通过调整 Flink 或 JVM 参数,或是通过扩容。
减少 Flink 作业中缓冲在 In-flight 数据的数据量。
启用非对齐 Checkpoints。这些选项并不是互斥的,可以组合在一起。本文档重点介绍后两个选项。
禁用/合并算子链chain或者资源槽共享
先赞批,再写入(满足实时性要求的情况下,异步 io + 热缓存来优化读写性能
增加并行度,增加资源。checkpoint时长合理设置
缓冲区 Debloating
Flink 1.14 引入了一个新的工具,用于自动控制在 Flink 算子/子任务之间缓冲的 In-flight 数据的数据量。缓冲区 Debloating 机 制可以通过将属性
taskmanager.network.memory.buffer-debloat.enabled
设置为
true
来启用。
此特性对对齐和非对齐 Checkpoint 都生效,并且在这两种情况下都能缩短 Checkpointing 的时间,不过 Debloating 的效果对于 对齐 Checkpoint 最明显。当在非对齐 Checkpoint 情况下使用缓冲区 Debloating 时,额外的好处是 Checkpoint 大小会更小,并且恢复时间更快 (需要保存 和恢复的 In-flight 数据更少)。
非对齐checkpoint
从Flink 1.11开始,Checkpoint 可以是非对齐的。Unaligned checkpoints 包含 In-flight 数据(例如,存储在缓冲区中的数据)作为 Checkpoint State的一部分,允许 Checkpoint Barrier 跨越这些缓冲区。因此, Checkpoint 时长变得与当前吞吐量无关,因为 Checkpoint Barrier 实际上已经不再嵌入到数据流当中。
如果您的 Checkpointing 由于背压导致周期非常的长,您应该使用非对齐 Checkpoint。这样,Checkpointing 时间基本上就与 端到端延迟无关。请注意,非对齐 Checkpointing 会增加状态存储的 I/O,因此当状态存储的 I/O 是 整个 Checkpointing 过程当中真 正的瓶颈时,您不应当使用非对齐 Checkpointing。
为了启用非对齐 Checkpoint,您可以:
// 启用非对齐 Checkpointenv.getCheckpointConfig().enableUnalignedCheckpoints();
**限制 **
**并发 Checkpoint **
Flink 当前并不支持并发的非对齐 Checkpoint。然而,由于更可预测的和更短的 Checkpointing 时长,可能也根本就不需要并发的 Checkpoint。此外,Savepoint 也不能与非对齐 Checkpoint 同时发生,因此它们将会花费稍长的时间。
与 Watermark 的相互影响
非对齐 Checkpoint 在恢复的过程中改变了关于 Watermark 的一个隐式保证。目前,Flink 确保了 Watermark 作为恢复的第一步, 而不是将最近的 Watermark 存放在 Operator 中,以方便扩缩容。在非对齐 Checkpoint 中,这意味着当恢复时,Flink 会在恢复 In-flight 数据后再生成 Watermark。如果您的 Pipeline 中使用了对每条记录都应用最新的 Watermark 的算子将会相对于 使用对齐 Checkpoint产生不同的结果。如果您的 Operator 依赖于最新的 Watermark 始终可用,解决办法是将 Watermark 存放在 OperatorState 中。在这种情况下,Watermark 应该使用单键 group 存放在 UnionState 以方便扩缩容。
与长时间运行的记录处理相互作用
即使非对齐的检查点,但障碍物能够超过队列中的所有其他记录。如果当前记录需要大量时间来处理,则该屏障的处理仍可能延迟。这种情况可能发生在同时触发多个计时器时,例如在窗口操作中。当处理单个输入记录时,系统被阻止等待多个网络缓冲区可用性时,可能会出现第二种问题。Flink不能中断单个输入记录的处理,未对齐的检查点必须等待当前处理的记录被完全处理。这可能在两种情况下造成问题。由于串行化了一个不适合单个网络缓冲区的大记录,或者在flatMap操作中,一个输入记录产生了多个输出记录。在这种情况下,背压可以阻止未对齐的检查点,直到处理单个输入记录所需的所有网络缓冲区都可用。在处理单个记录需要一段时间的任何其他情况下,也可能发生这种情况。因此,检查点的时间可能比预期的要长,也可能会有所不同。
某些数据分布模式没有检查点
有一部分包含属性的的连接无法与 Channel 中的数据一样保存在 Checkpoint 中。为了保留这些特性并且确保没有状态冲突或 非预期的行为,非对齐 Checkpoint 对于这些类型的连接是禁用的。所有其他的交换仍然执行非对齐 Checkpoint。
点对点连接
我们目前没有任何对于点对点连接中有关数据有序性的强保证。然而,由于数据已经被以前置的 Source 或是 KeyBy 相同的方式隐式 组织,一些用户会依靠这种特性在提供的有序性保证的同时将计算敏感型的任务划分为更小的块。
只要并行度不变,非对齐 Checkpoint(UC) 将会保留这些特性。但是如果加上UC的伸缩容,这些特性将会被改变。
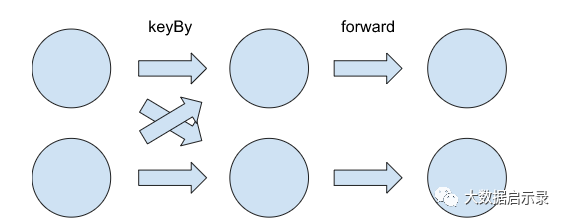
如果我们想将并行度从 p=2 扩容到 p=3,那么需要根据 KeyGroup 将 KeyBy 的 Channel 中的数据突然的划分到3个 Channel 中去。这 很容易做到,通过使用 Operator 的 KeyGroup 范围和确定记录属于某个 Key(group) 的方法(不管实际使用的是什么方法)。对于 Forward 的 Channel,我们根本没有 KeyContext。Forward Channel 里也没有任何记录被分配了任何 KeyGroup;也无法计算它,因为无法保证 Key仍然存在。
广播 Connections
广播 Connection 带来了另一个问题。无法保证所有 Channel 中的记录都以相同的速率被消费。这可能导致某些 Task 已经应用了与 特定广播事件对应的状态变更,而其他任务则没有,如图所示。
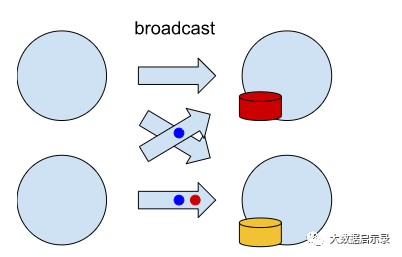
广播分区通常用于实现广播状态,它应该跨所有 Operator 都相同。Flink 实现广播状态,通过仅 Checkpointing 有状态算子的 SubTask 0 中状态的单份副本。在恢复时,我们将该份副本发往所有的 Operator。因此,可能会发生以下情况:某个算子将很快从它的 Checkpointed Channel 消费数据并将修改应有于记录来获得状态。

版权归原作者 大数据启示录 所有, 如有侵权,请联系我们删除。