
全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的
接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。

REST API:天然的跨平台。
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
官方中文(未更新):https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html
一、基本概念
Index(索引)、Type(类型)、Document(文档)
类比于MySQL,即对应Database(数据库)、Table(表)、record(记录)。
换句话说,比如:
保存了某个索引下,某种类型的一个文档。
相当于MySQL中,保存在某个数据库下,某张表的一条记录。
只不过保存的形式有所不同,MySQL是行和列形式组成的表,ES是JSON格式的。
当然了,如果Index作为动词,还额外指添加,相当于insert。
区别于MySQL这类关系型数据库,ES更大的特点是:**倒排索引机制 **
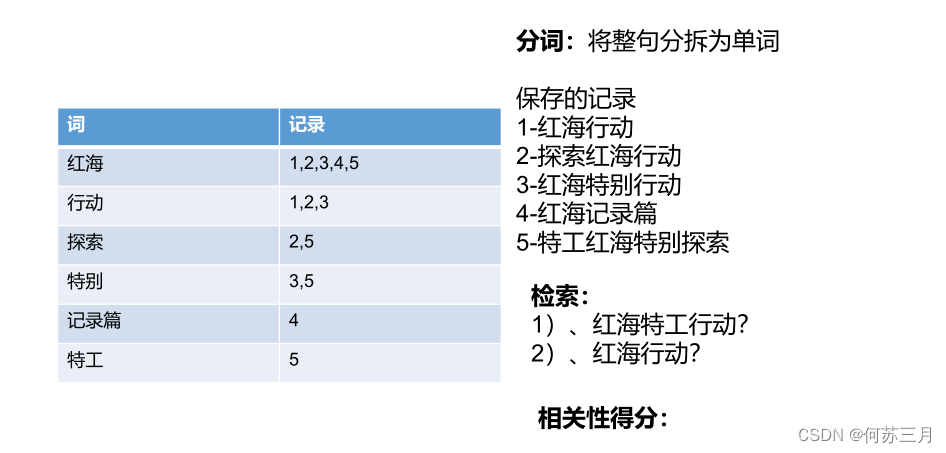
比如这里,我们保存的5条记录(也就是文档)
它在ES内部,其实每条记录都是将整句拆分为若干单词的。
比如:
第一条 红海行动(假如id为1),被拆分成了红海和行动两个词,然后这两个词都记录了当前id值。
以此类推
当我们检索比如红海特工行动的时候,他就会去找对应的分词
二、Docker 安装 Es
1 、下载镜像文件
存储和检索数据
docker pull kibana:7.4.2
可视化检索数据
docker pull kibana:7.4.2
2 、创建实例并运行
提前创建文件夹
用于挂在es,避免每次修改、查看配置文件都要进入到容器内部,而且容器一般都是最小的linux内核,很多功能都没有,也不方便操作,非常不推荐在容器内安装大量插件来操作。
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
保证/mydata/elasticsearch/文件夹中的文件都具有可读可写的权限
chmod -R 777 /mydata/elasticsearch/
配置任意机器可以访问 elasticsearch,默认只能本地访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
创建实例并运行
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx256m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
-p 9200:9200 -p 9300:9300:向外暴露两个端口,9200用于HTTP REST API请求,9300 ES 在分布式集群状态下 ES 之间的通信端口;-e "discovery.type=single-node":es 以单节点运行-e ES_JAVA_OPTS="-Xms64m -Xmx512m":设置启动占用内存,不设置可能会占用当前系统所有内存- -v:挂载容器中的配置文件、数据文件、插件数据到本机的文件夹;
-d elasticsearch:7.6.2:指定要启动的镜像特别注意:
-e ES_JAVA_OPTS="-Xms64m -Xmx256m" \ 测试环境下,设置 ES 的初始内存和最大内存,否则导致过大启动不了 ES
可以查看当前系统的内存占用情况,酌情设置es内存
free -m
访问 IP:9200 看到返回的 json 数据说明启动成功
{
"name" : "9ebe5e1ad810",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "QezTwLWMRTi9PT7j11XtSg",
"version" : {
"number" : "7.4.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date" : "2019-10-28T20:40:44.881551Z",
"build_snapshot" : false,
"lucene_version" : "8.2.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
无法访问说明:
若当前在云服务器中,还需要设置防火墙规则,打开9200端口。
若docker ps 未发现运行的docker
那么我们再次重启一下,docker start 镜像名
启动运行可视化工具Kibana
docker run --name kibana \
-e ELASTICSEARCH_HOSTS=http://你的服务器ip:9200 \
-p 5601:5601 \
-d kibana:7.4.2
同样,如果是云服务器,则需要开启5601端口
访问:ip:5601,出现如下页面则成功
访问可能比较慢,需要耐心等待,一般不会超过3分钟
三、初步 检索
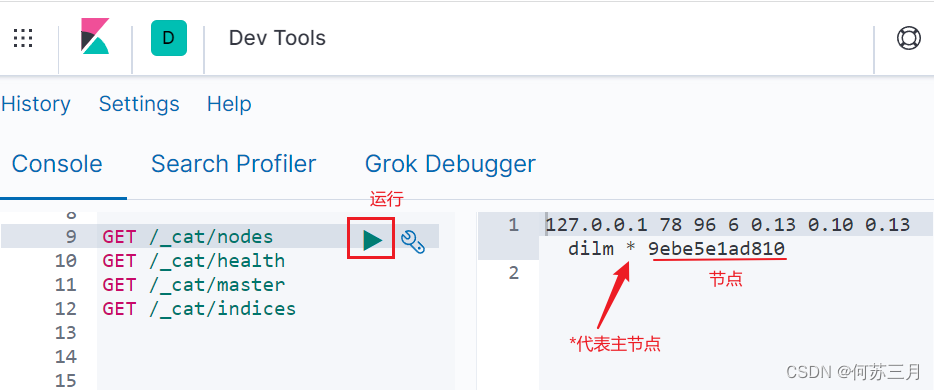
1 、_ cat
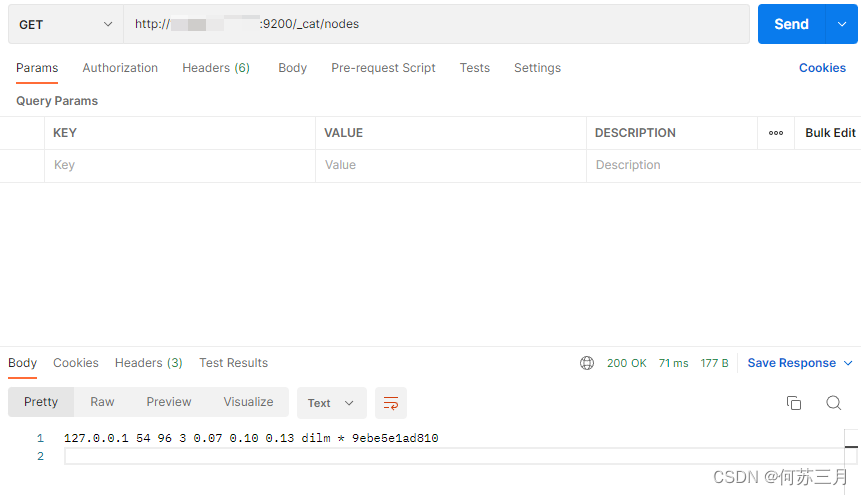
GET /_cat/nodes - 查看所有节点
GET /_cat/health - 查看 es 健康状况
GET /_cat/master - 查看主节点
GET /_cat/indices - 查看所有索引 show databases;
kibana测试:
 postman测试:
postman测试:
2 、保存一个文档(含更新)
put方法:
PUT customer/external/1
{"name": "zhangsan"}
post方法:
POST customer/external/1
{"name": "zhangsan"}
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 5,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1
}
两者的异同:
put方法必须传id,第一次传为新增,其后为修改,并且版本号会跟着增加
post方法可传可不传id,传id同put方法,不传id则自动生成随机id,随意永远都是新增
3、查询一个文档
GET customer/external/1
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 5,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "wangwu"
}
}
4、更新文档:拼接参数
拼接?if_seq_no=5&if_primary_term=1
可以防止修改时出现并发修改问题,实现机制是乐观锁
POST /customer/external/1?if_seq_no=5&if_primary_term=1
{"name":"user1-modify"}
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 6,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1
}
POST /customer/external/1?if_seq_no=5&if_primary_term=1
{"name":"user2-modify"}
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [5], primary term [1]. current document has seqNo [6] and primary term [1]",
"index_uuid": "z45xbsd2RqiGpbjD9Etwww",
"shard": "0",
"index": "customer"
}
],
"type": "version_conflict_engine_exception",
"reason": "[1]: version conflict, required seqNo [5], primary term [1]. current document has seqNo [6] and primary term [1]",
"index_uuid": "z45xbsd2RqiGpbjD9Etwww",
"shard": "0",
"index": "customer"
},
"status": 409
}
5、更新一个文档:/_update
POST customer/external/1/_update
{
"doc":{"name": "John Doew" }}
{
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 6,
"result" : "noop",
"_shards" : {
"total" : 0,
"successful" : 0,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1
}
这种更新方式是在路径后面再拼接一个_update
不过传参数的时候要将数据放在"doc":{数据}中
当我们传递的参数和原来一样,那么result会显示noop,即和原数据比较没有改变,就不会执行,那么序列号版本号都不会增加
6、删除文档或索引
DELETE customer/external/1
DELETE customer
删除,要么删除文档,要么删除索引
不能够删除类型
想要删除类型,只能说把类型里面的数据都删除掉
7、批量操作
批量添加
POST customer/external/_bulk
{"index":{"_id":"1"}}
{"name": "John Doe" }
{"index":{"_id":"2"}}
{"name": "Jane Doe" }
{"index":{"_id":"3"}}
{"name": "Mayun" }
此处的index就是作为动词的意思:添加
{
"took" : 9,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "customer",
"_type" : "external",
"_id" : "1",
"_version" : 8,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 1,
"status" : 200
}
},
{
"index" : {
"_index" : "customer",
"_type" : "external",
"_id" : "2",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 10,
"_primary_term" : 1,
"status" : 200
}
},
{
"index" : {
"_index" : "customer",
"_type" : "external",
"_id" : "3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 11,
"_primary_term" : 1,
"status" : 201
}
}
]
}
批量操作
POST /_bulk
{ "delete": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "create": { "_index": "website", "_type": "blog", "_id": "123" }}
{ "title": "My first blog post" }
{ "index": { "_index": "website", "_type": "blog" }}
{ "title": "My second blog post" }
{ "update": { "_index": "website", "_type": "blog", "_id": "123"} }
{ "doc" : {"title" : "My updated blog post"} }
删除website索引下的blog类型的id为123的文档
创建一个website索引的blog类型,id为123的文档,内容为 "title": "My first blog post"
创建一个website索引的blog类型,id为123的文档,内容为 "title": "My second blog post"
ps:这两个作用是一样的,create 和index都行
修改website索引下的blog类型的id为123的文档,修改的内容为:"title" : "My updated blog post"
注意:中间不能空行,否则空行后的不会执行
{
"took" : 13,
"errors" : false,
"items" : [
{
"delete" : {
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 5,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 5,
"_primary_term" : 1,
"status" : 404
}
},
{
"create" : {
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 6,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "website",
"_type" : "blog",
"_id" : "8qXpnoQBv9MLLpUzeND_",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 7,
"_primary_term" : 1,
"status" : 201
}
},
{
"update" : {
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 8,
"_primary_term" : 1,
"status" : 200
}
}
]
}
8、样本测试数据
我准备了一份顾客银行账户信息的虚构的 JSON 文档样本。每个文档都有下列的 schema
(模式)
Elasticsearch样本测试数据 · hssy/common-resource - Gitee.com
POST bank/account/_bulk
此处复制过来测试数据
准备后续进阶检索!
版权归原作者 何苏三月 所有, 如有侵权,请联系我们删除。