


「目的描述」

此篇文章目的是使用Python语言对启用Kerberos、High Availability的HDFS文件系统进行访问,主要介绍KerberosClient、pyarrow、hdfs3三种方式。


「环境说明」

Python运行环境为3.7.0
集群环境为CDH6.2.1(已启用Kerberos认证)
Namenode实例所在机器分别为cm111、cm112
废话不多说,直接上代码

1、HdfsCli方式

代码示例
from hdfs.ext.kerberos import KerberosClient
from krbcontext import krbcontext
keytab_file = "/root/hdfs.keytab"
principal = "hdfs/[email protected]"
with krbcontext(using_keytab=True, keytab_file=keytab_file, principal=principal, ccache_file="/tmp/cache_keytab_zds"):
client = KerberosClient(url="http://192.168.242.112:9870;http://192.168.242.111:9870")
hdfs_save_path = "/tmp/nuannuaanwqg"
#client.makedirs(hdfs_save_path)
print("hdfs中的目录为:", client.list(hdfs_path="/", status=True))
if __name__ == '__main__':
krbcontext()
所需条件
提供keytab票据及主体名称即可
参考链接
https://hdfscli.readthedocs.io/en/latest/api.html

2、PyArrow方式



「简要说明」

Apache Arrow是内存分析的开发平台。它包含一组技术,使大数据系统能够快速存储、处理和移动数据。Arrow Python是其一个分支。
Arrow Python 绑定(也称为“PyArrow”) 与NumPy、panda和内置Python对象具有一流的集成。它们基于Arrow的C++实现。
代码示例
#!/bin/python3.7.0
from pyarrow import fs
import os
import subprocess
def run_cmd(args_list):
"""
run linux commands
"""
# import subprocess
print('Running system command: {0}'.format(' '.join(args_list)))
proc = subprocess.Popen(args_list, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
s_output, s_err = proc.communicate()
s_return = proc.returncode
return s_return, s_output, s_err
if __name__ == '__main__':
(ret, out, err)= run_cmd(['/root/test/pythonD/CDH-6.2.1-1.cdh6.2.1.p0.1425774/bin/hadoop','classpath','--glob'])
lines = bytes.decode(out).split('\n')
for path in lines:
CLASSPATH = path
break
CLASSPATH = "/root/test/pythonD/conf/cm111/conf:{CLASSPATH}".format(CLASSPATH=CLASSPATH)
os.environ['CLASSPATH'] = CLASSPATH
os.environ['ARROW_LIBHDFS_DIR'] = '/root/test/pythonD/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib64/'
hdfs_host = 'nameservice1'
hdfs_port = 0
USER= 'hdfs/[email protected]'
KERB_TICKET = '/root/test/pythonD/pyarrow/krb5cc_0'
args = {
'host': hdfs_host,
'user': USER, #可选,此处与kerb_ticket一起使用,如果不选择则选择客户端上默认激活的用户
'kerb_ticket': KERB_TICKET, #可选,描述同上
'port': 8020,
}
fs2 = fs.HadoopFileSystem(**args)
print(fs2)
fs2.create_dir("/tmp/pyarrow_testa")
所需条件
①parcels目录下的依赖包(需要将parcels下的目录拷贝到脚本所在机器)
②Kerberos的缓存文件(非必须项,不使用缓存文件时,需要将user及kerb_ticket两个参数去掉,这样就默认使用本地激活的票据了)
③hadoop conf文件目录(使用HA模式方式HDFS需要)
④兼容的Java环境(因为此原因Kerberos验证不通过,会直接报权限不足异常。卡了很久,特此记录一下)
参考链接
https://arrow.apache.org/docs/python/generated/pyarrow.fs.HadoopFileSystem.html

3、HDFS3方式



「简要说明」

Pivotal生产了libhdfs3,这是一种替代的本机C/C++HDFS客户端,它在没有JVM的情况下与HDFS交互,向Python等非JVM语言提供了一流的支持。
这个名为hdfs3的库是围绕C/C++libhdfs3库的轻量级Python包装器。它提供了从Python直接访问libhdfs3以及一个典型的Pythonic接口。
代码示例
from hdfs3 import HDFileSystem
host = "nameservice1"
conf = {"dfs.nameservices": "nameservice1",
"dfs.ha.namenodes.nameservice1": "namenode29,namenode32",
"dfs.namenode.rpc-address.nameservice1.namenode29": "cm111:8020",
"dfs.namenode.rpc-address.nameservice1.namenode32": "cm112:8020",
"dfs.namenode.http-address.nameservice1.namenode29": "cm111:9870",
"dfs.namenode.http-address.nameservice1.namenode32": "cm112:9870",
"hadoop.security.authentication": "kerberos"
}
fs = HDFileSystem(host=host, pars=conf)
list_pat = fs.ls("/", detail=False)
print(list_pat)
hdfs3方式使用代码其实很简单,但是环境的依赖却是耗费了我好长时间。
下面是无法联网情况下如何使用这种方式访问HDFS。
这里我选择使用conda工具,目前可以大致确认通过pip无法实现。
(因为pip只能安装python相关的库,无法安装c++相关的依赖(如libhdfs3),有个方式是针对源码进行重新编译,由于测试过程中对c++不了解,且按照示例步骤一直失败,看不出原因这里就不再尝试)。
Conda离线使用hdfs3访问hdfs步骤如下:
① 离线安装conda,步骤如第五篇章
② 在有网的机器进行安装,新建新的空间名称,再紧接着安装hdfs3模块
执行命令如下
conda create --name offline python=3.7.6
conda install hdfs3 -c conda-forge
③ 验证执行python是否可以成功
Python xxx.py(可能联网机器无法访问目标集群这步可省略)
④ 如成功则进入conda安装的路径(联网机器下)
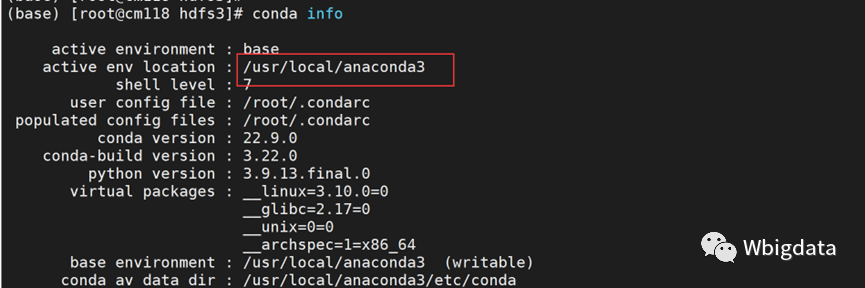
conda info 命令可以查看安装路径
显示中的active env location 一行信息可知,我这里是/usr/local/anaconda3
⑤ 进入envs目录
cd /usr/local/anaconda3/envs
压缩offline 路径
tar -zcf offline.tar.gz offline/
⑥ 将offline.tar.gz 包上传到断网机器并解压到conda安装路径下的envs目录下
tar -zxf offline.tar.gz -C /usr/local/anaconda3/envs/
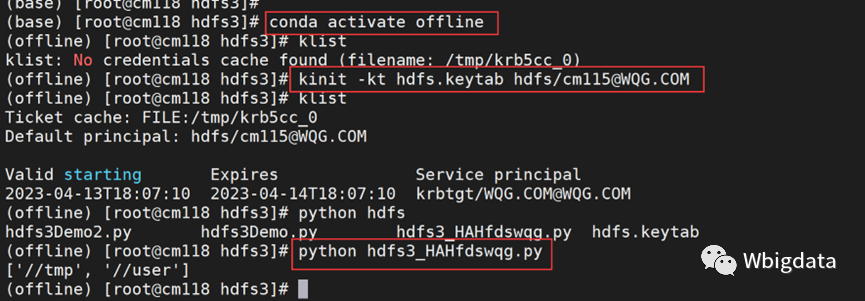
⑦ 在不联网机器中执行以下命令
conda activate offline #切换conda环境
kinit -kt hdfs.keytab hdfs/[email protected] #激活票据
⑧ 再执行python xxx.py,显示如下图即为成功
所需条件
①、安装Anaconda3(非必须项,但是通过其他方式会遇到各种问题,其安装使用步骤见第四篇章)
②、部署Kerberos客户端,并激活有权限的票据(我这里是使用hdfs.keytab)。
③、配置/etc/hadoop/conf/路径,里面的配置要求与要访问的目标集群配置文件一致。
④、兼容的java环境(不兼容会导致Kerberos认证失败)。

Anaconda3安装使用(联网情况)

1、下载Anaconda3(选择linux版本即可)
下载地址
https://www.anaconda.com/products/distribution#Downloads
2、安装所需依赖,否则后续会出现异常
yum install -y bzip2
3、直接执行安装脚本,按照提示一步步选择y或回车即可
bash Anaconda3-2022.10-Linux-x86_64.sh
4、添加镜像,为了安装HDFS3模块更快
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/bioconda/
5、创建wqgdemo环境并且安装python3.7
conda create --name wqgdemo python=3.7
6、切换到wqgdemo环境
conda activate wqgdemo
7、安装HDFS3模块
conda install hdfs3 -c conda-forge
8、此时准备工作已完成,直接执行第三篇章的python脚本即可
python hdfs3_HAHfds.py
注:此时python版本为Python 3.7.1非本地默认的2.7.5

Anaconda3安装使用(断网情况)

一般生产环境都是不允许联网的。
1、下载Anaconda3(选择linux版本即可)
下载地址
https://www.anaconda.com/products/distribution#Downloads
2、安装所需依赖,否则后续会出现异常
yum install -y bzip2
3、直接执行安装脚本,按照提示一步步选择y或回车即可
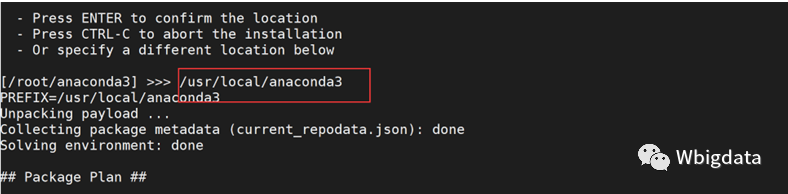
bash Anaconda3-2022.10-Linux-x86_64.sh
此步骤详细截图如下
然后shell退出重新连接
4、使用conda -V正常显示即可成功

版权归原作者 沧海寄馀生 所有, 如有侵权,请联系我们删除。