
文章目录
1 简介
本篇将会解决以下5个问题
- hadoop-hive-spark-scala-java-mysql版本匹配
- hive-spark源码编译
- hive 安装并配置mysql作为metastore外存数据库
- spark连接hive外部包导入
- spark读写hive表程序
2 版本匹配
点击相应链接跳转至相应archive仓库
hadoop-2.7.1
hive 1.2.2
spark 2.1.0
scala 2.11.8
mysql 5.7.23 - jdbc-connector-5.1.40
3 spark hive支持版本源码编译
完整版教程在这里
3.1 spark-src下载
spark源码在此下载
3.2 maven换源
由于使用spark内置maven编译,需要添加国内镜像进行换源处理,能够加快速度;寻找该文件夹
>${SPARK_HOME}/build/apache-maven-3.3.9/conf/settings.xml
在镜像mirrors标签下添加
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror>
换源到alimaven
3.3 spark编译
接下来,编辑/etc/profile文件,输出HADOOP_HOME系统环境变量,这个环境变量在build过程中需要系统能够访问
>vim /etc/profile
-----------
#HADOOP_HOMEexportHADOOP_HOME=/Users/collinsliu/hadoop-2.7.1/
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
------------
>source /etc/profile
> hadoop version
最后,在终端中输入
./dev/make-distribution.sh --tgz--name h27hive -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.1 -Phive -Phive-thriftserver -DskipTests
进行spark-hive build操作
4 hive 安装与mysql-metastore配置
hive安装需要进行以下5个步骤
- MySQL5.1.27 DMG版本下载并安装, jdbc-connector5.1.40下载
- hive编写hive-site.xml|hive-env.sh, jdbc-connector复制到hive/lib文件夹下
- mysql建立metastore表格,hive初始化并成功连接mysql-metastore
- spark编写spark-env.sh包含hadoop|hive|scala路径
- hive-site.xml|core-site.xml|hdfs-site.xml 复制到spark/conf文件夹下
具体步骤参见这里
注: 教程中使用hive-1.2.1,由于apache-hive官方访问源更新,因此我们使用hive-1.2.2仍旧能够兼容
4.1 mysql下载安装
在mac电脑上,我们需要选择mysql 5.7.23 DAG版本,然后直接以app形式进行安装即可
需要注意的是,此种方式下mysql会以服务的方式安装在电脑中,因此我们需要卸载掉之前可能安装着的mysql版本。
4.1.1 为mysql设置系统环境变量
如果mysql指令未被系统识别,我们需要手动添加系统环境变量
>vim /etc/profile
----------
#MYSQL_HOMEexportMYSQL_HOME=/usr/local/mysql
exportPATH=$PATH:$MYSQL_HOME/bin
----------
>source /etc/profile
然后,我们便可以使用
> mysql -uroot-p
进行初次登陆
4.1.2 初次登陆更改root身份密码
在安装最后,系统会自动生成root管理员角色的密码
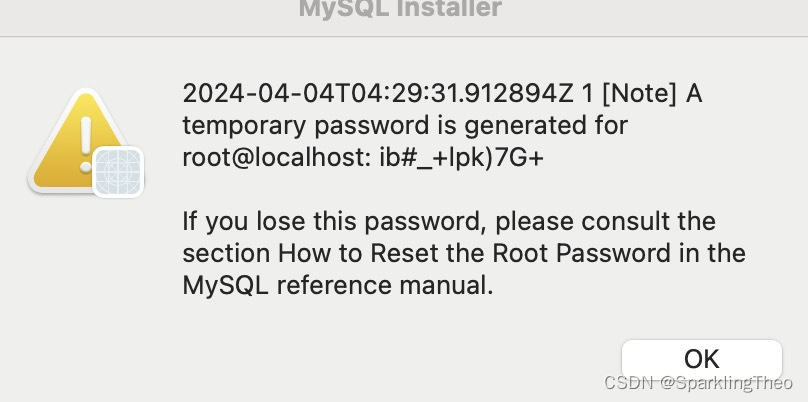
我们如果记录下来,安装后首次登陆后可以采用如下指令:
ALTER USER'root'@'localhost' IDENTIFIED BY '新密码';
在登陆入mysql后更改密码
4.1.3 安装后直接更改密码
在安装后,如果我们没有记录系统生成的初始密码,可以采用如下方式
> mysqladmin -u root passwrod 新密码
暴力修改密码
4.2 hive初始化
4.2.1 编写hive-site.xml文件
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- jdbc 连接的 URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value></property><!-- jdbc 连接的 Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc 连接的 username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc 连接的 password --><property><name>javax.jdo.option.ConnectionPassword</name><value>password</value></property><!-- Hive 元数据存储版本的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property><!--元数据存储授权--><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value></property><property><name>hive.exec.scratchdir</name><value>hdfs://localhost:9000/hive/opt</value></property><!-- Hive 默认在 HDFS 的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- 指定 hiveserver2 连接的 host --><property><name>hive.server2.thrift.bind.host</name>4
<value>localhost</value></property><!-- 指定 hiveserver2 连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><!-- 指定本地模式执行任务,提高性能 --><property><name>hive.exec.mode.local.auto</name><value>true</value></property></configuration>
4.2.2 编写hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directoryexportHADOOP_HOME=/Users/collinsliu/hadoop-2.7.1/
# Hive Configuration Directory can be controlled by:exportHIVE_CONF_DIR=/Users/collinsliu/hive-1.2.2/conf
4.2.3 初始化hive-metastore
>cd${hive_home}/bin
> ./schematool -dbType mysql -initSchema
4.2.4 复制jdbc-connector依赖包
jdbc-connector复制到 ${hive_home}/lib文件夹下
4.3 编写spark-env.sh
exportJAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_311.jdk/Contents/Home
exportSCALA_HOME=/Users/collinsliu/scala-2.11.8
exportHIVE_CONF_DIR=/Users/collinsliu/hive-1.2.2/conf
exportHADOOP_CONF_DIR=/Users/collinsliu/hadoop-2.7.1/etc/hadoop
exportSPARK_DIST_CLASSPATH=$(/Users/collinsliu/hadoop-2.7.1/bin/hadoop classpath)exportCLASSPATH=$CLASSPATH:/Users/collinsliu/hive-1.2.2/lib
exportSPARK_CLASSPATH=$SPARK_CLASSPATH:/Users/collinsliu/hive-1.2.2/lib/mysql-connector-java-5.1.40.jar
4.4 完善配置
hive-site.xml|core-site.xml|hdfs-site.xml 复制到${spark_home}/conf文件夹下
5 hive-spark连接与编程
相关项目以及pom文件配置可以参见我的这个代码仓库
配置项目时如果出现包导入错误,可以参见我的这篇文章
版权归原作者 SparklingTheo 所有, 如有侵权,请联系我们删除。