
在数据仓库设计中,数据模型的选择是一个关键的决策。在维度建模中,通常采用星型模型(Star Schema)或雪花模型(Snowflake Schema)来组织事实表和维度表。
星型模型和雪花模型是两种常见的维度建模的模型,它们在数据组织和查询性能方面有所差异。本文将深入探讨这两种模型的特点、优缺点以及选择的考虑因素
星型模型将事实表放置在中心,周围围绕着多个维度表,形成星型结构;而雪花模型在星型模型的基础上进一步规范化维度表,使得维度表之间形成更多层级的关系,类似雪花的结构。
星型模型(Star Schema)和雪花模型(Snowflake Schema)是数据仓库中常用的两种维度模型,用于组织事实表和维度表之间的关系。它们的主要区别在于维度表的规范化程度。
星型模型(Star Schema)
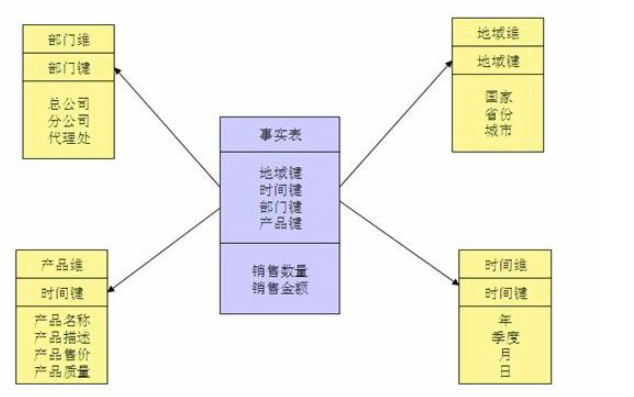
结构:星型模型由一个中心的事实表(Fact Table)和多个周围的维度表(Dimension Table)组成,形成了类似星星的结构,因此得名。
特点:事实表包含了业务过程中发生的事实数据,维度表包含了描述业务过程的各种维度信息。事实表和维度表之间通过一对多的关系进行连接。
优势:星型模型结构简单,易于理解和使用,适用于大多数数据分析场景。查询性能较好,适合快速查询和报表生成。
缺点:可能存在数据冗余,因为维度表中的数据可能在事实表中重复出现,导致存储空间的浪费。同时,维度表之间的关系比较简单,不适合描述复杂的维度层次结构。
雪花模型(Snowflake Schema):
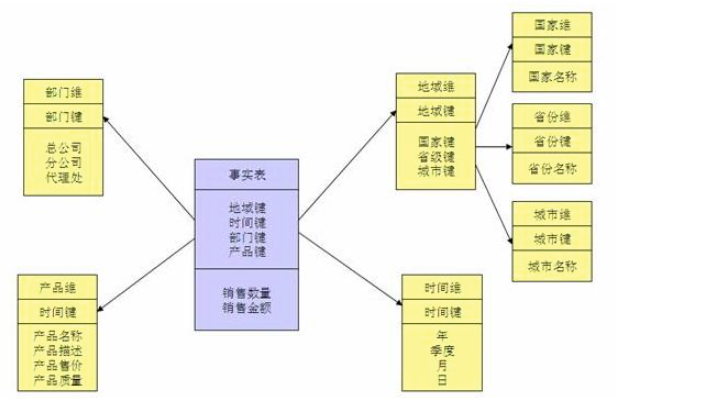
结构:雪花模型在星型模型的基础上进一步规范化维度表,将维度表中的数据分解成更多的表,形成类似雪花的结构。
特点:雪花模型通过规范化维度表,减少了数据冗余,提高了数据存储的效率。同时,可以更好地描述复杂的维度层次结构。
优势:雪花模型在节省存储空间的同时,仍保持了较好的查询性能,适合需要更详细的维度信息和更复杂的维度结构的场景。
缺点:雪花模型相对于星型模型来说,结构更加复杂,设计和维护成本较高。同时,多层次的连接可能会影响查询性能。
星座模型
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。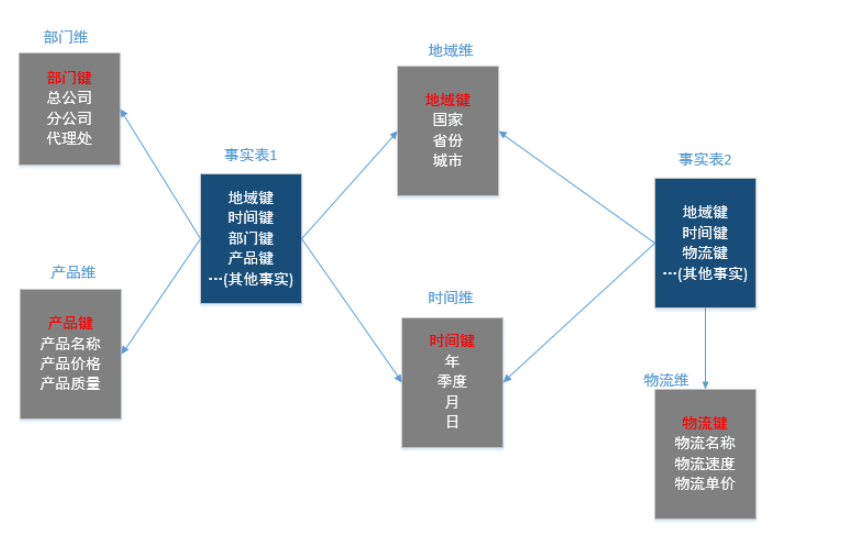
可以认为是多个事实表的关联或者是星型模型的关联,其实到了业务发展后期都是星座模型
选择考虑因素
在选择星型模型或雪花模型时,需要考虑以下因素:
- 数据复杂性:如果业务需求较简单,维度层次不复杂,可以选择星型模型。如果业务需求复杂,维度层次较多,可以选择雪花模型。
- 查询性能要求:如果对查询性能有较高的要求,可以选择星型模型。如果对存储空间有较高的要求,可以选择雪花模型。
- 可维护性和扩展性:如果需要频繁变更或扩展维度,可以选择雪花模型。如果数据模型相对稳定,变更频率较低,可以选择星型模型。
星型模型和雪花模型的优劣对比:
属性星型模型雪花模型数据总量多少可读性容易差表个数少多查询速度快慢冗余度高低对实时表的情况增加宽度字段比较少,冗余底扩展性差好星型模型的设计方式主要带来的好处是能够提升查询效率,因为生成的事实表已经经过预处理,主要的数据都在事实表里面,所以只要扫描实时表就能够进行大量的查询,而不必进行大量的join,其次维表数据一般比较少,在join可直接放入内存进行join以提升效率,除此之外,星型模型的事实表可读性比较好,不用关联多个表就能获取大部分核心信息,设计维护相对比较简单。
雪花模型的设计方式是比较符合数据库范式的理念,设计方式比较正规,数据冗余少,但在查询的时候可能需要join多张表从而导致查询效率下降,此外规范化操作在后期维护比较复杂
总结
综上所述,星型模型适用于简单的分析需求和对查询性能有较高要求的场景,而雪花模型适用于复杂的业务需求和对存储空间和灵活性有较高要求的场景。
可以发现数据仓库大多数时候是比较适合使用星型模型构建底层数据Hive表,通过大量的冗余来提升查询效率,星型模型对OLAP的分析引擎支持比较友好,这一点在Kylin中比较能体现。
而雪花模型在关系型数据库中如MySQL、Oracle中非常常见,尤其像电商的数据库表。在数据仓库中雪花模型的应用场景比较少,但也不是没有,所以在具体设计的时候,可以考虑是不是能结合两者的优点参与设计,以此达到设计的最优化目的
在大多数情况下,星型模型是一个简单而有效的选择,能够满足大部分数据分析和报表需求。而在需要处理复杂维度结构或需要节省存储空间的情况下,雪花模型可能更为合适。
版权归原作者 猫猫姐 所有, 如有侵权,请联系我们删除。