
在本文中将介绍如何使用 KerasTuner,并且还会介绍其他教程中没有的一些技巧,例如单独调整每一层中的参数或与优化器一起调整学习率等。Keras-Tuner 是一个可帮助您优化神经网络并找到接近最优的超参数集的工具,它利用了高级搜索和优化方法,例如 HyperBand 搜索和贝叶斯优化。所以只需要定义搜索空间,Keras-Tuner 将负责繁琐的调优过程,这要比手动的Grid Search强的多!

加载数据
我们这里使用手语数据集,假设想在图像分类数据集上训练 CNN,我们将使用 KerasTuner 优化神经网络。
首先,使用 pip 安装 Keras-Tuner 库并导入必要的库。
!pip install keras-tuner
然后导入需要的包:
import keras_tuner
from tensorflow import keras
from keras import backend as K
from tensorflow.keras import layers, losses
import numpy as np
import matplotlib.pyplot as plt
import os
下面我们就需要加载数据, 我们选择使用美国手语 (ASL) 数据集,该数据集可在 Kaggle 上下载。它包含代表手语的 400x400 RGB 手势图像。它共有 37 个类,每个类有 70 张图像。我们将训练一个 CNN 模型来对这些手势进行分类。

由于数据集已经基于类在文件夹目录进行了分类,加载数据集的最简单方法是使用 keras.utils.image_dataset_from_directory。使用 directory 参数指定父目录路径,并使用 labels='inferred' 自动加载基于文件夹名称的标签。使用 label_mode='categorical' 可以将标签作为 one-hot 向量加载,这样我们加载数据就别的非常简单了。
BATCH_SIZE = 64
train_data = keras.utils.image_dataset_from_directory(
directory="../input/asl-dataset/asl_dataset",
labels= 'inferred',
label_mode='categorical',
color_mode='rgb',
batch_size=BATCH_SIZE,
seed=777,
shuffle=True,
image_size=(400, 400) )
现在就可以使用下面的函数将 tf.data.dataset 项拆分为 train-val-test 集。我们数使用 0.7–0.15–0.15 拆分规则。
def split_tf_dataset(ds, train_split=0.8, val_split=0.1, test_split=0.1, shuffle=True, seed=None, shuffle_size=10000):
assert (train_split + test_split + val_split) == 1
# get the dataset size (in batches)
ds_size = len(ds)
if shuffle:
# Specify seed to always have the same split distribution between runs
ds = ds.shuffle(shuffle_size, seed=seed)
train_size = int(train_split * ds_size)
val_size = int(val_split * ds_size)
test_size = int(test_split * ds_size)
train_ds = ds.take(train_size) # Take train_size number of batches
val_ds = ds.skip(train_size).take(val_size) # Ignore the first train_size batches and take the rest val_size batches
test_ds = ds.skip(train_size).skip(val_size).take(test_size)
return train_ds, val_ds, test_ds
train_data, val_data, test_data = split_tf_dataset(train_data, 0.7, 0.15, 0.15, True, 777)
print(f"Train dataset has {sum(1 for _ in train_data.unbatch())} elements")
print(f"Val dataset has {sum(1 for _ in val_data.unbatch())} elements")
print(f"Test dataset has {sum(1 for _ in test_data.unbatch())} elements")
数据集加载已完成。让我们进入下一部分
Keras Tuner 基础知识
在使用之前,先简单介绍一下 Keras-Tuner 的工作流程。
build()函数接收keras_tuner的Hyperparameter的对象,这个对象定义了模型体系结构和超参数搜索空间。
为了定义搜索空间,hp对象提供了4个方法。hp.Choice(), hp.Int(), hp.Float()和hp.Boolean()。hp.Choice()方法是最通用的,它接受一个由str、int、float或boolean值组成的列表,但所有值的类型必须相同。
units = hp.Choice(name="neurons", values=[150, 200])
units = hp.Int(name="neurons", min=100, max=200, step=10)
dropout = hp.Int(name="dropout", min=0.0, max=0.3, step=0.05)
shuffle = hp.Boolean("shuffle", default=False)
Keras-Tuner 提供 3 种不同的搜索策略,RandomSearch、贝叶斯优化和 HyperBand。对于所有Tuner都需要指定一个 HyperModel、一个要优化的指标和一个计算预期时间(轮次),以及一个可选的用于保存结果的目录。例如下面的示例
tuner = keras_tuner.Hyperband(
hypermodel=MyHyperModel(),
objective = "val_accuracy", #准确率
max_epochs=50, #每个模型训练50轮
overwrite=True,
directory='hyperband_search_dir', #保存目录
project_name='sign_language_cnn')
然后就可以使用命令启动超参数的搜索了。
tuner.search(x=train_data,
max_trials=50,
validation_data=val_data,
batch_size=BATCH_SIZE)
以上是Keras Tuner的基本工作流程,现在我们把这个流程应用到我们这个示例中
代码实现
首先,我们定义一个继承自 keras_tuner.HyperModel 的 HyperModel 类,并定义 build 和 fit 方法。
通过 build 方法,定义模型的架构并使用 hp 参数来设置超参数搜索空间。
fit 方法接受 hp 参数、将训练数据 x 传递给 keras model.fit() 方法的 *args 和 kwargs。kwargs 需要传递给 model.fit() 因为它包含模型保存的回调和可选的 tensorboard 等回调。
在 HyperModel 类中定义 fit() 方法是因为需要在训练过程中灵活地搜索参数,而不仅仅是在构建过程中。
class MyHyperModel(keras_tuner.HyperModel) :
def build(self, hp, classes=37) :
model = keras.Sequential()
model.add(layers.Input( (400,400,3)))
model.add(layers.Resizing(128, 128, interpolation='bilinear'))
# Whether to include normalization layer
if hp.Boolean("normalize"):
model.add(layers.Normalization())
drop_rate = hp.Float("drop_rate", min_value=0.05, max_value=0.25, step=0.10)
# Number of Conv Layers is up to tuning
for i in range( hp.Int("num_conv", min_value=7, max_value=8, step=1)) :
# Tune hyperparams of each conv layer separately by using f"...{i}"
model.add(layers.Conv2D(filters=hp.Int(name=f"filters_{i}", min_value=20, max_value=50, step=15),
kernel_size= hp.Int(name=f"kernel_{i}", min_value=5, max_value=7, step=2),
strides=1, padding='valid',
activation=hp.Choice(name=f"conv_act_{i}", ["relu","leaky_relu", "sigmoid"] )))
# Batch Norm and Dropout layers as hyperparameters to be searched
if hp.Boolean("batch_norm"):
model.add(layers.BatchNormalization())
if hp.Boolean("dropout"):
model.add(layers.Dropout(drop_rate))
model.add(layers.Flatten())
for i in range(hp.Int("num_dense", min_value=1, max_value=2, step=1)) :
model.add(layers.Dense(units=hp.Choice("neurons", [150, 200]),
activation=hp.Choice("mlp_activ", ['sigmoid', 'relu'])))
if hp.Boolean("batch_norm"):
model.add(layers.BatchNormalization())
if hp.Boolean("dropout"):
model.add(layers.Dropout(drop_rate))
# Last layer
model.add(layers.Dense(classes, activation='softmax'))
# Picking an opimizer and a loss function
model.compile(optimizer=hp.Choice('optim',['adam','adamax']),
loss=hp.Choice("loss",["categorical_crossentropy","kl_divergence"]),
metrics = ['accuracy'])
# A way to optimize the learning rate while also trying different optimizers
learning_rate = hp.Choice('lr', [ 0.03, 0.01, 0.003])
K.set_value(model.optimizer.learning_rate, learning_rate)
return model
def fit(self, hp, model,x, *args, **kwargs) :
return model.fit( x,
*args,
shuffle=hp.Boolean("shuffle"),
**kwargs)
以上网络及参数仅作为示例。可以自定义网络和搜索空间,使其更适合你的应用。让我们详细解释以下代码:
在第 3-5 行中,构建 Keras 模型并添加一个调整大小的层。在第 7-8 行中,使用 hp.Boolean 来评估是否需要添加归一化层,在第 10 行中,为 dropout 定义了不同值。
第 12-17 动态地指定模型应该有多少卷积层,同时为每一层定义不同的超参数空间。将卷积层的数量设置为 7-8,并且在每一层中独立搜索最佳的核数量、内核大小和激活函数。这里是通过使用字符串 name=f”kernel_{i}” 中的索引 i 为循环中的每次迭代使用不同的 name 参数来做到的。这样就有了很大的灵活性,可以极大地扩展搜索空间,但是因为可能的组合可能会变得非常大,需要大量的计算能力。
在循环内使用 name=f”kernel_{i}” 可以为每一层上的每个参数定义不同的搜索空间。
在第 18-22 行中,搜索 conv 块内添加(或不添加)dropout 和批量归一化层。在 28-31 行也做了同样的事情。
在第 24-27 行中,我们添加了一个展平层,然后是可搜索数量的具有不同参数的全连接层,以在每个层中进行优化,类似于第 12-17 行。
在第 36-39 行,对模型进行了编译了,这里优化器也变为了一个可搜索的超参数。因为参数的类型限制所以不能直接传递 keras.optimizer 对象。所以这里将超参数搜索限制为 Keras 字符串别名,例如 keras.optimizers.Adam() -> 'adam' 。
如何调整学习率也并不简单。在第 41-43 行,我们以一种“hacky”的方式来做这件事。下面的代码可以更改优化器的超参数,例如学习率这是 keras Tuner 目前做不到的,我们只能手动完成
lr = hp.Choice('lr', [0.03, 0.01, 0.003])
K.set_value(model.optimizer.learning_rate, learning_rate)
在第 48-53 行,定义了模型类的 fit(self, hp, model,x, *args, **kwargs) 方法。将 hp 定义为参数这样可以在训练过程中调整超参数值。例如,我在每个 epoch 之前对使用了训练数据进行重新打乱,等等
在完成上述代码后,可以通过运行以下代码进行测试
classes = 37
hp = keras_tuner.HyperParameters()
hypermodel = MyHyperModel()
model = hypermodel.build(hp, classes)
hypermodel.fit(hp, model, np.random.rand(BATCH_SIZE, 400, 400,3), np.random.rand(BATCH_SIZE, classes))
进行超参数搜索
这里我们使用了贝叶斯优化策略。它是 AutoML 中使用的最佳搜索方法之一。
传递一个模型对象,将目标设置为希望优化的指标(例如“val_accuracy”、“train_loss”),并使用 max_trials 参数和保存模型的路径定义计算预期轮次。
tuner = keras_tuner.BayesianOptimization(
hypermodel=MyHyperModel(),
objective = "val_accuracy",
max_trials =10, #max candidates to test
overwrite=True,
directory='BO_search_dir',
project_name='sign_language_cnn')
使用下面的命令Keras-Tuner 就会开始工作了。
tuner.search(x=train_data, epochs=10,
validation_data=val_data)
搜索完成后,可以使用 tuner.results_summary(1) 访问结果。可以看到为每个超参数选择了哪个值,以及在训练期间获得的最佳模型的验证分数。
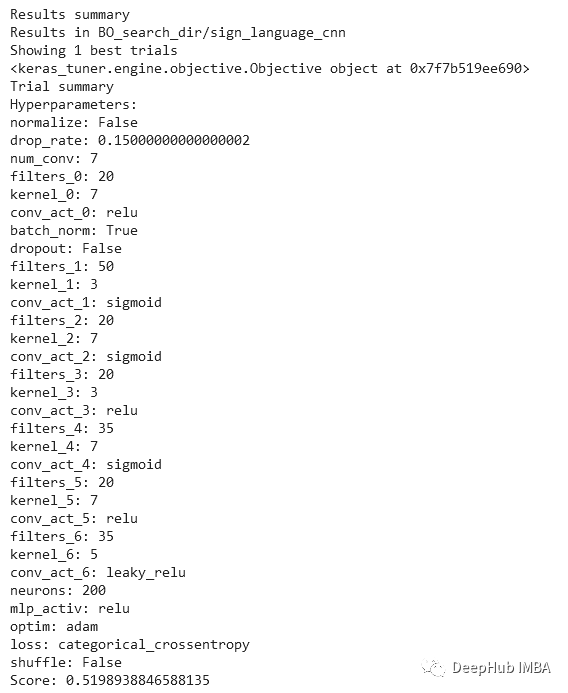
如果要自动提取和构建最佳的模型,请运行以下代码。
best_hps = tuner.get_best_hyperparameters(1)
h_model = MyHyperModel()
model = h_model.build(best_hps[0])
如果您想提取多个模型可以更改 tuner.get_best_hyperparameters(1) 中的数字。
有了模型,我们可以在完整数据集和使用更多 epoch 上训练这个模型。还可以传递回调函数,例如早停、保存最佳模型和学习率调度等等。
from tensorflow.keras.callbacks import EarlyStopping,ReduceLROnPlateau,ModelCheckpoint
def get_callbacks(weights_file, patience, lr_factor):
''' Callbacks used for saving the best weights, early stopping and learning rate scheduling.'''
return [
# Only save the weights that correspond to the maximum validation accuracy.
ModelCheckpoint(filepath= weights_file,
monitor="val_accuracy",
mode="max",
save_best_only=True,
save_weights_only=True),
# If val_loss doesn't improve for a number of epochs set with 'patience' var
# training will stop to avoid overfitting.
EarlyStopping(monitor="val_loss",
mode="min",
patience = patience,
verbose=1),
# Learning rate is reduced by 'lr_factor' if val_loss stagnates
# for a number of epochs set with 'patience/2' var.
ReduceLROnPlateau(monitor="val_loss", mode="min",
factor=lr_factor, min_lr=1e-6, patience=patience//2, verbose=1)]
history = model.fit(x=train_data, validation_data=val_data, epochs=100,
callbacks=get_callbacks('Net_weights.h5',
patience=10,
lr_factor=0.3))
这样就可以训练出完整的模型,训练完成后还可以绘制图表以进行检查并评估测试数据集,还有就是保存模型。
model.load_weights(‘Net_weights.h5’)
model.evaluate(test_data)
model.save(‘Best_model’)
一些小技巧
- 如果数据集非常大并且搜索时间过长,可以在搜索期间仅使用一小部分进行训练,例如 30%。这通常会在很短的时间内提供类似的结果。然后你再在整个集合上重新训练最好的模型。
- 为了加快搜索过程的速度,可以减少训练周期数。虽然这样这可能会降低搜索优化的精度,因为这样倾向于早期表现更好的超参数会进一步进步,但是这样做是可以找到时间和结果精度之间的最佳平衡点。
- 搜索过程中可能出现的一个问题是磁盘空间不足。因为tuner 会自动将所有模型保存在工程目录下,但表现不好的模型不会被动态删除,这将快速占用磁盘空间,尤其是在 Kaggle 或 Google Colab 上运行代码时。开发人员已将其标记为 Keras Tuners 中的增强功能,但还未解决,所以如果磁盘空间不足了,需要考虑限制搜索空间或将搜索拆分为多个较小的搜索。
总结
在本文中我们介绍了 Keras Tuner的使用。并且通过一个完整的项目实现了通过Keras Tuner自动搜索超参数的流程。与手动或网格搜索方法相比,KerasTuner 中实现的搜索策略允许更快、更轻松地进行微调。利用贝叶斯优化或 HyperBand 搜索等搜索方法不仅可以节省时间,还会会得到一个更好的模型。
最后 Keras Tuner官网:
https://keras-team.github.io/keras-tuner/
作者:Poulinakis Kon