
训练神经网络是一个复杂的过程。有许多变量相互配合,通常不清楚什么是有效的。
以下技巧旨在让您更轻松。这不是必须做的清单,但应该被视为一种参考。您了解手头的任务,因此可以从以下技术中进行最佳选择。它们涵盖了广泛的领域:从数据增强到选择超参数;涉及到很多话题。使用此选择作为未来研究的起点。

过拟合单个批次
使用此技术来测试您的网络容量。首先,取一个数据批次,并确保它被正确标记(如果使用了标签)。然后,重复拟合这单个批次,直到损失收敛。如果您没有达到完美的准确度(或类似的指标),您应该查看您的数据。这种情况下使用更大的网络通常不是解决方案。
将 epoch 数量增加一个显着因素
通常,您可以从运行大量步骤的算法中受益。如果您可以土工更长的训练时间,请将 epoch 数从例如 100 扩展到 500。如果您观察到更长训练时间的是有好处,可以在开始时就选择更合理的值。
随机种子
为确保可重复性,请设置任何随机数生成操作的种子。例如,如果您使用 TensorFlow,则可以使用以下代码段:
import os, random
import numpy as np
import tensorflow as tf
def set_seeds(seed: int):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
重新平衡数据集
一个不平衡的数据集有一个或多个主要类别,它们构成了数据集的很大一部分。相反,一个或多个小类仅贡献少量样本。如果您正在处理具有相似特征的数据,请考虑重新平衡您的数据集。推荐的技术是对少数类进行过采样、对主要类进行下采样、收集额外的样本(如果可能)以及生成具有增强功能的人工数据。
使用中性类
考虑以下情况:您有一个包含“Ill”和“not Ill”两个类别的数据集。样本由领域专家手工标记。如果他们中的一个不确定合适的标签,他可能没有或几乎没有信心分配。在这种情况下,引入第三个中性类是个好主意。这个额外的类代表“我不确定”标签。在训练期间,您可以排除此数据。之后,您可以让网络预先标记这些模糊的样本,并将它们展示给领域专家。
设置输出层的偏置
对于不平衡的数据集,网络的初始猜测不可避免地不足。即使网络学会了考虑这一点,在模型创建时设置更好的偏差可以减少训练时间。对于 sigmoid 层,偏差可以计算为(对于两个类):
bias = log(pos/negative)
创建模型时,将此值设置为初始偏差。
物理模拟过拟合
为了模拟流体的运动,人们经常使用特殊的软件。在复杂的相互作用中(例如,水流过不平坦的地面),可能需要很长时间才能看到结果。神经网络在这里可以提供帮助。由于模拟遵循物理定律,任何神奇的事情发生的可能性为零——只需要努力计算结果。网络可以学习这种物理模拟。因为定律是明确定义的,我们“只”要求网络过拟合。我们不希望有任何看不见的测试样本,因为它们必须遵循相同的规则。在这种情况下,过拟合训练数据是有帮助的;通常,甚至不需要测试数据。一旦网络经过训练,我们就用它来代替慢速模拟器。
调整学习率
如果您要寻找任何要调整的超参数,那么主要关注学习率。下图显示了学习率设置过高的影响:
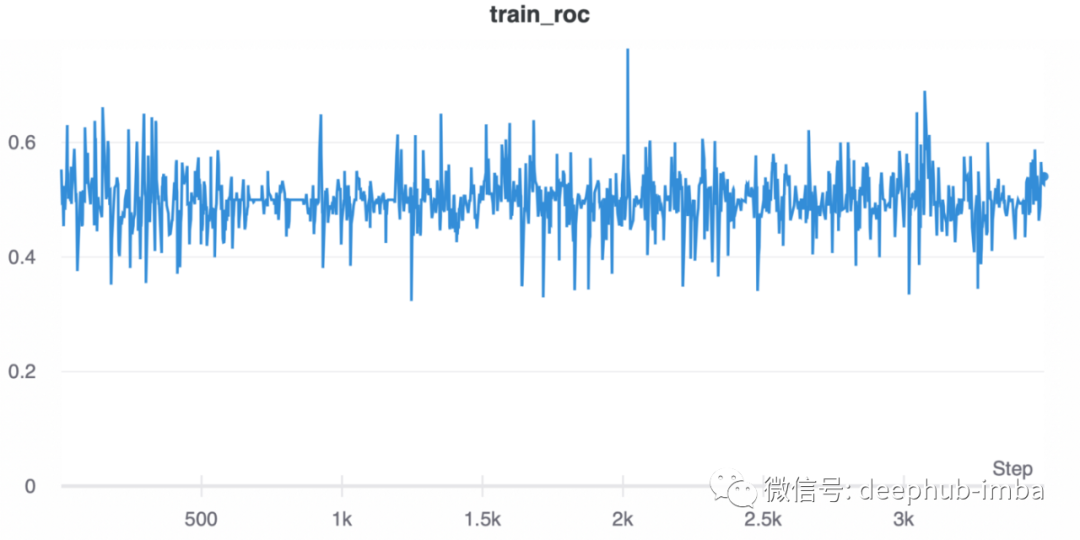
相比之下,使用不同的、较小的学习率,发展如预期:
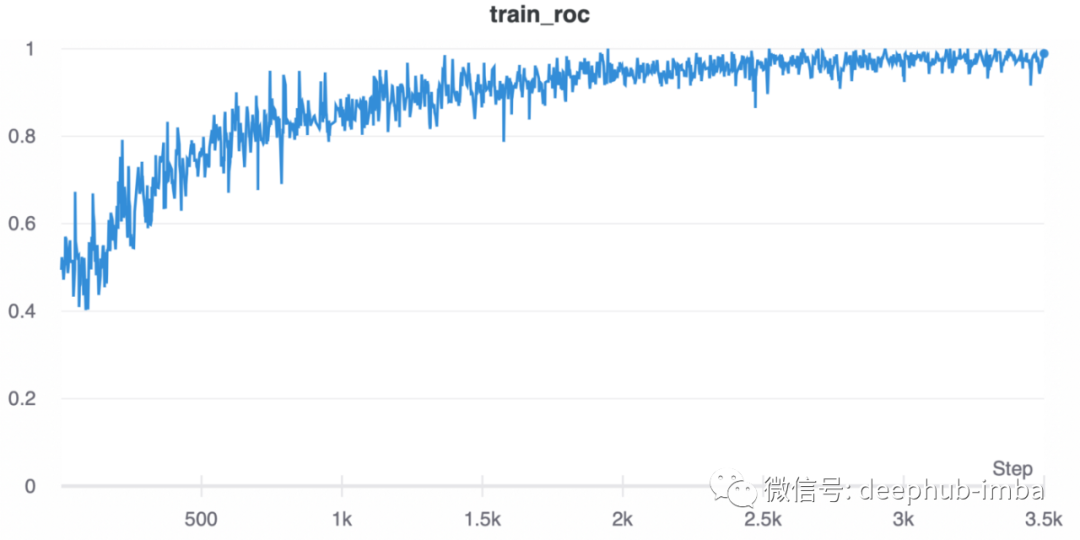
使用快速数据管道
对于小型项目,我经常使用自定义生成器。当我处理较大的项目时,我通常用专用的数据集机制替换它们。对于 TensorFlow,这是 tf.data API。它包括所有必需的方法,如改组、批处理和预取。依靠许多专家编写的代码,而不是自定义解决方案,让我有时间来完成实际任务。
使用数据增强
扩充您的训练数据以创建强大的网络、增加数据集大小或对次要类别进行过采样。这些好处是以增加训练时间为代价的,特别是如果增强是在 CPU 上完成的。如果您可以将其移动到 GPU,您将更快地看到结果。
使用 AutoEncoders 提取嵌入
如果您的标记数据集相对较小,您仍然可以使用一些技巧。其中之一是训练 AutoEncoder。背景是额外收集未标记的数据比标记它们更容易。然后,您可以使用具有足够大的潜在空间(例如,300 到 600 个条目)的 AutoEncoder 来实现相当低的重建损失。要获得实际数据的嵌入,您可以丢弃解码器网络。然后,您可以使用剩余的编码器网络来生成嵌入。是将此解码器添加到主网络还是仅用于提取嵌入由您决定。
使用来自其他模型的嵌入
您可以使用其他模型学习的嵌入,而不是从头开始为您的数据学习嵌入。这种方法与上面提出的技术有关。对于文本数据,下载预训练的嵌入是很常见的。对于图像,您可以使用在 ImageNet 上训练的大型网络。选择一个足够的层,然后剪切所有内容,并将输出用作嵌入。
使用嵌入来缩小数据
假设我们的数据点都具有分类特征。一开始,它可以取两个可能的值,所以一个单热编码有两个索引。但是一旦这增长到 1000 个或更多可能的值,稀疏的 one-hot 编码就不再有效。因为它们可以在低维空间中表示这些数据,所以嵌入在这里很有用。嵌入层采用分类值(在我们的例子中从 0 到 1000)并输出一个浮点向量,即嵌入。这种表示是在训练期间学习的,并作为连续网络层的输入。
使用检查点
没有什么比运行昂贵的训练算法无数个小时然后看到它崩溃更令人沮丧的了。有时,这可能是硬件故障,但通常是代码问题——您只能在训练结束时看到。虽然您永远不能期望只有完美的运行,但您仍然可以通过保存检查点来做好准备。在它们的基本形式中,这些检查点每 k 步存储模型的权重。您还可以扩展它们以保持优化器状态、当前时期和任何其他关键信息。然后,在重新训练时,检查点保证可以从失败时恢复所有必要的设置。这与自定义训练循环结合使用效果非常好。
编写自定义训练循环
在大多数情况下,使用默认的训练例程,例如 TensorFlow 中的 model.fit(...),就足够了。但是,我经常注意到的是灵活性有限。一些小的更改可能很容易合并,但重大的修改很难实施。这就是为什么我通常建议编写自定义算法。起初,这听起来可能令人生畏,但可以使用大量教程来帮助您入门。最初几次遵循此方法时,您可能会暂时放慢速度。但是一旦你有了经验,你就会获得更大的灵活性和理解力。此外,这些知识使您可以快速修改算法,整合您的最新想法。
适当设置超参数
现代 GPU 擅长矩阵运算,这就是它们被广泛用于训练大型网络的原因。通过适当地选择超参数,您可以进一步提高算法的效率。对于 Nvidia GPU(这是当今使用的主要加速器),您可以从使用以下方法开始:
- 选择可被 4 或 2 的更大倍数整除的批次大小
- 对于密集层,将输入(来自前一层)和输出设置为可被 64 或更多整除
- 对于卷积层,将输入和输出通道设置为可被 4 或更大的 2 的倍数整除
- 从 3 (RGB) 到 4 通道填充图像输入
- 使用批量大小 x 高度 x 宽度 x 通道
- 对于递归层,将批次和隐藏大小设置为至少可被 4 整除,理想情况下可被 64、128 或 256 中的任何一个整除
- 对于递归层,使用大批次
这些建议遵循使数据分布更均匀的想法。主要是通过将值选择为 2 的倍数来实现这一点。您设置的这个数字越大,您的硬件运行效率就越高。
使用早停机制
“我什么时候停止训练”这个问题很难回答。可能发生的一种现象是深度双重下降:您的指标在稳步改善后开始恶化。然后,经过一些更新,分数再次提高,甚至比以前更查。为了解决这个问题,您可以使用验证数据集。这个单独的数据集用于衡量您的算法在新的、看不见的数据上的性能。如果性能在一定次数后没有提高,训练将自动停止。对于这个参数。一个好的起始值是 5 到 20 个 epoch。
使用迁移学习
迁移学习背后的想法是利用从业者在大量数据集上训练的模型并将其应用于您的问题。理想情况下,您使用的网络已经针对相同的数据类型(图像、文本、音频)和与您的任务(分类、翻译、检测)类似的任务进行了训练。有两种相关的方法:
微调
微调是采用已经训练好的模型并更新特定问题的权重的任务。通常,您会冻结前几层,因为它们经过训练可以识别基本特征。然后在您的数据集上对其余层进行微调。
特征提取
与微调相反,特征提取描述了一种使用经过训练的网络来提取特征的方法。在预先训练好的模型之上,添加自己的分类器,只更新这部分网络;基层被冻结。您遵循此方法是因为原始 top 是针对特定问题进行训练的,但您的任务可能会有所不同。通过从头开始学习自定义顶部,您可以确保专注于您的数据集——同时保持大型基础模型的优势。
使用数据并行的多 GPU 训练
如果您可以使用多个加速器,则可以通过在多个 GPU 上运行算法来加快训练速度。通常,这是以数据并行的方式完成的:网络在不同的设备上复制,批次被拆分和分发。然后将梯度平均并应用于每个网络副本。在 TensorFlow 中,您有多种关于分布式训练的选择。最简单的选择是使用 MirroredStrategy,但还有更多策略。我注意到从 1 到 2 和从 2 到 3 个 GPU 时的加速效果比较明显。对于大型数据集,这是最小化训练时间的快速方法。
使用 sigmoid 进行多标签设置
在样本可以有多个标签的情况下,您可以使用 sigmoid 激活函数。与 softmax 函数不同,sigmoid 单独应用于每个神经元,这意味着多个神经元可以触发。输出值介于 0 和 1 之间,便于解释。此属性很有用,例如,将样本分类为多个类或检测各种对象。
对分类数据使用 one-hot 编码
由于我们需要数字表示,因此分类数据必须编码为数字。例如,我们不能直接输入字符串格式的数据,而必须使用替代表示。一个诱人的选择是枚举所有可能的值。然而,这种方法意味着在编码为 1 的“bank”和编码为 2 的“tree”之间进行排序。这种排序很少出现,这就是我们依赖单热向量来编码数据的原因。这种方法确保变量是独立的。
对索引使用 one-hot 编码
假设您正在尝试预测天气并索引日期:1 表示星期一,2 表示星期二,等等。但是,因为它只是一个任意索引,我们可以更好地使用 one-hot 编码。与上一个技巧类似,这种表示在索引之间没有建立关系。
(重新)缩放数值
网络通过更新权重进行训练,优化器负责这一点。通常,如果值介于 [-1, 1] 之间,它们会被调整为最佳。这是为什么?让我们考虑一个丘陵景观,我们寻找最低点。该地区越是丘陵,我们花在寻找全球最小值上的时间就越多。但是,如果我们可以修改景观的形状呢?那么我们可以更快地找到解决方案吗?
这就是我们通过重新调整数值所做的。当我们将值缩放到 [-1, 1] 时,我们使曲率更球形(更圆、更均匀)。如果我们用这个范围的数据训练我们的模型,我们会更快地收敛。
这是为什么?特征的大小(即值)影响梯度的大小。较大的特征会产生较大的梯度,从而导致较大的权重更新。这些更新需要更多的步骤来收敛,这会减慢训练速度。
使用知识蒸馏
你肯定听说过 BERT 模型,不是吗?这个 Transformer 有几亿个参数,但我们可能无法在我们的 GPU 上训练它。这就是提炼知识的过程变得有用的地方。我们训练第二个模型以产生更大模型的输出。输入仍然是原始数据集,但标签是参考模型的输出,称为软输出。这种技术的目标是在小模型的帮助下复制更大的模型。
问题是:为什么不直接训练小模型呢?首先,训练较小的模型,尤其是在 NLP 领域,比训练较大的模型更复杂。其次,大型模型对于我们的问题可能是过度的:它足够强大,可以学习我们需要的东西,但它可以学到更多。另一方面,较小的模型难以训练,但足以存储所需的知识。因此,我们将广泛的参考模型的知识提炼到我们的小型辅助模型中。然后我们受益于降低的复杂性,同时仍然接近原始质量。
本文作者:Pascal Janetzky
deephub翻译组