
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
这是2018年ICLR发表的一篇论文,被引用超过1100次。论文的想法来源于:如果某人不了解图像中描绘的对象的概念,则他无法识别应用于图像的旋转。

在这篇文章中,我们回顾了巴黎科技大学(University Paris-Est)通过预测图像旋转进行的无监督表示学习。使用RotNet通过训练ConvNets来学习图像特征,以识别应用于作为输入的图像的2d旋转。通过这种方法,无监督的预训练AlexNet模型达到了54.4%的mAP,仅比有监督的AlexNet低2.4点。
本文内容
- RotNet:图像旋转预测框架
- CIFAR-10的消融研究与SOTA比较
- 基于ImageNet、Places和PASCAL VOC的任务概化
图像旋转预测框架
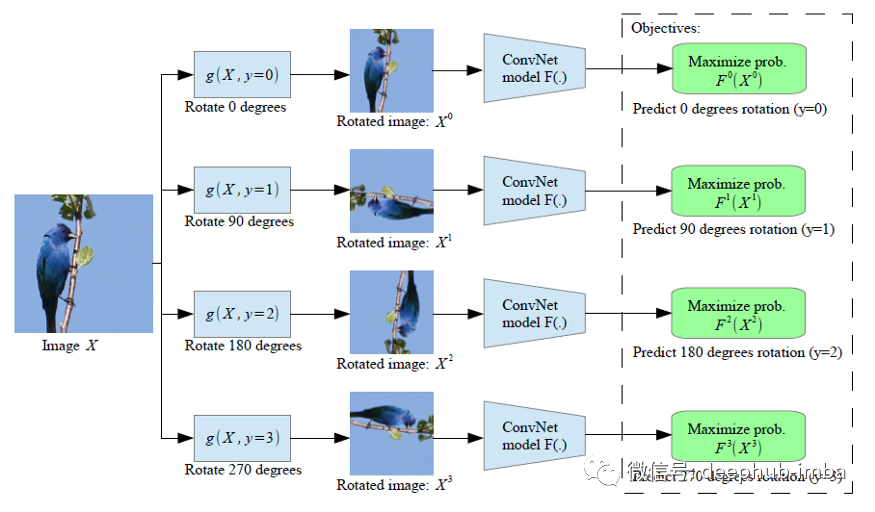
给定四种可能的几何变换,即0、90、180和270度旋转,卷积网络模型F(:)被训练来识别输入的图像应用了哪个旋转。
Fy(Xy) 是模型 F(:) 预测的旋转变换 y 的概率,它的输入是一个已经被旋转变换的图像。
为了成功地预测图像的旋转,ConvNet模型必须学习定位图像中的显著目标,识别它们的方向和对象类型,然后将对象方向与原始图像进行关联。

由经过训练的 AlexNet 模型生成的注意力图(a)识别对象(监督),和(b)识别图像旋转(自监督)。
上述注意力图是根据卷积层的每个空间单元的激活幅度计算的,本质上反映了网络将大部分焦点放在何处以对输入图像进行分类。
图中可以看到,监督模型和自监督模型似乎都关注大致相同的图像区域。
CIFAR-10 的消融研究和 SOTA 比较
CIFAR 上每一层的监督训练

通过测量在它们之上训练非线性对象分类器时获得的分类准确度来评估无监督学习的特征。
使用具有网络中网络 (NIN) 架构的 RotNet 模型。总计 3、4、5个Conv.块的RotNet模型总层数分别为9、12、15层。
分类器是在卷积层之上学习的。这些分类器在 CIFAR-10 上以有监督的方式进行训练。它们由 3 个全连接层组成;2 个隐藏层各有 200 个特征通道,此外还包括了BN和 ReLU 。
由第2个conv. 块生成的feature map(该块实际深度为6)的精度最高,即在88.26%到89.06%之间。
增加RotNet模型的总深度可以提高早期层生成的特征图的目标识别性能。
旋转次数

上图显示了自监督学习特征的质量与识别旋转次数的关系。
只使用2个方向的旋转只提供了很少的可识别类。
在8个方向的情况下,几何变换的可分辨性不够,而且额外引入的4个旋转可能会导致旋转图像上的视觉伪影。
所以最好的一个是使用4个旋转0,90,180,270。
SOTA对比
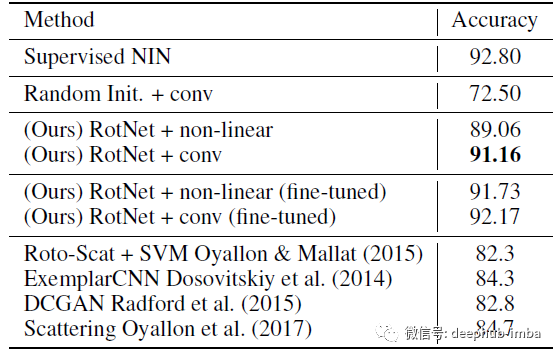
上图是基于CIFAR-10的无监督特征学习方法评价
RotNet改进了之前的无监督方法,如Exemplar-CNN和DCGAN,并在CIFAR-10中实现了最先进的结果。
更值得注意的是,基于RotNet的模型与全监督NIN模型之间的精度差距非常小,只有1.64个百分点(92.80% vs 91.16%)。
基于ImageNet、Places和PASCAL VOC的任务概化
ImageNet
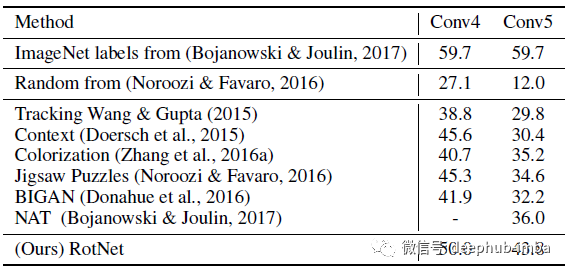
RotNet大大超过了所有其他方法,如上下文预测、着色、Jigsaw Puzzles和BiGAN
- 在每一层的特征图上训练回归分类器来执行1000类的ImageNet分类任务。
- 所有的权重都被冻结,特征地图的空间大小被调整(使用自适应最大池),以便拥有大约9000个元素。
- 所有方法都使用AlexNet变体,并且在ImageNet上进行了预训练,除了“ImageNet标签”之外没有任何标签。
同样,RotNet展示了与之前的非监督方法(如上下文预测、上下文编码器、着色、拼图、Split-Brain Auto和BiGAN)相比的显著改进。
Places
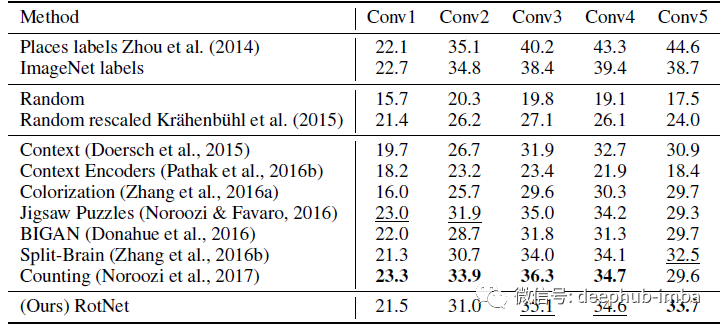
同样,RotNet也试图超越或实现与之前最先进的无监督学习方法相比的结果,如上下文预测、上下文编码器、着色、拼图、Split-Brain Auto和BiGAN。
PASCAL VOC
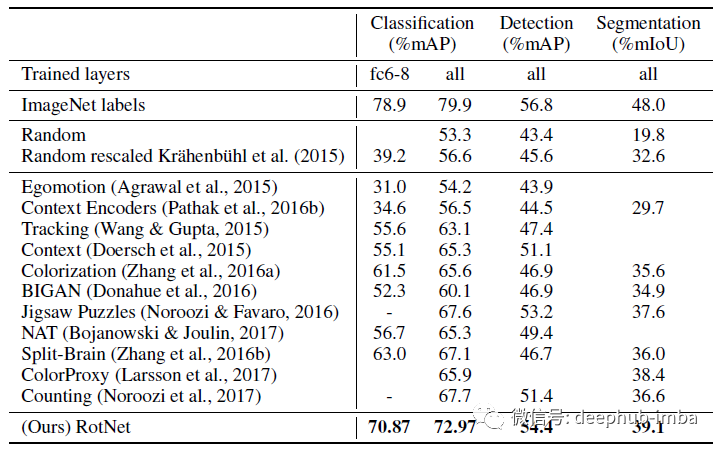
对于分类,特征要么在conv5之前固定(fc6-8列),要么对整个模型进行微调(all列)。检测采用多尺度训练和单尺度测试。所有方法都使用AlexNet变体,并在ImageNet上进行了预训练,并且不包含标签。
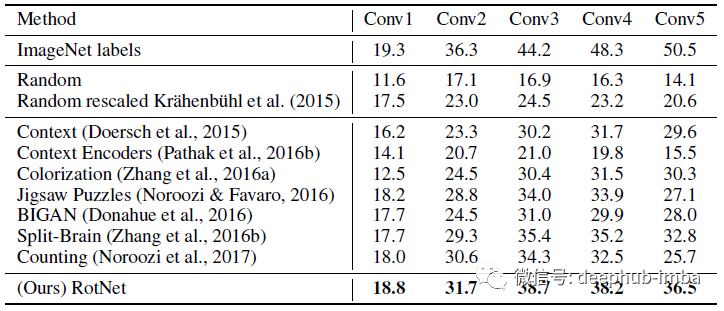
在所有测试任务中,RotNet的性能显著优于所有的非监督方法,如上下文预测、上下文编码器、着色、Jigsaw Puzzles、Split-Brain Auto和BiGAN,显著缩小了与监督情况的差距。
需要说明的是,论文中的自监督模型实现的PASCAL VOC 2007目标检测性能为54.4% mAP,仅比有监督情况低2.4点。
引用
[2018 ICLR] [RotNet/Image Rotations]Unsupervised Representation Learning by Predicting Image RotationsSelf-Supervised Learning
2008–2010 [Stacked Denoising Autoencoders] 2014 [Exemplar-CNN] 2015 [Context Prediction] 2016 [Context Encoders] [Colorization] [Jigsaw Puzzles] 2017 L³-Net 2018 [RotNet/Image Rotations]
作者:Sik-Ho Tsang
喜欢就关注一下吧:
点个 在看 你最好看!********** **********