
ElasticSearch——刷盘原理流程
刷盘原理流程
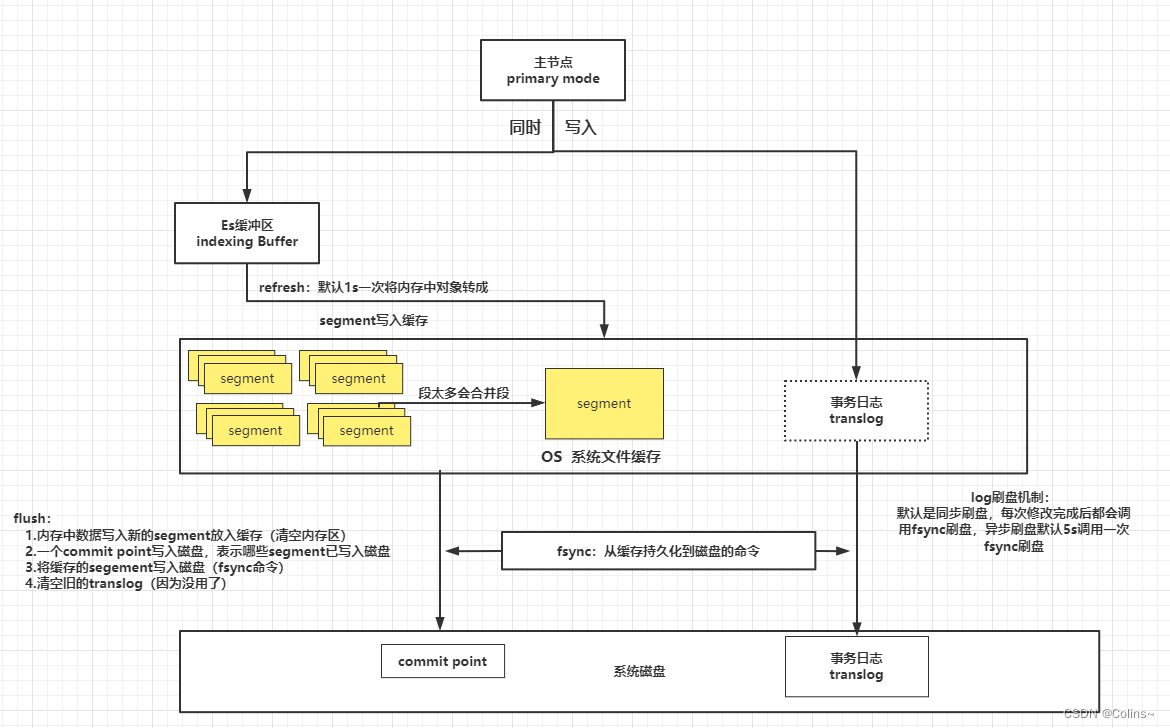
整个过程会分成几步:
- 数据会同时写入buffer缓冲区和translog日志文件
- buffer缓冲区满了或者到时间了(默认1s),就会将其中的数据转换成新的segment并写入系统文件缓存,这一步叫 refresh
- 其中后台会自动合并小的segment成大的segment; 这一步叫段合并
- 当translog达到大小的阈值(默认512M)或者flush默认时长(30m),则会执行flush操作: - 内存中数据写入新的segment放入缓存(清空内存区)- 一个commit point写入磁盘,表示哪些segment已写入磁盘- 将缓存的segement写入磁盘(fsync命令)- 清空旧的translog(因为没用了)
5.translog日志文件也需要持久化到磁盘:
- 同步刷盘:每次修改操作完成后立刻执行fsync命令刷盘
- 异步刷盘:默认每5s执行fsync命令刷盘
名词和操作解释
- index Buffer 是ES内存中的一部分;OS 系统文件缓存是操作系统的,不属于ES内存
- refresh操作:定时将ES缓冲区的数据转换成segment并写入系统文件缓存的过程(默认1s一次);因为数据只有到了系统文件缓存才能被搜索到,这个延迟也是ES被称为近实时搜索的原因
- translog:日志文件,因为不管是ES缓冲区还是系统文件缓存只要没到磁盘,一旦服务器宕机,数据就丢失了,所以有了translog日志文件,因为该文件是顺序写入所以开销不大,默认是同步刷盘,还可以设置成异步的(默认5s刷盘一次)
- flush:因为上述的数据只是到了系统文件缓存,虽然有translog的持久化保证数据的不丢失,但translog会越来越大,文件越大一旦宕机恢复的时候不是越麻烦?所以数据本身的持久化和translog文件清理的机制就叫flush,它会将系统文件缓存中的segment数据持久化到磁盘,同时清除旧的translog,默认30分钟一次或者translog大小达到512M阈值,有以下几步:1.内存中数据写入新的segment放入缓存(清空内存区)2.一个commit point写入磁盘,表示哪些segment已写入磁盘3.将缓存的segement写入磁盘(fsync命令)4.清空旧的translog(因为没用了)
- fsync:这个可能是很多人理解错的地方,这个只是个系统命令,一个将系统文件缓存中的数据持久化到磁盘的命令,所以flush在持久化segment段数据的时候会调用,同时translog持久化到磁盘的时候也会调用
- segment file:一个存储了倒排索引的文件,搜索也会按照段来搜索
- 段合并:由于refresh会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和 cpu 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。Elasticsearch 通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
- commit point:记录当前所有可用的segment,会维护一个.del文件(es删除的时候会先在.del文件中声明某个document被删除了,此时该document还是可以被查询出的,但是返回结果的时候会根据commit point维护的.del文件将被删除的document过滤掉)
相关设置
- index.refresh_interval:refresh刷新频率,默认1s一次,可以设置为-1为禁用
- index.translog.durability: - request:同步刷盘(默认)- async:异步刷盘
- index.translog.sync_interval:translog异步刷盘间隔时间;默认5s一次
- index.translog.flush_threshold_size:当translog的大小达到此值时会进行一次flush操作。默认是512m
- index.translog.flush_threshold_period:在指定的时间间隔内如果没有进行flush操作,会进行一次强制flush操作。默认是30分钟
- index Buffer 大小设置: - indices.memory.index_buffer_size:接受百分比或字节大小值,默认为10%,意味着分配给node的总内存的10%用于索引缓冲区- indices.memory.min_index_buffer_size:如果将index_buffer_size设置为备份比,则可以用此设置指定绝对最小值,默认为48mb- indices.memory.max_index_buffer_size:如果将index_buffer_size设置为百分比,则可以用此设置指定绝对最小值,默认无限制
标签:
elasticsearch
大数据
本文转载自: https://blog.csdn.net/weixin_44102992/article/details/128406379
版权归原作者 Colins~ 所有, 如有侵权,请联系我们删除。
版权归原作者 Colins~ 所有, 如有侵权,请联系我们删除。