
介绍
机器学习是一种解决不能明确编码的问题的方法,例如,分类问题。机器学习模型将从数据中学习一种模式,因此我们可以使用它来确定数据属于哪个类。
但有个问题。这个模型是如何工作的?一些人不能接受一个性能良好的模型,因为它不能被解释。这些人关心可解释性,因为他们想确保模型以合理的方式预测数据。
在解释ML模型之前,消除多重共线性是一个必要的步骤。多重共线性是指一个预测变量与另一个预测变量相关的情况。多重共线性虽然不影响模型的性能,但会影响模型的可解释性。如果我们不去除多重共线性,我们将永远不会知道一个变量对结果的贡献有多大。因此,我们必须消除多重共线性。
本文将向您展示如何使用Python消除多重共线性。
数据源
为了演示,我们将使用一个名为Rain in Australia的数据集。它描述了不同日期和地点的天气特征。这个数据集也是一个监督学习问题,我们可以使用这些数据来预测明天是否下雨。这个数据集可以在Kaggle上找到,你可以在这里访问它。
import pandas as pd
df = pd.read_csv('data.csv')
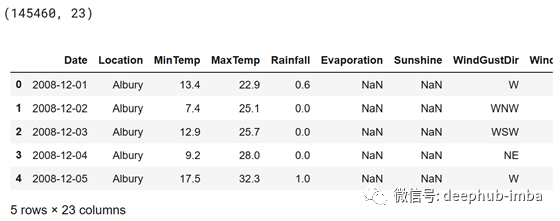
print(df.shape)
df.head()
预处理的数据
加载数据之后,下一步是对数据进行预处理。在本例中,我们将不使用分类列,并删除每个列至少缺少一个值的行。下面是这样做的代码:
df = df[list(df.columns[2:])]
df = df.drop(['WindGustDir', 'WindDir9am', 'WindDir3pm'], axis=1)
df = df.dropna()
print(df.shape)
df.head()
计算VIF值
在我们有了干净的数据之后,让我们计算方差膨胀因子(VIF)值。VIF是什么?
VIF是一个决定变量是否具有多重共线性的数值。这个数字也代表了一个变量因与其他变量线性相关而被夸大的程度。
VIF取值从1开始,没有上限。如果这个数字变大,就意味着这个变量有巨大的多重共线性。
为了计算VIF,我们将对每个变量进行线性回归过程,其中该变量将成为目标变量。在我们完成这个过程之后,我们计算出R的平方。最后,我们用这个公式计算VIF值:

在Python中,我们可以使用statmodels库中的variance_inflation_factor函数来计算VIF。下面是这样做的代码和结果:
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
X = df[list(df.columns[:-2])]
vif_info = pd.DataFrame()
vif_info['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif_info['Column'] = X.columns
vif_info.sort_values('VIF', ascending=False)
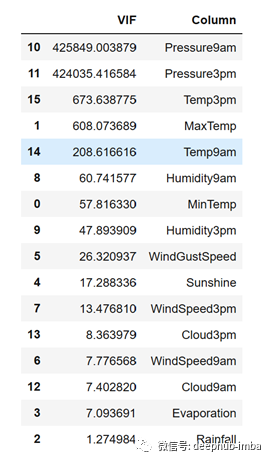
从上面可以看到,几乎所有变量的VIF值都大于5。甚至压力变量的VIF值也超过40万。这是一个很大的因素!
因此,我们需要从数据中清除这些多重共线性。
消除多重共线性
为了消除多重共线性,我们可以做两件事。我们可以创建新的特性,也可以从数据中删除它们。
首先不建议删除特征。因为我们去掉了这个特征,就有可能造成信息丢失。因此,我们将首先生成新特性。
从数据中,我们可以看到有一些特征有它们对。例如,' Temp9am '加上' Temp3pm ', ' Pressure9am '加上' Pressure3pm ', ' Cloud9am '加上' Cloud3pm ',等等。
从这些特性中,我们可以生成新的特性。新特性将包含这些对之间的差值。在我们创建这些特性之后,我们可以安全地将它们从数据中删除。
下面是这样做的代码和结果:
df['TempDiff'] = df['Temp3pm'] - df['Temp9am']
df['HumidityDiff'] = df['Humidity3pm'] - df['Humidity9am']
df['CloudDiff'] = df['Cloud3pm'] - df['Cloud9am']
df['WindSpeedDiff'] = df['WindSpeed3pm'] - df['WindSpeed9am']
df['PressureDiff'] = df['Pressure3pm'] - df['Pressure9am']
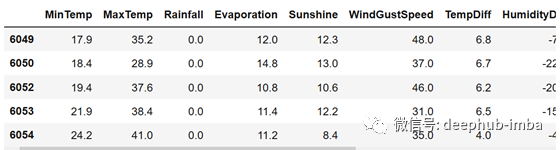
X = df.drop(['Temp3pm', 'Temp9am', 'Humidity3pm', 'Humidity9am', 'Cloud3pm', 'Cloud9am', 'WindSpeed3pm', 'WindSpeed9am', 'Pressure3pm', 'Pressure9am', 'RainToday', 'RainTomorrow'], axis=1)
X.head()
现在让我们看看数据的VIF值是怎样的:
vif_info = pd.DataFrame()
vif_info['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif_info['Column'] = X.columns
vif_info.sort_values('VIF', ascending=False)
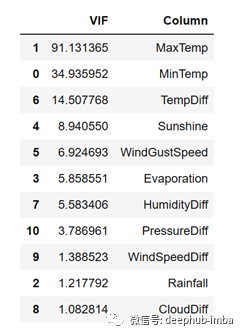
正如你从上面看到的,我们仍然得到了具有巨大VIF值的变量。但是,我们仍然从生成新功能中得到了一个很好的结果。
现在让我们删除VIF值大于5的特性。下面是这样做的代码和结果:
X = X.drop(['MaxTemp', 'MinTemp', 'TempDiff', 'Sunshine'], axis=1)
vif_info = pd.DataFrame()
vif_info['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif_info['Column'] = X.columns
vif_info.sort_values('VIF', ascending=False)
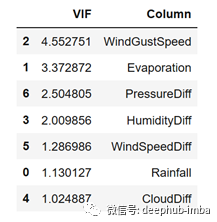
好了!现在我们有所有VIF值小于5的变量。有了这些变量,现在我们就可以解释结果了。但首先,让我们建立我们的机器学习模型。
构建模型
在这种情况下,我们将使用支持向量机(SVM)算法来建模我们的数据。简而言之,SVM是一种模型,它将创建一个超平面,可以最大限度地分离使用不同标签的数据。
因为我们的数据属于一个分类任务,所以我们将使用scikit-learn中的SVC对象来创建模型。下面是这样做的代码:
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
encoder = LabelEncoder()
y_encoded = encoder.fit_transform(y)
print(encoder.classes_)
print(y_encoded)
X_train, X_test, y_train, y_test = train_test_split(X.values, y_encoded)
model = SVC()
model.fit(X.values, y_encoded)
print(model.score(X_test, y_test))
利用排列特征重要性进行解释
理论上,支持向量机模型是不可解释的。这是因为我们不能仅仅通过查看参数来解释结果。但幸运的是,我们有几种方法可以解释这个模型。我们可以使用的方法之一是排列特征的重要性。
排列特征重要性通过观察改变特征值后误差增加了多少来衡量一个特征的重要性。如果特征值的变化增加了模型的误差,那么该特征是重要的。
要实现这个方法,可以使用scikit-learn库中的permutation_importance函数来计算特性的重要性。根据这个结果,我们将创建一个箱线图来可视化特性的重要性。
下面是这样做的代码和结果:
from sklearn.inspection import permutation_importance
result = permutation_importance(model, X.values, y_encoded, n_repeats=10, random_state=42)
perm_imp_idx = result.importances_mean.argsort()
plt.boxplot(result.importances[perm_imp_idx].T, vert=False,
labels=X.columns[perm_imp_idx])
plt.title('Feature Importance from Rain in Australia Dataset')
plt.show()

从上面可以看到,HumanityDiff特性是对最终结果有巨大贡献的最重要的特性。然后是降雨特性,这是第二个最重要的特性。其次是风速(WindGustSpeed)、蒸发(vaporize)、风速差(WindSpeedDiff)、气压差(PressureDiff)和云l量差(CloudDiff)。
最后总结
做得好!现在您已经学习了如何使用Python从数据集中删除多重共线性。我希望这篇文章能帮助你消除多重共线性,以及如何解释机器学习模型。
作者:Irfan Alghani Khalid
原文地址:https://towardsdatascience.com/how-to-remove-multicollinearity-using-python-4da8d9d8abb2