
文章目录
01 引言
在学习
Hadoop
之前,我们看看典型的大数据平台架构图: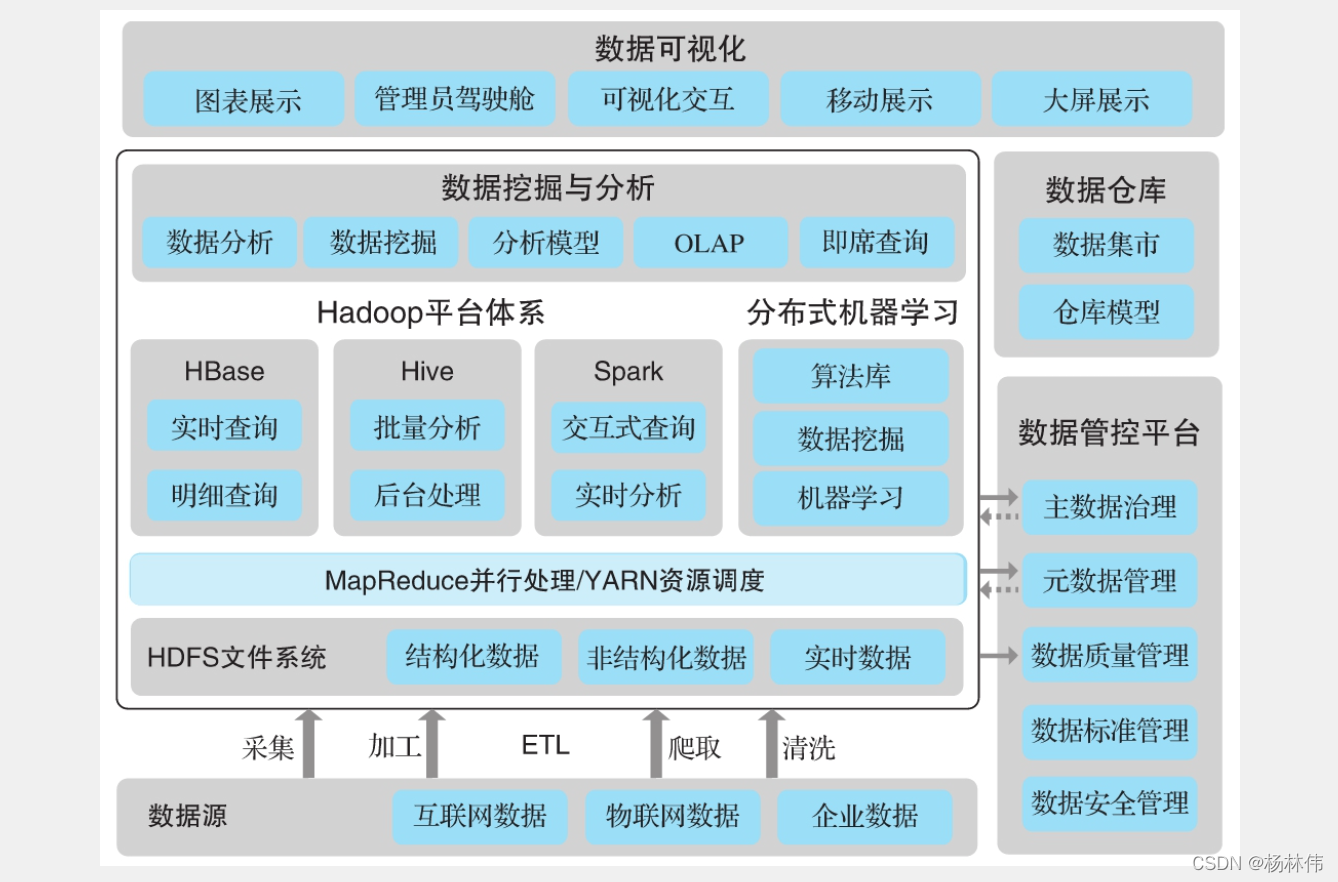
可以看到
Hadoop
在大数据平台里处于一个技术核心的地位,本文来讲解下。
02 Hadoop概述
2.1 Hadoop定义
Hadoop :是使用
Java
编写,允许分布在集群,使用简单的编程模型的计算机大型数据集处理的
Apache
的开源框架。
2.2 Hadoop优势
Hadoop的优势:
Hadoop是专为从单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。Hadoop可以用单节点模式安装,但是只有多节点集群才能发挥Hadoop的优势,我们可以把集群扩展到上千个节点,而且扩展过程中不需要先停掉集群。
2.3 Hadoop组成
看看
Hadoop
由哪些组件组成: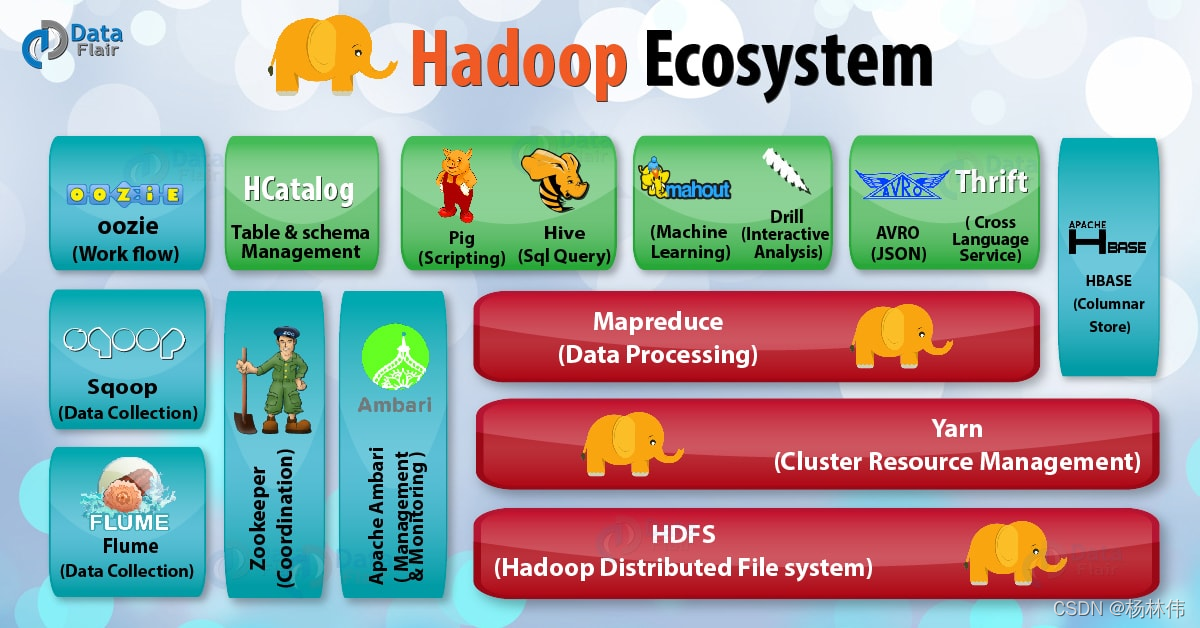
以上的各个组件都是属于
Hadoop
的生态系统的,如果想入门大数据,都是需要学习,它们分别是:
- Hadoop HDFS(核心):
Hadoop分布式存储系统; - Yarn(核心):
Hadoop 2.x版本开始才有的资源管理系统; - MapReduce(核心):并行处理框架;
- HBase:基于
HDFS的列式存储数据库,它是一种NoSQL数据库,非常适用于存储海量的稀疏的数据集; - Hive:
Apache Hive是一个数据仓库基础工具,它适用于处理结构化数据。它提供了简单的 sql 查询功能,可以将sql语句转换为MapReduce任务进行运行; - Pig:它是一种高级脚本语言。利用它不需要开发
Java代码就可以写出复杂的数据处理程序; - Flume:它可以从不同数据源高效实时的收集海量日志数据;
- Sqoop:适用于在
Hadoop和关系数据库之间抽取数据; - Oozie:这是一种
Java Web系统,用于Hadoop任务的调度,例如设置任务的执行时间和执行频率等; - Zookeeper:用于管理配置信息,命名空间。提供分布式同步和组服务;
- Mahout:可扩展的机器学习算法库。
其中:
HDFS
、
MapReduce
、
YARN
是核心。
2.3.1 HDFS
已有专栏专门讲解,有兴趣的同学可以参考《HDFS专栏》
HDFS :即
Hadoop
分布式文件系统(
Hadoop Distribute File System
),以分布式存储的方式存储数据。
HDFS 也是一种
Master-slave
架构,NameNode 是运行 master 节点的进程,它负责命名空间管理和文件访问控制。DataNode 是运行在 slave 节点的进程,它负责存储实际的业务数据,如下图: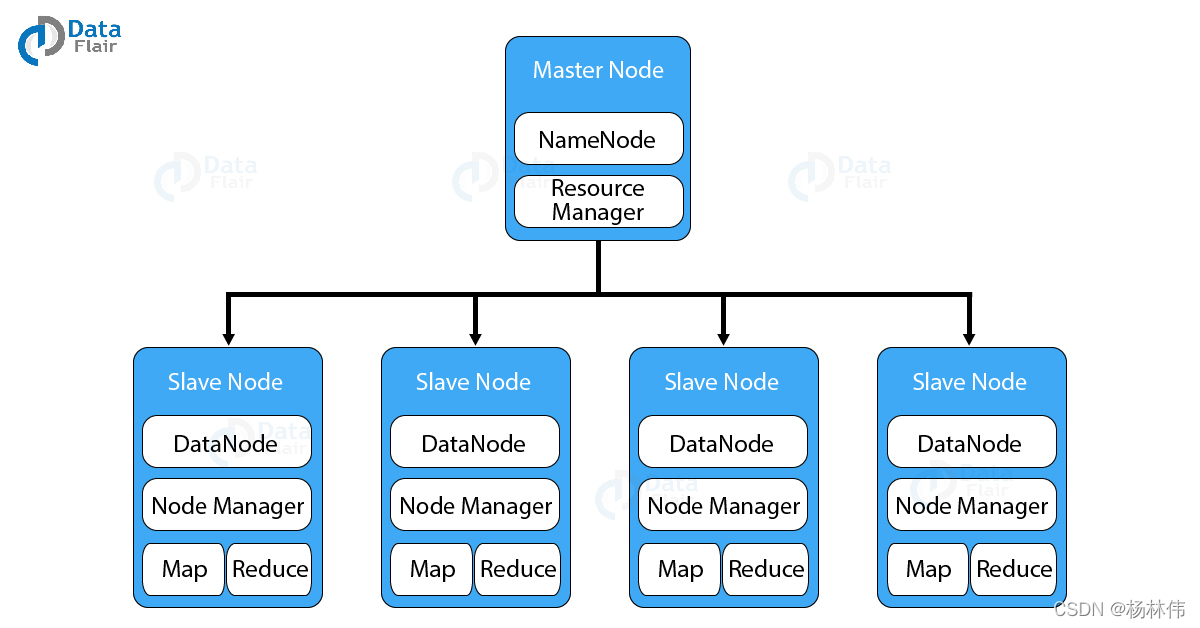
2.3.2 MapReduce
已有专栏专门讲解,有兴趣的同学可以参考《MapReduce专栏》
Hadoop MapReduce
是一种编程模型,它是
Hadoop
最重要的组件之一。它用于计算海量数据,并把计算任务分割成许多在集群并行计算的独立运行的
task
。
MapReduce
是
Hadoop
的核心,它会把计算任务移动到离数据最近的地方进行执行,因为移动大量数据是非常耗费资源的。
2.3.3 YARN
Yarn :是一个资源管理系统,其作用就是把资源管理和任务调度/监控功分割成不同的进程,
Yarn
有一个全局的资源管理器叫
ResourceManager
,每个
application
都有一个
ApplicationMaster
进程。一个
application
可能是一个单独的
job
或者是
job
的
DAG
(有向无环图)。
在 Yarn 内部有两个守护进程:
- ResourceManager :负责给 application 分配资源
- NodeManager :负责监控容器使用资源情况,并把资源使用情况报告给 ResourceManager。这里所说的资源一般是指CPU、内存、磁盘、网络等。
ApplicationMaster
负责从
ResourceManager
申请资源,并与
NodeManager
一起对任务做持续监控工作。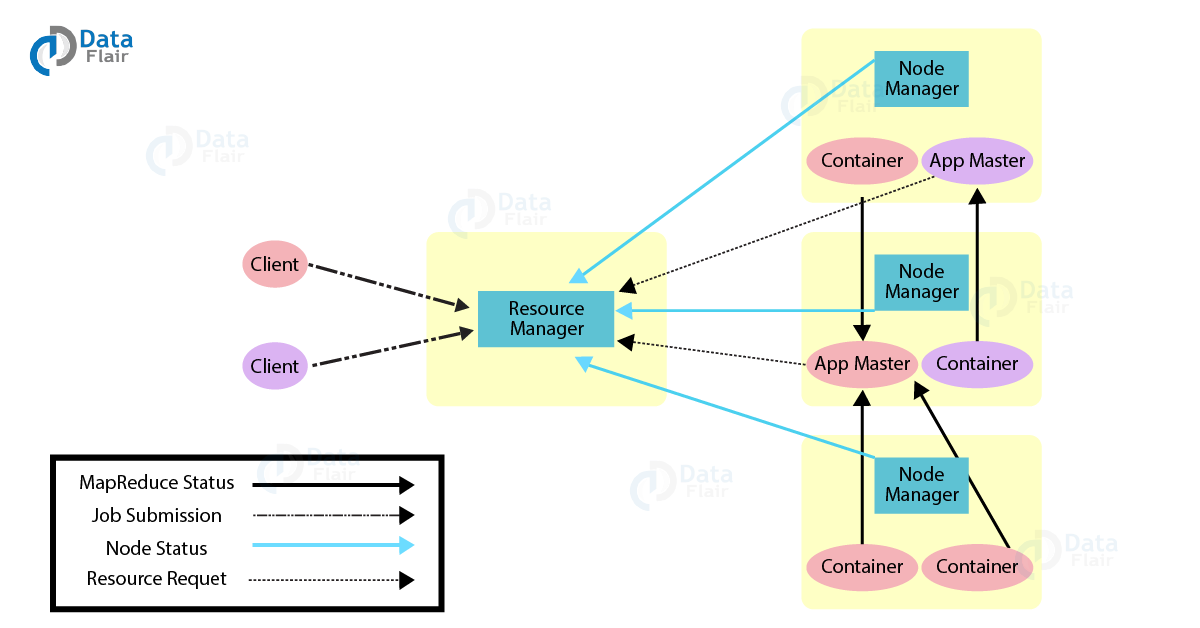
Yarn
具有下面这些特性:
- 多租户:
Yarn允许在同样的Hadoop数据集使用多种访问引擎。这些访问引擎可能是批处理,实时处理,迭代处理等; - 集群利用率:在资源自动分配的情况下,跟早期的
Hadoop版本相比,Yarn拥有更高的集群利用率; - 可扩展性:
Yarn可以根据实际需求扩展到几千个节点,多个独立的集群可以联结成一个更大的集群; - 兼容性:
Hadoop 1.x的MapReduce应用程序可以不做任何改动运行在Yarn集群上面。
2.4 Hadoop工作方式
2.4.1 Hadoop的主从工作方式
Hadoop 以主从的方式工作(如下图):

2.4.2 Hadoop的守护进程
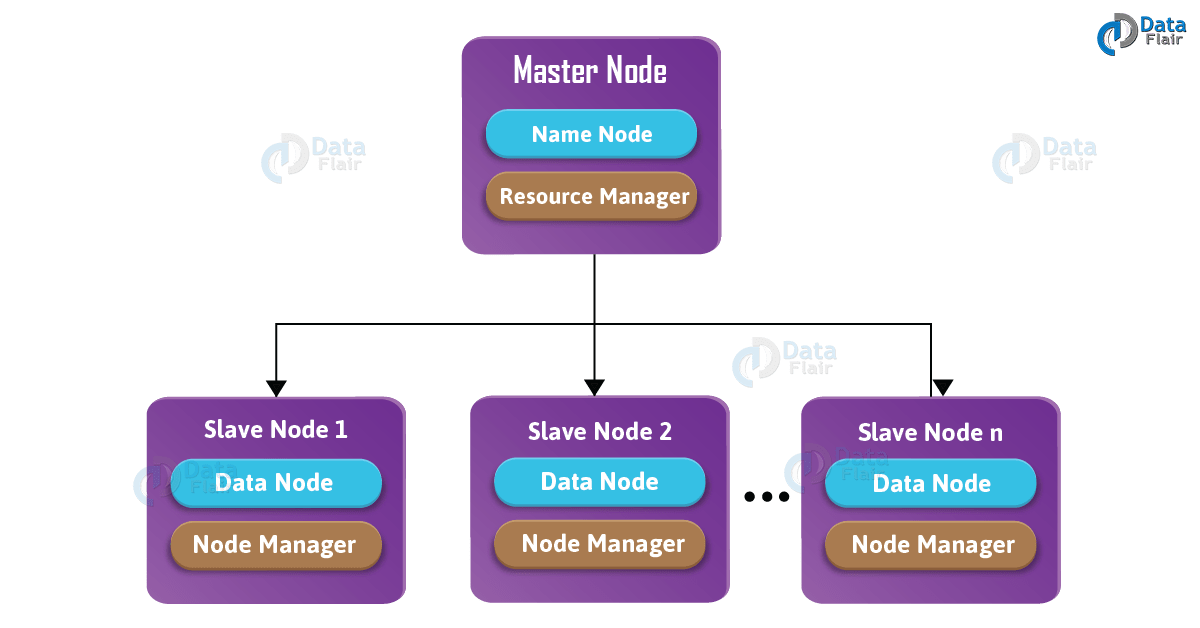
Hadoop
主要有4个守护进程:
- NameNode :它是HDFS运行在Master节点守护进程。
- DataNode:它是 HDFS 运行在Slave节点守护进程。
- ResourceManager:它是 Yarn 运行在 Master 节点守护进程。
- NodeManager:它是 Yarn 运行在 Slave 节点的守护进程。
除了这些,可能还会有
secondary NameNode,standby NameNode,Job HistoryServer
等进程。
03 Hadoop的安装
之前写过关于在Mac系统下安装Hadoop,有兴趣的同学可以参考《Mac下安装Hadoop》
其它系统下不同版本的hadoop安装参考:
- 《Hadoop Ubuntu 安装 Hadoop 2.0(伪分布式)》
- 《Ubuntu 安装 Hadoop 2.0(分布式)》
- 《Ubuntu 安装 Hadoop 3.0(伪分布式)》
04 Hadoop 高可用
**
NameNode
很容易面临单点故障风险(
SPOF
)**:
- 在
Hadoop 2.0以前的版本,一旦NameNode节点挂了,整个集群就不可用了,而且需要借助辅助NameNode来手工干预重启集群,这将延长集群的停机时间; Hadoop 2.0版本支持一个备用节点用于自动恢复NameNode故障;Hadoop 3.0则支持多个备用NameNode节点,这使得整个集群变得更加可靠。
为了解决
SPOF
故障,
Hadoop
必须制定高可用的解决方案。
4.1 Hadoop高可用的解决方案
Hadoop 实现自动故障切换需要用到下面的组件:
- ZooKeeper quorum
- ZKFailoverController 进程(ZKFC)
4.1.1 ZooKeeper quorum
ZooKeeper quorum
是一种集中式服务,主要为分布式应用提供协调、配置、命名空间等功能。它提供组服务和数据同步服务,它让客户端可以实时感知数据的更改,并跟踪客户端故障,HDFS故障自动切换的实现依赖下面两个方面:
- 故障监测:
ZooKeeper维护一个和NameNode之间的会话。如果NameNode发生故障,该会话就会过期,会话一旦失效了,ZooKeeper将通知其他NameNode启动故障切换进程。 - 活动NameNode选举:
ZooKeeper提供了一种活动节点选举机制,只要活动的NameNode发生故障失效了,其他NameNode将从ZooKeeper获取一个排它锁,并把自身声明为活动的NameNode。
4.1.2 ZKFC
ZKFC 是
ZooKeeper
的监控和管理
namenode
的一个客户端,所以每个运行
namenode
的机器上都会有
ZKFC
。
那ZKFC具体作用是什么?主要有以下3点:
- 状态监控:
ZKFC会定期用ping命令监测活动的NameNode,如果NameNode不能及时响应ping命令,那么ZooKeeper就会判断该活动的NameNode已经发生故障了。 - ZooKeeper会话管理:如果
NameNode是正常的,那么它和ZooKeeper会保持一个会话,并持有一个znode锁。如果会话失效了,那么该锁将自动释放。 - 基于ZooKeeper的选举:如果
NameNode是正常的,ZKFC 知道当前没有其他节点持有znode锁,那么ZKFC自己会试图获取该锁,如果锁获取成功,那么它将赢得选举,并负责故障切换工作。这里的故障切换过程其实和手动故障切换过程是类似的;先把之前活动的节点进行隔离,然后把ZKFC所在的机器变成活动的节点。
05 Hadoop 任务调度器
Hadoop 是一个可以高效处理大数据量的分布式集群,并且支持多用户多任务执行。
在Hadoop早期版本是以一种比较简单的方式对任务进行调度的,即
FIFO
调度器,它是按任务的提交顺序来调度任务的,并且可以使用
mapred.job.priority
配置或者利用
JobClient
的
setJobPriority()
方法设置任务调度优先级。
目前
Hadoop
支持三种调度器:
FIFO
调度器、公平调度器(
Fair Scheduler
)、容量调度器(
Capacity Scheduler
)。
5.1 FIFO 调度器
**
FIFO
调度器也就是平时所说的先进先出(
First In First Out
)调度器**。可以简单的将其理解为一个
Java
队列,它的含义在于集群中同时只能有一个作业在运行。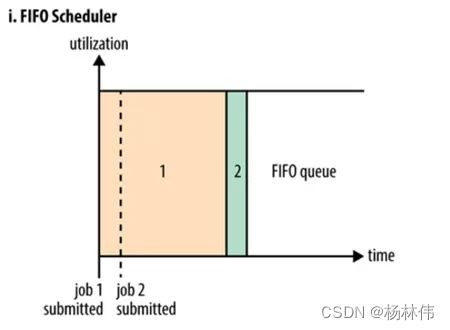
队列形式会有什么问题?
FIFO调度器以集群资源独占的方式来运行作业,这样的好处是一个作业可以充分利用所有的集群资源,但是对于运行时间短,重要性高或者交互式查询类的MR作业就要等待排在序列前的作业完成才能被执行,这也就导致了如果有一个非常大的Job在运行,那么后面的作业将会被阻塞。
因此,虽然单一的
FIFO
调度实现简单,但是对于很多实际的场景并不能满足要求。这也就催生了
Capacity
调度器和
Fair
调度器的出现。
5.2 容量调度器(Capacity Scheduler)
Capacity 调度器也就是日常说的容器调度器,可以将它理解成一个个的资源队列,这个资源队列是用户自己去分配的: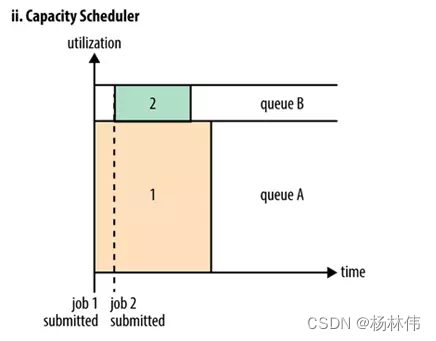
举例:如上图,因为工作所需要把整个集群分成了AB两个队列,A队列下面还可以继续分,比如将A队列再分为1和2两个子队列。那么队列的分配就可以参考下面的树形结构:
|___A[60%]|_____A.1[40%]|_____A.2[60%]|___B[40%]
上述的树形结构可以理解为:
- A队列占用整个资源的60%,B队列占用整个资源的40%。
- A队列里面又分了两个子队列,A.1占据40%,A.2占据60%,也就是说此时A.1和A.2分别占用A队列的40%和60%的资源。
- 虽然此时已经具体分配了集群的资源,但是并不是说A提交了任务之后只能使用它被分配到的60%的资源,而B队列的40%的资源就处于空闲。只要是其它队列中的资源处于空闲状态,那么有任务提交的队列可以使用空闲队列所分配到的资源,使用的多少是依据配来决定。
调度器特性特性:
- 层次化的队列设计:这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源;
- 容量保证:队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源;
- 安全:每个队列又严格的访问控制。
- 弹性分配:空闲的资源可以被分配给任何队列。
- 多租户租用:通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
- 操作性:
Yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。 - 基于资源的调度:协调不同资源需求的应用程序,比如内存、
CPU、磁盘等等。
相关参数配置:
参数描述
capacity
队列的资源容量(百分比)
maximum-capacity
队列的资源使用上限(百分比)
user-limit-factor
每个用户最多可使用的资源量(百分比)
maximum-applications
集群或者队列中同时处于等待和运行状态的应用程序数目上限
maximum-am-resource-percent
集群中用于运行应用程序ApplicationMaster的资源比例上限
maximum-am-resource-percent
设置适合自己的值
state
队列状态可以为STOPPED或者RUNNING
acl_submit_applications
限定哪些Linux用户/用户组可向给定队列中提交应用程序
acl_administer_queue
为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等
5.3 公平调度器(Fair Scheduler)
Fair调度器也就是日常说的公平调度器。Fair调度器是一个队列资源分配方式,在整个时间线上,所有的Job平均的获取资源。默认情况下,Fair调度器只是对内存资源做公平的调度和分配。
当集群中只有一个任务在运行时,那么此任务会占用整个集群的资源。当其他的任务提交后,那些释放的资源将会被分配给新的Job,所以每个任务最终都能获取几乎一样多的资源。
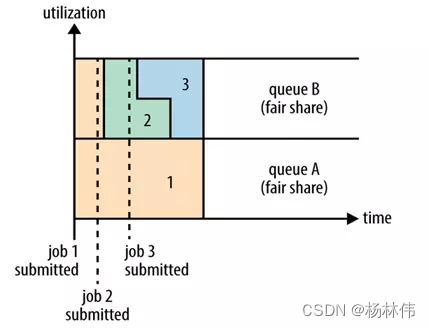
如上图所示,例如有两个用户A和B,他们分别拥有一个队列:
- 当A启动一个
Job而B没有任务提交时,A会获得全部集群资源;- 当B启动一个
Job后,A的任务会继续运行,不过队列A会慢慢释放它的一些资源,一会儿之后两个任务会各自获得一半的集群资源。- 如果此时B再启动第二个
Job并且其它任务也还在运行时,那么它将会和B队列中的的第一个Job共享队列B的资源,也就是队列B的两个Job会分别使用集群四分之一的资源,- 而队列A的
Job仍然会使用集群一半的资源,结果就是集群的资源最终在两个用户之间平等的共享。
相关参数配置:
参数描述
yarn.scheduler.fair.allocation.file
allocation”文件是一个用来描述queue以及它们的属性的配置文件
yarn.scheduler.fair.user-as-default-queue
是否将与allocation有关的username作为默认的queue name
yarn.scheduler.fair.preemption
是否使用“preemption”(优先权,抢占),默认为fasle
yarn.scheduler.fair.assignmultiple
是在允许在一个心跳中,发送多个container分配信息
yarn.scheduler.fair.max.assign
如果assignmultuple为true,那么在一次心跳中,最多发送分配container的个数
yarn.scheduler.fair.locality.threshold.node
一个float值,在0~1之间,表示在等待获取满足node-local条件的containers时,最多放弃不满足node-local的container的机会次数,放弃的nodes个数为集群的大小的比例。默认值为-1.0表示不放弃任何调度的机会
yarn.scheduler.fair.locality.threashod.rack
同上,满足rack-local
yarn.scheduler.fair.sizebaseweight
是否根据application的大小(Job的个数)作为权重
06 分布式缓存
分布式缓存:是
Hadoop MapReduce
框架提供的一种数据缓存机制,它可以缓存只读文本文件,压缩文件,jar包等文件,一旦对文件执行缓存操作,那么每个执行
map/reduce
任务的节点都可以使用该缓存的文件。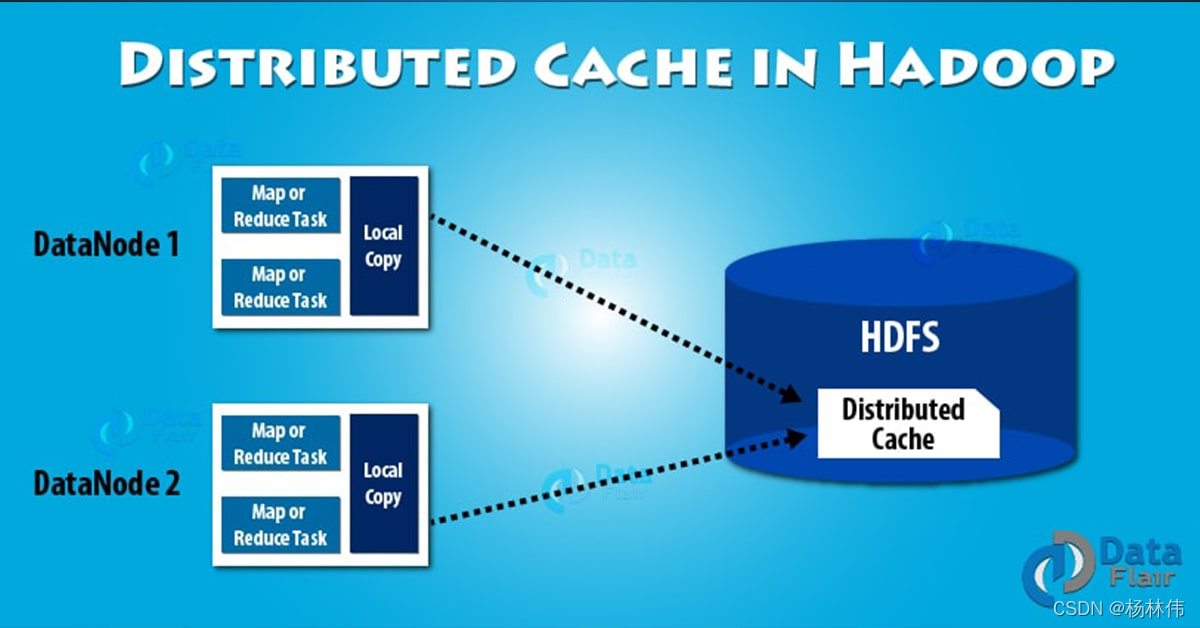
6.1 分布式缓存优点
- 存储复杂的数据:它分发了简单、只读的文本文件和复杂类型的文件,如jar包、压缩包。这些压缩包将在各个slave节点解压。
- 数据一致性:Hadoop分布式缓存追踪了缓存文件的修改时间戳。然后当job在执行时,它也会通知这些文件不能被修改。使用hash 算法,缓存引擎可以始终确定特定键值对在哪个节点上。所以,缓存cluster只有一个状态,它永远不会是不一致的。
- 单点失败:分布式缓存作为一个跨越多个节点独立运行的进程。因此单个节点失败,不会导致整个缓存失败。
6.2 分布式缓存的使用
旧版本的
DistributedCache
已经被注解为过时,以下为
Hadoop-2.2.0
以上的新
API
接口。
Job job =Job.getInstance(conf);//将hdfs上的文件加入分布式缓存
job.addCacheFile(newURI("hdfs://url:port/filename#symlink"));
由于新版
API
中已经默认创建符号连接,所以不需要再调用
setSymlink(true)
方法了,可以下面代码来查看是否开启了创建符号连接。
System.out.println(context.getSymlink());
之后在
map/reduce
函数中可以通过
context
来访问到缓存的文件,一般是重写
setup
方法来进行初始化:
@Overrideprotectedvoidsetup(Context context)throwsIOException,InterruptedException{super.setup(context);if(context.getCacheFiles()!=null&& context.getCacheFiles().length >0){String path = context.getLocalCacheFiles()[0].getName();File itermOccurrenceMatrix =newFile(path);FileReader fileReader =newFileReader(itermOccurrenceMatrix);BufferedReader bufferedReader =newBufferedReader(fileReader);String s;while((s = bufferedReader.readLine())!=null){//TODO:读取每行内容进行相关的操作}
bufferedReader.close();
fileReader.close();}}
得到的
path
为本地文件系统上的路径。
这里的
getLocalCacheFiles方法也被注解为过时了,只能使用
context.getCacheFiles方法,和
getLocalCacheFiles不同的是,
getCacheFiles得到的路径是
HDFS上的文件路径,如果使用这个方法,那么程序中读取的就不再试缓存在各个节点上的数据了,相当于共同访问
HDFS上的同一个文件 ,可以直接通过符号连接来跳过
getLocalCacheFiles获得本地的文件。
6.3 分布式缓存的大小
可以在文件
mapred-site.xml中设置,默认为10GB。
注意事项:
- 需要分发的文件必须是存储在
HDFS上了; - 文件只读;
- 不缓存太大的文件,执行
task之前对文件进行分发,影响task的启动速度。
07 Hadoop常用命令
所有的
Hadoop
命令均由
bin/hadoop
脚本引发。不指定参数运行
hadoop
脚本会打印所有命令的描述。
用法:
hadoop [--config confdir][COMMAND][GENERIC_OPTIONS][COMMAND_OPTIONS]
Hadoop
有一个选项解析框架用于解析一般的选项和运行类。
命令选项描述
--config confdir
覆盖缺省配置目录。缺省是${HADOOP_HOME}/conf。
GENERIC_OPTIONS
多个命令都支持的通用选项。
COMMAND
命令选项各种各样的命令和它们的选项会在下面提到。这些命令被分为用户命令和管理命令两组。
7.1 常规选项
GENERIC_OPTION描述-conf指定应用程序的配置文件。-D为指定property指定值value。-fs指定namenode。-jt指定job tracker。只适用于job。-files <逗号分隔的文件列表>指定要拷贝到map reduce集群的文件的逗号分隔的列表。 只适用于job。-libjars <逗号分隔的jar列表>指定要包含到classpath中的jar文件的逗号分隔的列表。 只适用于job。-archives <逗号分隔的archive列表>指定要被解压到计算节点上的档案文件的逗号分割的列表。 只适用于job。
7.2 用户命令
7.2.1 archive(创建一个 hadoop 档案文件)
用法:
hadoop archive -archiveName NAME <src>* <dest>
命令选项描述-archiveName NAME要创建的档案的名字src文件系统的路径名,和通常含正则表达的一样dest保存档案文件的目标目录
7.2.2 distcp(递归地拷贝文件或目录)
用法:
hadoop distcp <srcurl><desturl>
命令选项描述srcurl源Urldesturl目标Url
7.2.3 fs(运行一个常规的文件系统客户端)
用法:
hadoop fs [GENERIC_OPTIONS][COMMAND_OPTIONS]
命令选项描述srcurl源Urldesturl目标Url
具体的
GENERIC_OPTIONS
可以参考官方文档
各种命令选项可以参考HDFS Shell指南。
7.2.4 fsck(运行 HDFS 文件系统检查工具)
用法:
hadoop fsck[GENERIC_OPTIONS]<path>[-move | -delete | -openforwrite][-files [-blocks [-locations | -racks]]]
命令选项描述path检查的起始目录-move移动受损文件到/lost+found-delete删除受损文件-openforwrite打印出写打开的文件-files打印出正被检查的文件-blocks打印出块信息报告-locations打印出每个块的位置信息-racks打印出data-node的网络拓扑结构
7.2.5 jar(运行 jar 文件)
用法:
hadoop jar <jar>[mainClass] args...
streaming 作业是通过这个命令执行的。参考Streaming examples中的例子。
Word count 例子也是通过jar命令运行的。参考Wordcount example。
7.2.6 job(与Map Reduce 作业交互和命令)
用法:
hadoop job [GENERIC_OPTIONS][-submit <job-file>]|[-status <job-id>]|[-counter <job-id><group-name><counter-name>]|[-kill <job-id>]|[-events <job-id><from-event-#> <#-of-events>] | [-history [all] <jobOutputDir>] | [-list [all]] | [-kill-task <task-id>] | [-fail-task <task-id>]
命令选项描述-submit提交作业-status打印map和reduce完成百分比和所有计数器-counter打印计数器的值-kill杀死指定作业-events <#-of-events>打印给定范围内jobtracker接收到的事件细节-history [all] -history打印作业的细节、失败及被杀死原因的细节。更多的关于一个作业的细节比如成功的任务,做过的任务尝试等信息可以通过指定[all]选项查看-list [all]-list all显示所有作业,-list只显示将要完成的作业-kill-task杀死任务。被杀死的任务不会不利于失败尝试。-fail-task使任务失败。被失败的任务会对失败尝试不利。
7.2.7 pipes(运行 pipes 作业)
用法:
hadoop pipes [-conf <path>][-jobconf <key=value>, <key=value>, ...][-input <path>][-output <path>][-jar <jar file>][-inputformat <class>][-map <class>][-partitioner <class>][-reduce <class>][-writer <class>][-program <executable>][-reduces <num>]
命令选项描述-conf作业的配置-jobconf增加/覆盖作业的配置项-input输入目录-output输出目录-jarJar文件名-inputformatInputFormat类-mapJava Map类-partitionerJava Partitioner-reduceJava Reduce类-writerJava RecordWriter-program可执行程序的URI-reducesreduce个数
7.2.8 version(打印版本信息)
用法:
hadoop version
7.2.9 CLASSNAME(调用任何类)
用法:
hadoop CLASSNAME
运行名字为
CLASSNAME
的类。
7.3 管理命令
hadoop
集群管理员常用的命令。
7.3.1 balancer(运行集群平衡工具)
用法:
hadoop balancer [-threshold <threshold>]
命令选项描述-threshold磁盘容量的百分比。这会覆盖缺省的阀值。
管理员可以简单的按 Ctrl+C 来停止平衡过程。参考 Rebalancer 了解更多。
7.3.2 daemonlog(获取或设置每个守护进程的日志级别)
用法:
hadoop daemonlog -getlevel <host:port><name>
hadoop daemonlog -setlevel <host:port><name><level>
命令选项描述-getlevel打印运行在的守护进程的日志级别。这个命令内部会连接 http:///logLevel?log=-setlevel设置运行在的守护进程的日志级别。这个命令内部会连接 http:///logLevel?log=
7.3.3 datanode(运行一个 HDFS 的 datanode)
用法:
hadoop datanode [-rollback]
命令选项描述-rollback将datanode回滚到前一个版本。这需要在停止datanode,分发老的hadoop版本之后使用。
7.3.4 dfsadmin(运行一个 HDFS 的 dfsadmin 客户端)
用法:
hadoop dfsadmin [GENERIC_OPTIONS][-report][-safemode enter | leave | get | wait][-refreshNodes][-finalizeUpgrade][-upgradeProgress status | details | force][-metasave filename][-setQuota <quota><dirname>...<dirname>][-clrQuota <dirname>...<dirname>][-help [cmd]]
命令选项描述-report报告文件系统的基本信息和统计信息-safemode [enter / leave / get / wait]安全模式维护命令。安全模式是Namenode的一个状态,这种状态下,Namenode 1. 不接受对名字空间的更改(只读)2. 不复制或删除块Namenode会在启动时自动进入安全模式,当配置的块最小百分比数满足最小的副本数条件时,会自动离开安全模式。安全模式可以手动进入,但是这样的话也必须手动关闭安全模式。-refreshNodes重新读取hosts和exclude文件,更新允许连到Namenode的或那些需要退出或入编的Datanode的集合。-finalizeUpgrade终结HDFS的升级操作。Datanode删除前一个版本的工作目录,之后Namenode也这样做。这个操作完结整个升级过程。-upgradeProgress [status / details / force]请求当前系统的升级状态,状态的细节,或者强制升级操作进行。-metasave filename保存Namenode的主要数据结构到hadoop.log.dir属性指定的目录下的文件。对于下面的每一项,中都会一行内容与之对应1. Namenode收到的Datanode的心跳信号2. 等待被复制的块3. 正在被复制的块4. 等待被删除的块-setQuota …为每个目录 设定配额。目录配额是一个长整型整数,强制限定了目录树下的名字个数。命令会在这个目录上工作良好,以下情况会报错:1. N不是一个正整数,或者2. 用户不是管理员,或者3. 这个目录不存在或是文件,或者4. 目录会马上超出新设定的配额。-clrQuota …为每一个目录清除配额设定。命令会在这个目录上工作良好,以下情况会报错:1. 这个目录不存在或是文件,或者2. 用户不是管理员。如果目录原来没有配额不会报错。-help [cmd]显示给定命令的帮助信息,如果没有给定命令,则显示所有命令的帮助信息。
7.3.5 jobtracker(运行 MapReduce job Tracker 节点)
用法:
hadoop jobtracker
7.3.6 namenode(运行 namenode)
用法:
hadoop namenode [-format]|[-upgrade]|[-rollback]|[-finalize]|[-importCheckpoint]
命令选项描述-format格式化namenode。它启动namenode,格式化namenode,之后关闭namenode。-upgrade分发新版本的hadoop后,namenode应以upgrade选项启动。-rollback将namenode回滚到前一版本。这个选项要在停止集群,分发老的hadoop版本后使用。-finalizefinalize会删除文件系统的前一状态。最近的升级会被持久化,rollback选项将再不可用,升级终结操作之后,它会停掉namenode。-importCheckpoint从检查点目录装载镜像并保存到当前检查点目录,检查点目录由fs.checkpoint.dir指定。
7.3.7 secondarynamenode(运行 HDFS 的 secondary namenode)
用法:
hadoop secondarynamenode [-checkpoint [force]]|[-geteditsize]
命令选项描述-checkpoint [force]如果EditLog的大小 >= fs.checkpoint.size,启动Secondary namenode的检查点过程。 如果使用了-force,将不考虑EditLog的大小。-geteditsize打印EditLog大小。
7.3.8 tasktracker(运行 MapReduce 的 task Tracker 节点)
用法:
hadoop tasktracker
08 文末
参考文献:
本文主要讲了
Hadoop
的入门知识,谢谢大家的阅读,本文完!
版权归原作者 杨林伟 所有, 如有侵权,请联系我们删除。