
高级大数据实验
实验一:
1. 计算水仙花数
实验目标;
(1) 掌握scala的数组,列表,映射的定义与使用
(2) 掌握scala的基本编程
实验说明
水仙花数是指其个位、十位、百位三个数的立方和等于这个数本身,用Scala编程求出所有水仙花数。
object shuixianhua {
def main(args:Array([String]): Unit={
for(a<-100 until 1000){
val b=a/100
val c=a%100/10
val d=a%100%10
if(b*b*b+c*c*c+d*d*d==a){
println(a)
}
}
}
}
shuixainhua.main(Array())
2. 使用scala编写函数过滤文本中的回文单词
实验目标;
(3) 掌握scala的数组,列表,映射的定义与使用
(4) 掌握scala的for循环与if判断的使用
(5) 掌握scala的函数式编程
实验说明:
回文是指正向和逆向读起来相同的词,英语中也存在着回文现象,如“mom”和“dad”。
参照给出的英文文档word.txt,使用scala编程读取文件,并且编写一个函数判断文档中的每个单词是否为回文单词,若是则输出该单词。
实现思路及步骤:
(1)读取word.txt数据,将数据
(2)使用flatMap()方法获取缓存区里面的数据,并使用空格进行分割。
(3)定义函数isPalindrom(word:String)
(4) 在函数中判断单词正向与逆向是否一样,若是则输出该单词
(5)调用isPalindrom 函数
import scala.io.Source
object PalindromeFilter {
def main(args: Array[String]): Unit = {
val filePath = "word.txt" // 更改为实际的文本文件路径
// 读取文本文件数据
val words = Source.fromFile(filePath).getLines().flatMap(_.split(" "))
// 过滤回文单词并输出
words.filter(isPalindrome).foreach(println)
}
// 判断单词是否为回文
def isPalindrome(word: String): Boolean = {
word == word.reverse
}
}
3. 使用scala编程输出九九乘法表:
实验目标:
(1) 掌握scala循环的使用
(2) 掌握scala函数式编程
实验说明:
九九乘法表是我国古代人民的智慧结晶,在春秋战国时代就已经在筹算中运算,到明代则改良病用在算盘上。现需要使用scala编程输出九九乘法表,要求输出效果如图所示:
- 使用scala编程输出九九乘法表:
xxxxxxxxxx mkdir -p /u01/app/12.2.0/gridmkdir -p /u01/app/gridmkdir -p /u01/app/oracle/product/12.2.0/dbhome_1chown -R grid:oinstall /u01chown -R oracle:oinstall /u01/app/oraclechmod -R 775 /u01/css
(1) 掌握scala循环的使用
(2) 掌握scala函数式编程
实验说明:
九九乘法表是我国古代人民的智慧结晶,在春秋战国时代就已经在筹算中运算,到明代则改良病用在算盘上。现需要使用scala编程输出九九乘法表。
object chengfabiao{
def main(args: Array[String]): Unit = {
for (i<-1 to 9){
for (j<-1 to i){
print(j+"*"+i+"="+(i*j)+"\t")
}
println()
}
}
}
编辑文章
第二次实验
要去掉Spark中的日志输出,有几种不同的方法可以实现:
import org.apache.log4j.{Level, Logger}
val rootLogger = Logger.getRootLogger()
rootLogger.setLevel(Level.ERROR)
请根据给定的实验数据,在spark-shell中通过编程来计算以下内容:
学生填写代码以及给出最终结果
(1) 该系总共有多少学生;
答案为: 人
(2) 该系共开设来多少门课程;
答案为 门
(3) Tom同学的总成绩平均分是多少;
Tom同学的平均分为 分
(4) 求每名同学的选修的课程门数;
答案共 265行
(5) 该系DataBase课程共有多少人选修;
答案为 人
val rdd= sc.textFile("file:///home/spark/score.txt")
1.
val count = rdd.map(line=>line.split(",")(0)).distinct().count
2.
val countCourse = rdd.map(line=>line.split(",")(1)).distinct().count
3.
val sum = rdd.filter(line=>line.split(",")(0)=="Tom")
val avg = sum.map(name=>(name.split(",")(0),name.split(",")(2).toInt)).mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2)).mapValues(x=>(x._1/x._2)).collect()
4.
val countC = rdd.map(row=>(row.split(",")(0),row.split(",")(1))).mapValues(x=>(x,1)).reduceByKey((x,y)=>(" ",x._2+y._2)).mapValues(x =>x._2).foreach(println)
5
val countPeople = rdd.filter(line=>line.split(",")(1)=="DataBase").count
实验说明:
现有一份某电商2020年12月份的订单数据文件onlin_retail.csv,记录了每位顾客每笔订单的购物情况,包含三个数据字段,字段说明如下表所示。现需要统计每位客户的总消费金额,并筛选出消费金额在前50名的客户。

实现思路及步骤:
(1) 读取数据并创建RDD
(2) 通过map()方法分割数据,选择客户编号和订单价格字段组成键值对数据
(3) 使用reduceByKey()方法计算每位客户的总消费金额
(4) 使用sortBy()方法对每位客户的总消费金额进行降序排序,取出前50条数据
val rdd= sc.textFile("file:///home/spark/online_retail.txt")
val bianhao = rdd.mapPartitionsWithIndex((index, iter) => {
if (index == 0) {
iter.drop(1) // 跳过第一行
} else {
iter
}
}).map(line => {
val fields = line.split(",").map(_.trim)
if (fields.length > 1 && fields(0).nonEmpty) {
Some((fields(0), fields(1).toDouble))
} else {
None
}
}).filter(_.isDefined).map(_.get)
bianhao.collect().foreach(println)
bianhao.take(10).foreach(println)
val totalSpentPerCustomer = bianhao.map{ case (customerId, price) => (customerId, price) }.reduceByKey(_ + _)
totalSpentPerCustomer.collect().foreach(println)
totalSpentPerCustomer.take(10).foreach(println)
val jiangxu = totalSpentPerCustomer.sortBy(_._2, ascending = false)
jiangxu.take(50).foreach(println)
实验说明:
现有一份各城市的温度数据文件avgTemperature.txt,数据如下表所示,记录了某段时间范围内各城市每天的温度,文件中每一行数据分别表示城市名和温度,现要求用spark编程计算出各城市的平均气温。
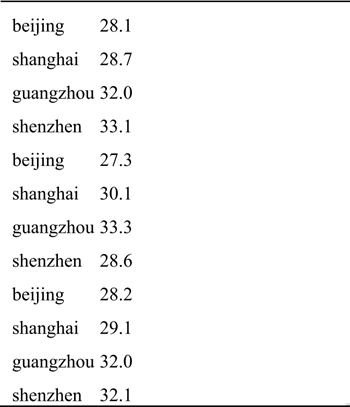
实现思路及步骤:
(1) 通过textFile()方法读取数据创建RDD
(2) 使用map()方法将数据输入数据按制表符进行分割,并转化成(城市,温度)的形式
(3) 使用groupBy()方法按城市分组,得到每个城市对应的所欲温度。
(4) 使用mapValues()和reduce()方法计算各城市的平均气温
val rdd= sc.textFile("file:///home/spark/avgTemperature.txt")
val cityTemperatures = rdd.map(line => {
val Array(city, temperature) = line.split("\t") // 使用制表符"\t"进行分割
(city, temperature.toDouble) // 生成键值对
})
val cityWiseTemperatures = cityTemperatures.groupBy(_._1).mapValues(_.map(_._2))
cityWiseTemperatures.collect().foreach(println)
val cityAvgTemperatures = cityTemperatures.groupBy(_._1).mapValues(values => {
val totalTemp = values.map(_._2).sum
val count = values.size
totalTemp / count
})
cityAvgTemperatures.collect().foreach(println)
学习通第二章作业
“双减”政策落地后,为了体现“分数是一时之得,要从一生的长远目标来看”教育,需要通过大数据技术分析部分考试数据来提高学校老师的教学质量。某学校某班级经过期中考试后,该班级中每位同学的各科目考试成绩保存在一份文件primary_midsemester.txt中,文件共有5个数据字段,分别为学生学号(ID)、性别(gender)、语文成绩(Chinese)英语成绩(English)、数学成绩(Math),部分数据如表2-8所示。
表 2-8 某学校某班级的学生各科目考试成绩部分数据
ID性别汉语英语数学301610男80号6478301611女65 87 58301612女性447177301613女66 7191301614女7071 100301615男72 77 72301616女73 81 75301617女69 77 75301618男73 61 65
为了分析各科目老师的教学质量,请使用scala(Scala)函数式编程分别统计各科目考试成绩的平均分、最低分和最高分。
val source = sc.textFile("file:///home/hadoop/primary_midsemester.txt")
val headerLine = source.first()
val remainingLines = source.filter(_ != headerLine)
val thirdColumn = remainingLines.map(line => {
val columns = line.split("\s+")
columns(2).toInt
})
val thirdColumn1 = remainingLines.map(line => {
val columns = line.split("\s+")
columns(3).toInt
})
val thirdColumn2 = remainingLines.map(line => {
val columns = line.split("\s+")
columns(4).toInt
})
val avg1: Double = thirdColumn.reduce(_ + ).toDouble / thirdColumn.count()
val avg2: Double = thirdColumn1.reduce( + ).toDouble / thirdColumn1.count()
val avg3: Double = thirdColumn2.reduce( + ).toDouble / thirdColumn2.count()
val columns = headerLine.split(" ") // 使用split方法按空格分隔
val name1 = columns(2)
val name2 = columns(3)
val name3 = columns(4)
val maxScore = thirdColumn.aggregate(Int.MinValue)( max _, _ max )
val minScore = thirdColumn.aggregate(Int.MaxValue)( min _, _ min _)
val maxScore1 = thirdColumn1.aggregate(Int.MinValue)(_ max _, _ max )
val minScore1 = thirdColumn1.aggregate(Int.MaxValue)( min _, _ min _)
val maxScore2 = thirdColumn2.aggregate(Int.MinValue)(_ max _, _ max )
val minScore2 = thirdColumn2.aggregate(Int.MaxValue)( min _, _ min _)
println(s"${name1}的最高分是: $maxScore; 最低分是:$minScore;${name2}的最高分是: $maxScore1; 最低分是:$minScore1;${name3}的最高分是: $maxScore2; 最低分是:$minScore2")
print(s"${name1}的平均分是$avg1;${name2}的平均分是$avg2;${name3}的平均分是$avg3")
版权归原作者 wkp0311 所有, 如有侵权,请联系我们删除。