
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
篇一:Linux系统下配置java环境
篇二:hadoop伪分布式搭建(超详细)
篇三:hadoop完全分布式集群搭建(超详细)-大数据集群搭建
文章目录
1.Spark Local环境搭建介绍

Spark单机版的搭建,常用于本地开发测试
Spark使用Scala语言编写,运行在Java虚拟机(JVM)当中,故在安装前检查下本机的Java虚拟机环境。用命令查询当前Java版本是否为6以上。
2.搭建环境准备:
本次用到的环境为:
Java 1.8.0_191
Spark-2.2.0-bin-hadoop2.7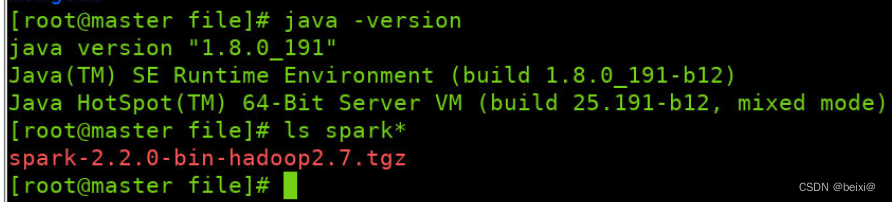
3.搭建步骤:
1.将spark安装包spark-2.2.0-bin-hadoop2.7.tgz解压至路径/opt目录下:
tar zvxf spark-2.2.0-bin-hadoop2.7.tgz -C /opt
2.为了方便维护,将解压后的spark-2.2.0-bin-hadoop2.7文件夹更名为spark
mv /opt/spark-2.2.0-bin-hadoop2.7 /opt/spark
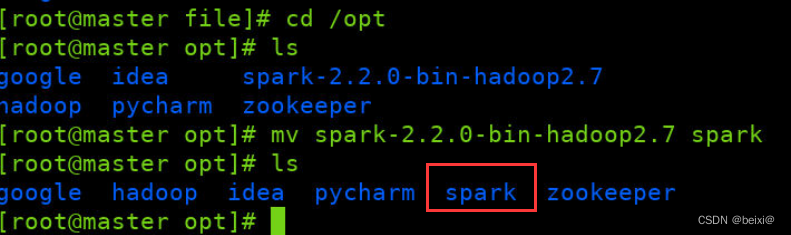
3.通过vi命令打开配置环境变量文件profile,将Spark环境配置到环境变量文件中
vi /etc/profile
在配置文件中,键入GG移动到配置文件最后一行,再键入i进入可编辑状态,输入以下环境变量设置:
exportSPARK_HOME=/opt/spark
exportPATH=$SPARK_HOME/bin:$PATH
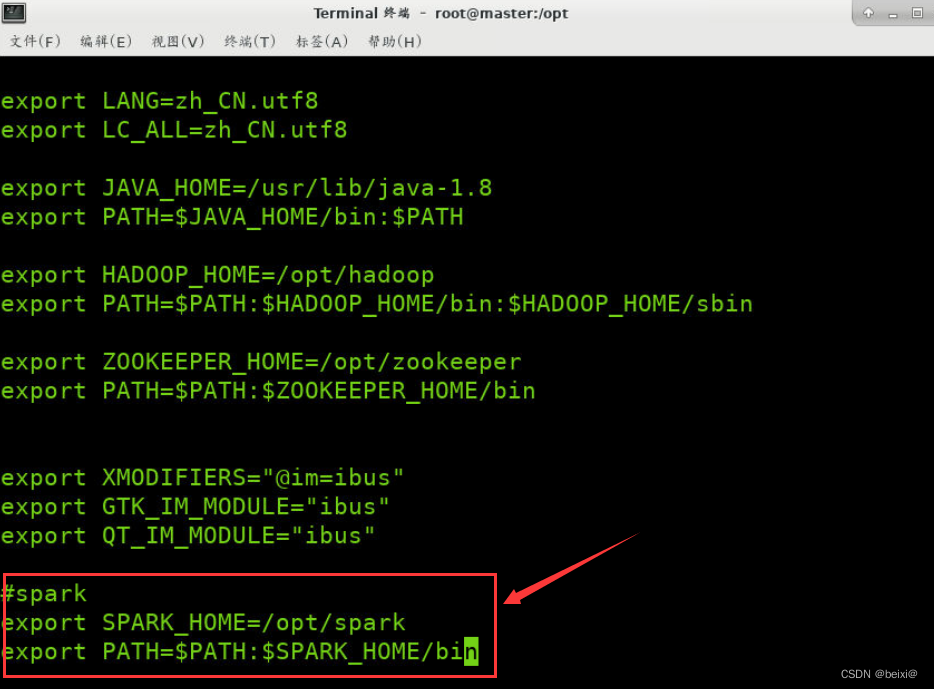
4.从键盘按ESC键,使文件profile退出编辑状态,从键盘输入“:wq!”命令保存对profile文件的更改,并使刚刚的配置内容生效
source /etc/profile

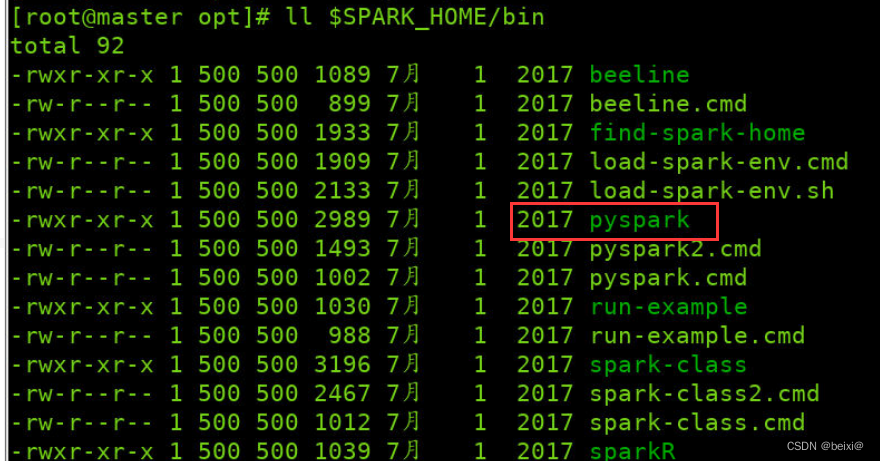
5.查看Spark命令列表,其中pyspark为启动Spark下Python的命令
ll $SPARK_HOME/bin
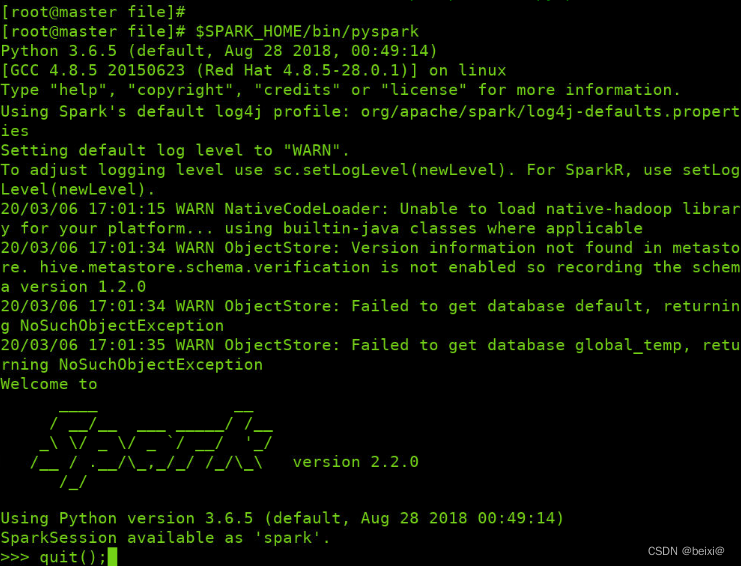
6.利用Spark启动Python环境,并通过quit命令退出该环境
$SPARK_HOME/bin/pyspark
quit();
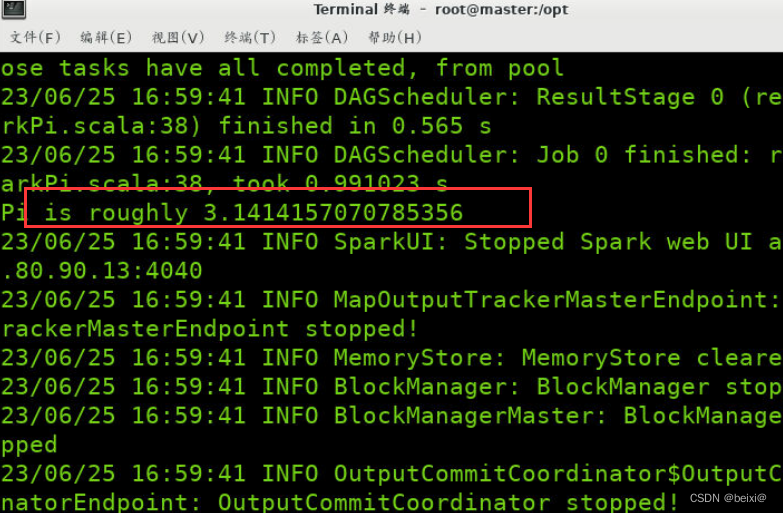
6.使用Spark自带的示例程序进行测试。本次使用的测试程序为SparkPi,SparkPi会将计算圆周率并将计算结果打印至控制台。
$SPARK_HOME/bin/spark-submit --master local[3] --class org.apache.spark.examples.SparkPi /opt/spark/examples/jars/spark-examples_2.11-2.2.0.jar
如果本篇文章对你有帮助,记得点赞关注+收藏哦~
本文转载自: https://blog.csdn.net/beixige/article/details/131335511
版权归原作者 beixi@ 所有, 如有侵权,请联系我们删除。
版权归原作者 beixi@ 所有, 如有侵权,请联系我们删除。