
基于Hadoop3.3.6+Spark3.4.3电商用户行为分析
一、摘要
电商用户分析是指对电商平台上的用户进行细分和分析,以了解用户特征、行为和需求,从而优化产品、服务和营销策略。本文主要利用Spark框架分析用户在电商平台上的行为,如浏览商品、购买商品、添加到购物车等,以了解用户的购买意愿、偏好和行为路径,针对其中部分数据分别统计出用户点击行为、下单行为、支付行为以及网站的浏览量PV等数据,进而分析电商系统的用户转化率、用户留存率等指标,帮助电商企业更好的实现经营目标。
二、正文
2.1 需求分析
- 需求&要求:分析电商用户行为数据,按照天、周、月为时间单位,分别统计出用户点击行为、下单行为、支付行为以及网站的浏览量PV等,并将分析结果以用户行为漏斗图的方式进行可视化。
- 数据分析:电商用户行为数据通常被记录在日志文件中,即Log文件,以文本文件形式存储在服务器中。该日志文件作为分析的对象。
- 技术路线分析:可采用大数据离线分析方式,采用Flume+Hadoop+Spark作为大数据采取、数据存储与分布式计算的框架,并由此构成大数据平台。为突出数据存储与计算部分内容,本文省略了数据采集框架的介绍,直接手动将已有的电商日志文件进行分析,在本地测试和验证分析结果的准确性后,再将程序打包上传到大数据平台中。
2.2 架构设计
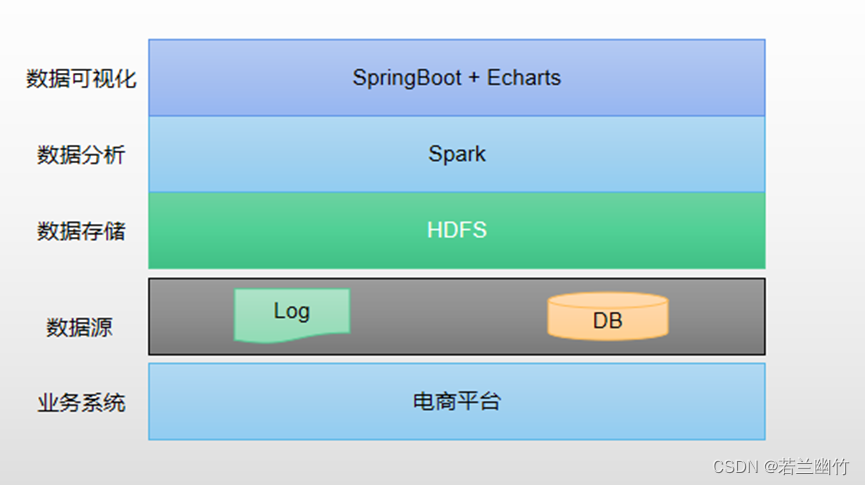
- 系统整体流程介绍: 本系统采用Spark框架对电商日志进行处理和分析,并将处理结果存入MySQL中,再通过springboot框架实现对MySQL数据的读取后,最后利用thymeleaf模板引擎渲染加载html代码,并引入echarts对最终的结果数据进行漏斗图的方式进行可视化
- 系统整体构成: 本系统总统由三部分组成:- 前端网站(技术架构可采取Vue+ElementUI等开发)- 后台服务(后台程序,可选择SpringBoot进行开发)- 大数据平台(可选择flume+hadoop+spark构成)因总体项目比较大,因此本文只重点介绍如何通过Spark程序分析用户行为日志后,将分析结果写入到mysql表中,并通过springboot后台程序读取后,将其渲染到后台管理界面中。至于前端网站中展示结果,读者可根据实际情况进行操作。
- 系统架构图:
2.3 实施过程
2.3.1 系统环境说明
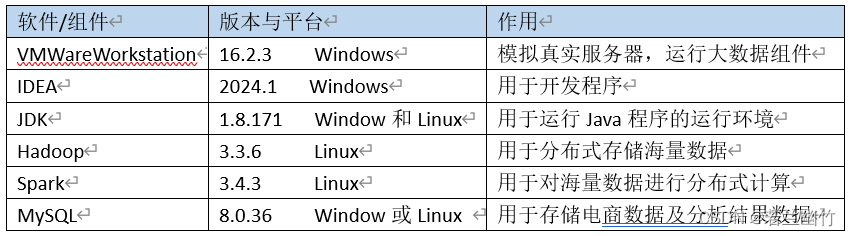
上述软件版本可根据实际情况进行调整,如hadoop可选择3.x版本,spark也可选择最新版本。
2.3.2 系统开发思路说明
首先,获取电商平台的行为日志Log文件(正常生产环境中一般由Flume采集),如读者没有真实的电商数据,以下两种方法可获取或自行生成:
- 网上爬取,已经得到
- 编写程序,由程序模拟生成
然后,利用Spark对Log日志进行分析,将分析结果写入MySQL中(
重点内容
)
最后,利用Springboot+thymeleaf+echarts读取MySQL结果数据进行展示。
2.3.4 代码实现及测试
- 创建用于spark程序编写的maven项目,并添加如下依赖:
<modelVersion>4.0.0</modelVersion><groupId>com.ecommerce</groupId><artifactId>spark-analysis</artifactId><version>1.0</version><packaging>jar</packaging><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><!-- <scala.version>2.12.15</scala.version>--><spark.version>3.4.3</spark.version><spark.artifact.version>2.12</spark.artifact.version><hadoop.version>3.3.6</hadoop.version></properties><dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_${spark.artifact.version}</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><!-- 使用scala2.11.8进行编译和打包 --><!-- <dependency>--><!-- <groupId>org.scala-lang</groupId>--><!-- <artifactId>scala-library</artifactId>--><!-- <version>${scala.version}</version>--><!-- </dependency>--><!-- 引入MySQL驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.12</version></dependency></dependencies><build><!-- 指定scala源代码所在的目录 --><sourceDirectory>src/main/scala</sourceDirectory><testSourceDirectory>src/test/scala</testSourceDirectory><plugins><!--对src/main/java下的后缀名为.java的文件进行编译 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration></plugin><!-- scala的打包插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>4.5.4</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions><!-- <configuration>--><!-- <scalaVersion>${scala.version}</scalaVersion>--><!-- </configuration>--></plugin></plugins></build> - 创建用于springboot程序编写maven项目,并添加如下依赖:
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.4.RELEASE</version><relativePath/><!-- lookup parent from repository --></parent><modelVersion>4.0.0</modelVersion><groupId>com.ecommerce.web</groupId><artifactId>springboot-echarts</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><java.version>1.8</java.version><slf4j.version>1.7.22</slf4j.version><log4j.version>1.2.17</log4j.version><mysql.version>8.0.12</mysql.version><mybatis-plus.version>3.0.5</mybatis-plus.version><httpclient.version>4.5.1</httpclient.version><fastjson.version>1.2.28</fastjson.version><gson.version>2.8.2</gson.version><json.version>20170516</json.version><commons-dbutils.version>1.7</commons-dbutils.version><jodatime.version>2.10.1</jodatime.version><lombok-version>1.18.12</lombok-version><spring-starter-version>2.3.4.RELEASE</spring-starter-version><spring-starter-web-version>2.3.4.RELEASE</spring-starter-web-version></properties><dependencies><!--Spring boot--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--Spring boot 热启动--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId
标签:
大数据
本文转载自: https://blog.csdn.net/sujiangming/article/details/138510693
版权归原作者 若兰幽竹 所有, 如有侵权,请联系我们删除。
版权归原作者 若兰幽竹 所有, 如有侵权,请联系我们删除。