
Hive的表查询
1. 前置准备
实验环境
- Oracle Linux 7.4
- Java1.8.0_144
- Hadoop2.7.4
- Hive2.1.1
实验数据
查看完userinfo1.txt文件内容

查看完userinfo2.txt文件内容

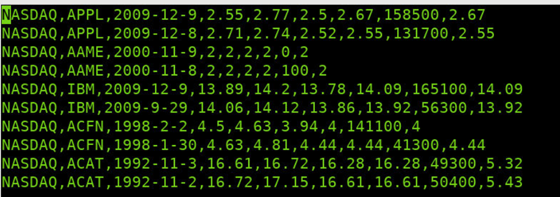
数据文件stocks.csv内容
stocks.csv内容以逗号“,”分隔,依次记录股票代码、股票交易日期、股票开盘价、股票开盘价、股票最低价、股票收盘价、股票交易量和股票成交价。
2. 实验流程
2.1 创建表
创建外部表userinfos存放数据
CREATE external TABLE userinfos (
uname STRING,
salary FLOAT,
family ARRAY <STRING>,
deductions MAP <STRING,FLOAT>,
address STRUCT<street:STRING,city:STRING,state:STRING,zip:INT>) PARTITIONED BY(country String)row format delimited fieldsterminatedby'\001'
collection items terminatedby'\002'
MAP KEYSterminatedby'\003'LINESterminatedby'\n'
stored as textfile;

查询userinfos表结构信息,可以看到表的字段信息及分区等的信息。

2.2 导数据
从本地数据存储位置加载数据到userinfos表中,其中country是分区字段。
-- 01loaddatalocal inpath '/root/experiment/datas/hiveselect/userinfo1.txt' overwrite intotable userinfos partition(country='China');-- 02loaddatalocal inpath '/root/experiment/datas/hiveselect/userinfo2.txt' overwrite intotable userinfos partition(country='America');

2.3 表查询
查询userinfo表被导入数据后,在HDFS平台上的存储情况。

查询userinfos表内容信息,并将每条数据所在的分区展示。

2.4 再建表
创建stock表,做查询
-- stockCREATE EXTERNAL TABLE stocks(
exchanger STRING,
symbol STRING,
ymd STRING,
price_open FLOAT,
price_high FLOAT,
price_low FLOAT,
price_close FLOAT,
volume INT,
price_adj_close FLOAT)ROW FORMAT DELIMITED FIELDSTERMINATEDBY',';

从本地数据存储位置hiveselect文件夹下加载数据到stocks表中。并查看导入数据后在HDFS中的存储情况。
loaddatalocal inpath '/root/experiment/datas/hiveselect/stocks.csv' overwrite intotable stocks;

2.5 表查询
2.4.1 基本查询
LIMIT应用:按指定字段查询前3条数据。
select uname,salary from userinfos limit3;
分区查询:查询userinfo表中分区为“China”下的所有指定字段的内容。其中指定的字段为:uname、salary、country。
select uname,salary,country from userinfos where country='China';

嵌套Select语句、别名应用:其中语句 “address.street AS stree”中,address.street代表查询的字段,stree代表这个字段,即用stree查询与用address.street查询是一个效果。而t代表整个“SELECT address.street AS street,address.city AS city FROM userinfo”语句,由from指定查询的t表中street字段。
from(SELECT address.street AS street,address.city AS city FROM userinfo) t select t.street;

2.4.2 分组查询
分组查询:按股票交易码symbol进行分组,并求出每组股票的平均关盘价格。
SELECT symbol,avg(price_close)FROM stocks GROUPBY symbol;

2.4.3 连接查询
条件查询 内连接:查看IBM公司和苹果(APPL)公司收盘价每日价格对比表。要求只显示IBM公司和苹果(APPL)公司共同存在的收盘价格比对表。
select a.ymd,a.price_close,b.price_close from(select ymd,price_close from stocks where symbol='APPL') a,(select ymd,price_close from stocks where symbol='IBM') b
where a.ymd=b.ymd;


条件查询 左外连接:查看IBM公司和苹果(APPL)公司收盘价每日价格对比表。要求苹果(APPL)公司内容全显示,IBM公司有对应数据显示,没有为NULL。
select a.ymd,a.symbol,b.symbol,a.price_close,b.price_close
from(select*from stocks where symbol='APPL') a
LEFTOUTERJOIN(select*from stocks where symbol='IBM') b
ON a.ymd=b.ymd;

条件查询 右外连接:查看IBM公司和苹果(APPL)公司收盘价每日价格对比表。要求IBM公司内容全显示,苹果(APPL)公司有对应数据显示,没有为NULL。
select a.ymd,a.symbol,b.symbol,a.price_close,b.price_close
from(select*from stocks where symbol='APPL') a
RIGHTOUTERJOIN(select*from stocks where symbol='IBM') b
ON a.ymd=b.ymd;

条件查询 全连接:查看IBM公司和苹果(APPL)公司收盘价每日价格对比表,要求IBM公司与苹果(APPL)公司所有数据全显示,数据未对应位置用NULL值补齐。
select a.ymd,a.symbol,b.symbol,a.price_close,b.price_close
from(select*from stocks where symbol='APPL') a
FULLOUTERJOIN(select*from stocks where symbol='IBM') b
ON a.ymd=b.ymd;

3. 总结
子查询
Hive支持的子查询是放在FROM字句中的,因为每个表的FROM字句必须要有一个别名,所以子查询也就有了一个别名。在子查询中的SELECT列表名必须是唯一的,这些SSELECT列表名在外层的SELECT查询中就像表中的列一样是可用的。子查询可以是含有UNION的查询表达式,Hive支持任意层次的子查询。
连接查询
连接查询(join)是将两个表在共同数据项上相互匹配的那些行合并后进行查询的操作.HQL的连接查询分为内连接(Inner Join) 、左外连接(left join)、右外连接(right join)、全连接和半连接(本篇未涉及)
申明:
文章仅做记录,涉及侵权内容请联系删除
版权归原作者 会撸代码的懒羊羊 所有, 如有侵权,请联系我们删除。