
介绍
在本文中,我们将分析一个经典的序列对序列(Seq2Seq)模型的结构,并演示使用注意解码器的优点。这两个概念将为理解本文提出的Transformer奠定基础,因为“注意就是您所需要的一切”。
本文内容:
- 什么是Seq2Seq模型?
- 经典的Seq2Seq模型是如何工作的?
- 注意力机制
什么是Seq2Seq模型?
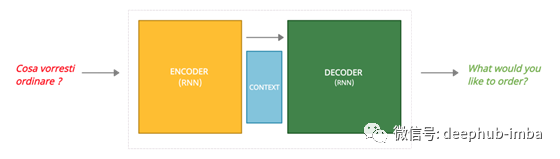
在Seq2seq模型中,神经机器翻译以单词序列的形式接收输入,并生成一个单词序列作为输出。例如,意大利语的“Cosa vorresti ordinare?”作为输入,英语的输出是“What would you like to order?”。另外,输入可以是一幅图像(图像字幕)或一长串单词(文本摘要)。
经典的Seq2Seq模型是如何工作的?
一个Seq2Seq模型通常包括:
- 一个编码器
- 一个解码器
- 一个上下文向量
请注意:在神经机器翻译中,编码器和解码器都是rnn
编码器通过将所有输入转换为一个称为上下文的向量(通常具有256、512或1024的长度)来处理所有输入。上下文包含编码器能够从输入中检测到的所有信息(请记住,输入是在本例中要翻译的句子)。然后向量被发送到解码器,由解码器确定输出序列。
神经机器翻译中的时间步长
现在我们已经对序列到序列模型有了一个高层次的概述,让我们简要分析一下如何处理输入。
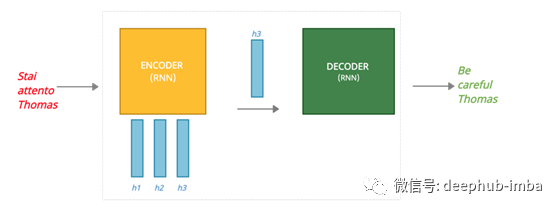
时间步骤#1:将意大利语单词“Stai”发送到编码器编码器根据其输入和之前的输入更新其隐藏状态(h1)。
时间步骤#2:单词“attento”被发送到编码器编码器根据其输入和之前的输入更新其隐藏状态(h2)。
时间步骤#3:单词“Thomas”被发送到编码器编码器根据其输入和之前的输入更新其隐藏状态(h3)。
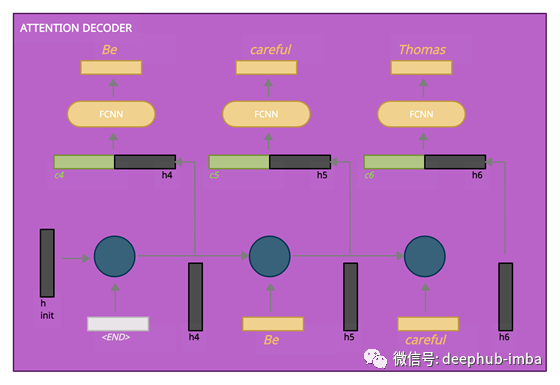
时间步骤#4:最后一个隐藏状态成为发送到解码器的上下文解码器产生第一个输出“Be”
时间步骤#5:解码器产生第二个输出“careful”
时间步骤#6:解码器产生第三个输出“Thomas”
编码器或解码器的每一步都是RNN处理其输入并生成该时间步长的输出。正如您可能注意到的,我们最后的隐藏状态(h3)成为发送到解码器的内容。这就是经典序列对序列模型的局限性;编码器“被迫”只发送一个向量,不管输入的长度是多少,也就是我们的句子包含了多少个单词。即使我们决定在编码器中使用大量隐藏单元以获得更大的上下文,模型也会与短序列过度匹配,并且随着参数数量的增加,我们的性能也会受到影响。
但是注意力能解决这个问题!
注意力机制
在这一点上,我们知道要解决的问题在于上下文向量。这是因为,如果输入是一个包含大量单词的句子,那么模型就会陷入麻烦。badanua等和Loung等人提出了一种解决方案。这两篇论文介绍并改进了“注意力”的概念。这种技术通过关注输入序列的相关部分,使机器翻译系统得到了相当大的改进。
思路
带有注意力的Seq2Seq模型中的编码器的工作原理与经典的类似。一次接收一个单词,并生成隐藏状态,用于下一步。随后,与之前不同的是,不仅最后一个隐藏状态(h3)将被传递给解码器,所有的隐藏状态都将被传递给解码器。

编码器
在到达编码器之前,我们的句子中的每个单词都通过嵌入过程转换为一个向量(大小为200或300)。第一个单词,在我们的例子中是“Stai”,一旦它转换为一个向量就被发送到编码器。在这里,RNN的第一步产生第一个隐藏状态。同样的场景也会发生在第二个和第三个单词上,总是考虑到之前隐藏的状态。一旦我们的句子中的所有单词都被处理完,隐藏状态(h1, h2, h2)就会被传递给注意力解码器。
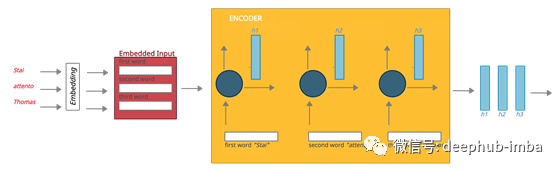
注意力译码器
首先,注意力解码器中添加了一个重要过程:
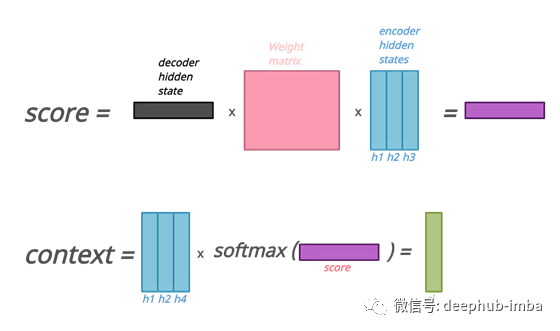
- 每个隐藏状态都有一个分数。
- 分数通过softmax函数。
- 隐藏状态和相关的softmax分数相互相乘
- 最后,将得到的隐藏状态相加,得到单个向量,即上下文向量。
这个过程允许我们放大我们序列中重要的部分,减少不相关的部分。此时,我们必须理解如何将分数分配给每个隐藏状态。你还记得badanau和Luong吗?为了更好地理解注意力解码器内部发生了什么以及分数是如何分配的,我们需要更多地谈谈点积注意力。
点积注意力(multiplicative**attention)是利用先前对加法注意所做的研究而发展起来的。在“基于注意力的神经机器翻译的有效方法”一文中,Loung介绍了几个注意力评分的方法:
一般方法、点积 、合并(concat)
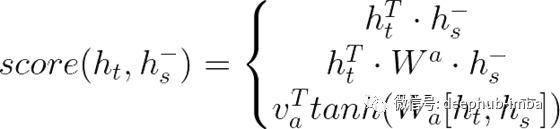
在这篇文章中,我们将分析一般注意力机制(公式中间的部份)。
这是因为在我们的例子中,一旦确定每种语言都有自己的嵌入空间,编码器和解码器就没有相同的嵌入空间。
我们可以直接将解码器的隐藏状态、权值矩阵和编码器的隐藏状态集相乘得到分数。
现在我们已经知道了如何计算分数,让我们尝试着理解Seq2Seq模型中的注意力解码器是如何工作的。
第一步,注意解码器RNN嵌入<END>令牌(表示语句结束),并将其进入初始解码器隐藏状态。RNN处理其输入,生成输出和新的解码器隐藏状态向量(h4)。这时输出被丢弃,从这里开始“注意力”步骤:
1-为每个编码器隐藏状态分配一个注意力公式中计算的分数。
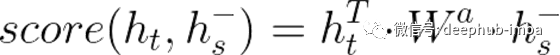
2-分数通过softmax函数。

3-编码器隐藏状态和相关softmax分数相乘。将获得的隐藏状态添加到上下文向量(c4)中。

4-上下文向量(c4)与解码器隐藏状态(h4)连接。
由连接产生的向量通过一个完全连接的神经网络传递,该神经网络基本上是乘以权值矩阵(Wc),并应用tanh激活。这个完全连接的层的输出将是输出序列中的第一个输出单词(输入:“Stai”->输出:“be”)。
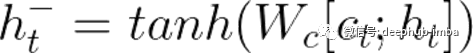
第二个时间步骤从第一步的输出(“Be”)开始,并产生解码器隐藏状态(h5)。所有这些都遵循上面描述的注意步骤。重复以上时间步骤中描述的过程。
总结
非常感谢您花时间阅读本文。我希望本文能使您对经典的Seq2Seq模型以及带有注意力的Seq2Seq有一个很好的初步了解。
引用
- Bahdanua et al., "Neural Machine Translation by Jointly Learning to Align and Translate"
- Loung et al., "Effective Approaches to Attention-based Neural Machine Translation"
- Visualizing a Neural Machine Translation Model (Mechanics of Seq2seq Model With Attention) by Jay Alammar
作者:Muhamed Kouate
原文地址:https://towardsdatascience.com/classic-seq2seq-model-vs-seq2seq-model-with-attention-31527c77b28a
deephub翻译组