
对于自然场景的文字识别我们会遇到了许多不规则裁剪的图像,其中包含文本表示。虽然已经引入了许多复杂的想法来从图像中提取确切的文本。例如光学字符识别 (OCR)、基于 RNN 的 seq2seq 注意方法都是被认为是从结构图像中提取序列信息的传统方法,但许多研究人员发现,很难处理不规则图像和训练时间使他们更加昂贵。基于 RNN 的 seq2seq 注意力方法需要输入的序列表示,这些输入因输入而异,因此很难训练数百万张图像。大多数时间模型无法预测文本或字符,因为我们正在处理自然场景图像。
基本上,如果我们选择任何模型,我们会发现所有模型都有一个共同点,即 自注意力self-attention。它使模型能够通过位置对计算绘制序列中不同位置之间的依赖关系。但是自注意力方法在词序列中有效,其中注意力机制可以查看句子中的所有词序列。在将图像翻译成文本的情况下,很难理解特征图并创建依赖关系。简而言之,我将解释两个模型,它们使用强大而复杂的方法将二维 CNN 特征直接连接到基于注意力的序列编码器和解码器,以整体表示为指导,并使用 ResNet 和 Transformer 的概念来解决图像文本识别问题.
本文的目录
- 业务问题
- 性能指标
- 数据源
- 探索性数据分析
- ResNet架构简介
- 简介 Transformer 架构
业务问题
在现实世界中,大多数时候我们都会遇到不同形式的图像。它可以是规则的、不规则的图像以及其中的文本格式。从它们中提取字符串是一项具有挑战性的任务。因此,我们得到了一个包含 5000 张不规则和自然场景图像的数据集,业务问题是使用最先进的深度学习概念从它们中成功预测字符串。
性能指标
我们使用了自定义准确度度量,即给定预测和真实字符串的字符序列匹配总数除以真实字符串中的字符总数的比率。
数据集
- ICDAR_2017_table_dataset:http://cvit.iiit.ac.in/research/projects/cvit-projects/the-iiit-5k-word-dataset
探索性数据分析
由于我们使用的是 IIIT 5K 字数据集,其中包含总共 5000 个文本图像及其对应的 .mat 格式的注释文件。我们必须提取带有字符串的图像。
一些带有真实字符串字符的随机图像如下所示:-
#Displaying iamge with groundtruth string charcters
for (batch, (inp, tar)) in enumerate(train_batches):
if batch == 3:
break
plt.figure(figsize=(3, 3))
plt.title('Image' )
plt.imshow(tf.keras.preprocessing.image.array_to_img(inp[0][0]))
print(str(tar))
plt.axis('off')
plt.show()


ResNet架构简介
深度学习模型处理训练相当多的隐藏层。最近的证据表明,更深的网络非常重要,并且在 ImageNet 数据集中给出了出色的结果。训练时间与我们使用的隐藏层数和激活函数类型成正比。所以训练更深的神经网络更加困难。在大型神经网络中,我们大多会遇到反向传播时梯度消失等问题。
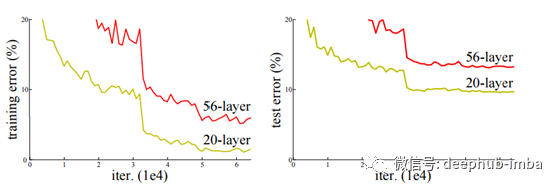
正如我们所看到的,简单地堆叠层并不能减少训练错误和模型过拟合问题。但是为了解决这个问题,我们可以在隐藏层之间添加一个中间归一化层来解决收敛问题以及反向传播时的过度拟合问题。
那么问题就来了,如果我们可以用中间归一化层解决梯度问题,为什么还需要 ResNet 概念?
随着我们增加隐藏层,训练错误会暴露出来,从而降低模型性能。研究人员发现,退化与过度拟合无关,而只是由于增加了更多层而导致模型难以优化。因此,为了解决这个问题,ResNet 在堆叠层的顶部引入了映射,为梯度的反向传播提供了干净的网络。
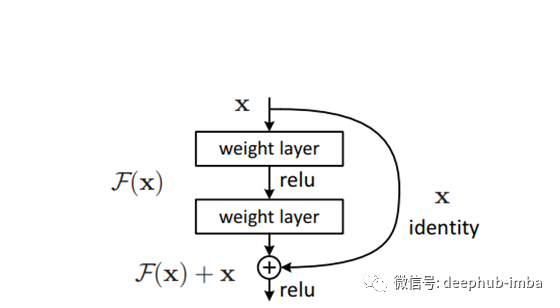
F(x)定义了堆叠层的输出,可以是2层或更多层的大小。然后,在relu激活之前,添加快捷连接和剩余输出。该操作既不增加额外的参数,也不增加计算复杂度,而且可以很容易地帮助使用SGD进行反向传播。通过这种机制,我们可以在不影响训练精度的情况下训练更深层次的神经网络。通过这种方式,并添加“n”层数堆叠在一起,加上映射创建了ResNet架构。
残差网络单位映射的数学方程为:-
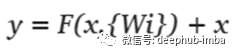
在上面的函数中,F(x,{Wi})表示整个堆叠层需要学习的残差映射,x是添加残差的快捷连接,条件是两者必须是相同维数。
还有另一种解释这个概念的方式,那就是“公路网络”。这种机制有点类似于 LSTM 网络。在高速公路网络中,我们不能控制要添加到下一层的信息量。它具有数据依赖性,并且具有 ResNet 架构中没有的参数。但是发现性能方面的 Resnet 更具适应性,可以解决退化问题。
研究人员对普通网络和残差网络进行了映射神经网络的实验,发现后一种模型即使添加额外的层数也表现得更好。我们可以比较具有相同数量的参数、深度、宽度和计算代价的普通网络和残差网络,发现其结果更有利于ResNet。
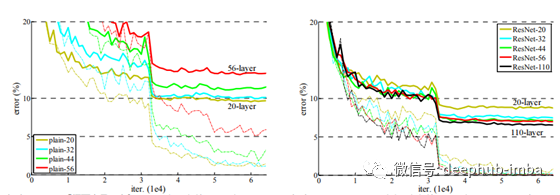
有不同类型的 ResNet。其中一些示例是 ResNet 32、ResNet 50、ResNet 101 等。它们之间的共同区别是堆叠层内的层数以及相互添加的堆叠层数。
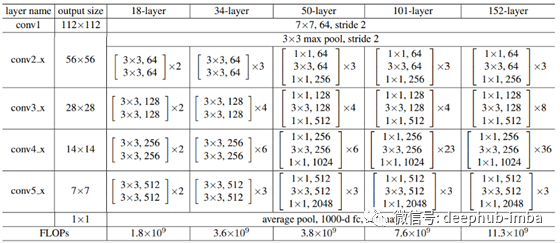
现在的问题是为什么我们需要 ResNet 架构而不是 VGG 进行特征提取预训练?
由于我们知道深度学习网络相当深,这可能需要较高的计算能力,并且随着网络深度的增加,模型发生过度拟合并增加训练误差的可能性更高。在图像到文本任务中,我们需要一个可以更深入但计算成本低并提供更好精度增益的网络。ResNet 战胜了所有其他模型的 ImageNet 检测、ImageNet 定位、COCO 检测和 COCO 分割挑战。
ResNet 最独特之处在于,即使增加了层数,它的复杂度仍然低于 VGG-16/19。
Transformer架构简介
在 Transformer 进化之前,序列模式是使用称为 RNN 网络的概念进行训练的。但是 RNN 在记忆长词序列的过去信息方面非常失败,因此无法预测下一个序列词。为了解决这个问题,引入了长短期记忆(LSTM),它具有内部遗忘门和添加门。遗忘门只允许来自先前时间步的信息部分传递到下一个时间步,而添加门允许来自当前时间步的信息量与先前信息的部分相加。这个概念可以通过额外添加注意力概念来解决单词之间的长期依赖关系。它仍然无法捕获大句子的依赖关系,比如 1000 个单词的句子。此外,我们知道句子的长度因句子而异,因此训练时间因句子而异。因为在反向传播梯度时,我们必须为每个输入句子展开 LSTM 网络并在每个时间步计算梯度,因此会导致训练时间过长。
因此,为了解决所有这些问题,研究人员提出了强大而简单的网络架构“Transformer”,它是一种基于注意力的机制,具有与递归模型相同的特征。最重要的是,我们可以在可行的时间内将并行化应用于训练。
名为“Attention Is All You Need”的研究论文引入了称为自我注意的概念,它查看输入的句子并创建甚至对长句子也能很好地工作的单词依赖性。注意机制在完成阅读理解、机器翻译、问答建模等任务时是成功的。它是一种简单的循环注意机制,具有端到端的记忆网络。它不需要序列对齐的 RNN 或卷积网络,但可以提供更好的结果。
完整的 Transfomer 架构如下所示:-
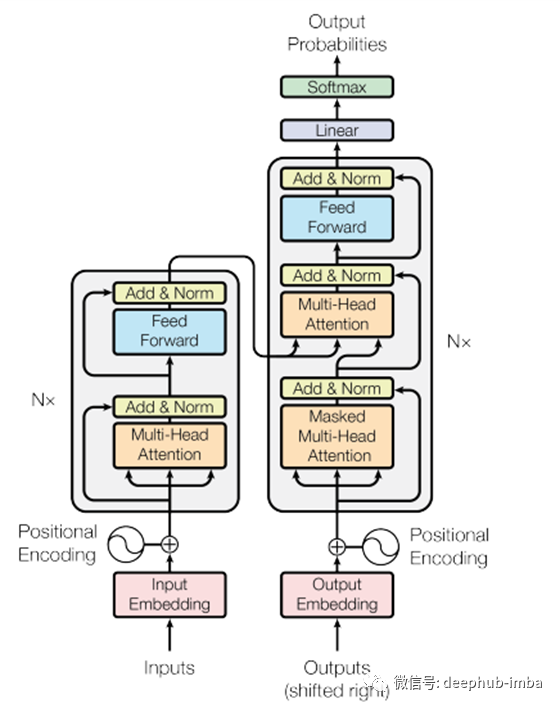
我将把架构分解成几部分,并为每个内部部分给出一个简短的理由。
整个架构分为编码器和解码器两部分。左半部分是“编码器”,右半部分是“解码器”。
编码器:- 它有 N 个堆叠的相同层,其中 N 可以是超参数。它细分为两部分,即多头机制和位置前馈网络。对于来自位置编码的每个堆叠层输入向量并行通过多头和快捷连接,多头的输出与快捷连接相加,然后进行层归一化。然后输出将通过一个前馈网络,该网络分别且相同地应用于每个位置。每个子层都引入了残差网络,以便在反向传播时容易收敛。
解码器:- 它也是 N 个堆叠的相同层,其中 N 可以是超参数。它细分为 3 部分,即掩蔽多头机制、2D 多头机制和位置前馈网络。对于来自位置编码的每个堆叠层,输入向量并行通过 Masked Multi-head 和shortcut connection,Masked multi-head 的输出添加有short cut connection,然后进行层归一化。然后输出将通过下一个多头注意力,其中还引入了编码器层的输出。然后输出将通过前馈网络,该网络分别且相同地应用于每个位置。每个子层都引入了残差网络,以便在反向传播时容易收敛。
让我们按时间顺序讨论整个架构。为简单起见,我们假设一个编码器和一个解码器层。
与我们按顺序传递输入词的 RNN 模型不同,我们不需要执行相同的过程。我们将一次传递整个句子或一批句子,然后进行词嵌入。
词嵌入将通过边训练边学习为每个词分配 d 维向量。为了确保每个单词按顺序排列,嵌入层的输出将通过位置编码。
位置编码确保每个单词都在其位置上。它管理输入句子或句子批次的序列模式。
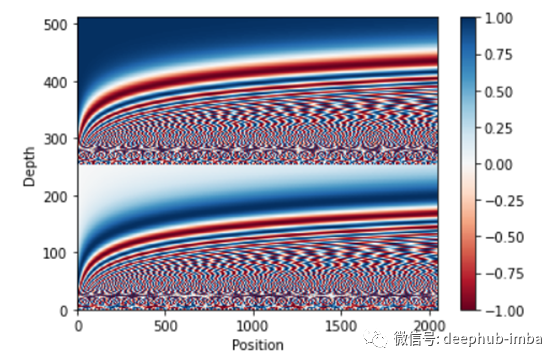
x 轴是单词位置,y 轴是每个单词的 512 维。如果我们放大上图,我们会发现每个词都定位英勇。位置编码的输出是多头注意力和快捷连接的输入。
多头注意力是“m”头注意力机制,其中 m 是一个超参数。在研究论文中,他们使用了 8 Scaled Dot-Product Attention,内部为每个单词提供 8、512 维向量,每个 Scaled Dot-Product 的结果连接起来并进行 ((8 * 512) * k) 的点积 维权重矩阵。这些权重通过反向传播学习。
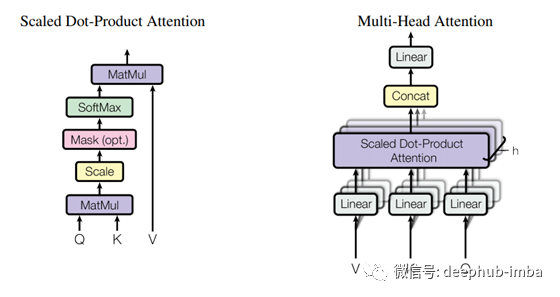
将多头注意力视为一个内部有 8 个缩放点积注意力的函数,它需要的参数是 3 个向量。第 3 个向量只不过是前一层的输出,并且所有三个向量都相同。它们被称为查询、键和值。Scaled Dot-Product Attention的输出是
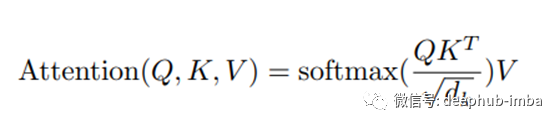
多头注意力的输出将添加一个快捷连接,然后进行层归一化。然后它通过位置前馈网络,然后进行层归一化,因此它是 1 个编码器的最终输出。
现在让我们谈谈解码器,
与 RNN 不同,我们将解码器输入一次发送到词嵌入层。这是一种强制学习的技术,这意味着我们从 softmax 获得的输出不会反馈给解码器,而是模型假设它已经预测了正确的序列并被要求预测下一个单词序列。它允许模型快速训练并具有更少的计算成本。
除了一个额外的多头注意力之外,解码器层具有几乎相同的子层。第一个注意力层是掩码多头注意力,其中掩码是指向前看掩码,这意味着它限制单词序列向前看该单词,因为我们必须预测下一个单词。编码器的输出将馈送到第二个多头注意力,其余过程保持不变。解码器的输出通过最后一个 2D 密集层,然后是大小等于 vocab 大小的 softmax 层。
由于我使用了2个模型来成功提取字符串。我将详细讨论这两种模型。
第一个模型
对ResNet作为编码器和Transformer作为解码器的结合架构的简要解释:
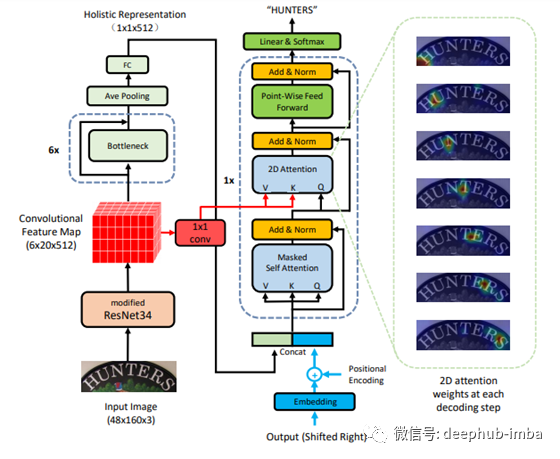
整个体系结构分为两个部分。左半部分是编码器,右半部分是解码器。
让我们首先了解编码器的细节。
编码器:
ResNet 34 用作特征映射和特征提取机制。3 维特征图是从修改后的 ResNet34 输出的。在我的实验中,我尝试使用经过修改的 ResNet50 来获得更深的网络,与 ResNet34 相比,它可以提供更好的结果。特征映射进一步同时通过两个网络,其中(1 * 1)卷积层和瓶颈。(1 * 1) conv 层的输出馈入解码器子层,即第二个多注意机制,并将其视为查询和关键向量。
在论文中,研究人员使用了六个堆叠的普通 ResNet34 作为具有残差连接的瓶颈层。最后一个堆栈瓶颈的输出进一步通过平均池化,然后是一个大小为 512 的全连接密集层。密集层的输出是二维的,它被视为输入图像的词嵌入。
解码器:
解码器嵌入层的输入是字符串。输入字符串是字符标记的,附加的“<end>”作为字符串的结尾。我没有使用‘<start>’,因为来自编码器最后一个密集层的输出在位置编码后作为字符串的开始被引入字符嵌入。在论文中,他们将密集层图像词嵌入的编码器输出与位置编码连接起来,但不是这样,我在连接后进行了位置编码,只是为了确保图像词嵌入首先作为 '<start> ' 指数。
前一层的输出被输入到一个屏蔽的多层注意力模型,然后通过添加残差网络进行层归一化。掩码与前瞻掩码相关联。然后将输出与特征映射的输出一起馈送到二维注意力层,然后通过添加残差网络进行层归一化。层归一化的输出被馈送到位置前馈网络,然后通过添加残差网络进行层归一化,最后通过具有 softmax 激活的二维线程层。
实验 :
我已经使用修改后的 ResNet50 和普通 ResNet50 的瓶颈尝试了上述架构。从最后一个瓶颈层出来的输出,然后是平均池化,被重塑为 2 维,然后传递到大小为 512 的密集层。我还尝试使用自定义学习率,其温步等于 4000,以及 Adam 作为 优化器。我也尝试过光束搜索来预测更好的输出。我已经用 232 个 epoch 训练了这个模型,发现该模型的预测准确度为 87%,损失减少到 0.0903。
下面是关于第一个模型架构的代码。
#function creating modified_restnet50
modified_RestNet50 = tf.keras.applications.resnet.ResNet50(weights='imagenet',include_top=False,input_shape=([48, 160, 3]))
def modified_restnet50():
model = tf.keras.Sequential()
model.add(modified_RestNet50)
model.add(UpSampling2D((3,3), interpolation = 'bilinear'))
model.add(Conv2D(512, (1, 1), activation = 'relu', name='block6_conv1'))
return model
#funtion creating feature map
def Extend():
model = tf.keras.Sequential()
model.add(Conv2D(512, (1, 1), activation = 'relu', name='block6_conv2'))
model.add(keras.layers.Reshape([90, 512]))
return model
#function to create bottleneck restnet50
RestNet50 = tf.keras.applications.resnet.ResNet50(weights='imagenet',include_top=False,input_shape=([54, 135, 3]))
def restnet50():
model = tf.keras.Sequential()
model.add(Conv2D(3, (1, 1), activation = 'relu', name='block6_conv3'))
model.add(UpSampling2D((3,3), interpolation = 'bilinear'))
model.add(Conv2D(3, (1, 1), activation = 'relu', name='block6_conv4'))
model.add(UpSampling2D((3,3), interpolation = 'bilinear'))
model.add(Conv2D(3, (1, 1), activation = 'relu', name='block6_conv5'))
model.add(RestNet50)
model.add(UpSampling2D((3,3), interpolation = 'bilinear'))
model.add(Conv2D(512, (1, 1), activation = 'relu', name='block6_conv6'))
return model
#function to create last layer bottleneck
restNet = tf.keras.applications.resnet.ResNet50(weights='imagenet',include_top=False,input_shape=([54, 135, 3]))
def restnet50_final():
model = tf.keras.Sequential()
model.add(Conv2D(3, (1, 1), activation = 'relu', name='block6_conv7'))
model.add(UpSampling2D((3,3), interpolation = 'bilinear'))
model.add(Conv2D(3, (1, 1), activation = 'relu', name='block6_conv8'))
model.add(UpSampling2D((3,3), interpolation = 'bilinear'))
model.add(Conv2D(3, (1, 1), activation = 'relu', name='block6_conv9'))
model.add(restNet)
model.add(Conv2D(512, (1, 4), activation = 'relu', name='block6_conv10'))
model.add(tf.keras.layers.AveragePooling2D(pool_size=(2, 2)))
model.add(keras.layers.Reshape([1, 512]))
model.add(tf.keras.layers.Dense(512,activation='relu'))
return model
##Source :- https://www.tensorflow.org/text/tutorials/transformer
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size,
maximum_position_encoding, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, last,feature_map, training,
look_ahead_mask, padding_mask):
#seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x = tf.concat([last, x], 1)
seq_len = tf.shape(x)[1]
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, feature_map, training,
look_ahead_mask, padding_mask)
attention_weights[f'decoder_layer{i+1}_block1'] = block1
attention_weights[f'decoder_layer{i+1}_block2'] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weights
# making an instance for each function
modified = modified_restnet50()
extend = Extend()
bottleneck1 = restnet50()
bottleneck2 = restnet50()
bottleneck3 = restnet50()
bottleneck4 = restnet50()
bottleneck5 = restnet50()
final = restnet50_final()
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
target_vocab_size, pe_input, pe_target, rate=0.1):
super(Transformer, self).__init__()
self.decoder = Decoder(num_layers, d_model, num_heads, dff,
target_vocab_size, pe_target, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask,
look_ahead_mask, dec_padding_mask):
generated_images1 = modified(inp, training=True)
feature_map = extend(generated_images1 , training=True)
bottle1 = bottleneck1(generated_images1 ,training=True )
sum = Add(name = 'add1')([generated_images1, bottle1])
bottle2 = bottleneck2(sum ,training=True )
sum = Add(name = 'add2')([sum, bottle2])
bottle3 = bottleneck3(sum ,training=True )
sum = Add(name = 'add3')([sum, bottle3])
bottle4 = bottleneck4(sum ,training=True )
sum = Add(name = 'add4')([sum, bottle4])
bottle5 = bottleneck5(sum ,training=True )
sum = Add(name = 'add4')([sum, bottle5])
last = final(sum , training=True)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attention_weights = self.decoder(tar, last,feature_map, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output, attention_weights
#return enc_output
预测样本如下所示:
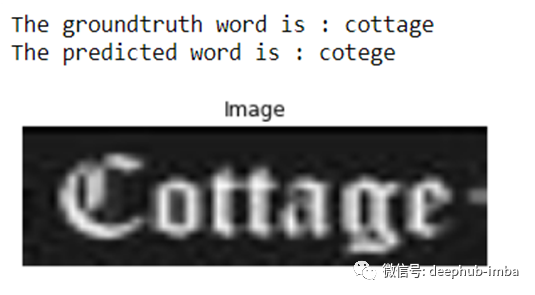
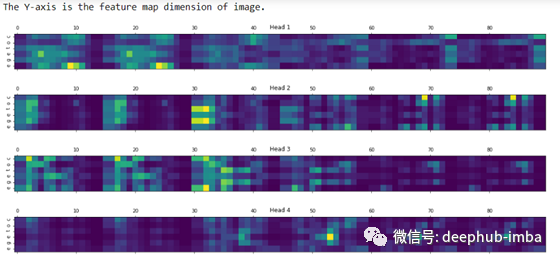
对应的注意力图如下所示:
第二个模型
简单解释一下以 ResNet101 作为输入到 Transformer Encoder 和 Transformer 作为 Decoder 的组合架构:
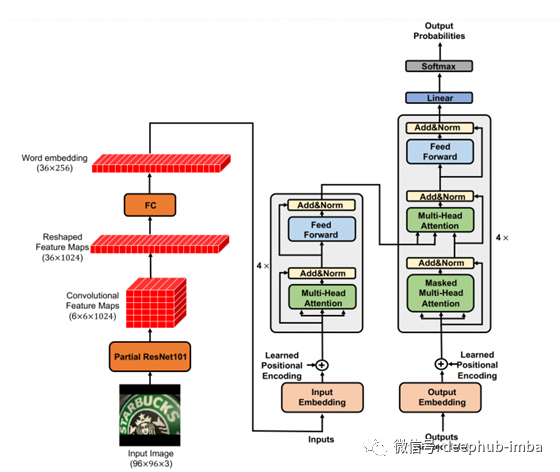
正如我们在第一个模型中看到的那样,ResNet 被视为编码器,Transformer 被视为解码器。第二个模型的模型架构完全不同。这里使用 ResNet 进行特征图提取,并将图像词嵌入的输出输入到Transformer 的编码器。除此之外,一切都与我们在 Transformer 架构基础中讨论的一样。
术语部分 ResNet101 指的是瓶颈模型,它可以进一步减少到所需的层,从而获得 3 维卷积特征图。它被进一步重塑为二维特征图,然后是一个完全连接的二维密集层。最终输出被视为输入到编码器层的每个图像的词嵌入。我们使用 4 个堆叠的编码器和解码器层,具有 8 个多头注意机制。
在这里,我还尝试使用自定义学习率,预热等于 4000 以及 Adam 作为优化器。我也尝试过光束搜索来预测更好的输出。我已经用 500 个 epoch 训练了这个模型,发现该模型的预测准确度为 51%,损失减少到 0.37,这意味着与第一个模型相比,它无法预测。
下面是关于第一个模型架构的代码。
#function to extract feature extaction for given image
vgg16_model = tf.keras.applications.resnet.ResNet101(weights='imagenet',include_top=False,input_shape=([96, 96, 3]))
def restnet101():
model = tf.keras.Sequential()
model.add(vgg16_model)
model.add(Conv2D(1024, (1, 1), activation = 'relu', name='block6_conv1'))
model.add(UpSampling2D((2,2), interpolation = 'bilinear'))
model.add(keras.layers.Reshape([36, 1024]))
model.add(tf.keras.layers.Dense(256,activation='relu'))
return model
generator = restnet101()
#source :- https://www.tensorflow.org/text/tutorials/transformer
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# add extra dimensions to add the padding
# to the attention logits.
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2
from tensorflow.keras.layers import Input, Add
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.pos_encoding = positional_encoding(maximum_position_encoding,
self.d_model)
self.enc_layers = [EncoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # (batch_size, input_seq_len, d_model)
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size,
maximum_position_encoding, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, training,
look_ahead_mask, padding_mask)
attention_weights[f'decoder_layer{i+1}_block1'] = block1
attention_weights[f'decoder_layer{i+1}_block2'] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weights
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
target_vocab_size, pe_input, pe_target, rate=0.1):
super(Transformer, self).__init__()
self.tokenizer = Encoder(num_layers, d_model, num_heads, dff,
input_vocab_size, pe_input, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff,
target_vocab_size, pe_target, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask,
look_ahead_mask, dec_padding_mask):
generated_images = generator(inp, training=True)
enc_output = self.tokenizer(generated_images, training, enc_padding_mask) # (batch_size, inp_seq_len, d_model)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attention_weights = self.decoder(tar, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output, attention_weights
#return enc_output
预测样本如下所示:

对应的注意力图如下所示:
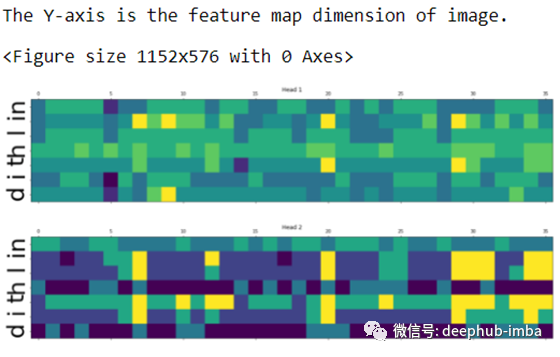
我只展示了前两个头的结果。有关详细信息,请查看 GitHub 。https://github.com/tiwaridipak103/Scene-Text-Recognition
未来的工作
我想尝试不同的 ResNet 架构并以更多的 epoch 运行模型。我还没有做过我想尝试的数据增强。
本文作者:Dipak Kumar Tiwari
原文地址:https://tiwaridipak103.medium.com/scene-text-recognition-using-resnet-and-transformer-c1f2dd0e69ae