

索引概述
介绍
索引(index)是帮助htysQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
演示
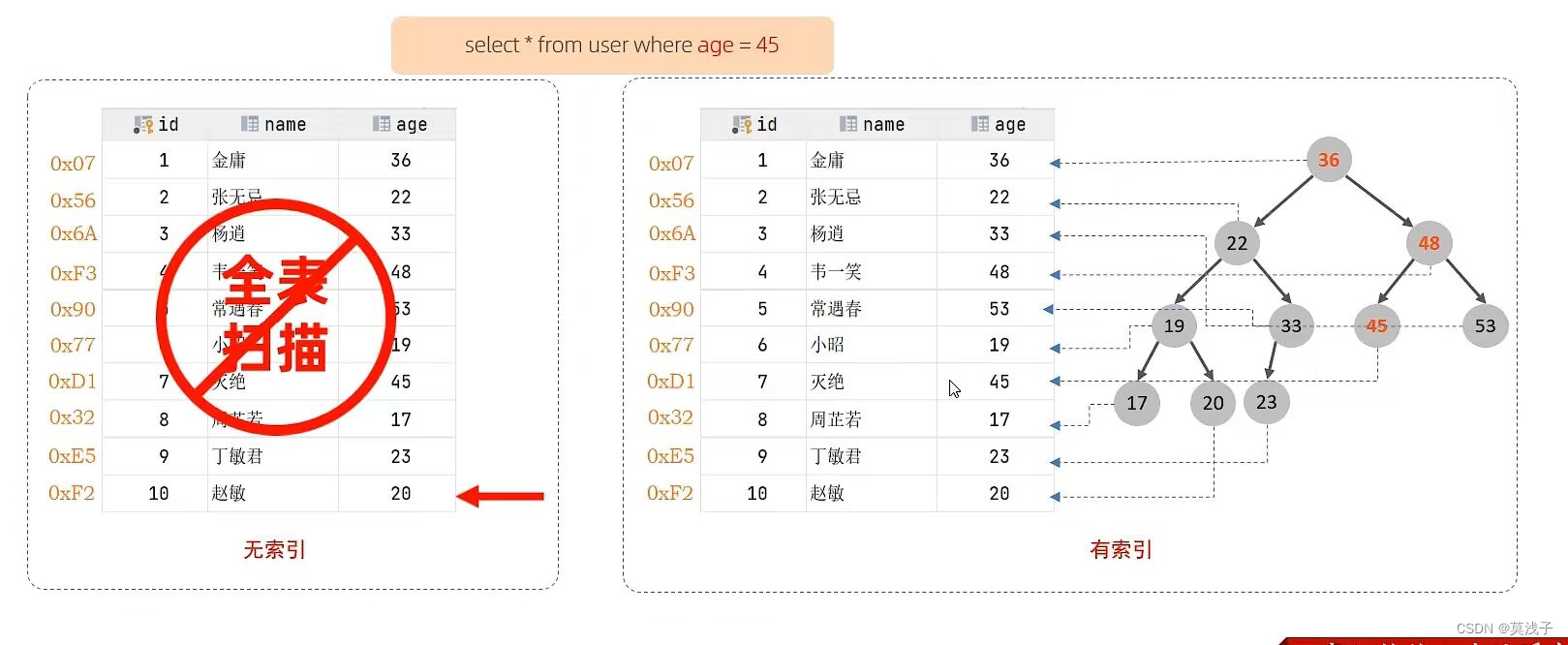
如果去查找age = 45 的人
常规操作:首先按表一个一个对比,就算找到了age= 45,仍然会继续搜索,因为不确定是否还有没有age等于45的了,这种遍历显而易见十分的耗费时间
有索引的操作:首先建立表的时候就把年龄数据放在二叉树上,至于进行查找的时候,如果某个数据比要查找的数据大,那就往右子树上去看,如果要查的数据比这个结点数据小,则往左子树上去查
优缺点

索引的结构
MySQL的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种:

索引对存储引擎的支持情况
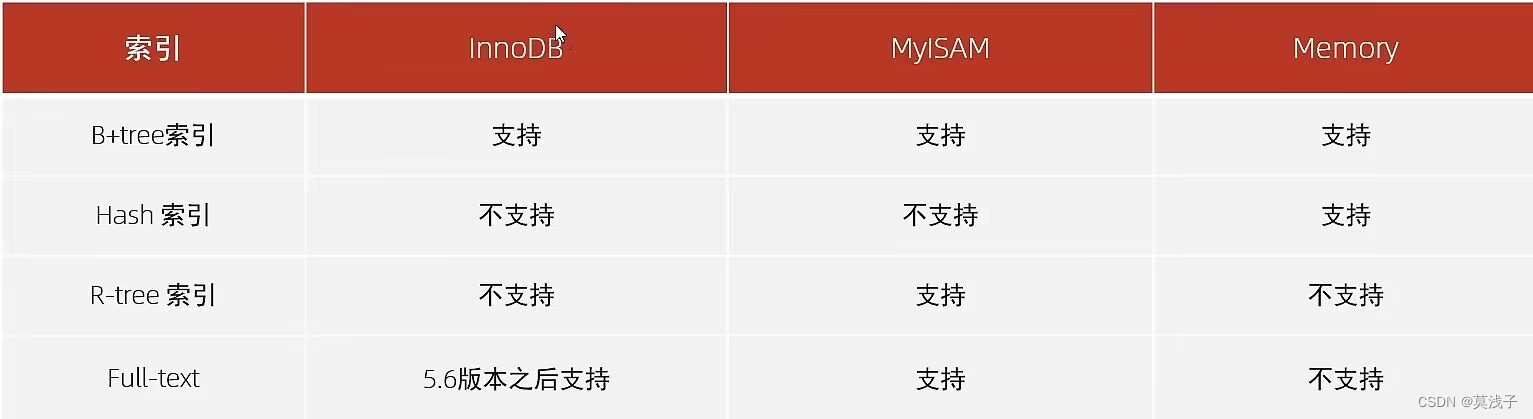
我们平常所说的索引,如果没有特别指明,都是B+树结构组织的索引。
二叉树
通上述介绍一样,查找数据时,大了往右边查找,小了往左边查找
 但是仍然存在缺点
但是仍然存在缺点
二叉树缺点:顺序插入时,会形成一个链表,查询性能大大降低。大数据量情况下,层级较深,检索速度慢。
红黑树:大数据量情况下,层级较深,检索速度慢。
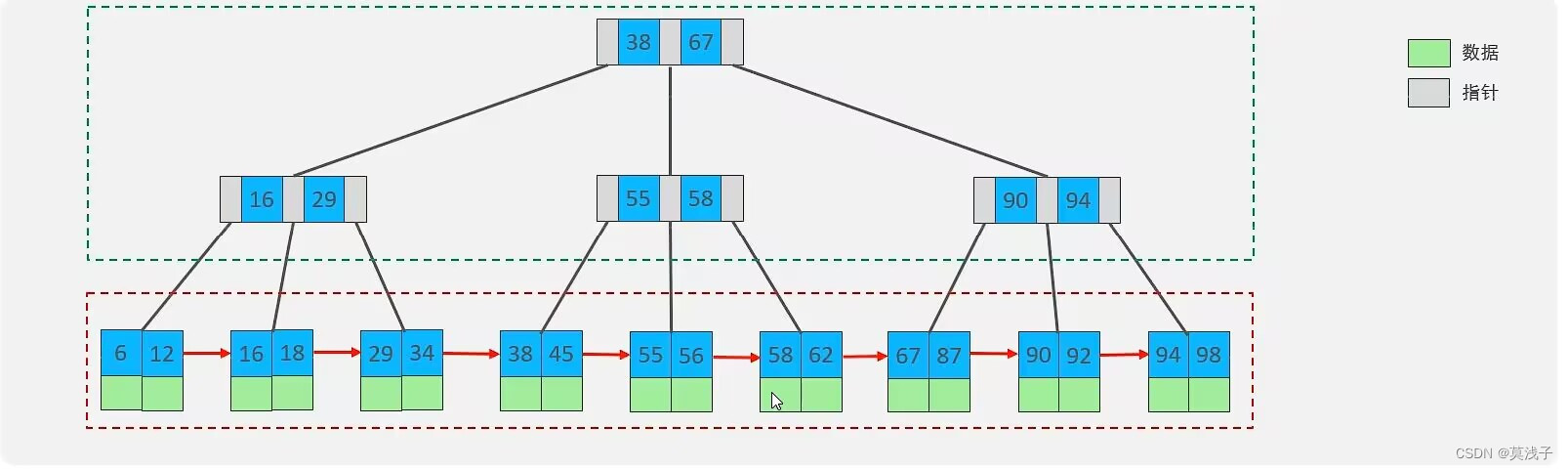
** B-Tree(多路平衡查找树)**
以一颗最大度树(max-degree)为 5(5阶)的b-tree 为例(每个结点最多存储4个key,5个指针):

注意:树的度数指一个结点的子节点个数
其实上面B-Tree 不难看出和二叉树很像不过比较结点的时候,不可以一下就找到了,需要与一个结点上4个key做比较,同样的如果大的在右边,小的在左边
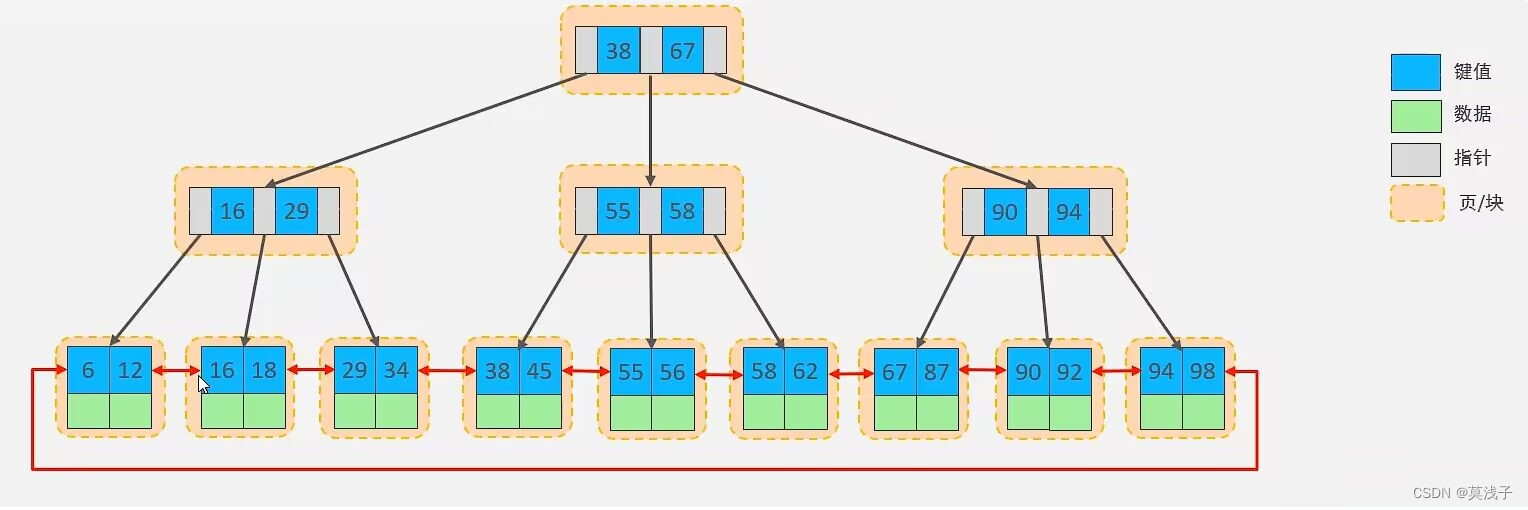
B+Tree
以一颗最大度数(max-degree) 为 4(4阶)的b+Tree为例
这个树的特点除了上述所说,其实所有的数都会存放在叶子结点,而上面的数只是起到了索引的作用,叶子结点形成了一个单向的链表,每个结点存放俩个数据
在MySQL中的B+Tree
MySQL索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
Hash
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也称为hash碰撞),可以通过链表来解决。
操作:
先算出表中每一行数据的哈希值,针对name字段所有值,通过内部的哈希函数计算每一个name值该落在哪个槽位上(图中蓝色的为槽位)

Hash索引特点
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<,...)
2.无法利用索引完成排序操作
3.查询效率高,通常只需要一次检索就可以了,效率通常要高于B+tree索引
>存储引擎支持
在MySQL中,支持hash索引的是Memory引擎,而innoDB中具有自适应hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的。
思考
为什么InnoDB存储引擎选择使用B+tree索引结构?
相对于二叉树,层级更少,搜索效率高;
对于B-tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低;
版权归原作者 莫浅子 所有, 如有侵权,请联系我们删除。