
1、内容简介
本文为大二在校学生所做,内容为爬取中国大学Mooc网站的课程分类数据、课程数据、评论数据。数据集大佬们需要拿走。主要是希望大佬们能指正代码问题。
2、数据集
课程评论数据集,343525条(包括评论id、评论时间、发送评论用户的id,发送评论的用户昵称,评论内容,所属课程id)
课程数据集,29196条(包括课程id、课程、课程名称、报名人数、教师名称、所属大学、开始日期、截止日期、所属课程类别id)
课程分类数据集,23条(包括课程id、课程名称、课程简介)
链接:https://pan.baidu.com/s/10m_kWEvLaom41sFvb8CQgA?pwd=8888
提取码:8888
--来自百度网盘超级会员V4的分享
3、代码
3.1 获取课程类别
3.1.1 全部代码
import csv
import json
import requests
# 获取类别的数据
# 请求url
baseurl = "https://www.icourse163.org/web/j/channelBean.listChannelCategoryDetail.rpc?csrfKey=9ddd9641afce4905aa429bf754db5b1b"
# 请求头
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"no-cache",
"Content-Length":"192",
"Content-Type":"application/x-www-form-urlencoded;charset=UTF-8",
"Cookie":"NTESSTUDYSI=9ddd9641afce4905aa429bf754db5b1b; EDUWEBDEVICE=7a18a0d811e443da8466a956d9571abd; Hm_lvt_77dc9a9d49448cf5e629e5bebaa5500b=1714007316; __yadk_uid=lxVu0GBpcgHrjnjdBP4LXojZlFfwpS4n; WM_NI=4G7PWoEQ02m4%2BvueYIsLLEdVSrkmtq2QbnYz6oN0vU7DuVNiljn7xkLMqPibUCA0Y3KTw4e3PffcgFfwwieW1RRmO7vvCHyP7%2FfjlmJia7I03OR%2FMP0xMocc%2FWmx3lHnckU%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee91e159a5adb6b5f162b1a88aa6d15f968b9e86d83eb0bc83dae67dbc8699a6db2af0fea7c3b92af899f9b1d665878f00d3f040e9aabb86dc43b19484a6e75e91aea58ef77bf28fae8fdc72f6b182d1f55ff59cbbb7cd63b0b6a2d8fb619093bfb1ec6a979d8fd1dc39898cb9d5e83994baaa84e64ea6a9b98ae85df38e9e8ece3db6aa8da9fc5cf5f1aa8bef678ab7afd8cc3cf1919ed0d05cf4a88390e269ed89a399b2688cb2ad8cd837e2a3; WM_TID=uZLSXz1D89ZBAUAUVQKFu0YZ91x1YWRD; Hm_lpvt_77dc9a9d49448cf5e629e5bebaa5500b=1714009886",
"Edu-Script-Token":"9ddd9641afce4905aa429bf754db5b1b",
"Origin":"https://www.icourse163.org",
"Pragma":"no-cache",
"Referer":"https://www.icourse163.org/channel/2001.htm?cate=-1&subCate=-1",
"Sec-Ch-Ua":'"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
"Sec-Ch-Ua-Mobile":"?1",
"Sec-Ch-Ua-Platform":"Android",
"Sec-Fetch-Dest":"empty",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Site":"same-origin",
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Mobile Safari/537.36"
}
# 请求数据,固定的
data = "includeALLChannels=true&includeDefaultChannels=false&includeMyChannels=false";
# 发送请求
response = requests.post(baseurl,data=data, headers=headers,timeout=10)
# 获取数据
parsed_data = json.loads(response.text)
# 将数据转为utf-8模式
for key, value in parsed_data.items():
if isinstance(value, str):
parsed_data[key] = value.encode('utf-8').decode('unicode-escape')
# 打印 类别JSON数据
print(json.dumps(parsed_data, indent=4, ensure_ascii=False))
# 定义需要写入csv的字段
fields = ['id', 'name', 'shortDesc', 'weight', 'defaultChannel', 'charge', 'includeLearningProgress', 'newGiftBag', 'suportOoc', 'suportVocationalMooc', 'suportNavigationType', 'icon', 'recommendWord', 'seoKeywords', 'showChildCategory', 'childrenChannelIds', 'childrenChannelDtoList']
# 创建 CSV 文件并写入数据
with open('channel_data.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(fields)
# 按照json数据 遍历写入数据即可
for channel_category in parsed_data['result']['channelCategoryDetails']:
for channel in channel_category['channels']:
row = [channel[field] for field in fields]
writer.writerow(row)
3.1.2 代码解释
中国大学Mooc的网站爬取很简单,几乎没有反爬手段,适合我这种初学者。
首先,是请求头数据的获取。浏览器右键打开审查模式,单击网络,找到一个请求,将其请求头数据复制下来。
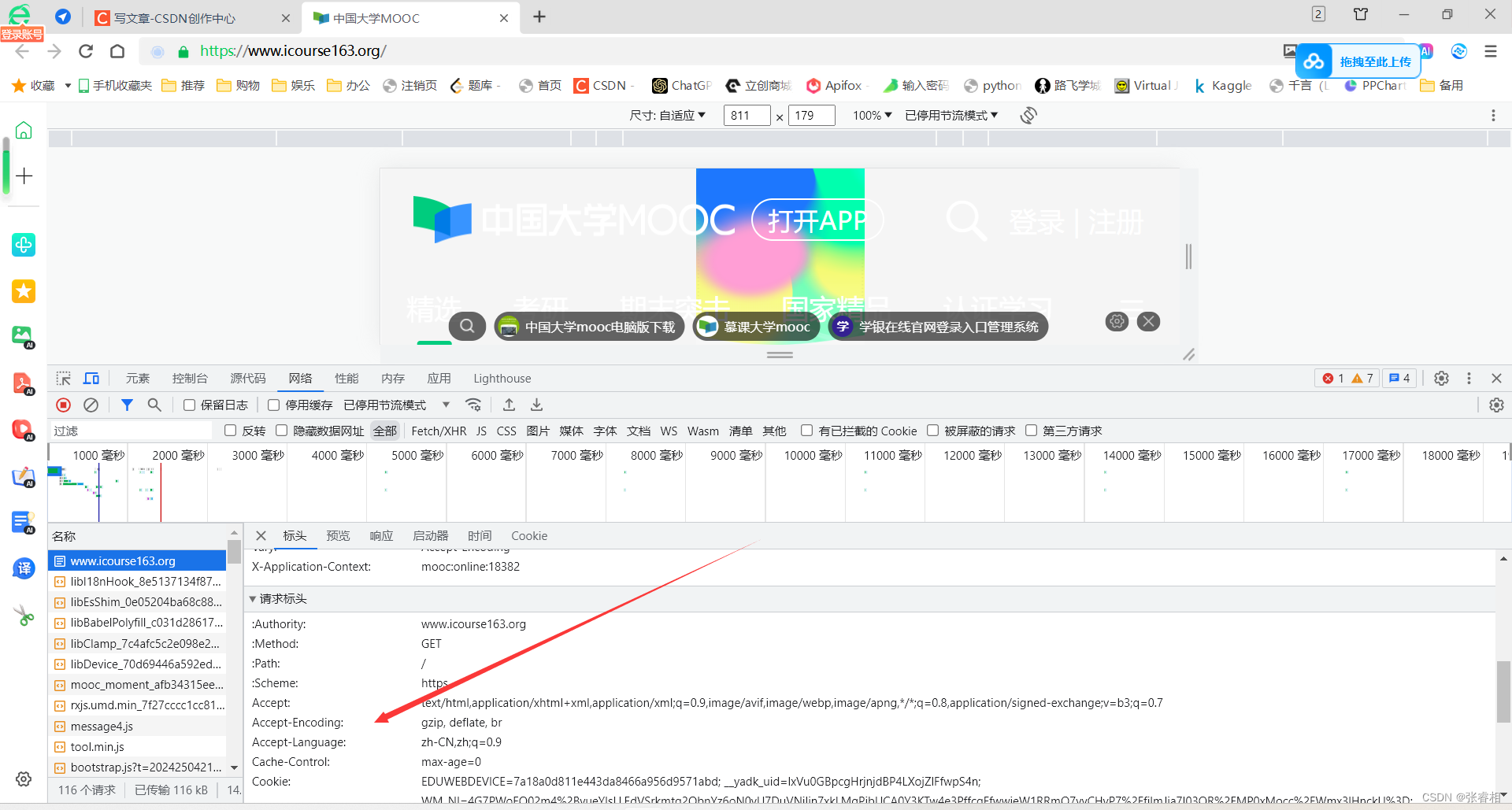
请求的url我就不多说了,这个是我自己慢慢看后搜索出来的
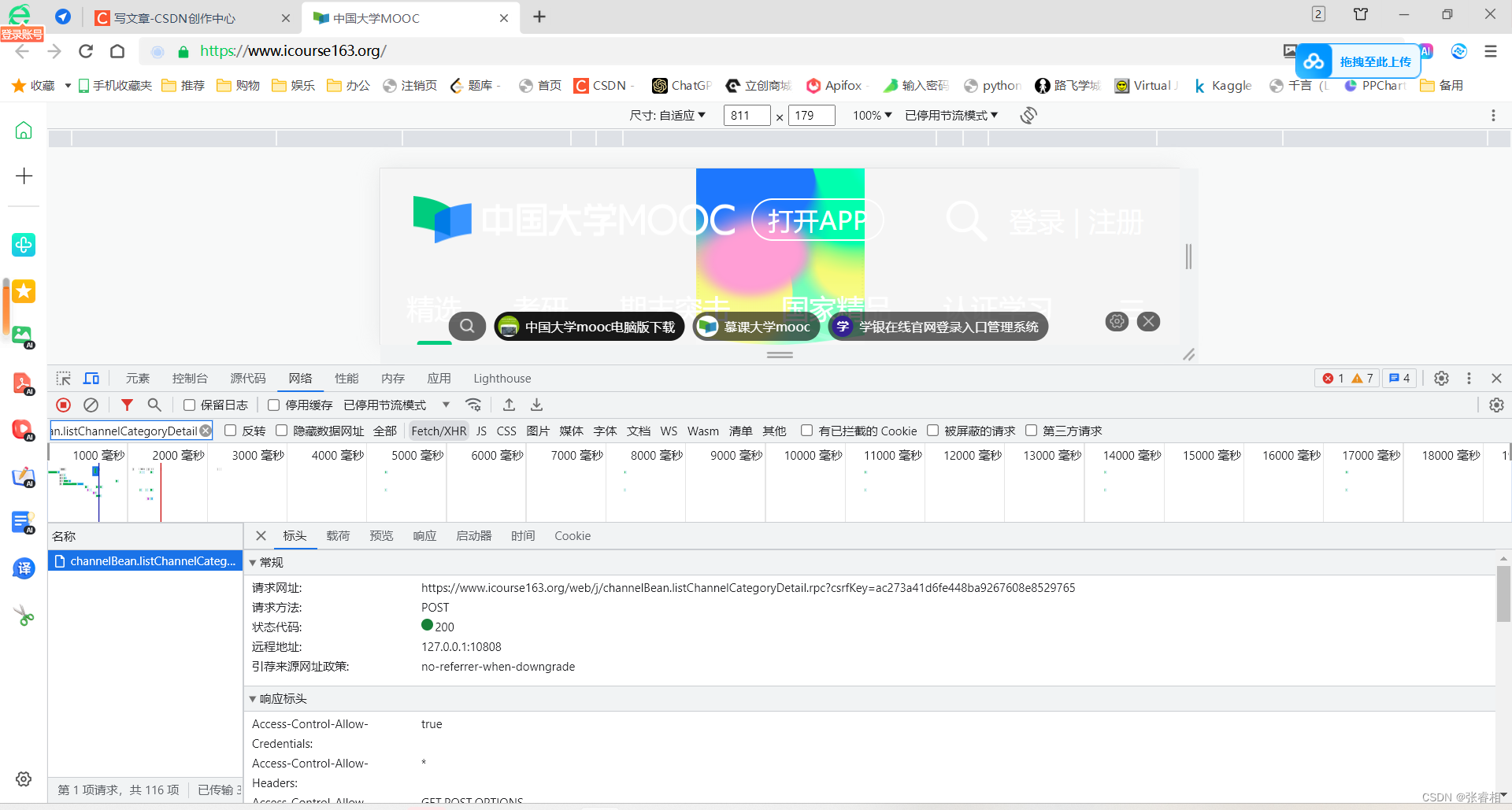
我们可以看到,该请求方法为post,载荷,也就是携带的参数是固定的。那么简单,我们就把参数转成字符串,封装为data,一起给请求头发过去。

之后我们获取数据,并转为json格式。再把json数据转为utf-8的编码格式,防止乱码。这些数据处理就不细讲了。
然后我们根据他的json格式,遍历数据,最后输出为csv文件。
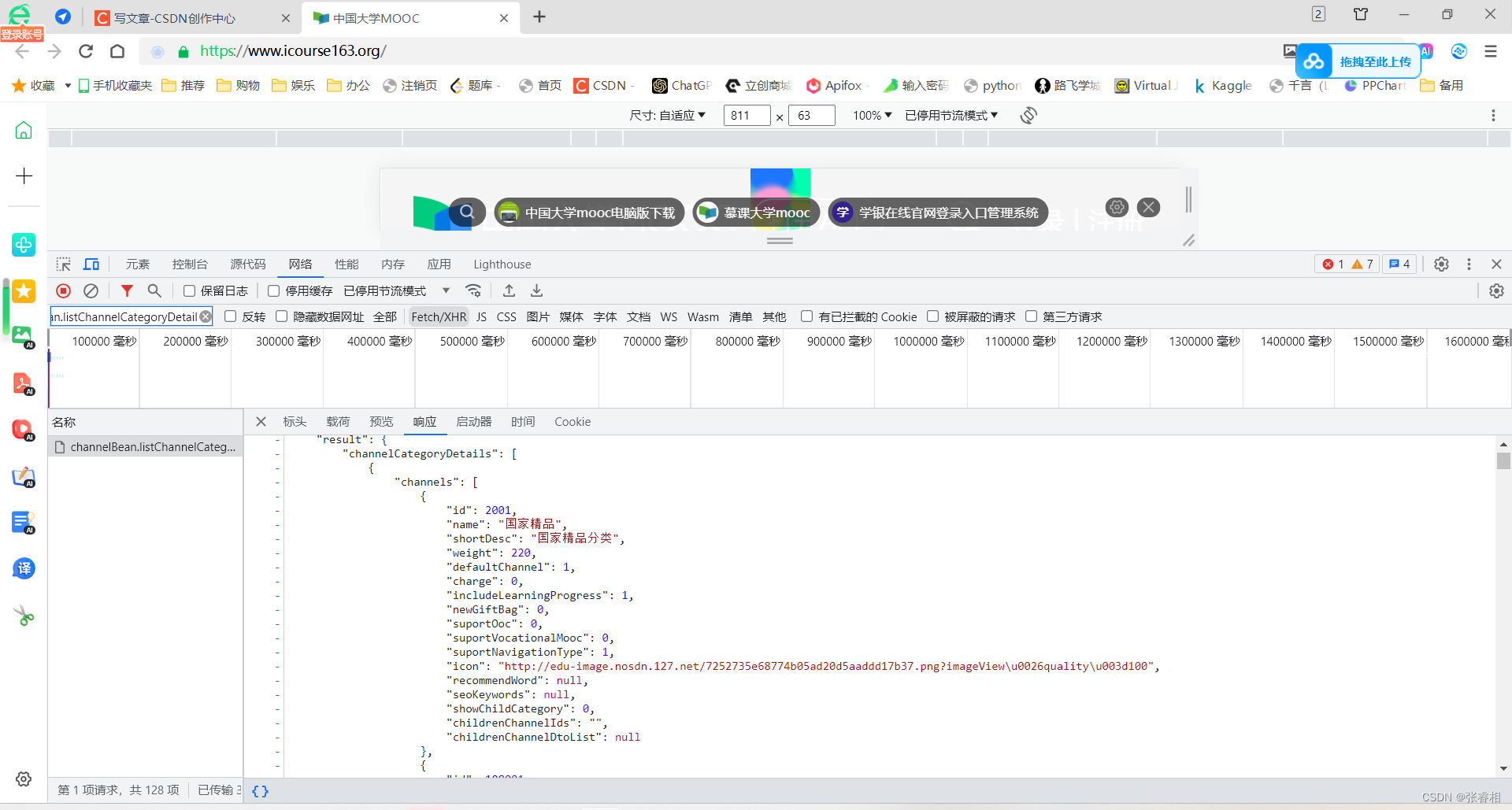
3.2 获取全部课程
3.2.1 全部代码
import csv
import json
import requests
# 目的:获取每个课程的概览信息
# 先创建一个csv文件,把列名写进去
with open('course_data.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
# 设置课程数据的列名
fields = ['id', 'name', 'enrollCount', 'teacherName', 'schoolName', 'startTime', 'endTime']
# 设置所有数据的列名(因为有些数据不在课程信息的VO类里,需要单独获取,所以另外设立)
all = ['id', 'name', 'enrollCount', 'teacherName', 'schoolName', 'startTime', 'endTime','type',"channel_Id"]
writer.writerow(all)
# 定义获取课程类别的url
baseurl = "https://www.icourse163.org/web/j/channelBean.listChannelCategoryDetail.rpc?csrfKey=9ddd9641afce4905aa429bf754db5b1b"
# 定义获取课程信息的url
twourl = "https://www.icourse163.org/web/j/mocSearchBean.searchCourseCardByChannelAndCategoryId.rpc?csrfKey=9ddd9641afce4905aa429bf754db5b1b"
# 请求头
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"no-cache",
"Content-Length":"192",
"Content-Type":"application/x-www-form-urlencoded;charset=UTF-8",
"Cookie":"NTESSTUDYSI=9ddd9641afce4905aa429bf754db5b1b; EDUWEBDEVICE=7a18a0d811e443da8466a956d9571abd; Hm_lvt_77dc9a9d49448cf5e629e5bebaa5500b=1714007316; __yadk_uid=lxVu0GBpcgHrjnjdBP4LXojZlFfwpS4n; WM_NI=4G7PWoEQ02m4%2BvueYIsLLEdVSrkmtq2QbnYz6oN0vU7DuVNiljn7xkLMqPibUCA0Y3KTw4e3PffcgFfwwieW1RRmO7vvCHyP7%2FfjlmJia7I03OR%2FMP0xMocc%2FWmx3lHnckU%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee91e159a5adb6b5f162b1a88aa6d15f968b9e86d83eb0bc83dae67dbc8699a6db2af0fea7c3b92af899f9b1d665878f00d3f040e9aabb86dc43b19484a6e75e91aea58ef77bf28fae8fdc72f6b182d1f55ff59cbbb7cd63b0b6a2d8fb619093bfb1ec6a979d8fd1dc39898cb9d5e83994baaa84e64ea6a9b98ae85df38e9e8ece3db6aa8da9fc5cf5f1aa8bef678ab7afd8cc3cf1919ed0d05cf4a88390e269ed89a399b2688cb2ad8cd837e2a3; WM_TID=uZLSXz1D89ZBAUAUVQKFu0YZ91x1YWRD; Hm_lpvt_77dc9a9d49448cf5e629e5bebaa5500b=1714009886",
"Edu-Script-Token":"9ddd9641afce4905aa429bf754db5b1b",
"Origin":"https://www.icourse163.org",
"Pragma":"no-cache",
"Referer":"https://www.icourse163.org/channel/2001.htm?cate=-1&subCate=-1",
"Sec-Ch-Ua":'"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
"Sec-Ch-Ua-Mobile":"?1",
"Sec-Ch-Ua-Platform":"Android",
"Sec-Fetch-Dest":"empty",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Site":"same-origin",
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Mobile Safari/537.36"
}
# 我们先进行获取所有类别的请求
data = "includeALLChannels=true&includeDefaultChannels=false&includeMyChannels=false";
response = requests.post(baseurl,data=data, headers=headers,timeout=10)
# 接收所有类别的数据
parsed_data = json.loads(response.text)
# 转换数据为utf-8编码格式
for key, value in parsed_data.items():
if isinstance(value, str):
parsed_data[key] = value.encode('utf-8').decode('unicode-escape')
# 遍历所有类别
for channel_category in parsed_data['result']['channelCategoryDetails']:
for channel in channel_category['channels']:
# 当前页码
pageIndex = 1
# 我也不知道这个参数干啥的,根据正常请求里的数据 无脑-1就完了
categoryId = -1;
# 获取类别的id
categoryChannelId = channel["id"];
# 进行循环,要进行 获取类别内所有课程信息 的请求
while True :
# 设置请求参数
data = {
"mocCourseQueryVo": '{categoryId:' + str(categoryId) + ',categoryChannelId:' + str(
categoryChannelId) + ','
'orderBy:0,stats:30,pageIndex:' + str(
pageIndex) + ',pageSize:20,shouldConcatData:true}'
}
try:
# 发送请求,因为请求头相同,不做赘述
response = requests.post(twourl, data=data, headers=headers)
# 当前页数+1,完成下次翻页操作
pageIndex+=1
# 获取该类别内课程的数据
parsed_course_data = json.loads(response.text)
# 转化为utf-8编码格式
for key, value in parsed_data.items():
if isinstance(value, str):
parsed_course_data[key] = value.encode('utf-8').decode('unicode-escape')
# 打印获取的 课程JSON数据
print(json.dumps(parsed_course_data, indent=4, ensure_ascii=False))
# 创建 CSV 文件并写入数据
with open('course_data.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
# 遍历类别的课程数据
for item in parsed_course_data['result']['list']:
# 获取课程数据
course = item.get('mocCourseBaseCardVo')
# 获取type数据(我也不知道干啥的)
type = item.get('type')
# 获取该课程所属类别的id
channelId = categoryChannelId
# 在csv写入数据
if course:
row = [course.get(field, '') for field in fields]
if type:
row.append(type)
if channelId:
row.append(channelId)
writer.writerow(row)
# 如果翻页数超过或等于最大页码,退出循环
if pageIndex >= parsed_course_data["result"]["query"]["totlePageCount"]:
break;
except Exception as e:
print(f"网络异常,{e}")
continue
3.2.2 代码解释
课程获取的请求URL如下图所示,我找的这个URL的过程就是,先筛选为Fetch/XHR,在点击每个链接,看他的响应。找到之后我们注意他的请求方式和url即可。
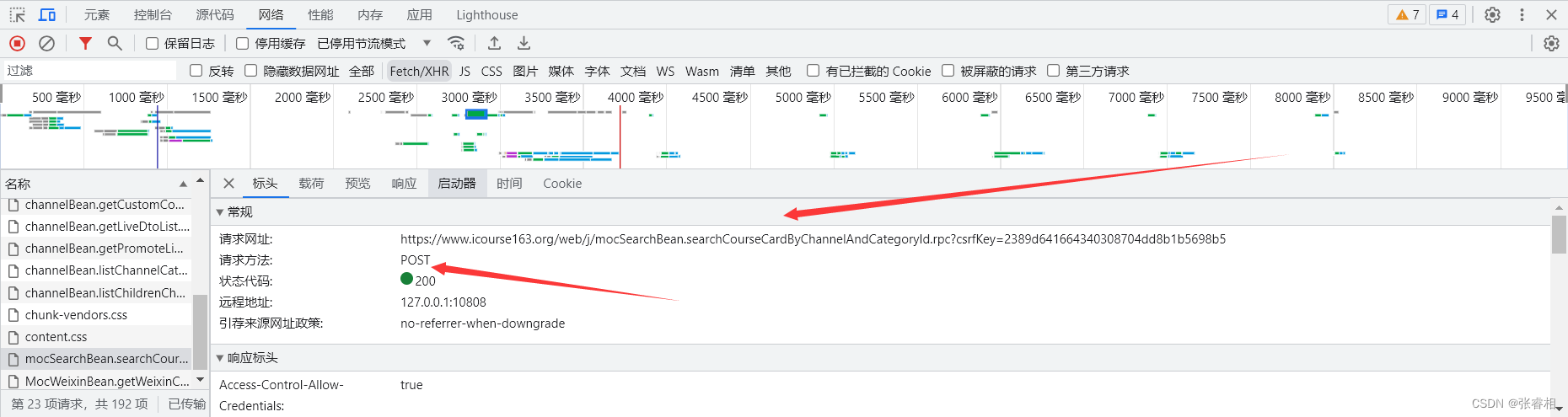
之后我们看他的载荷,也就是请求数据。我们可以看到,是一个请求头。包括类别id,页码,页数等,一个很常规的查询请求参数。我们只需把请求体封装为字符形式即可。
我们在3.1 获取课程类别的基础上,遍历课程类别数据,之后通过类别id,搜索对应课程数据。之后根据课程数据的json格式,依次遍历数据即可,除此之外,我们还可以额外加一个课程类别id的列,便于更好管理。
3.3 获取评论
3.3.1 全部代码
# 获取课程大纲
# dagangurl = 'https://www.icourse163.org/web/j/courseBean.getMocTermDto.rpc?csrfKey=9ddd9641afce4905aa429bf754db5b1b'
import csv
import json
import requests
# 目的:获取每个课程的评论
# 先创建一个csv文件,把列名写进去
with open('course_comment_data.csv', 'w', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
# 设置课程数据的列名
fields = ['id',"gmtModified","commentorId", 'userNickName', 'content', 'mark', 'schoolName', 'termId', 'status']
# 设置所有数据的列名(因为有些数据不在课程信息的VO类里,需要单独获取,所以另外设立)
all = ['id',"gmtModified","commentorId", 'userNickName', 'content', 'mark', 'schoolName', 'termId', 'status','courseId']
writer.writerow(all)
# 定义获取课程类别的url
baseurl = "https://www.icourse163.org/web/j/channelBean.listChannelCategoryDetail.rpc?csrfKey=9ddd9641afce4905aa429bf754db5b1b"
# 定义获取课程信息的url
twourl = "https://www.icourse163.org/web/j/mocSearchBean.searchCourseCardByChannelAndCategoryId.rpc?csrfKey=9ddd9641afce4905aa429bf754db5b1b"
# 获取课程评论信息的url
commentUrl = 'https://www.icourse163.org/web/j/mocCourseV2RpcBean.getCourseEvaluatePaginationByCourseIdOrTermId.rpc?csrfKey=9ddd9641afce4905aa429bf754db5b1b'
# 请求头
headers = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Cache-Control":"no-cache",
"Content-Length":"192",
"Content-Type":"application/x-www-form-urlencoded;charset=UTF-8",
"Cookie":"NTESSTUDYSI=9ddd9641afce4905aa429bf754db5b1b; EDUWEBDEVICE=7a18a0d811e443da8466a956d9571abd; Hm_lvt_77dc9a9d49448cf5e629e5bebaa5500b=1714007316; __yadk_uid=lxVu0GBpcgHrjnjdBP4LXojZlFfwpS4n; WM_NI=4G7PWoEQ02m4%2BvueYIsLLEdVSrkmtq2QbnYz6oN0vU7DuVNiljn7xkLMqPibUCA0Y3KTw4e3PffcgFfwwieW1RRmO7vvCHyP7%2FfjlmJia7I03OR%2FMP0xMocc%2FWmx3lHnckU%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee91e159a5adb6b5f162b1a88aa6d15f968b9e86d83eb0bc83dae67dbc8699a6db2af0fea7c3b92af899f9b1d665878f00d3f040e9aabb86dc43b19484a6e75e91aea58ef77bf28fae8fdc72f6b182d1f55ff59cbbb7cd63b0b6a2d8fb619093bfb1ec6a979d8fd1dc39898cb9d5e83994baaa84e64ea6a9b98ae85df38e9e8ece3db6aa8da9fc5cf5f1aa8bef678ab7afd8cc3cf1919ed0d05cf4a88390e269ed89a399b2688cb2ad8cd837e2a3; WM_TID=uZLSXz1D89ZBAUAUVQKFu0YZ91x1YWRD; Hm_lpvt_77dc9a9d49448cf5e629e5bebaa5500b=1714009886",
"Edu-Script-Token":"9ddd9641afce4905aa429bf754db5b1b",
"Origin":"https://www.icourse163.org",
"Pragma":"no-cache",
"Referer":"https://www.icourse163.org/channel/2001.htm?cate=-1&subCate=-1",
"Sec-Ch-Ua":'"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"',
"Sec-Ch-Ua-Mobile":"?1",
"Sec-Ch-Ua-Platform":"Android",
"Sec-Fetch-Dest":"empty",
"Sec-Fetch-Mode":"cors",
"Sec-Fetch-Site":"same-origin",
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Mobile Safari/537.36"
}
# 我们先进行获取所有类别的请求
# 请求数据,固定的
data = "includeALLChannels=true&includeDefaultChannels=false&includeMyChannels=false";
# 发送请求
response = requests.post(baseurl,data=data, headers=headers,timeout=10)
# 接收所有类别的数据
parsed_data = json.loads(response.text)
# 转换数据为utf-8编码格式
for key, value in parsed_data.items():
if isinstance(value, str):
parsed_data[key] = value.encode('utf-8').decode('unicode-escape')
# 遍历所有类别
for channel_category in parsed_data['result']['channelCategoryDetails']:
for channel in channel_category['channels']:
# 当前页码
pageIndex = 1
# 我也不知道这个参数干啥的,根据正常请求里的数据 无脑-1就完了
categoryId = -1;
# 获取类别的id
categoryChannelId = channel["id"];
# 进行循环,要进行 获取类别内所有课程信息 的请求
while True :
# 设置请求参数
data = {
"mocCourseQueryVo": '{categoryId:' + str(categoryId) + ',categoryChannelId:' + str(
categoryChannelId) + ','
'orderBy:0,stats:30,pageIndex:' + str(
pageIndex) + ',pageSize:20,shouldConcatData:true}'
}
try:
# 发送请求,因为请求头相同,不做赘述
response = requests.post(twourl, data=data, headers=headers)
# 当前页数+1,完成下次翻页操作
pageIndex+=1
# 获取该类别内课程的数据
parsed_course_data = json.loads(response.text)
# 转化为utf-8编码格式
for key, value in parsed_data.items():
if isinstance(value, str):
parsed_course_data[key] = value.encode('utf-8').decode('unicode-escape')
# 遍历类别的课程数据
for item in parsed_course_data['result']['list']:
# 设置获取评论请求的数据(获取课程id、当前页码)
courseId = item.get('mocCourseBaseCardVo').get("id")
commentPageIndex = 1;
# 根据id获取对应课程评论
while True :
commentData = {
'courseId': str(courseId),
'pageIndex': str(commentPageIndex),
'pageSize': str(20),
'orderBy': str(3)
}
response = requests.post(commentUrl, data=commentData, headers=headers, timeout=10)
commentResultData = json.loads(response.text)
commentPageIndex += 1
# 打印获取的 课程JSON数据
print(json.dumps(commentResultData, indent=4, ensure_ascii=False))
# 创建 CSV 文件并写入数据
with open('course_comment_data.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
# 遍历类别的课程数据
for item in commentResultData['result']['list']:
# 在csv写入数据
if item:
row = [item.get(field, '') for field in fields]
row.append(courseId)
writer.writerow(row)
# 如果 课程评论数据 翻页数超过或等于最大页码,退出循环
if commentPageIndex >= commentResultData["result"]["query"]["totlePageCount"]:
break;
# 如果课程数据翻页数超过或等于最大页码,退出循环
if pageIndex >= parsed_course_data["result"]["query"]["totlePageCount"]:
break;
except Exception as e:
print(f"网络异常,{e}")
break;
本文转载自: https://blog.csdn.net/a614631315/article/details/138200404
版权归原作者 张睿相 所有, 如有侵权,请联系我们删除。
版权归原作者 张睿相 所有, 如有侵权,请联系我们删除。