
网络爬虫—js逆向
前言:
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,阿里云社区专家博主
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🧾 🧾第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八领域热榜第二🧾 🧾第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》
全站热榜第十二。
🧾 🧾第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
🧾 🧾第十六篇文章《16.网络爬虫—字体反爬(实战演示)》全站热榜第二十五。
🧾 🧾第十九篇文章《19.网络爬虫—照片管道》全站综合热榜第十二。🧾 🧾第二十篇文章《20.网络爬虫—Scrapy-Redis分布式爬虫》
全站综合热榜第二十五名,大数据领域第六名。
🎁🎁《Python网络爬虫》专栏累计发表二十篇文章,上榜九篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
js逆向
📑 📑在这个大数据时代,我们眼睛所看到的百分之九十的数据都是通过页面呈现出现的,不论是PC端、网页端还是移动端,数据渲染还是基于html/h5+javascript进行的,而大多数的数据都是通过请求后台接口动态渲染的。而想成功的请求成功互联网上的开放/公开接口,必须知道它的URL、Headers、Params、Body等数据是如何生成的。
JavaScript逆向的详细讲解
📑 📑JavaScript逆向工程是指通过分析JavaScript代码和运行行为来理解程序的内部机制。这种技术可以用于破解JavaScript程序的加密和混淆,以及获取程序的逻辑和数据等信息。
以下是JavaScript逆向的详细讲解:
- JavaScript逆向工程的基本原理
📑 📑JavaScript逆向工程的基本原理是通过分析JavaScript代码和运行行为来理解程序的内部机制。这种技术可以用于破解JavaScript程序的加密和混淆,以及获取程序的逻辑和数据等信息。
JavaScript逆向工程通常包括以下步骤:
1)获取JavaScript代码
:
可以使用浏览器的开发人员工具或其他工具来获取JavaScript代码。
2)分析JavaScript代码
:
可以使用代码编辑器或其他工具来分析JavaScript代码,包括查找函数、变量、常量和操作符等。
3)调试JavaScript代码
:
可以使用浏览器的开发人员工具或其他工具来调试JavaScript代码,包括断点调试、单步调试和变量监视等。
4)破解JavaScript代码
:
可以使用反混淆和反编译工具来破解JavaScript代码,以获取程序的逻辑和数据等信息。
- JavaScript逆向工程的应用场景
JavaScript逆向工程可以应用于以下场景:
1)破解加密和混淆的JavaScript程序
:JavaScript逆向工程可以破解加密和混淆的JavaScript程序,以获取程序的逻辑和数据等信息。
2)调试和测试JavaScript程序
:JavaScript逆向工程可以帮助开发人员调试和测试JavaScript程序,以发现程序中的错误和问题。
3)优化JavaScript程序的性能和安全性
:JavaScript逆向工程可以帮助开发人员优化JavaScript程序的性能和安全性,以提高程序的质量和可靠性。
4)研究JavaScript程序的内部机制
:JavaScript逆向工程可以帮助研究人员研究JavaScript程序的内部机制,以发现其中的漏洞和安全问题。
- JavaScript逆向工程的注意事项
在进行JavaScript逆向工程时,需要注意以下事项:
1)遵守法律法规
:
JavaScript逆向工程可能涉及版权、知识产权和隐私等问题,需要遵守相关的法律法规。
2)保护个人隐私
:
在分析JavaScript程序时,需要遵守个人隐私的原则,不得获取个人信息和敏感信息。
3)避免滥用JavaScript逆向技术
:
JavaScript逆向技术可以用于破解和攻击,需要避免滥用。
4)保护JavaScript程序的安全性
:
在进行JavaScript逆向工程时,需要保护JavaScript程序的安全性,不得泄露JavaScript程序的机密信息和漏洞。
5)学习和研究JavaScript逆向技术
:
JavaScript逆向技术是一种有用的技术,需要学习和研究,以提高自己的技能和知识水平。
实战是学习知识最快的途径,下面进行实战演示帮助理解学习。
实战演示
有道翻译
有道翻译
浏览器:谷歌浏览器
右键检查,输入需要翻译的内容,然后开始抓包
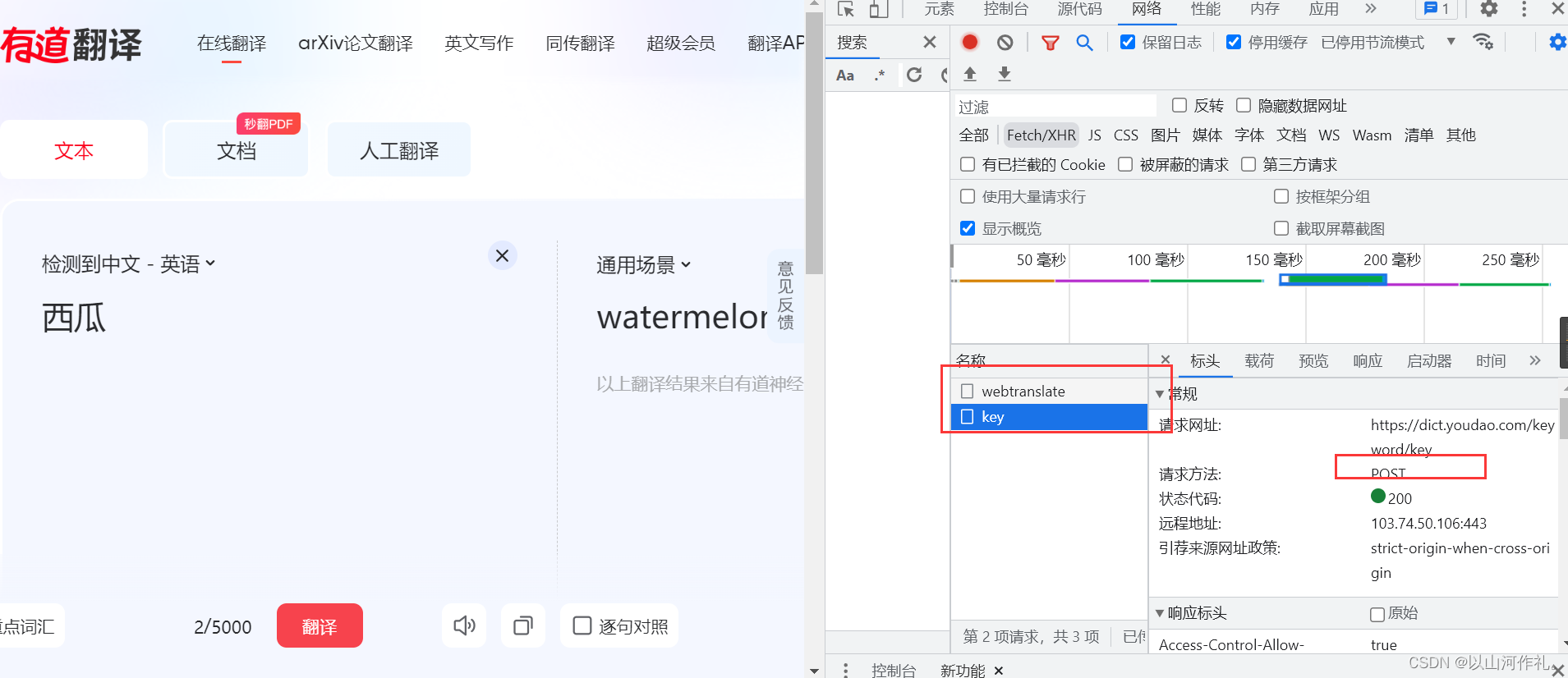

🎯点击翻译,我们得到两个数据,一个是key,请求方式是post,状态是200
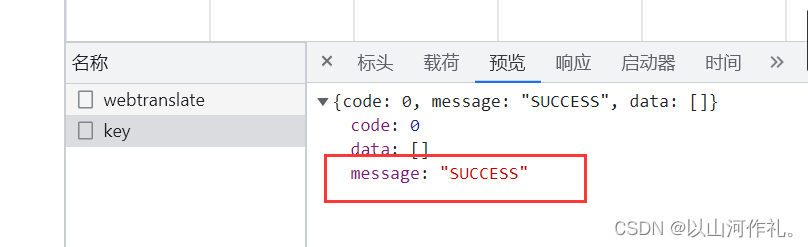
载荷是西瓜,预览里面出现success,表示翻译成功。
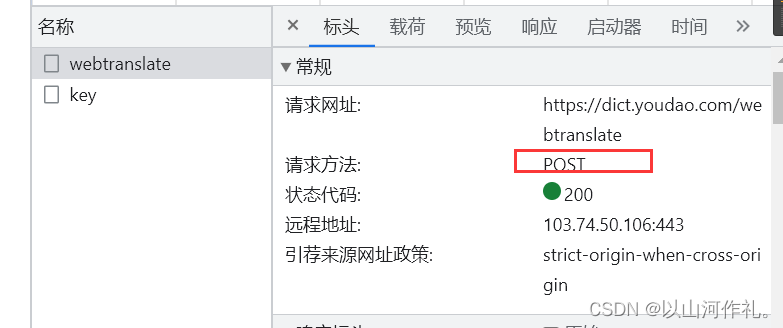
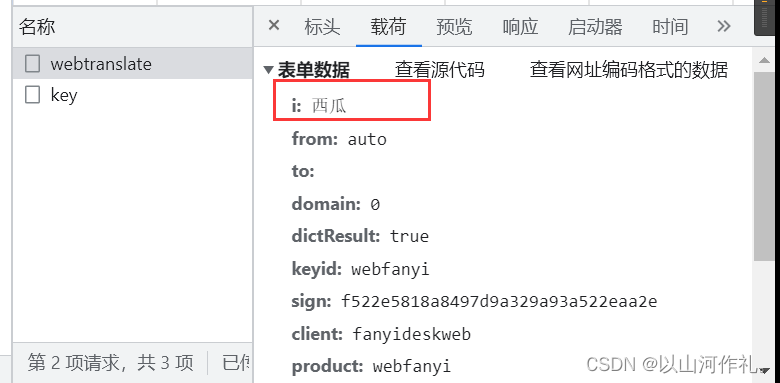

🎯还有一个文件是webtranslate,请求方法同样是post,状态是200,载荷里面有西瓜两个字和一些参数,预览和响应里面是一串加密的数据。
🎯接下来敲代码来获取文件,然后来破解数据
# coding = utf-8import crawles
url ='https://dict.youdao.com/webtranslate'
cookies ={'OUTFOX_SEARCH_USER_ID':'[email protected]','OUTFOX_SEARCH_USER_ID_NCOO':'42958927.495580636',}
headers ={'Accept':'application/json, text/plain, */*','Accept-Language':'zh-CN,zh;q=0.9','Cache-Control':'no-cache','Connection':'keep-alive','Content-Type':'application/x-www-form-urlencoded','Origin':'https://fanyi.youdao.com','Pragma':'no-cache','Referer':'https://fanyi.youdao.com/','Sec-Fetch-Dest':'empty','Sec-Fetch-Mode':'cors','Sec-Fetch-Site':'same-site','User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36','sec-ch-ua':'\"Google Chrome\";v=\"113\", \"Chromium\";v=\"113\", \"Not-A.Brand\";v=\"24\"','sec-ch-ua-mobile':'?0','sec-ch-ua-platform':'\"Windows\"',}
data ={'i':'西瓜','from':'auto','to':'','domain':'0','dictResult':'true','keyid':'webfanyi','sign':'f522e5818a8497d9a329a93a522eaa2e','client':'fanyideskweb','product':'webfanyi','appVersion':'1.0.0','vendor':'web','pointParam':'client,mysticTime,product','mysticTime':'1683270687293','keyfrom':'fanyi.web',}
response = crawles.post(url, headers=headers, data=data, cookies=cookies)print(response.text)
运行结果:
🎯接下来我们可以通过多次发多次请求来观察哪些是变的,哪些是不变的数据:
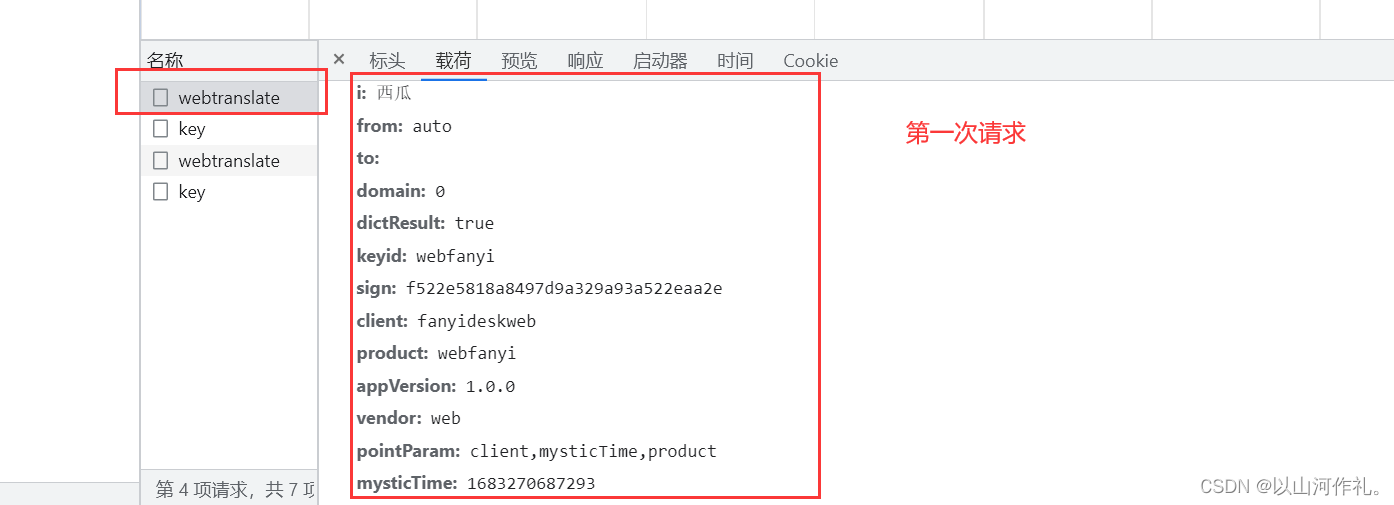
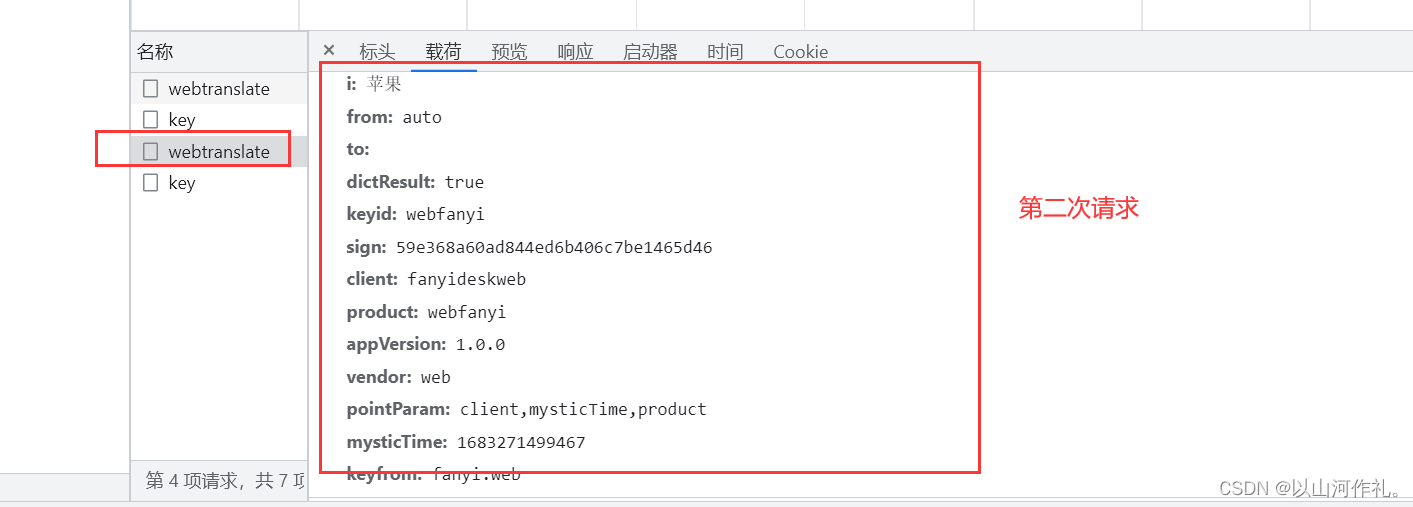
🎯经过对比,我们发现,
sign
,
mysticTime
这两个字段的参数是动态变化的。
🎯参数大概分析之后,我们就找出对应的js文件,来分析一下js是如何处理的参数
选择文件,点击启动器,然后可以随便点击一个文件,然后点击它。
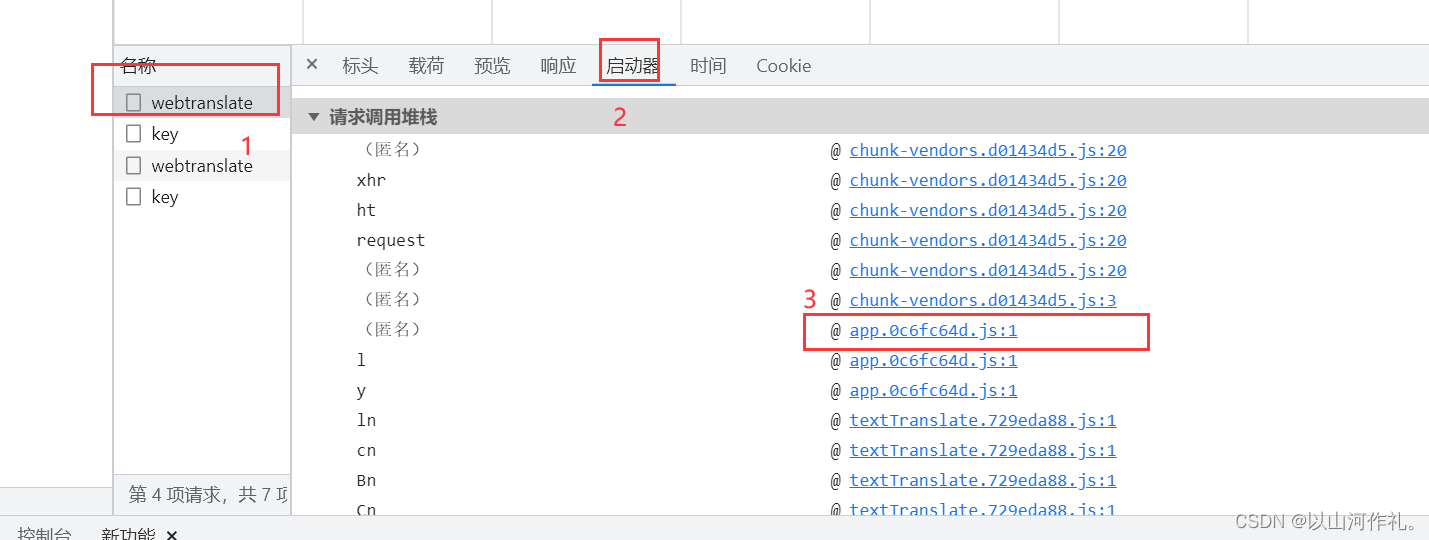
🎯输入sign后,如果出现多个,我们需要逐个观察,看哪一个符合要求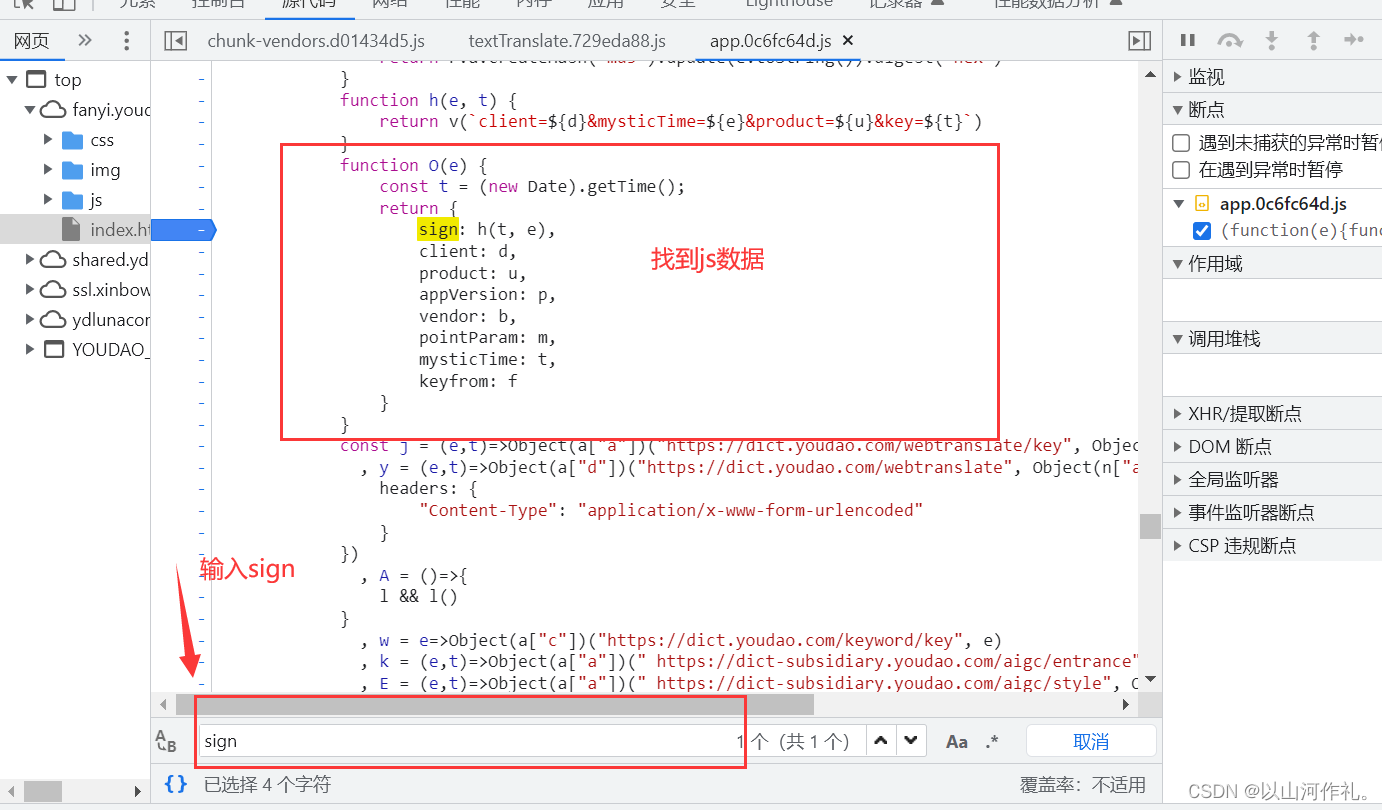
🎯我们在sign这里打上断点,然后点击翻译,进行抓包处理,得到e和t的值
e:"fsdsogkndfokasodnaso"
t:1683272866426
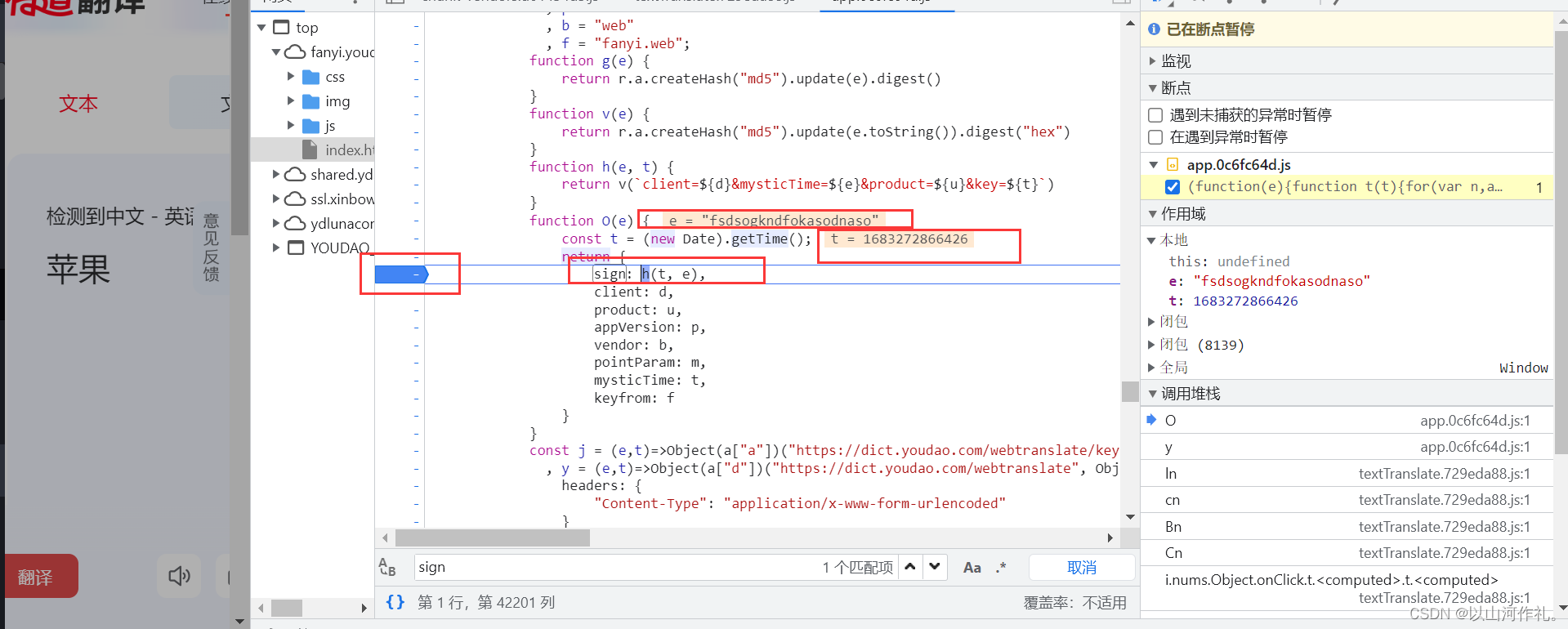
🎯然后我们点击其他参数,获取数据
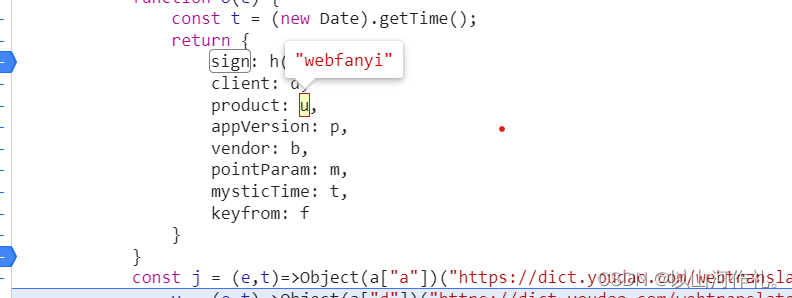
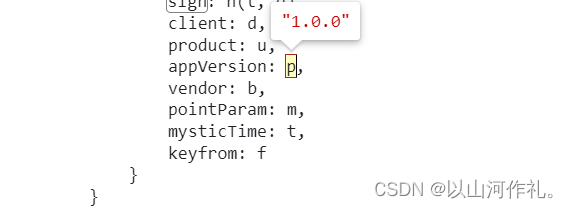

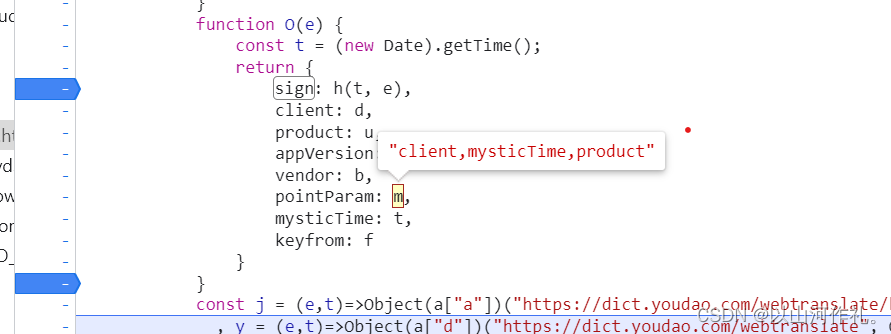
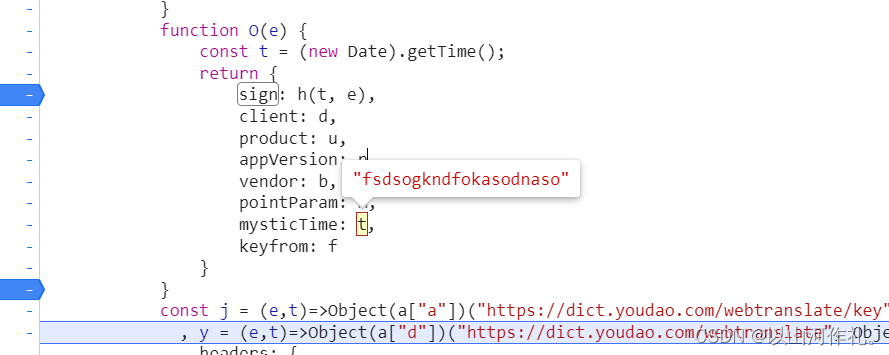
🎯接下来我们写代码,来得到sign的值
import time
t ='fsdsogkndfokasodnaso'
e = time.time()
e =1682603344052
d ='fanyideskweb'
u ='webfanyi'
data =f'client={d}&mysticTime={e}&product={u}&key={t}'from hashlib import md5
m = md5()
m.update(data.encode('utf-8'))
nonce = m.hexdigest()print(nonce)

🎯接下来对字符串进行解密,将解密后的字节码转换为utf-8编码的文本字符串。
import hashlib
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import base64
# 导入必要的模块和库# pip install pycryptodome# 将存放模块的文件(Crypto)改成大写开头(Crypto)defdecrypt( decrypt_str):
key ="ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
iv ="ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
key_md5 = hashlib.md5((key).encode('utf-8')).digest()
iv_md5 = hashlib.md5((iv).encode('utf-8')).digest()print('key_md5:', key_md5)print('iv_md5:', iv_md5)print()
aes = AES.new(key=key_md5, mode=AES.MODE_CBC, iv=iv_md5)
code = aes.decrypt(base64.urlsafe_b64decode(decrypt_str))return unpad(code, AES.block_size).decode('utf8')print(decrypt(response.text))
设置密钥和初始向量
key ="ydsecret://query/key/B*RGygVywfNBwpmBaZg*WT7SIOUP2T0C9WHMZN39j^DAdaZhAnxvGcCY6VYFwnHl"
iv ="ydsecret://query/iv/C@lZe2YzHtZ2CYgaXKSVfsb7Y4QWHjITPPZ0nQp87fBeJ!Iv6v^6fvi2WN@bYpJ4"
这里定义了两个变量key和iv,分别表示密钥和初始向量。注意到这两个字符串已经被加密处理,因此在使用之前需要将它们进行解密。
对密钥和初始向量进行哈希处理
key_md5 = hashlib.md5((key).encode('utf-8')).digest()
iv_md5 = hashlib.md5((iv).encode('utf-8')).digest()
使用了哈希函数md5对密钥和初始向量进行处理。在处理之前,需要将密钥和初始向量从字符串类型转换为字节类型,并在处理后获取到它们的哈希值。
创建AES对象并解密消息
aes = AES.new(key=key_md5, mode=AES.MODE_CBC, iv=iv_md5)
code = aes.decrypt(base64.urlsafe_b64decode(decrypt_str))
创建了一个AES对象,使用了上一步中得到的哈希值作为密钥和初始向量的值,并使用CBC模式进行加密解密操作。然后,我们对传入的待解密字符串进行base64解码,再使用解密过程对其进行解密操作。
移除padding并返回结果
return unpad(code, AES.block_size).decode('utf8')
通过
Crypto.Util.Padding.unpad函数移除了解密后的字节码中的
padding,并通过
.decode('utf8')将其转换为文本字符串类型。最终,我们从
decrypt函数中返回了解密后的明文字符串。
🎯这段代码主要实现了一个AES-CBC加密算法的解密过程,使用了哈希函数增强了密钥和初始向量的安全性,并通过base64编解码和padding移除等操作对加密消息进行了处理。
运行结果如下:
🎯后续可以对数据进行解析,提取出我们想要的数据。
版权归原作者 以山河作礼。 所有, 如有侵权,请联系我们删除。