
白盒测试
覆盖语句

语句覆盖
让所有的语句执行即可,用图表述就是流程图中矩形表示的语句全部执行即可
判定覆盖(*)
让所有判定的YES/NO执行一次即可。假设有两个判定M、N,对于两者YES/NO的条件组合一共有四组,在这里M/N只需要满足YES、NO出现了一次即可,比如M–YES N–NO,那么第二组为M–NO,N–YES,此时对于M、N来说他们都进行了YES和NO的判断
条件覆盖
所有判定内的条件,在条件真假的情况下都执行了一次。如果有4个条件,那么4*2种情况都执行一次后完成测试。
判定条件覆盖(*)
所有判定内的条件,在条件真假的情况下都执行了一次,并且保证判断的真假也要也行一次
条件组合覆盖
可以看作是条件真假的组合,真真、真假、假真、假假。
路径覆盖
所有的路径都需要走一次
举例说明
现在给出一个程序的流程图,分析这个程序的基本逻辑判断条件和执行路径。
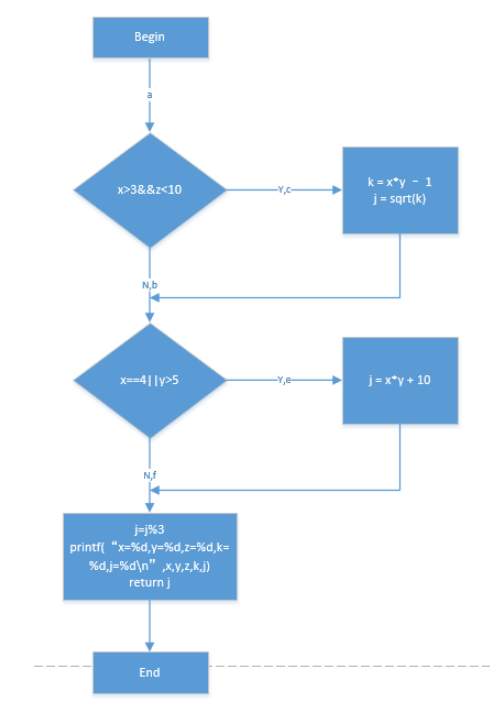
该程序模块有四条不同的路径:
P1(a-c-e) P2(a-c-f) P3(a-b-e) P4(a-b-f)
基本逻辑判定条件有:
x>3, z<10, x==4, y>5
判定M = x > 3 and z < 10 判定N = x == 4 or y > 5
一共有八种条件出现的情况:
(1) x > 3为真 (2) x == 3为假
(3) z < 10为真 (4) z == 10 为假
(5) x == 4为真 (6) x <>4 为假
(7) y > 5 为真 (8) y == 5 为假
条件 / 判定覆盖
// 不仅M、N每组判定要执行一次YES、NO,还需要将4*2种情况都执行一次
需满足的条件测试数据期望结果M真N真 出现1.3.5.7x=4 z=9 y=6 k=0 j=0覆盖路径为P1M假N假 出现2.4.6.8x=3 z=10 y=5 k=0 j=0覆盖路径为P4
判定覆盖
// 让所有判定的YES/NO执行一次即可。假设有两个判定M、N// 对于两者YES/NO的条件组合一共有四组,在这里M/N只需要满足YES、NO出现了一次即可// 比如M--YES N--NO,那么第二组为M--NO,N--YES,此时对于M、N来说他们都进行了YES和NO的判断
需满足的条件测试数据期望结果M真N假 出现1.3.6.8x=4 z=9 y=6 k=0 j=0覆盖路径为P2M假N真 出现2.4.5.7x=3 z=10 y=5 k=0 j=0覆盖路径为P3
条件组合覆盖
// 可以看作是条件真假的组合,真真、真假、假真、假假
需满足的条件测试数据期望结果M:真&&真 N:真||真x=4 z=9 y=6 k=0 j=0覆盖路径为P1M: 真&&假 N:真||假x=4 z=10 y=5 k=0 j=0覆盖路径为P3M:假&&真 N:假||真x=3 z=9 y=6 k=0 j=0覆盖路径为P3M:假&&假 N:假||假X=3 z=10 y=5 k=0 j=0覆盖路径为P4
控制流图
绘图
// 在控制流图中,图中的每个节点代表一个基本块,即一段没有任何跳转或跳转目标的直线代码;// 跳转目标开始一个块,而跳转结束一个块。// 有向边用来表示控制流中的跳转。在大多数演示中,有两个特别指定的块:// 入口块,控制通过它进入流程图;出口块,所有控制流通过它离开
控制流图的结构有:
圈复杂度
V(G) = m - n + 2,其中 m 是边数,n 是顶点数,这是最常用的一种计算方法
独立路径集合
把所有从根节点开始,到最底部叶子结点的所有路径列举出来
举例说明
例子一
这里引用一下这位博主的例子,清晰易懂
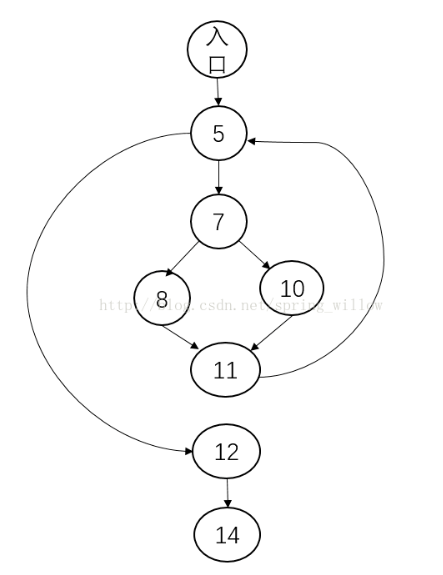
intgsd(int x,int y){int q=x;int r=y;while(q!=r){if(q>r) q=q-r;else r=r-q;}return q;}该程序的控制流图为:
分析一下这个图是如何得出来的:
- 首先我们画一下入口,对于基本的没有判断的语句(如第3,4行)可以写在一起替换掉入口,即(3,4)作为一个圈
- 走到第5行,遇到while判断条件,放下一个判断块
- 进入循环,走到第7行的 if 判断,有第8、10行这两种结果
- 结束当前循环体,走入第11行,然后回到第5行进行判断,如果跳出循环,就进入12 行
- 最后结束的出口块也需要画出
例子二
代码段为:

绘制的控制流图为:(如果说要求序号是第几个执行语句,是不能行数的,那么从上到下改为1,2,3…即可)
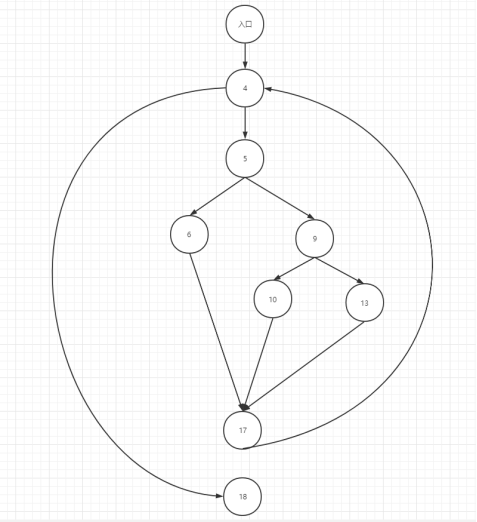
环路复杂度:
一共有9个点,11条边,所以环路复杂度为 11 - 9 + 2 = 4
黑盒测试
边界值分析法
边界值分析法就是对输入或输出的边界值进行测试的一种黑盒测试方法。通常边界值分析法是作为对等价类划分法的补充,其测试用例来自等价类的边界。使用边界值分析方法设计测试用例,首先应确定边界情况。通常输入和输出等价类的边界,就是应着重测试的边界情况。下面介绍几种情况:
- 假设一个文本输入区域内允许输入 1 到 255 个字符,则,输入1个和255个字符作为有效等价类,然后,输入0个和256个字符作为无效等价类,这几个值都属于边界条件值
- 假设文本输入框要求输入5位数据值,则10000作为最小值,99999作为最大值,然后,输入9999和100000作为恰好超出边界的值
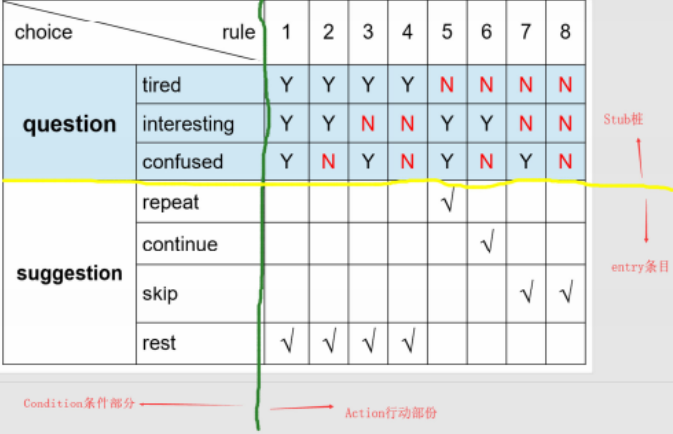
决策表法(判定表法)
决策表能够将各种复杂情况都列举出来,不会产生遗漏,因此,使用决策表设计出的测试用例是完整的测试用例集合,它们非常适合描述在不同条件集下采取许多行动组合的情况
决策表的组成
桩规则条件桩条件项动作桩动作项
决策表通常由四部分组成:条件桩,动作桩,条件项,动作项
- 条件桩:列出问题的所有条件
- 动作桩:列出问题规定所采取的操作
- 条件项:针对条件桩给出的条件,列出所有可能情况下的真假值
- 动作项:列出在条件项的各种取值情况下应该采取的动作
- 规则:任何一个条件组合的特定取值即相应要执行的操作成为一条规则,决策表中一列就是一条规则
创建判定表的步骤:
- 列出条件桩和动作桩的内容
- 确定规则的个数;如果有n个条件,判定表有2^n规则
- 填入条件项
- 填入动作项,这样便可得到初始决策表
- 化简合并,合并相似规则后得到决策表
黑盒测试例题
接下来用一道例题来补充说明:
快递收费标准
快递按公斤计算超过1公斤按2公斤算,超过2公斤就按3公斤算以此类推。(每个产品的重量在产品的详情里面都有标注)
江浙沪首重10元续重1.5元,
北京,安徽,福建,广东,广西,贵州,海南,河北,河南,黑龙江,湖北,湖南,江西,辽宁,宁夏,山东,山西,陕西,四川,天津,云南,重庆首重18元续重15元,
甘肃,吉林,内蒙古,青海,西藏,新疆首重25元续重22元。
首重是指1公斤以内,续重是每增加一公斤
f(x,y)=
![**[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1tGw2SOM-1653828470387)(file:///C:\Users\NEKO_~1\AppData\Local\Temp\ksohtml8584\wps1.jpg)]](https://img-blog.csdnimg.cn/888d28333dab43b788c6ae5d3680cc1e.png)
按软件测试书籍上来说,测试条件只会取在边界值范围内的点上,所以**[0,500]**的测试取值为0,1,250,499,500
根据题意可以看到,边界条件在于快递重量是否超过整数公斤数,所以边界条件可以分别取2和2.1,具体测试用例如下所示:
序号x(重量)y(公里)期望输出(计算就行)1202213225042499525002500625017275082999921000210001021001112200012229991323000142.11500
现在再来试试画决策表:
条件桩一共就两个,一个是距离,一个是重量。
但是距离有很多种情况,所以可以拆分为三个子条件桩。
事实上,我们在写判定条件的时候,可以将NNNN看作是0000,NNNT看作是0001…这样似二进制的填写判定结果。
桩12345678条件0≤y1≤500NNNNNNNN500<y2≤1000NNNNYYYY1000<y3≤3000NNYYNNYY重量在首重范围内NYNYNYNY动作按首重付款√√按超出首重付款√√不可能配送√√√√910111213141516YYYYYYYYNNNNYYYYNNYYNNYYNYNYNYNY√√√√√√√√
再之后就是化简决策表,举例来说,
YYNNNNY****N√√
第四行中两个不同的条件并不会影响最终的结果,所以这两个条件可以合并为一个:
YNN——√
化简后的结果为:(这里没有写入不可能配送的情况)
桩12345678条件0≤y1≤500NNNNYY500<y2≤1000NNYYNN1000<y3≤3000YYNNNN重量在首重范围内NYNYNY动作按首重付款√√√按超出首重付款√√√不可能配送
再之后就可以根据新的决策表设计测试用例了:
这里覆盖的规则就是决策表最上面的那些编号,现在我们需要输入x,y来满足这些条件。
测试用例编号输入数据预期结果覆盖的规则xy112233445566
集成测试
这一部分的内容转自这篇博文。
基本概念
为什么我们需要集成测试?
- 在开发应用程序时,它被分解为更小的模块,并且为每个开发人员分配1个模块。一个开发人员实现的逻辑与另一个开发人员完全不同。
- 很多时候,当数据从一个模块移动到另一个模块时,数据的结构会发生变化,这会导致后续模块出现问题。
- 模块与某些第三方工具或API进行交互,这些工具或API也需要进行测试,以确保该工具或API接受的数据是正确的,并且生成的响应也是预期的。
- 测试中有一个非常常见的问题:频繁更改需求。许多时间开发人员在没有单元测试的情况下部署更改,此时集成测试变得很重要。
优点
- 可确保集成模块/组件正常工作
- 一旦要测试的模块可用,就可以开始集成测试。它不需要完成其他模块以进行测试,因为Stubs和Drivers可以用于相同的操作
- 它可以检测与接口相关的错误
缺点
- 管理集成测试十分复杂
- 在将任何新系统与遗留系统集成时,需要进行大量的更改和测试工作
测试方案
从根本上说,有两种方法可以进行测试集成:
- 自下而上的方法
- 自上而下的方法
让我们考虑用下图来表述该测试方法:
自下而上
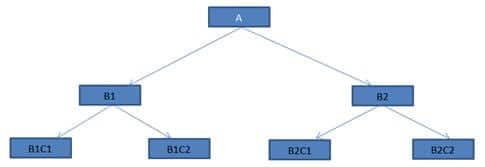
从应用程序的最低或最里面的单位开始,逐渐向上移动。集成测试从最低模块开始,逐步向应用程序的上层模块发展。这种集成一直持续到所有模块都集成在一起,整个应用程序作为一个单元进行测试。
在这种情况下,模块B1C1,B1C2,B2C1,B2C2是经过单元测试的最低模块。模块B1和B2尚未开发。模块B1和B2的功能是调用模块B1C1,B1C2,B2C1,B2C2。由于B1和B2还没有开发,我们需要一些程序或“刺激器”来调用B1C1,B1C2和B2C1,B2C2模块。这些刺激计划称为驱动程序。
简单来说,DRIVERS(驱动模块)是虚拟程序,用于在调用函数不存在的情况下调用最低模块的函数。自底向上技术要求模块驱动程序将测试用例输入提供给被测模块的接口。
优点:
- 如果在程序的最低单元存在重大故障,则更容易检测到它,并且可以采取纠正措施
- 可以实施多个模块的并行测试,提高了测试效率
- 模块是自底向上进行组装,对于一个给定层次的模块,它的子模块(包括子模块的所有下属模块)已经组装并测试完成,所以不再需要桩模块
缺点:
- 在最后一个模块被集成和测试之前,主程序实际上不存在。因此,只会在最后检测到更高级别的设计缺陷
- 对驱动程序的需求让测试管理变得很复杂
举个例子,现在给出一个自底向上的集成测试示例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1hs7ieuC-1653828470390)(../AppData/Roaming/Typora/typora-user-images/image-20220529200309114.png)]](https://img-blog.csdnimg.cn/4c93fc1cec0a4b72945454db3366e153.png)
- 首先找到底层模块有M5,M3,M6,并列进行这三个对象的测试,建立三个驱动模块D1,D2,D3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4znPBx2S-1653828470391)(../AppData/Roaming/Typora/typora-user-images/image-20220529200524890.png)]](https://img-blog.csdnimg.cn/d592ea99371e4d13aa3af44c12f56283.png)
- 现在测试D1对应的M2,以及D3对应的M4(因为D2对应的M1依赖的M2和M4模块还没有测试,所以此时不测试M1)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J48CICPr-1653828470393)(../AppData/Roaming/Typora/typora-user-images/image-20220529200639144.png)]](https://img-blog.csdnimg.cn/19bfe03bfa9a45d2b1d995734b848596.png)
- 测试M1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K3S4BPNL-1653828470394)(../AppData/Roaming/Typora/typora-user-images/image-20220529200659987.png)]](https://img-blog.csdnimg.cn/4053f14797b74f9490f9698adbb7cedc.png)
自上而下
该技术从最顶层的模块开始,以深度优先或者是广度优先,逐渐向较低的模块发展,向系统中增加模块。只有顶层模块是单独进行单元测试的。在此之后,下层模块逐个集成。重复该过程,直到所有模块都被集成和测试。
在我们的图中,测试从模块A开始,下层模块B1和B2逐个集成。现在,较低的模块B1和B2实际上不可用于集成。因此,为了测试最顶层的模块A,我们开发了“ STUBS(桩模块)”。
“Stubs”可以称为代码片段,它接受来自顶层模块的输入/请求并返回结果/响应。这样,尽管模块较低,但是不存在,我们能够测试顶层模块。
优点:
- 较早地验证了主要的控制和判断点,可以首先实现和验证一个完整的软件功能
- 在早期发现顶层的错误
- 早期的程序框架可以进⾏演⽰
缺点:
- 创建Stubs像真实模块一样复杂和耗时。在某些情况下,Stub模块可能会比受激模块更大
- 需要开发桩模块辅助测试。有些甚⾄需要多个桩模块辅助,加⼤了桩模块本来的错误影响
举个例子,现在给出一个程序模块化设计示意图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JgWQJgao-1653828470395)(../AppData/Roaming/Typora/typora-user-images/image-20220529194946577.png)]](https://img-blog.csdnimg.cn/c5e2aea346d04e56990f2f4f3e1730e8.png)
深度优先
以深度优先的顺序进行测试:
- 测试M1,构建S2,S3,S4的stubs模块
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k0BMDksl-1653828470397)(../AppData/Roaming/Typora/typora-user-images/image-20220529195400637.png)]](https://img-blog.csdnimg.cn/9d639d1025dd45c48a7248482942e34a.png)
- 以M1-M2-M5这条路径为例进行深度遍历,现在测试M2,构建S5,S6的stubs模块
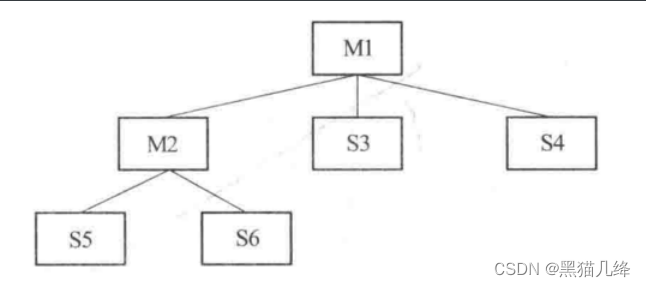
- 测试M5,没有后续模块
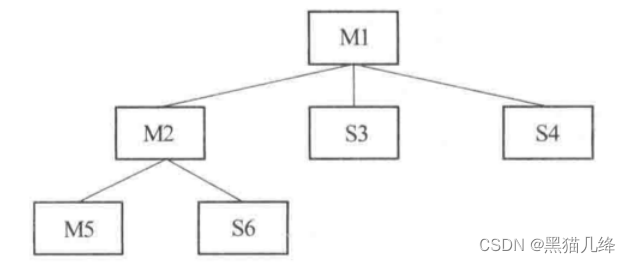
- 测试M6,没有后续模块
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BuGeJmpS-1653828470400)(../AppData/Roaming/Typora/typora-user-images/image-20220529195626516.png)]](https://img-blog.csdnimg.cn/f8b93fb1695f465fa5ebcbfaf8c24259.png)
- 测试M3,没有后续模块
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DxNWSHem-1653828470401)(../AppData/Roaming/Typora/typora-user-images/image-20220529195658556.png)]](https://img-blog.csdnimg.cn/a2d351a1430d420ca934c02a215e93bc.png)
- 测试M4,构建S7的stubs模块
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pVyGA6Co-1653828470402)(../AppData/Roaming/Typora/typora-user-images/image-20220529195740898.png)]](https://img-blog.csdnimg.cn/97d5bcb70d6e470ca89d365119860080.png)
- 测试M7,没有后续模块
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BSATN4Lp-1653828470403)(../AppData/Roaming/Typora/typora-user-images/image-20220529195800268.png)]](https://img-blog.csdnimg.cn/a5292fb1259d4ad2b4df5bfc562721ef.png)
广度优先
以广度优先进行测试:
这里就不步骤介绍了,整体来说,首先测试M1,然后构建S2,S3,S4的stubs模块;然后测试M2->构建,测试M3->构建,测试M4->构建…具体的思路和广度优先算法一样:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5rYSVGpg-1653828470404)(../AppData/Roaming/Typora/typora-user-images/image-20220529200036461.png)]](https://img-blog.csdnimg.cn/a5f1185405b441ea869ddb2e2519d232.png)
GBT-5532-2008
介绍一下软件测试的技术要求:

- 软件测试是验证软件产品特性是否满足用户的需求
- 软件测试就是一系列活动,这些活动是为了评估一个程序或软件系统的特性或能力,井确定其是否达到了预期结果
- 测试是不能穷尽的
- 测试就是为了发现缺陷,而不是证明程序无错误
- 一个成功的测试是发现了软件问题的测试,否则测试就没有价值。这就如同一个病人(因为是病人,假定确实有病),到医院去做相应的检查,结果没有发现问题,那说明这次体检是失败的,浪费了病人的时间和金钱。以逆向思维方式引导人们证明软件是“不工作的”,会促进我们不断思考开发人员对需求理解的误区、不良的习惯、程序代码的边界、无效数据的输入等,找到系统的薄弱环节或识别出系统复杂的区域,目标就是发现系统中各种各样的问题
版权归原作者 黑猫几绛 所有, 如有侵权,请联系我们删除。