

🐇明明跟你说过:个人主页
🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅
🔖行路有良友,便是天堂🔖
一、引言
1、Kafka简介
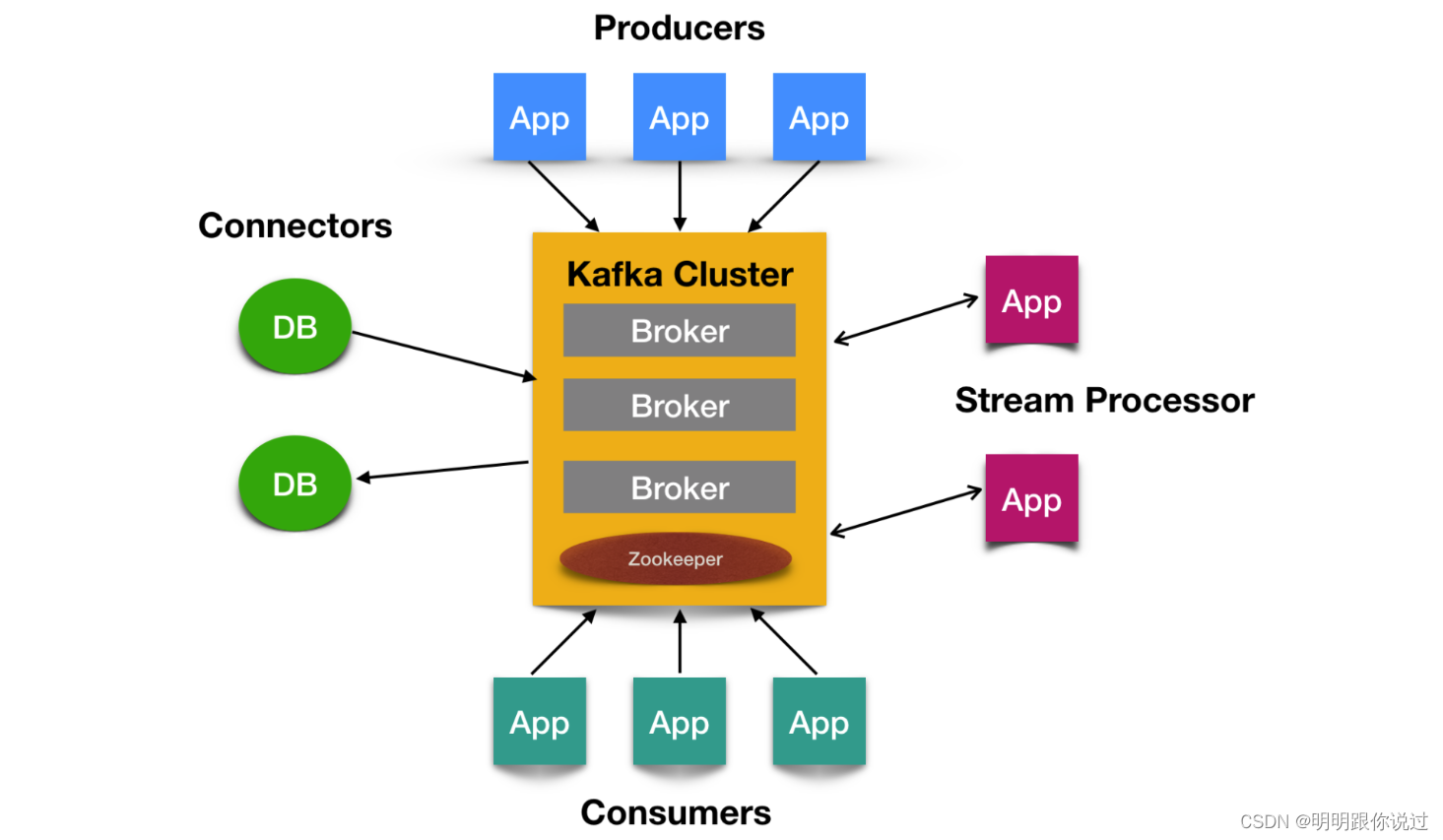
Kafka是一个分布式流处理平台,最初由LinkedIn开发,随后开源并捐献给了Apache基金会。Kafka的主要设计目标是处理和存储大规模的实时数据流。
Kafka的核心概念
- Producer(生产者):生产者是向Kafka主题(topic)发送消息的客户端应用程序。生产者发布的数据消息被称为记录(records)。
- Consumer(消费者):消费者是从Kafka主题中读取消息的客户端应用程序。消费者从指定的主题订阅并消费消息。
- Topic(主题):主题是Kafka中的一个逻辑通道,生产者将消息发布到主题,消费者从主题订阅和消费消息。每个主题可以有多个分区(partition),以实现更高的并行处理能力。
- Partition(分区):主题中的数据分为多个分区,每个分区是一个有序的、不可变的记录序列。分区通过分布在集群中的不同Kafka代理(broker)上来实现负载均衡和并行处理。
- Broker(代理):Kafka集群中的每个服务器节点被称为一个代理。代理负责存储分区数据,并处理来自生产者和消费者的请求。
- Consumer Group(消费者组):消费者组是一组协同工作的消费者。每个消费者组订阅一个或多个主题,并分担消费这些主题中的消息。每条消息只会被消费者组中的一个消费者处理。
- ZooKeeper:Kafka使用Apache ZooKeeper来管理集群配置、选举代理领导以及进行分布式协调。ZooKeeper确保集群的高可用性和一致性。

Kafka的特点
- 高吞吐量:Kafka可以在低延迟下处理大量的数据流,适合实时大数据处理和流数据分析。
- 可扩展性:Kafka通过添加更多的代理节点来水平扩展集群,支持大规模数据处理。
- 容错性:Kafka通过数据复制机制保证消息的高可用性和容错能力,即使在代理节点故障的情况下,也能继续处理消息。
- 持久化:Kafka将消息持久化到磁盘,确保数据的持久存储和可靠传递。
- 流处理:Kafka Streams API提供了强大的流处理功能,可以在消息流上传输和处理数据,进行实时计算和分析。

Kafka的典型应用场景
- 日志收集:Kafka可以从不同的应用程序和系统中收集日志,并将它们统一存储和处理。
- 实时分析:通过Kafka将数据实时传输到流处理系统或实时分析平台,进行实时数据分析和监控。
- 事件源:使用Kafka构建事件源架构,实现事件驱动的微服务通信和数据同步。
- 数据管道:Kafka作为数据管道的核心组件,可以将数据从源系统传输到目标系统,如数据库、数据仓库、数据湖等。
- 消息传递:Kafka可以作为消息中间件,处理高吞吐量、低延迟的消息传递需求。
关于更多Kafka的介绍,请参考《大数据领域的重要基础设施——Kafka入门篇(诞生背景与主要特点介绍)》 这篇文章
2、为什么在Kubernetes中部署Kafka
1. 自动化管理和编排
- Kubernetes 提供了自动化的部署、扩展和运维管理,这使得管理复杂的分布式系统如Kafka更加容易。Kubernetes可以自动处理容器的启动、停止和重启,确保Kafka集群的高可用性和稳定性。
2. 弹性扩展
- Kubernetes具有强大的扩展能力,可以根据需要动态地增加或减少Kafka节点的数量。这种弹性扩展能力对于应对流量波动和负载变化非常重要,能够确保Kafka在高峰期仍然能够高效地处理数据。
3. 高可用性
- Kubernetes的自愈功能可以自动检测和恢复故障节点,确保Kafka服务的高可用性。通过Pod的重启和重新调度,Kubernetes能有效应对节点故障和网络问题,保证Kafka集群的持续运行。
4. 资源隔离和管理
- Kubernetes的资源管理能力能够确保Kafka集群的资源需求得到满足。通过使用Kubernetes的资源配额和限制,管理员可以确保Kafka实例拥有足够的CPU、内存和存储资源,从而提高系统的性能和稳定性。
5. 部署一致性
- Kubernetes的声明式配置使得Kafka的部署变得更加一致和可重复。使用Kubernetes配置文件(YAML/JSON),可以定义Kafka集群的所需状态,Kubernetes会自动将系统调节到该状态。这种声明式配置简化了部署流程,减少了人为错误的可能性。
6. 便捷的服务发现和负载均衡
- Kubernetes内置的服务发现和负载均衡功能可以简化Kafka集群的网络配置。Kubernetes服务(Service)可以为Kafka代理提供一个稳定的网络端点,消费者和生产者可以通过该端点访问Kafka集群,而不必关心具体的Pod IP地址。

3、单机版Kafka与集群版Kafka的对比
1. 可靠性
- 单机版Kafka:在单机环境下运行,如果这台机器发生故障或崩溃,那么Kafka服务将不可用,导致数据丢失或不可用。因此,单机版Kafka的可靠性相对较低。
- 集群版Kafka:通过多台机器组成的集群来运行Kafka,数据会被复制到多个Broker上,实现数据的冗余存储。即使集群中的某个Broker发生故障,其他Broker仍然可以提供服务,确保数据的可靠性和服务的可用性。
2. 可扩展性
- 单机版Kafka:受限于单台机器的资源(如CPU、内存、磁盘等),单机版Kafka的可扩展性较差。当数据量或并发量增长时,可能会遇到性能瓶颈。
- 集群版Kafka:集群版Kafka可以通过添加更多的Broker来扩展集群的容量和性能。当数据量或并发量增长时,可以通过水平扩展来应对这些挑战,保持系统的稳定性和性能。
3. 性能
- 单机版Kafka:虽然单机版Kafka在小型应用或测试环境中可能表现出较好的性能,但在处理大规模数据和高并发场景时,其性能可能会受到限制。
- 集群版Kafka:集群版Kafka通过分布式处理和负载均衡来提高整体性能。多个Broker可以并行处理数据,从而提高吞吐量。此外,集群版Kafka还支持数据分区和复制,进一步提高数据处理能力和容错能力。
4. 容错能力
- 单机版Kafka:由于单机版Kafka没有冗余存储和备份机制,因此其容错能力较差。一旦机器发生故障或崩溃,数据将可能丢失。
- 集群版Kafka:集群版Kafka通过数据复制和分区容错机制来提高容错能力。即使某个Broker发生故障,其他Broker仍然可以提供服务,并确保数据的可靠性和完整性。此外,集群版Kafka还支持数据备份和恢复机制,以应对更严重的故障情况。
5. 部署和维护
单机版Kafka:部署和维护相对简单,只需要关注单台机器的状态和性能即可。
集群版Kafka:集群版Kafka的部署和维护相对复杂一些,需要关注整个集群的状态、性能、负载均衡以及故障恢复等方面。同时,还需要考虑网络延迟、数据同步等问题对集群性能的影响。
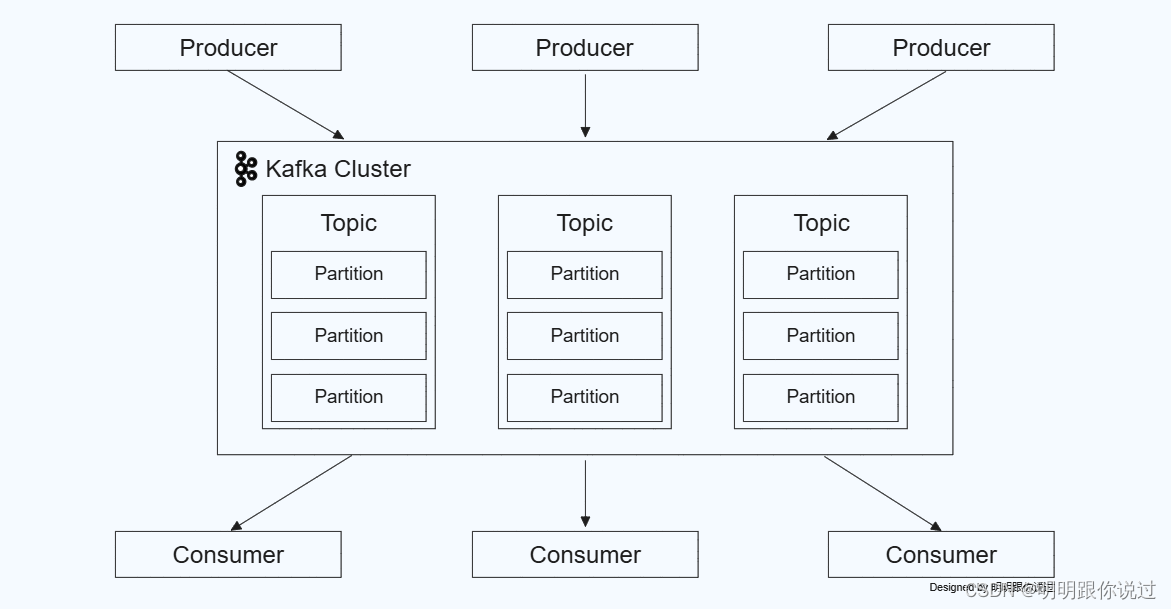
二、Kubernetes基础知识
1、Kubernetes简介
Kubernetes(常简称为K8s)是一个开源的容器编排平台,最初由Google开发,后来捐赠给了Cloud Native Computing Foundation(CNCF)进行维护。它旨在简化部署、扩展和管理容器化应用程序的任务。
Kubernetes的主要特点:
1. 自动化部署与扩展:
- Kubernetes可以自动化地部署和管理容器化应用程序,实现无缝的扩展。它可以根据应用程序的需求自动调整容器数量,并确保它们在集群中均匀地分布。
2. 自我修复:
- Kubernetes具有自我修复的能力,能够自动检测并替换失败的容器实例或节点,确保应用程序的高可用性。
3. 服务发现与负载均衡:
- Kubernetes提供了内置的服务发现和负载均衡功能,可以将请求动态地路由到可用的容器实例,确保应用程序的稳定性和可靠性。
4. 自动装箱(Pod):
- Kubernetes使用Pod作为最小部署单元,一个Pod可以包含一个或多个相关的容器,并共享网络和存储资源。这种抽象简化了应用程序的部署和管理。
5. 存储编排:
- Kubernetes支持多种存储解决方案,并提供了存储卷(Volume)和持久卷(PersistentVolume)等资源,以便应用程序可以方便地访问持久化存储。
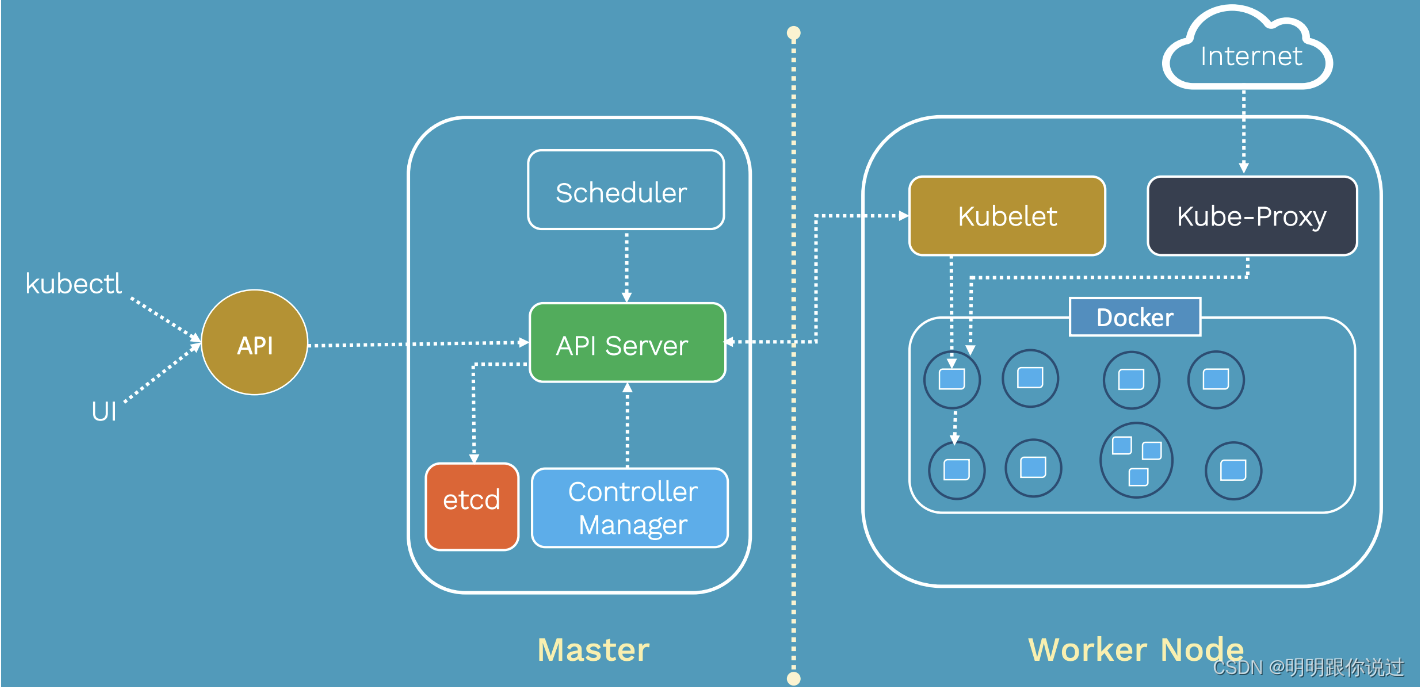
2、Pods、Deployments、Services等概念介绍
1. Pods(Pod)
Pod是Kubernetes中最小的可部署单元。它是一个或多个相关容器的组合,它们共享网络和存储空间,并被放置在同一主机上。Pod通常包含一个主应用程序容器,以及辅助容器(如日志收集器、监控代理等)。Pod提供了一种抽象层,使应用程序和服务能够独立于底层的基础设施运行,并具有一定的隔离性。
2. Deployments(部署)
Deployment是用于定义和管理Pod部署的对象。它描述了应用程序的期望状态,并负责确保集群中的Pod按照定义的副本数进行部署和维护。Deployment具有自我修复和自动扩展的能力,可以实现滚动更新和回滚操作,保证应用程序的稳定性和可靠性。通过Deployment,开发团队可以轻松地进行应用程序的部署和管理,而无需手动管理Pod实例。
3. Services(服务)
Service是Kubernetes中用于定义一组Pod的访问入口。它为一组Pod提供了一个统一的网络终结点,并负责将请求路由到可用的Pod实例。Service可以通过标签选择器来选择相关的Pod,并实现负载均衡和服务发现。Kubernetes支持多种类型的Service,如ClusterIP、NodePort、LoadBalancer等,以满足不同的应用场景和需求。
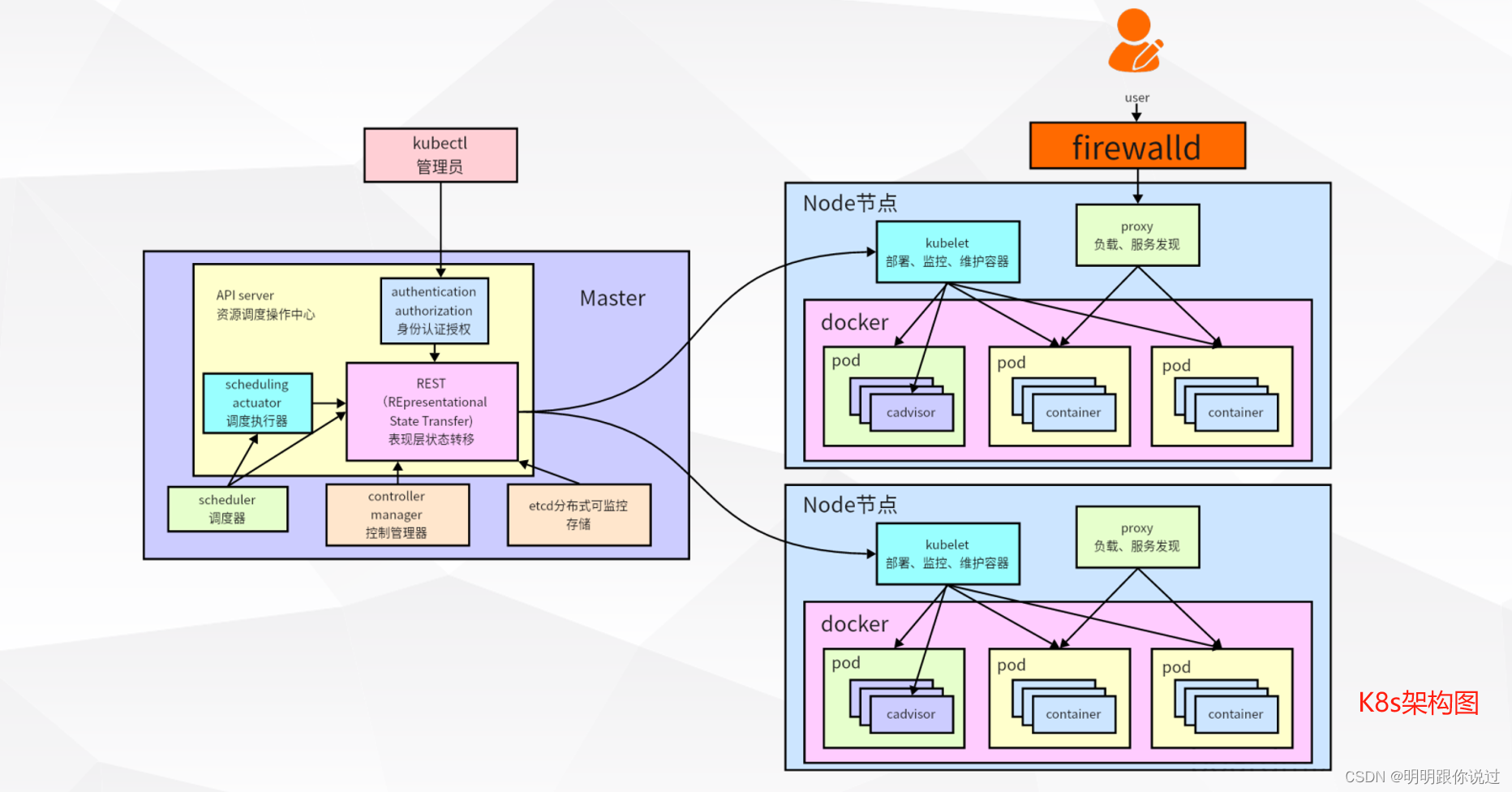
三、准备Kafka部署环境
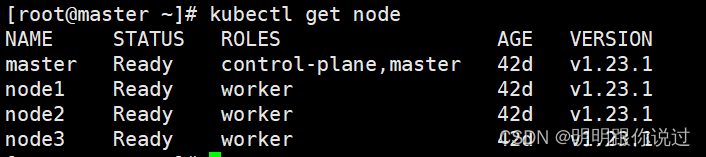
1、选择Kubernetes集群与配置
K8s集群版本 1.23,也可以是其他版本,这里以1.23为例
2、获取Kafka镜像
在k8s Node节点上执行以下命令
[root@node1 ~]# docker pull zookeeper:3.8
[root@node1 ~]# docker pull kafka:3.1.0
[root@node2 ~]# docker pull zookeeper:3.8
[root@node2 ~]# docker pull kafka:3.1.0
[root@node3 ~]# docker pull zookeeper:3.8
[root@node3 ~]# docker pull kafka:3.1.0
四、部署单机版Kafka
1、部署zookeeper
为什么部署kafka前要部署zookeeper?
Kafka依赖Zookeeper来实现分布式协调和配置管理。在Kafka集群中,Zookeeper扮演着多种角色,包括:
- 配置管理:Kafka集群的配置信息和元数据存储在Zookeeper中,包括主题(topics)、分区(partitions)、副本(replicas)等配置信息。
- Leader选举:Kafka的分区(partitions)被分布式存储在集群中的多个Broker上,每个分区都有一个Leader和多个Follower。Zookeeper负责Leader选举,确保每个分区都有一个活跃的Leader。
- Broker注册:Kafka Broker在启动时会向Zookeeper注册自己的信息,包括地址、ID等,以便其他Broker和客户端发现和连接。
- 健康监测:Zookeeper监控Kafka集群中各个节点的健康状态,并在节点出现故障或宕机时触发相应的处理操作。
因此,在部署Kafka之前,需要先部署Zookeeper,确保Kafka集群正常运行所需的分布式协调和配置管理功能可用。没有Zookeeper,Kafka无法正常运行,并且无法实现高可用性、数据一致性和故障容错等特性。
编写部署zookeeper的YAML文件,如下
[root@master ~]# vim zook.yaml
#输入如下内容
apiVersion: apps/v1
kind: Deployment
metadata:
name: zookeeper-deployment
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
containers:
- name: zookeeper
image: zookeeper:3.8
ports:
- containerPort: 2181
---
apiVersion: v1
kind: Service
metadata:
name: zookeeper-service
spec:
selector:
app: zookeeper
ports:
- protocol: TCP
port: 2181
targetPort: 2181
nodePort: 32181 # NodePort设置为32181
type: NodePort
部署zookeeper
[root@master ~]# kubectl apply -f zook.yaml
查看状态
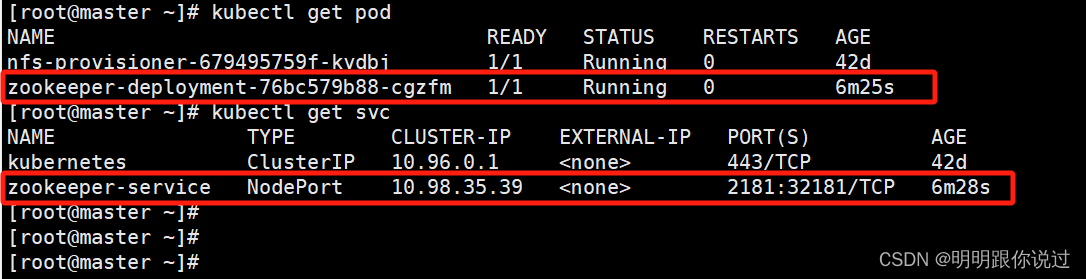
2、部署Kafka
编写部署kafka的YAML文件
[root@master ~]# cat kafka.yaml
# 输入如下内容
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-deployment
spec:
replicas: 1
selector:
matchLabels:
app: kafka
template:
metadata:
labels:
app: kafka
spec:
containers:
- name: kafka
image: kafka:3.1.0
ports:
- containerPort: 9092
command:
- sh
- -c
- "exec /app/kafka/bin/kafka-server-start.sh /app/kafka/config/server.properties --override broker.id=0 \
--override listeners=PLAINTEXT://:9092 \
--override advertised.listeners=PLAINTEXT://192.168.40.181:30092 \
--override zookeeper.connect=192.168.40.181:32181/kafka \
--override auto.create.topics.enable=true \
--override zookeeper.session.timeout.ms=6000 \
--override zookeeper.set.acl=false"
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: ALLOW_PLAINTEXT_LISTENER
value: "yes"
- name: KAFKA_HEAP_OPTS
value : "-Xms1g -Xmx1g"
---
apiVersion: v1
kind: Service
metadata:
name: kafka-service
spec:
type: NodePort
ports:
- port: 30092
targetPort: 9092
nodePort: 30092
selector:
app: kafka
部署kafka
[root@master ~]# kubectl apply -f kafka.yaml
查看状态
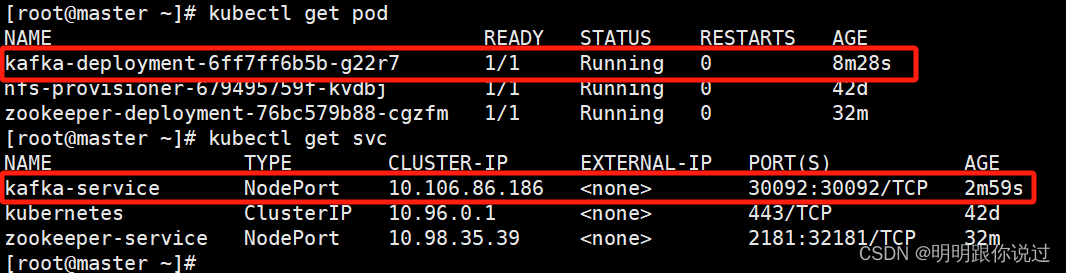
五、测试
1、访问Kafka服务
进入到kafka的pod中,使用自带的命令行客户端工具
[root@master ~]# kubectl exec -it kafka-deployment-6ff7ff6b5b-g22r7 -- /bin/bash
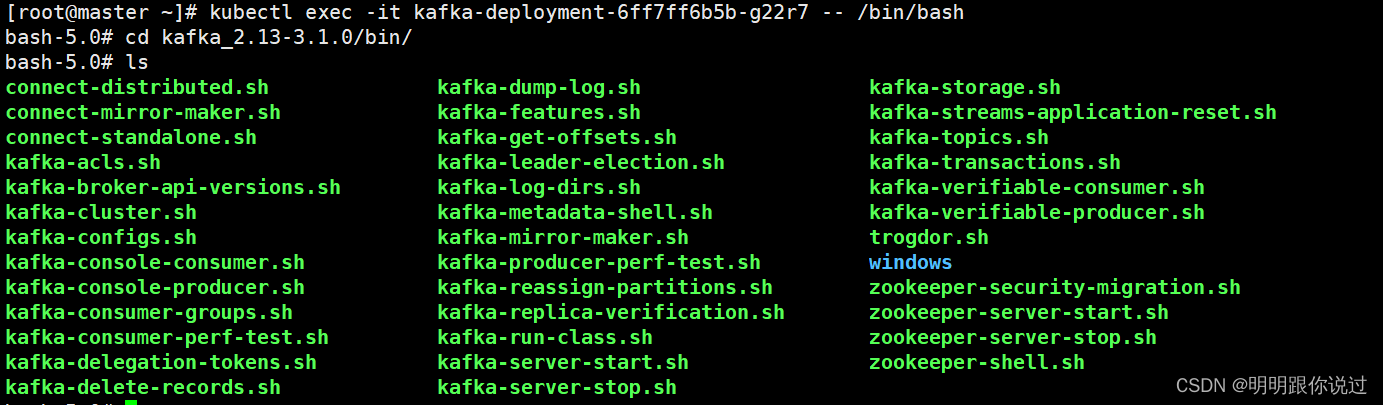
2、创建第一个Topic
bash-5.0# ./kafka-topics.sh --bootstrap-server 192.168.40.181:30092 --create --topic test --partitions 1 --replication-factor 1
查看详情
bash-5.0# ./kafka-topics.sh --bootstrap-server 192.168.40.181:30092 --describe --topic test

3、kafka-topics.sh工具介绍
kafka-topics.sh 是 Apache Kafka 提供的一个命令行工具,用于管理 Kafka 集群中的主题(topics)。我们可以使用它来创建、列出、描述、修改或删除主题。
1. 列出所有主题
bin/kafka-topics.sh --list --bootstrap-server <kafka_connect_string>
2. 创建主题
bin/kafka-topics.sh --create --bootstrap-server <kafka_connect_string> --replication-factor <replication_factor> --partitions <num_partitions> --topic <topic_name>
其中:
- ***
--replication-factor**是每个分区的副本数量。 - ***
--partitions**是主题中的分区数量。 - ***
--topic**是要创建的主题的名称。
3. 描述主题
bin/kafka-topics.sh --describe --bootstrap-server <kafka_connect_string> --topic <topic_name>
这会显示关于主题的详细信息,如分区、副本、领导者等。
4. 删除主题
默认情况下,Kafka 不会自动删除主题。但是,如果Kafka 集群启用了 delete.topic.enable 配置(在 server.properties 中),可以使用以下命令来删除主题:
bin/kafka-topics.sh --delete --bootstrap-server <kafka_connect_string> --topic <topic_name>
但是,请注意,即使删除了主题,Kafka 也会保留与该主题相关的日志文件,除非也配置了日志删除策略。
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于Kafka的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
版权归原作者 明明跟你说过 所有, 如有侵权,请联系我们删除。